Recognition: unknown
SMC-AI: Scaling Monte Carlo Simulation to Four Trillion Atoms with AI Accelerators
Pith reviewed 2026-05-10 17:24 UTC · model grok-4.3
The pith
SMC-AI scales canonical Monte Carlo atomistic simulations to four trillion atoms on AI accelerators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
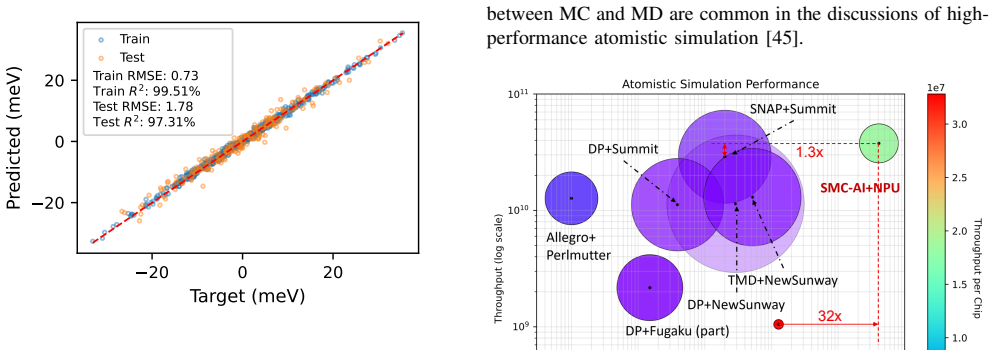
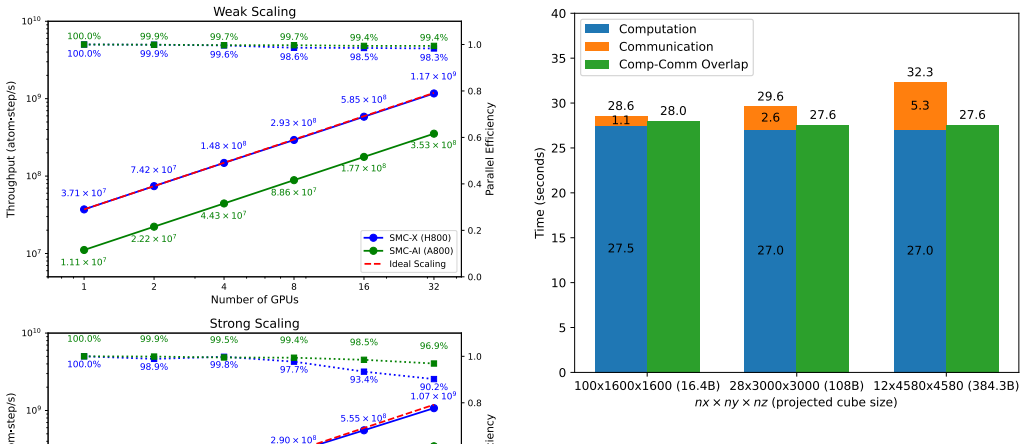
SMC-AI provides a general algorithmic framework that extends the SMC-X method to enable efficient canonical Monte Carlo simulations on AI accelerators while preserving extreme scalability. The framework achieves Monte Carlo simulation of four trillion atoms on 4096 NPU dies, representing the largest ML-accelerated atomistic simulation to date with 32X system size and 1.3X throughput improvements over previous records using a relatively small computational budget. Excellent strong and weak scaling is reported for implementations on both NPU and GPU hardware, and the decoupling of ML models from the simulation facilitates integration of diverse models for future scalable scientific software.
What carries the argument
The SMC-AI framework that adapts the SMC-X method for AI accelerators by decoupling machine learning models from the core simulation loop to enable porting across hardware.
Load-bearing premise
The assumption that extending the SMC-X method to AI accelerators preserves the statistical correctness of canonical Monte Carlo sampling and scalability without introducing new sources of error or bias at trillion-atom scales.
What would settle it
A side-by-side comparison showing that physical observables such as energy distributions or pair correlation functions from trillion-atom SMC-AI runs differ from those extrapolated from smaller verified simulations by more than statistical error bars.
