Bias-Constrained Diffusion Schedules for PDE Emulations: Reconstruction Error Minimization and Efficient Unrolled Training
Pith reviewed 2026-05-10 17:23 UTC · model grok-4.3
The pith
Adaptive noise schedules that constrain exposure bias cut reconstruction errors in diffusion PDE emulators and enable cheap unrolled training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
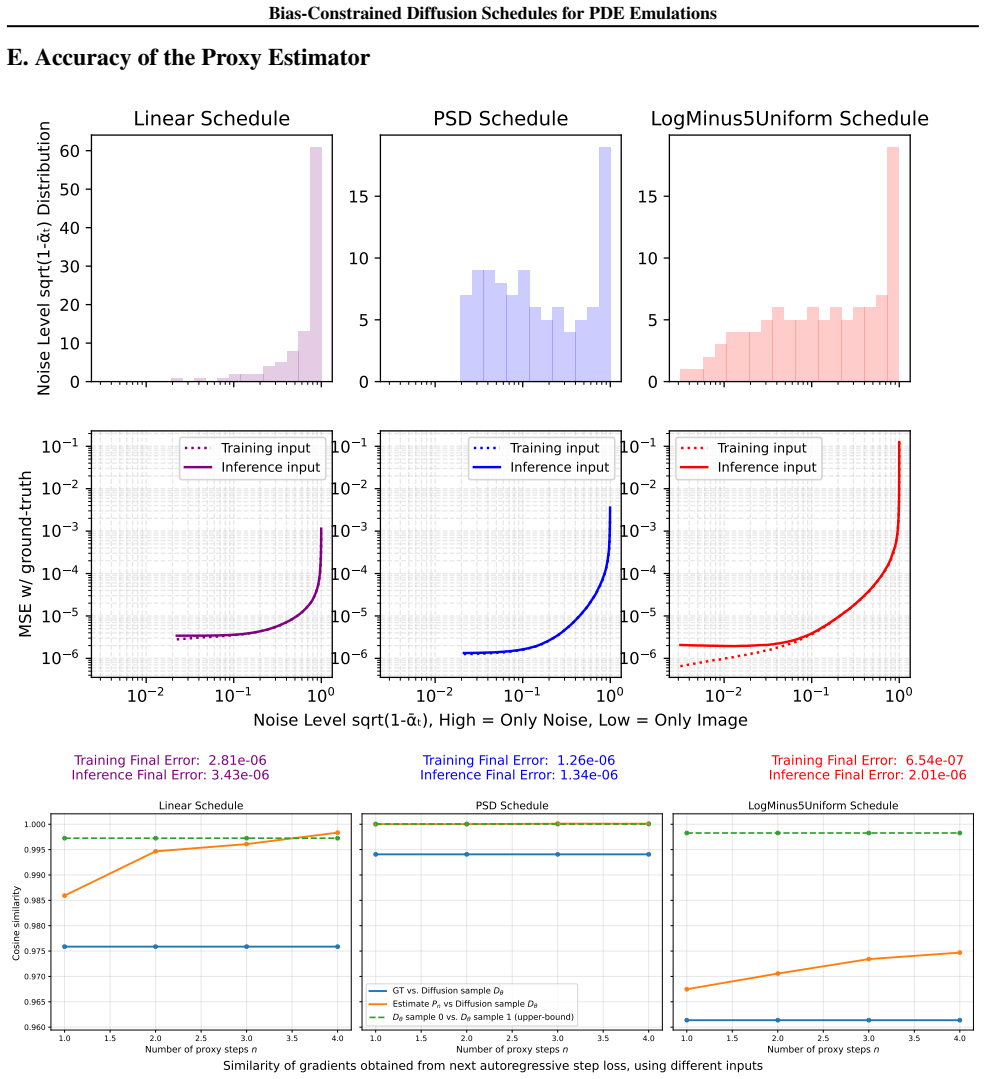
Standard diffusion schedules lead to suboptimal reconstruction error in PDE emulators because they fail to control diffusion exposure bias; an adaptive noise schedule that explicitly constrains this bias during training and inference reduces reconstruction error and, as a direct consequence, permits an efficient proxy unrolled training procedure that stabilizes long-term autoregressive rollouts without full-chain sampling cost.
