Recognition: 2 theorem links
· Lean TheoremLeveraging Complementary Embeddings for Replay Selection in Continual Learning with Small Buffers
Pith reviewed 2026-05-10 17:44 UTC · model grok-4.3
The pith
A graph-based selector that fuses supervised and self-supervised embeddings improves replay quality for continual learning under tight memory limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
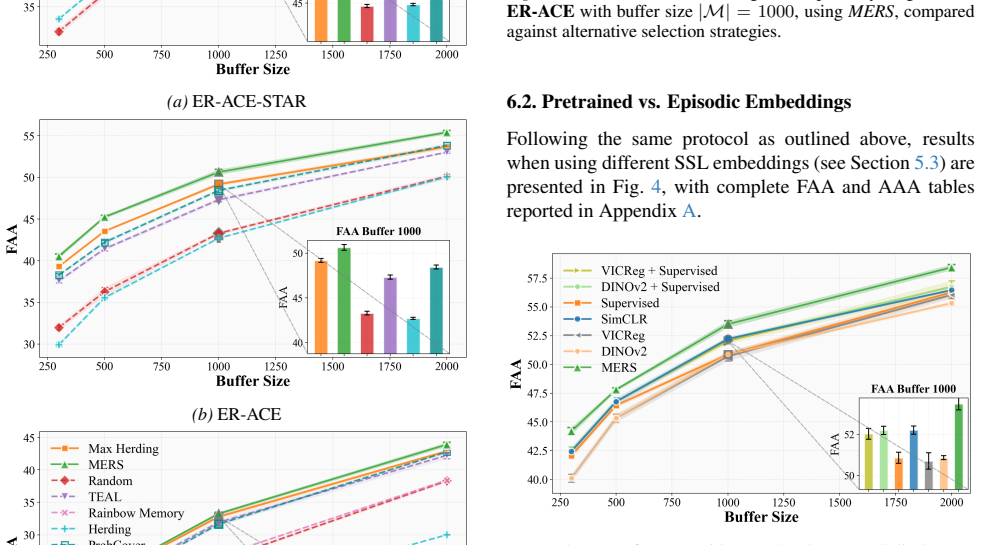
The authors introduce Multiple Embedding Replay Selection (MERS), a graph-based replay selection strategy that integrates both supervised and self-supervised embeddings to rank and retain samples for the memory buffer. They show that this integration produces consistent accuracy improvements over existing single-embedding selection baselines across multiple replay-based continual learning algorithms, with the largest relative gains occurring in low-memory regimes on CIFAR-100 and TinyImageNet.
What carries the argument
MERS, a graph-based selector that builds a unified representation from complementary supervised and self-supervised embeddings to decide which incoming samples to store in the replay buffer.
If this is right
- MERS functions as a drop-in module that can replace the selection component in many existing replay-based continual learning algorithms.
- Performance advantages grow as buffer size shrinks, making the approach especially relevant for edge or resource-limited deployments.
- No increase in stored parameters or replay volume is required, preserving the original memory footprint.
- The same dual-embedding graph construction can be applied to any dataset where both supervised labels and self-supervised pretraining are feasible.
Where Pith is reading between the lines
- The result implies that representation diversity itself, rather than any single embedding quality, may be the key lever for effective replay under extreme memory constraints.
- Similar fusion of multiple embedding sources could be tested in non-replay continual learning settings such as regularization-based or architecture-based methods.
- One could measure whether the benefit scales with the degree of semantic overlap between the supervised and self-supervised views on a given task sequence.
Load-bearing premise
Self-supervised representations encode class-relevant semantics that supervised embeddings overlook and that are useful for choosing good replay samples.
What would settle it
If MERS produces no statistically significant reduction in forgetting or increase in final accuracy compared with a strong single supervised-embedding baseline on TinyImageNet using a 200-sample buffer, the central claim would not hold.
Figures













read the original abstract
Catastrophic forgetting remains a key challenge in Continual Learning (CL). In replay-based CL with severe memory constraints, performance critically depends on the sample selection strategy for the replay buffer. Most existing approaches construct memory buffers using embeddings learned under supervised objectives. However, class-agnostic, self-supervised representations often encode rich, class-relevant semantics that are overlooked. We propose a new method, Multiple Embedding Replay Selection, MERS, which replaces the buffer selection module with a graph-based approach that integrates both supervised and self-supervised embeddings. Empirical results show consistent improvements over SOTA selection strategies across a range of continual learning algorithms, with particularly strong gains in low-memory regimes. On CIFAR-100 and TinyImageNet, MERS outperforms single-embedding baselines without adding model parameters or increasing replay volume, making it a practical, drop-in enhancement for replay-based continual learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Multiple Embedding Replay Selection (MERS), a graph-based replay buffer selection module for replay-based continual learning that integrates supervised and self-supervised embeddings. It claims this yields consistent improvements over SOTA selection strategies across CL algorithms, with particularly strong gains in low-memory regimes on CIFAR-100 and TinyImageNet, without adding parameters or increasing replay volume.
Significance. If the performance gains are shown to stem specifically from the complementarity of the two embedding types rather than the graph construction alone, the method would provide a practical, drop-in enhancement for memory-constrained continual learning. The evaluation on standard benchmarks and emphasis on low-buffer regimes addresses a relevant practical constraint in the field.
major comments (2)
- [§5] §5 (Experimental results): The central claim that gains derive from complementary supervised and self-supervised embeddings is not supported by ablations that fix the graph-based selection procedure and vary only the embedding sources (supervised-only graph, self-supervised-only graph, and combined). Without these controls, it remains possible that any sufficiently rich single embedding fed into the same graph module would produce similar results, directly weakening the load-bearing assumption stated in the abstract and introduction.