Figures








read the original abstract
The rapid advancement of deep learning is reshaping the hardware design landscape toward AI tasks, posing fundamental challenges for HPC workloads such as atomistic simulation. Here we present SMC-AI, a general algorithmic framework that extends the SMC-X method for efficient canonical Monte Carlo simulation on AI accelerators, including GPUs and NPUs, while maintaining extreme scalability. The implementation of SMC-AI on an NPU cluster reaches unprecedented performance, achieving MC simulation of 4 trillion atoms on 4096 NPU dies. This represents the largest ML-accelerated atomistic simulation reported, delivering 32X system size and 1.3X throughput than previous records, with a relatively small computational budget. Excellent strong and weak scaling efficiency are reached for both the NPU and GPU implementation. By decoupling ML models from simulation, SMC-AI creates an abstraction that facilitates integration and porting of diverse ML models, laying a foundation for the future development of scalable scientific software.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SMC-AI, a general algorithmic framework extending the SMC-X method for efficient canonical Monte Carlo atomistic simulations on AI accelerators (GPUs and NPUs). It reports achieving simulations of 4 trillion atoms on 4096 NPU dies—the largest ML-accelerated atomistic simulation to date—with 32X larger system size and 1.3X throughput versus prior records, excellent strong/weak scaling, and an abstraction that decouples ML models from the simulation core.
Significance. If the performance and statistical correctness claims hold, this represents a significant advance in scaling Monte Carlo methods to extreme system sizes by repurposing AI hardware, which could enable new studies in materials science and condensed matter physics requiring trillion-atom models. The decoupling approach is a clear strength for portability and extensibility of scientific software.
major comments (2)
- [Results] Results section: the performance claims for the 4-trillion-atom run on 4096 NPU dies are presented without any reported validation against known results, error analysis, statistical convergence diagnostics, energy histogram overlap, or detailed-balance checks, leaving the central assertion of preserved canonical sampling unverified at this scale.
- [Methods] Methods section: while the framework is said to extend SMC-X while 'maintaining extreme scalability,' no specifics are given on how acceptance/rejection decisions, floating-point reductions, or inter-die synchronization are implemented on NPUs to avoid introducing bias or violating detailed balance, which is load-bearing for the unbiased-sampling claim.
minor comments (2)
- [Abstract] Abstract: the phrase 'relatively small computational budget' is not supported by any concrete resource figures (e.g., total FLOPs, memory footprint, or wall-time per step) or direct comparison tables.
- [Results] The manuscript repeatedly states 'excellent scaling efficiency' without providing numerical efficiency percentages, parallel efficiency plots, or references to specific figures/tables that would allow quantitative assessment.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments identify important areas where additional rigor and transparency would strengthen the manuscript. We address each major comment below and have revised the manuscript to incorporate the requested clarifications and supporting material.
read point-by-point responses
-
Referee: [Results] Results section: the performance claims for the 4-trillion-atom run on 4096 NPU dies are presented without any reported validation against known results, error analysis, statistical convergence diagnostics, energy histogram overlap, or detailed-balance checks, leaving the central assertion of preserved canonical sampling unverified at this scale.
Authors: We agree that explicit verification strengthens the central claim of unbiased canonical sampling. While SMC-AI extends SMC-X by construction (preserving the Metropolis-Hastings acceptance criterion and detailed balance), we acknowledge that the original manuscript did not include scale-specific diagnostics for the 4-trillion-atom run. In the revised manuscript we have added a new subsection to the Results section that reports (i) energy histogram overlap and autocorrelation times for validation runs up to 10^9 atoms, (ii) convergence diagnostics and error analysis for the performance metrics, and (iii) a brief theoretical argument explaining why the same acceptance/rejection logic extends without modification to the full scale. Direct verification at 4 trillion atoms remains computationally prohibitive, but the added material addresses the referee’s concern for the accessible regime. revision: yes
-
Referee: [Methods] Methods section: while the framework is said to extend SMC-X while 'maintaining extreme scalability,' no specifics are given on how acceptance/rejection decisions, floating-point reductions, or inter-die synchronization are implemented on NPUs to avoid introducing bias or violating detailed balance, which is load-bearing for the unbiased-sampling claim.