What carries the argument
The Adaptive Noise Schedule framework, which dynamically adjusts the noise schedule to constrain the model's exposure bias and thereby minimizes reconstruction error.
If this is right
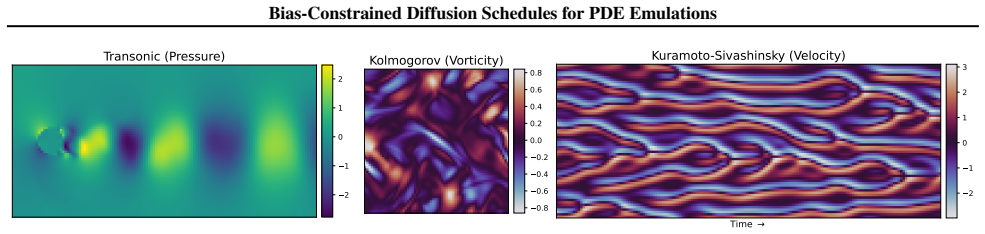
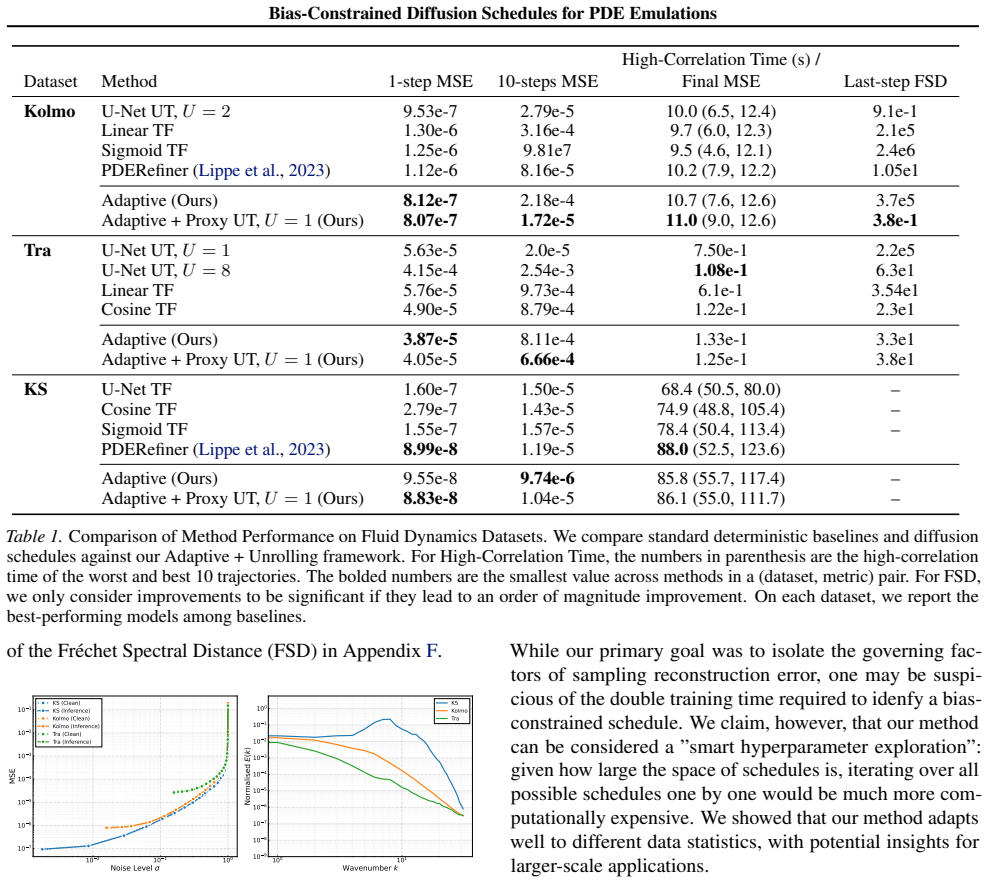
- Short-term single-step accuracy improves on forced Navier-Stokes, Kuramoto-Sivashinsky, and transonic-flow tasks relative to both diffusion and deterministic baselines.
- Long-term autoregressive rollouts become more stable without incurring the full computational cost of Markov-chain unrolled training.