- [§4] §4 (Method): The description of the graph construction does not specify how the two embedding types are fused (e.g., joint node/edge features, separate graphs with combined scoring, or concatenation before distance computation). This detail is necessary to evaluate whether the reported improvements are reproducible and attributable to complementarity rather than implementation choices such as the distance metric.
minor comments (2)
- [Abstract] Abstract: Replace qualitative statements such as 'consistent improvements' and 'particularly strong gains' with specific quantitative deltas (e.g., average accuracy lift on CIFAR-100 at buffer size 500) to allow readers to assess effect sizes immediately.
- Figures: Ensure all plots include error bars or statistical significance markers when comparing MERS against baselines, and label the exact buffer sizes and CL algorithms used in each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which have identified key opportunities to strengthen the presentation of our core hypothesis and the reproducibility of the method. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§5] §5 (Experimental results): The central claim that gains derive from complementary supervised and self-supervised embeddings is not supported by ablations that fix the graph-based selection procedure and vary only the embedding sources (supervised-only graph, self-supervised-only graph, and combined). Without these controls, it remains possible that any sufficiently rich single embedding fed into the same graph module would produce similar results, directly weakening the load-bearing assumption stated in the abstract and introduction.
Authors: We agree that the requested ablations are necessary to rigorously support the claim of complementarity. In the revised manuscript we will add experiments that hold the graph construction and selection procedure fixed while varying only the embedding sources: supervised-only, self-supervised-only, and the combined embeddings used by MERS. These results will be reported in §5 under the same protocols and benchmarks as the main experiments. We believe the combined variant will demonstrate clear gains over the single-embedding graphs, thereby confirming that the observed improvements are attributable to the integration of complementary representations rather than the graph module alone. revision: yes
-
Referee: [§4] §4 (Method): The description of the graph construction does not specify how the two embedding types are fused (e.g., joint node/edge features, separate graphs with combined scoring, or concatenation before distance computation). This detail is necessary to evaluate whether the reported improvements are reproducible and attributable to complementarity rather than implementation choices such as the distance metric.
Authors: We apologize for the omission of these implementation details. The revised §4 will explicitly describe the fusion mechanism, including how the supervised and self-supervised embeddings are combined to form node features, the precise distance metric applied, and whether a single joint graph or multiple graphs are used. This clarification will enable full reproducibility and allow readers to assess whether the gains arise from complementarity or from other design choices. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical method (MERS) for replay buffer selection in continual learning by combining supervised and self-supervised embeddings in a graph-based module. No equations, derivations, fitted parameters, or predictions appear in the provided text. All claims rest on experimental comparisons against external SOTA baselines on standard datasets (CIFAR-100, TinyImageNet). No self-citations form load-bearing chains, no ansatzes are smuggled, and no results reduce to inputs by construction. The central performance gains are presented as measured outcomes rather than self-referential logic, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Class-agnostic, self-supervised representations often encode rich, class-relevant semantics that are overlooked by supervised embeddings.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
graph-based approach that integrates both supervised and self-supervised embeddings... weighted maximum k-coverage problem
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
non-parametric alignment strategy based on k-NN density estimation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2, 6 Fini, E., Turrisi da Costa, V
URLhttps://arxiv.org/abs/2503.01595. 2, 6 Fini, E., Turrisi da Costa, V . G., Alameda-Pineda, X., Ricci, E., Alahari, K., and Mairal, J. Self-supervised models are contin- ual learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2 Garreau, D., Jitkrittum, W., and Kanagawa, M. Large sam- ple analysis o...
-
[2]
16 Li, Z
See Proposition 4.5 for a supremum characterization of total variation. 16 Li, Z. and Hoiem, D. Learning without forgetting.IEEE trans- actions on pattern analysis and machine intelligence, 40(12): 2935–2947, 2017. 2 McCloskey, M. and Cohen, N. J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learni...
2017
-
[3]
Proceedings of the National Academy of Sciences117(40), 24652–24663 (2020)
Elsevier, 1989. 1 Nemhauser, G. L., Wolsey, L. A., and Fisher, M. L. An analysis of approximations for maximizing submodular set functions—i. Mathematical Programming, 14(1):265–294, 1978. 12 9 Leveraging Complementary Embeddings for Replay Selection in Continual Learning with Small Buffers Ni, Z., Tang, S., and Zhuang, Y . Self-supervised class increment...
-
[4]
and Isola, P
4 Wang, T. and Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InInternational conference on machine learning, pp. 9929–
-
[5]
Lifelong Learning with Dynamically Expandable Networks
PMLR, 2020. 14, 15 Welling, M. Herding dynamical weights to learn. InProceed- ings of the 26th annual international conference on machine learning, pp. 1121–1128, 2009. 6 Yehuda, O., Dekel, A., Hacohen, G., and Weinshall, D. Active learning through a covering lens.Advances in Neural Informa- tion Processing Systems, 35:22354–22367, 2022. 3, 10, 14 Yoon, J...
work page Pith review arXiv 2020
-
[6]
uniformity
ThusFis non-negative and normalized. Monotonicity.LetA⊆B⊆X. If an indexu∈Uis covered byA, i.e.,A∩C u ̸=∅, then sinceA⊆Bwe also haveB∩C u ̸=∅. Therefore, {u∈U:A∩C u ̸=∅} ⊆ {u∈U:B∩C u ̸=∅}, and by non-negativity of the weights, F(A) = X u:A∩Cu̸=∅ wu ≤ X u:B∩Cu̸=∅ wu =F(B). ThusFis monotone. Submodularity.To show submodularity, letA⊆B⊆ Xandx∈X\B. Consider th...
1978
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.