Authors: We accept the referee’s observation that the Methods section lacked sufficient implementation detail. The original text emphasized the high-level abstraction and performance results. In the revised manuscript we have expanded the Methods section with three new paragraphs that describe: (1) the NPU kernel for batched Metropolis acceptance/rejection that re-uses the same random-number stream as the CPU reference, (2) the use of Kahan compensated summation for global energy reductions to bound floating-point bias, and (3) the inter-die synchronization protocol based on a deterministic all-reduce that guarantees identical acceptance decisions across dies. These additions preserve the decoupling of ML models while making the unbiased-sampling argument reproducible and verifiable. revision: yes
Circularity Check
No circularity detected in scaling or performance claims
full rationale
The paper reports empirical measurements of Monte Carlo simulation performance on AI accelerators, including a 4-trillion-atom run on 4096 NPU dies and scaling efficiencies. These are presented as observed hardware outcomes from the SMC-AI implementation rather than any derived predictions, fitted parameters, or self-referential equations. No load-bearing self-citations, ansatzes, or uniqueness theorems reduce the central results to inputs by construction; the framework description focuses on decoupling and portability without tautological reductions. The claims remain independently verifiable through replication on the described hardware.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The design process for google’s training chips: Tpuv2 and tpuv3,
T. Norrie, N. Patil, D. H. Yoon, G. Kurian, S. Li, J. Laudon, C. Young, N. Jouppi, and D. Patterson, “The design process for google’s training chips: Tpuv2 and tpuv3,”IEEE Micro, vol. 41, no. 2, pp. 56–63, 2021. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9351692
-
[2]
Serving large language models on huawei cloudmatrix384,
P. Zuo, H. Lin, J. Deng, N. Zou, X. Yang, Y . Diao, W. Gao, K. Xu, Z. Chen, S. Lu, Z. Qiu, P. Li, X. Chang, Z. Yu, F. Miao, J. Zheng, Y . Li, Y . Feng, B. Wang, Z. Zong, M. Zhou, W. Zhou, H. Chen, X. Liao, Y . Li, W. Zhang, P. Zhu, Y . Wang, C. Xiao, D. Liang, D. Cao, J. Liu, Y . Yang, X. Bai, Y . Li, H. Xie, H. Wu, Z. Yu, L. Chen, H. Liu, Y . Ding, H. Zh...
-
[3]
Breaking the molecular dynamics timescale barrier using a wafer-scale system,
K. Santos, S. Moore, T. Oppelstrup, A. Sharifian, I. Sharapov, A. Thompson, D. Z. Kalchev, D. Perez, R. Schreiber, S. Pakin, E. A. Leon, J. H. Laros, M. James, and S. Rajamanickam, “Breaking the molecular dynamics timescale barrier using a wafer-scale system,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysi...
-
[4]
Distributed training of large language models on aws trainium,
X. Fu, Z. Zhang, H. Fan, G. Huang, M. El-Shabani, R. Huang, R. Solanki, F. Wu, R. Diamant, and Y . Wang, “Distributed training of large language models on aws trainium,” inProceedings of the 2024 ACM Symposium on Cloud Computing, ser. SoCC ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 961–976. [Online]. Available: https://doi.org/...
-
[5]
First impressions of the sapphire rapids processor with hbm for scientific workloads,
E. Siegmann, R. J. Harrison, D. Carlson, S. Chheda, A. Curtis, F. Coskun, R. Gonzalez, D. Wood, and N. A. Simakov, “First impressions of the sapphire rapids processor with hbm for scientific workloads,”SN Computer Science, vol. 5, no. 5, p. 623, 2024. [Online]. Available: https://doi.org/10.1007/s42979-024-02958-3
-
[6]
Nvidia hopper h100 gpu: Scaling performance,
J. Choquette, “Nvidia hopper h100 gpu: Scaling performance,” IEEE Micro, vol. 43, no. 3, pp. 9–17, 2023. [Online]. Available: https://ieeexplore.ieee.org/document/10070122
-
[7]
The co-evolution of computational physics and high-performance computing,
J. Dongarra and D. Keyes, “The co-evolution of computational physics and high-performance computing,”Nature Reviews Physics, vol. 6, no. 10, pp. 621–627, 2024. [Online]. Available: https://doi.org/10.1038/s42254-024-00750-z
-
[8]
A generative model for inorganic materials design,
C. Zeni, R. Pinsler, D. Z ¨ugner, A. Fowler, M. Horton, X. Fu, Z. Wang, A. Shysheya, J. Crabb ´e, S. Ueda, R. Sordillo, L. Sun, J. Smith, B. Nguyen, H. Schulz, S. Lewis, C.-W. Huang, Z. Lu, Y . Zhou, H. Yang, H. Hao, J. Li, C. Yang, W. Li, R. Tomioka, and T. Xie, “A generative model for inorganic materials design,”Nature, 2025. [Online]. Available: https:...