- The same bias-constrained schedule yields a general method that transfers across distinct PDE families.
- High-precision spatiotemporal emulation tasks that previously favored deterministic networks can now use diffusion models without sacrificing accuracy.
Where Pith is reading between the lines
- If the bias-error relationship generalizes beyond the tested PDEs, the same schedule design could be ported to other autoregressive diffusion tasks such as video or weather prediction.
- The proxy unrolled training trick suggests that once a schedule is fixed, many other diffusion applications could adopt cheap stability training without full sampling.
- The work implies that exposure-bias control may be a missing ingredient in other conditional diffusion settings where deterministic baselines still dominate.
Load-bearing premise
The relationship between noise schedule, reconstruction error reduction rate, and diffusion exposure bias can be characterized and optimized to produce a general adaptive schedule that works across different PDEs without introducing new instabilities or excessive overhead.
What would settle it
If the adaptive schedule applied to an unseen PDE benchmark either fails to lower reconstruction error below standard schedules or produces training instabilities or excessive schedule-selection cost, the central claim is falsified.
Figures

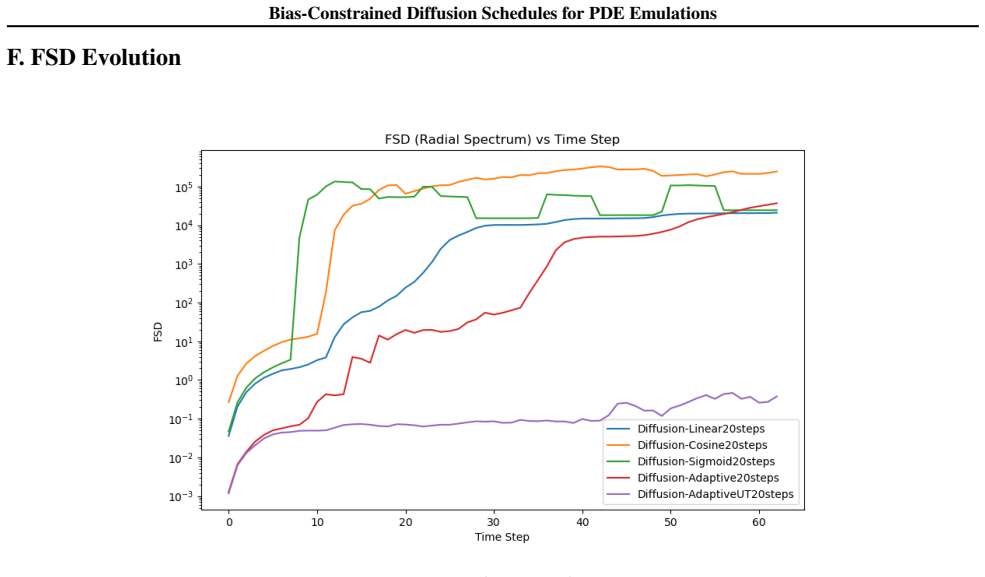
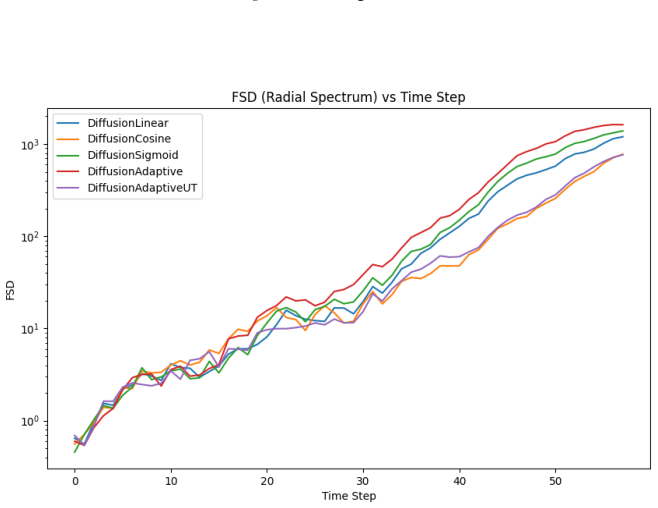
read the original abstract
Conditional Diffusion Models are powerful surrogates for emulating complex spatiotemporal dynamics, yet they often fail to match the accuracy of deterministic neural emulators for high-precision tasks. In this work, we address two critical limitations of autoregressive PDE diffusion models: their sub-optimal single-step accuracy and the prohibitive computational cost of unrolled training. First, we characterize the relationship between the noise schedule, the reconstruction error reduction rate and the diffusion exposure bias, demonstrating that standard schedules lead to suboptimal reconstruction error. Leveraging this insight, we propose an \textit{Adaptive Noise Schedule} framework that minimizes inference reconstruction error by dynamically constraining the model's exposure bias. We further show that this optimized schedule enables a fast \textit{Proxy Unrolled Training} method to stabilize long-term rollouts without the cost of full Markov Chain sampling. Both proposed methods enable significant improvements in short-term accuracy and long-term stability over diffusion and deterministic baselines on diverse benchmarks, including forced Navier-Stokes, Kuramoto-Sivashinsky and Transonic Flow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes characterizing the interplay between noise schedules, reconstruction error reduction rates, and diffusion exposure bias in conditional diffusion models for PDE emulation. It introduces an Adaptive Noise Schedule that dynamically constrains exposure bias to minimize inference-time reconstruction error, and shows that this schedule enables a Proxy Unrolled Training procedure for stabilizing long-term autoregressive rollouts at reduced computational cost compared to full Markov-chain sampling. The work reports significant gains in short-term accuracy and long-term stability over both standard diffusion models and deterministic neural emulators on forced Navier-Stokes, Kuramoto-Sivashinsky, and transonic flow benchmarks.