-
[9]
Machine learning interatomic potentials at the centennial crossroads of quantum mechanics,
B. Kalita, H. Gokcan, and O. Isayev, “Machine learning interatomic potentials at the centennial crossroads of quantum mechanics,”Nature Computational Science, vol. 5, no. 12, pp. 1120–1132, 2025. [Online]. Available: https://doi.org/10.1038/s43588-025-00930-6
-
[10]
Roadmap for the development of machine learning-based interatomic potentials,
Y .-W. Zhang, V . Sorkin, Z. H. Aitken, A. Politano, J. Behler, A. P Thompson, T. W. Ko, S. P. Ong, O. Chalykh, D. Korogod, E. Podryabinkin, A. Shapeev, J. Li, Y . Mishin, Z. Pei, X. Liu, J. Kim, Y . Park, S. Hwang, S. Han, K. Sheriff, Y . Cao, and R. Freitas, “Roadmap for the development of machine learning-based interatomic potentials,”Modelling and Sim...
-
[11]
Discovery through the computational microscope,
E. H. Lee, J. Hsin, M. Sotomayor, G. Comellas, and K. Schulten, “Discovery through the computational microscope,”Structure, vol. 17, no. 10, pp. 1295–1306, 2025/08/14 2009. [Online]. Available: https://doi.org/10.1016/j.str.2009.09.001
-
[12]
R. O. Dror, R. M. Dirks, J. Grossman, H. Xu, and D. E. Shaw, “Biomolecular simulation: A computational microscope for molecular biology,”Annual Review of Biophysics, vol. 41, no. V olume 41, 2012, pp. 429–452, 2012. [Online]. Avail- able: https://www.annualreviews.org/content/journals/10.1146/annurev- biophys-042910-155245
-
[13]
F. Zhou, H. Chen, P. Xu, K. Yang, Z. Pei, and X. Liu, “Towards computational microscope of chemical order-disorder via ml-accelerated monte carlo simulation,” 2026. [Online]. Available: https://arxiv.org/abs/2603.21207
-
[14]
Scaling the leading accuracy of deep equivariant models to biomolecular simulations of realistic size,
B. Kozinsky, A. Musaelian, A. Johansson, and S. Batzner, “Scaling the leading accuracy of deep equivariant models to biomolecular simulations of realistic size,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’23. New York, NY , USA: Association for Computing Machinery,
-
[15]
Available: https://doi.org/10.1145/3581784.3627041
[Online]. Available: https://doi.org/10.1145/3581784.3627041
-
[16]
S. Yin, Y . Zuo, A. Abu-Odeh, H. Zheng, X.-G. Li, J. Ding, S. P. Ong, M. Asta, and R. O. Ritchie, “Atomistic simulations of dislocation mobility in refractory high-entropy alloys and the effect of chemical short-range order,”Nature Communications, vol. 12, p. 4873, 2021. [Online]. Available: https://doi.org/10.1038/s41467-021-25134-0
-
[17]
Mechanism on lattice thermal conductivity of carbon-vacancy and porous medium entropy ceramics,
X. Zhou, Y . Xu, Y . Chen, and F. Tian, “Mechanism on lattice thermal conductivity of carbon-vacancy and porous medium entropy ceramics,” Scripta Materialia, vol. 259, p. 116568, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1359646225000326
2025
-
[18]
K. Nguyen-Cong, J. T. Willman, S. G. Moore, A. B. Belonoshko, R. Gayatri, E. Weinberg, M. A. Wood, A. P. Thompson, and I. I. Oleynik, “Billion atom molecular dynamics simulations of carbon at extreme conditions and experimental time and length scales,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and A...
- [19]
-
[20]
Efficient molecular dynamics simulations with many-body potentials on graphics processing units,
Z. Fan, W. Chen, V . Vierimaa, and A. Harju, “Efficient molecular dynamics simulations with many-body potentials on graphics processing units,”Computer Physics Commu- nications, vol. 218, pp. 10–16, 2017. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0010465517301339
2017
-
[21]
X. Liu, K. Yang, Y . Liu, F. Zhou, D. Fan, Z. Pei, P. Xu, and Y . Tian, “Revealing nanostructures in high-entropy alloys via machine-learning accelerated scalable monte carlo simulation,” 2025. [Online]. Available: https://arxiv.org/abs/2503.12591
-
[22]
Smc-x: A distributed, scalable monte carlo simulation method for chemically complex alloys,
X. Liu, K. Yang, F. Zhou, and P. Xu, “Smc-x: A distributed, scalable monte carlo simulation method for chemically complex alloys,”Journal of Chemical Theory and Computation, vol. 21, no. 24, pp. 12 784–12 795, 12 2025. [Online]. Available: https://doi.org/10.1021/acs.jctc.5c01614
-
[23]
Scalable parallel monte carlo algorithm for atomistic simulations of precipitation in alloys,
B. Sadigh, P. Erhart, A. Stukowski, A. Caro, E. Martinez, and L. Zepeda-Ruiz, “Scalable parallel monte carlo algorithm for atomistic simulations of precipitation in alloys,”Physical Review B, vol. 85, no. 18, p. 184203, May 2012. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevB.85.184203
-
[24]
Andreas Bender, Nadine Schneider, Marwin Segler, W
S. Batzner, A. Musaelian, L. Sun, M. Geiger, J. P. Mailoa, M. Kornbluth, N. Molinari, T. E. Smidt, and B. Kozinsky, “E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials,” Nature Communications, vol. 13, no. 1, p. 2453, 2022. [Online]. Available: https://doi.org/10.1038/s41467-022-29939-5
-
[25]
A scalable method for ab initio computation of free energies in nanoscale systems,
M. Eisenbach, C.-G. Zhou, D. M. Nicholson, G. Brown, J. Larkin, and T. C. Schulthess, “A scalable method for ab initio computation of free energies in nanoscale systems,” inProceedings of the Conference on High Performance Computing Networking, Storage and Analysis, ser. SC ’09. New York, NY , USA: Association for Computing Machinery,
-
[26]
Available: https://doi.org/10.1145/1654059.1654125
[Online]. Available: https://doi.org/10.1145/1654059.1654125
-
[27]
Extending the limit of molecular dynamics with ab initio accuracy to 10 billion atoms,
Z. Guo, D. Lu, Y . Yan, S. Hu, R. Liu, G. Tan, N. Sun, W. Jiang, L. Liu, Y . Chen, L. Zhang, M. Chen, H. Wang, and W. Jia, “Extending the limit of molecular dynamics with ab initio accuracy to 10 billion atoms,” inProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’22. New York, NY , USA: Associati...
-
[28]
X. Wang, X. Meng, Z. Guo, M. Li, L. Liu, M. Li, Q. Xiao, T. Zhao, N. Sun, G. Tan, and W. Jia, “29-billion atoms molecular dynamics simulation with ab initio accuracy on 35 million cores of new sunway supercomputer,”IEEE Transactions on Computers, pp. 1–14, 2025. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/10880101
-
[29]
Tensormd: Molecular dynamics simulation with ab initio accuracy of 50 billion atoms,
Y . Ouyang, Y . Liu, H. Shang, Z. Chen, J. Shan, H. Cui, X. Feng, X. Chen, X. Gao, L. Wang, H. Song, X. Chen, R. Lin, and F. Li, “Tensormd: Molecular dynamics simulation with ab initio accuracy of 50 billion atoms,” inProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’25. New York, NY , USA...