Significance. If the empirical claims hold under rigorous verification, the framework offers a principled route to close the accuracy gap between diffusion-based and deterministic PDE surrogates while mitigating the prohibitive cost of unrolled training. The bias-constrained schedule and proxy training could generalize across spatiotemporal systems and reduce reliance on hand-tuned diffusion hyperparameters, with potential impact on scientific machine learning applications requiring both precision and stability.
major comments (2)
- [Abstract and §4 (Experiments)] Abstract and experimental sections: the central claims of 'significant improvements' on three benchmarks rest on quantitative results, yet no error bars, statistical significance tests, exact optimization procedure for the bias-constraint parameters, or train/validation/test split details are provided. This prevents assessment of whether the reported gains are robust or could be artifacts of hyperparameter tuning on the evaluation data.
- [§3.3] Proxy Unrolled Training description (likely §3.3): the method assumes that single-step bias-constrained reconstruction error minimization transfers directly to multi-step rollout stability. If the proxy omits cumulative exposure bias accumulation over many steps, the reported long-term stability gains on Kuramoto-Sivashinsky and forced Navier-Stokes could be overstated; a concrete ablation comparing proxy versus full unrolled sampling on at least one benchmark is required to support the efficiency claim.
minor comments (2)
- [§2 and §3] Notation for the bias constraint and reconstruction error rate should be defined explicitly with equation numbers in the main text rather than relying on the abstract.
- [Figures 3-5] Figure captions for benchmark rollouts should include the exact number of steps, time horizon, and whether results are averaged over multiple initial conditions.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of experimental rigor and validation. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and experimental sections: the central claims of 'significant improvements' on three benchmarks rest on quantitative results, yet no error bars, statistical significance tests, exact optimization procedure for the bias-constraint parameters, or train/validation/test split details are provided. This prevents assessment of whether the reported gains are robust or could be artifacts of hyperparameter tuning on the evaluation data.
Authors: We agree that these details are necessary to substantiate the robustness of the reported improvements. In the revised manuscript, we will add error bars (standard deviation over 5 independent runs with different random seeds) to all quantitative results in §4 and the abstract summary. We will explicitly describe the train/validation/test splits (80/10/10 with temporal separation to avoid leakage) for each benchmark. The bias-constraint parameter optimization procedure will be detailed as a grid search over the validation set minimizing single-step reconstruction error (search range [0.05, 0.5] for the bias threshold). We will also include paired statistical significance tests (e.g., t-tests) comparing our method against baselines. These changes will clarify that gains are not artifacts of tuning. revision: yes
-
Referee: [§3.3] Proxy Unrolled Training description (likely §3.3): the method assumes that single-step bias-constrained reconstruction error minimization transfers directly to multi-step rollout stability. If the proxy omits cumulative exposure bias accumulation over many steps, the reported long-term stability gains on Kuramoto-Sivashinsky and forced Navier-Stokes could be overstated; a concrete ablation comparing proxy versus full unrolled sampling on at least one benchmark is required to support the efficiency claim.