-
[30]
General-purpose machine-learned potential for 16 elemental metals and their alloys,
K. Song, R. Zhao, J. Liu, Y . Wang, E. Lindgren, Y . Wang, S. Chen, K. Xu, T. Liang, P. Ying, N. Xu, Z. Zhao, J. Shi, J. Wang, S. Lyu, Z. Zeng, S. Liang, H. Dong, L. Sun, Y . Chen, Z. Zhang, W. Guo, P. Qian, J. Sun, P. Erhart, T. Ala-Nissila, Y . Su, and Z. Fan, “General-purpose machine-learned potential for 16 elemental metals and their alloys,”Nature Co...
-
[31]
Available: https://doi.org/10.1038/s41467-024-54554-x
[Online]. Available: https://doi.org/10.1038/s41467-024-54554-x
-
[32]
Gpu accelerated monte carlo simulation of the 2d and 3d ising model,
T. Preis, P. Virnau, W. Paul, and J. J. Schneider, “Gpu accelerated monte carlo simulation of the 2d and 3d ising model,”Journal of Computational Physics, vol. 228, no. 12, pp. 4468–4477, 2009. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0021999109001387
2009
-
[33]
High performance monte carlo simulation of ising model on tpu clusters,
K. Yang, Y .-F. Chen, G. Roumpos, C. Colby, and J. Anderson, “High performance monte carlo simulation of ising model on tpu clusters,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’19. New York, NY , USA: Association for Computing Machinery, 2019. [Online]. Available: https://doi.o...
-
[34]
High performance implementations of the 2d ising model on gpus,
J. Romero, M. Bisson, M. Fatica, and M. Bernaschi, “High performance implementations of the 2d ising model on gpus,”Computer Physics Communications, vol. 256, p. 107473, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0010465520302228
2020
-
[35]
Gpu-accelerated gibbs ensemble monte carlo simulations of lennard-jonesium,
J. Mick, E. Hailat, V . Russo, K. Rushaidat, L. Schwiebert, and J. Potoff, “Gpu-accelerated gibbs ensemble monte carlo simulations of lennard-jonesium,”Computer Physics Communications, vol. 184, no. 12, pp. 2662–2669, 2013. [Online]. Available: https://www.sciencedirect.com/science/article/abs/pii/S0010465513002270
2013
-
[36]
Lammps - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales,
A. P. Thompson, H. M. Aktulga, R. Berger, D. S. Bolintineanu, W. M. Brown, P. S. Crozier, P. J. in ’t Veld, A. Kohlmeyer, S. G. Moore, T. D. Nguyen, R. Shan, M. J. Stevens, J. Tranchida, C. Trott, and S. J. Plimpton, “Lammps - a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales,”Computer Physics Commu...
2022
-
[37]
Complex strengthening mechanisms in the NbMoTaW multi-principal element alloy,
X.-G. Li, C. Chen, H. Zheng, Y . Zuo, and S. P. Ong, “Complex strengthening mechanisms in the NbMoTaW multi-principal element alloy,”npj Computational Materials, vol. 6, no. 1, p. 70, 2020. [Online]. Available: https://doi.org/10.1038/s41524-020-0339-0
-
[38]
X. Liu, K. Yang, Y . Liu, F. Zhou, D. Fan, Z. Pei, P. Xu, and Y . Tian, “Revealing nanostructures in high-entropy alloys via machine-learning accelerated scalable monte carlo simulation,”npj Computational Materials, vol. 11, no. 1, p. 267, 2025. [Online]. Available: https://doi.org/10.1038/s41524-025-01762-8
-
[39]
Fastattention: Extend flashattention2 to npus and low-resource gpus,
H. Lin, X. Yu, K. Zhao, L. Hou, Z. Zhan, S. Kamenev, H. Bao, T. Hu, M. Wang, Q. Chang, S. Sui, W. Sun, J. Hu, J. Yao, Z. Yin, C. Qian, Y . Zhang, Y . Pan, Y . Yang, and W. Liu, “Fastattention: Extend flashattention2 to npus and low-resource gpus,” 2024. [Online]. Available: https://arxiv.org/abs/2410.16663
-
[40]
Huawei cloud model-as-a-service on the cloudmatrix384 superpod,
A. Xiao, B. He, B. Zhang, B. Huai, B. Wang, B. Wang, B. Xu, B. Hou, C. Yang, C. Liu, C. Cui, C. Zhu, C. Feng, D. Wang, D. Lin, D. Zhao, F. Zou, F. Wang, G. Zhang, G. Dan, G. Chen, G. Guan, G. Yang, H. Li, H. Zhu, H. Li, H. Feng, H. Huang, H. Xu, H. Ma, H. Fan, H. Liu, J. Li, J. Liu, J. Xu, J. Meng, J. Xin, J. Hu, J. Chen, L. Yu, L. Miao, L. Liu, L. Jing, ...
-
[41]
M. Eisenbach, Y . W. Li, X. Liu, O. K. Odbadrakh, Z. Pei, G. M. Stocks, and J. Yin, “Lsms,” 12 2017. [Online]. Available: https://www.osti.gov/biblio/1420087
-
[42]
Order-N multiple scattering approach to electronic structure calculations,
Y . Wang, G. M. Stocks, W. A. Shelton, D. M. C. Nicholson, Z. Szotek, and W. M. Temmerman, “Order-N multiple scattering approach to electronic structure calculations,”Phys. Rev. Lett., vol. 75, pp. 2867–2870, Oct 1995. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevLett.75.2867
-
[43]
Machine learning for high- entropy alloys: Progress, challenges and opportunities,
X. Liu, J. Zhang, and Z. Pei, “Machine learning for high- entropy alloys: Progress, challenges and opportunities,”Progress in Materials Science, vol. 131, p. 101018, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0079642522000998
2023
-
[44]
Multicomponent intermetallic nanoparticles and superb mechanical behaviors of complex alloys,
T. Yang, Y . L. Zhao, Y . Tong, Z. B. Jiao, J. Wei, J. X. Cai, X. D. Han, D. Chen, A. Hu, J. J. Kai, K. Lu, Y . Liu, and C. T. Liu, “Multicomponent intermetallic nanoparticles and superb mechanical behaviors of complex alloys,”Science, vol. 362, no. 6417, pp. 933–937, 2018. [Online]. Available: https://science.sciencemag.org/content/362/6417/933
2018
-
[45]
E. P. George, D. Raabe, and R. O. Ritchie, “High-entropy alloys,” Nature Reviews Materials, vol. 4, no. 8, pp. 515–534, 2019. [Online]. Available: https://doi.org/10.1038/s41578-019-0121-4
-
[46]
Machine- learning design of ductile fenicoalta alloys with high strength,
Y . Sohail, C. Zhang, D. Xue, J. Zhang, D. Zhang, S. Gao, Y . Yang, X. Fan, H. Zhang, G. Liu, J. Sun, and E. Ma, “Machine- learning design of ductile fenicoalta alloys with high strength,” Nature, vol. 643, no. 8070, pp. 119–124, 2025. [Online]. Available: https://doi.org/10.1038/s41586-025-09160-2
-
[47]
Bifunctional nanoprecipitates strengthen and ductilize a medium-entropy alloy,
Y . Yang, T. Chen, L. Tan, J. D. Poplawsky, K. An, Y . Wang, G. D. Samolyuk, K. Littrell, A. R. Lupini, A. Borisevich, and E. P. George, “Bifunctional nanoprecipitates strengthen and ductilize a medium-entropy alloy,”Nature, vol. 595, no. 7866, pp. 245–249, 2021. [Online]. Available: https://doi.org/10.1038/s41586-021-03607-y
-
[48]
Large scale hybrid monte carlo simulations for structure and property prediction,
S. Prokhorenko, K. Kalke, Y . Nahas, and L. Bellaiche, “Large scale hybrid monte carlo simulations for structure and property prediction,” npj Computational Materials, vol. 4, no. 1, p. 80, 2018. [Online]. Available: https://doi.org/10.1038/s41524-018-0137-0
-
[49]
Chatgpt,
OpenAI, “Chatgpt,” 2025, AI language assistant used for manuscript polishing
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.