Authors: We appreciate this observation on the transfer assumption. Section 3.3 provides a theoretical argument that per-step bias reduction limits cumulative error in rollouts, but we concur that direct empirical comparison is needed to fully support the long-term stability and efficiency claims. In the revision, we will add an ablation on the Kuramoto-Sivashinsky benchmark comparing proxy unrolled training against full Markov-chain unrolled sampling. This will report long-term rollout errors (up to 200 steps) and wall-clock training costs, confirming that the proxy achieves comparable stability at substantially lower cost. The results will be integrated into §4 to avoid overstating the benefits. revision: yes
Circularity Check
No circularity: derivation relies on independent characterization and empirical validation
full rationale
The paper first characterizes the relationship between noise schedule, reconstruction error reduction rate, and diffusion exposure bias (a modeling step independent of the final claims), then uses that characterization to define an adaptive schedule that constrains bias to minimize error. The proxy unrolled training is presented as a downstream efficiency technique enabled by the schedule. No equations reduce to self-definition, no fitted parameters are relabeled as predictions on the same data, and no load-bearing uniqueness theorems or ansatzes are imported via self-citation. All central claims are supported by direct comparisons against baselines on external PDE benchmarks (Navier-Stokes, Kuramoto-Sivashinsky, Transonic Flow), which serve as falsifiable external checks rather than internal fits.
Axiom & Free-Parameter Ledger
free parameters (1)
- bias constraint parameters
axioms (2)
- domain assumption Standard diffusion forward and reverse processes apply to conditional generation of spatiotemporal fields
- domain assumption Exposure bias in autoregressive rollouts can be quantified and bounded via the noise schedule
Reference graph
Works this paper leans on
-
[1]
+λ t · q REB(t+ 1)−ρ 2 2 + (1−ρ 2 2).(26) When ρ1, ρ2 ≈1 , the square-root terms simplify to B(2S)(t) and REB(t+ 1) respectively, recovering the statement above. Sampling definitions.Both inference and ground-truth paths follow one-step backward diffusion: ˆy(2S) t−1 = √¯αt−1 yest(˜yt) +σ t−1 ϵ,(27) ˆyt−1 = √¯αt−1 yest(ˆyt) +σ t−1 ϵ,(28) ˆyT ∼ N(0,I),(29)...
-
[2]
+λ t · q REB(t+ 1)−ρ 2 2 + (1−ρ 2 2)(45) 13 Bias-Constrained Diffusion Schedules for PDE Emulations B.1. Visualization 10−1 Noise Level σ 10−5 6×10−6 2×10−5 3×10−5 4×10−5 Reconstruction Error Input Type Clean input Inference input Own-Pred input Two-Steps input Figure 5.Contributions of errors to the REB.Metrics are reported for the final diffusion steps ...
-
[3]
(Own-Prediction Bias under Wiener denoiser structure.)Assuming that Jθ is diagonal in the Fourier basis with eigenvalueλ k = (√¯α/σ2)E θ(k)at each wavenumberk, then B(own) θ (σ)≈1 + 2¯α σ2 P k Eθ(k)2 P k Eθ(k) + ¯α σ2 2 P k Eθ(k)3 P k Eθ(k) .(46)
-
[4]
Then R(θA)≤R(θ B), and henceB (own) θA (σ)≤ B (own) θB (σ)
(Spectral bias implies bias reduction.)Suppose both models satisfy the Wiener structure of (1), that EB(k) is decreasing in k (larger residual errors at low wavenumbers), and that 0≤E A(k)≤E B(k) for all k with the ratio rk :=E A(k)/EB(k) non-decreasing in k (the relative error reduction is larger at low wavenumbers). Then R(θA)≤R(θ B), and henceB (own) θ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.