Recognition: 2 theorem links
· Lean TheoremLess Approximates More: Harmonizing Performance and Confidence Faithfulness via Hybrid Post-Training for High-Stakes Tasks
Pith reviewed 2026-05-10 18:28 UTC · model grok-4.3
The pith
A hybrid post-training method lets language models gain accuracy and honest confidence from mostly unlabeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
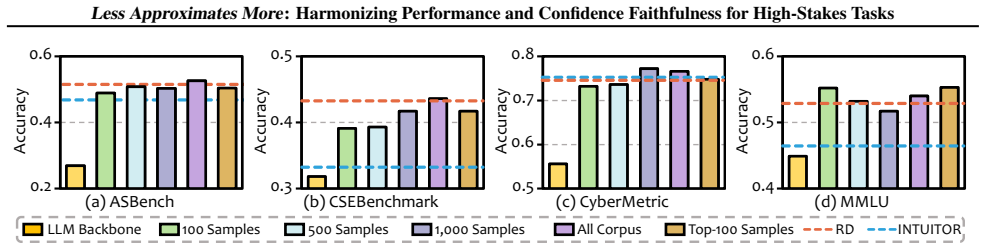
HyTuning is a hybrid post-training framework that adaptively reweights Reasoning Distillation and Reinforcement Learning from Internal Feedback using a Progressive Reasoning Gain metric. Scarce supervised reasoning traces act as a stable anchor while unlabeled queries supply scalability. Experiments on domain-specific and general benchmarks show that the method improves accuracy while producing confidence scores that better reflect actual correctness, supporting a practical 'Less Approximates More' effect.
What carries the argument
Progressive Reasoning Gain (PRG), a metric that assesses whether successive reasoning steps strengthen support for the final answer, used to adaptively balance supervised distillation against unsupervised internal feedback.
If this is right
- HyTuning improves accuracy on several domain-specific and general benchmarks.
- The method achieves confidence faithfulness under limited supervision.
- Scalability arises from exploiting abundant unlabeled queries alongside scarce labeled traces.
- The results support a practical 'Less Approximates More' effect in which reduced labeled data still yields stronger performance and faithfulness.
Where Pith is reading between the lines
- The same adaptive reweighting idea could be applied to other combinations of supervised and self-supervised signals in model alignment.
- Measuring how PRG correlates with external human judgments of reasoning quality would test whether the metric captures something beyond internal model statistics.
- Integrating the PRG weighting into the main training phase rather than only post-training might produce larger gains in faithfulness.
- The approach could be tested on models of varying sizes to check whether the limited-supervision benefit scales consistently.
Load-bearing premise
That the progressive reasoning gain metric can accurately reweight the two training signals without amplifying erroneous updates.
What would settle it
An experiment in which PRG-guided weighting increases the influence of RLIF on queries with flawed reasoning traces, yet overall accuracy or confidence faithfulness declines on held-out high-stakes test sets.
Figures





read the original abstract
Large language models are increasingly deployed in high-stakes tasks, where confident yet incorrect inferences may cause severe real-world harm, bringing the previously overlooked issue of confidence faithfulness back to the forefront. A promising solution is to jointly optimize unsupervised Reinforcement Learning from Internal Feedback (RLIF) with reasoning-trace-guided Reasoning Distillation (RD), which may face three persistent challenges: scarcity of high-quality training corpora, factually unwarranted overconfidence and indiscriminate fusion that amplifies erroneous updates. Inspired by the human confidence accumulation from uncertainty to certainty, we propose Progressive Reasoning Gain (PRG) to measure whether reasoning steps progressively strengthen support for the final answer. Furthermore, we introduce HyTuning, a hybrid post-training framework that adaptively reweights RD and RLIF via a PRG-style metric, using scarce supervised reasoning traces as a stable anchor while exploiting abundant unlabeled queries for scalability. Experiments on several domain-specific and general benchmarks demonstrate that HyTuning improves accuracy while achieving confidence faithfulness under limited supervision, supporting a practical "Less Approximates More" effect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Progressive Reasoning Gain (PRG) to quantify whether individual reasoning steps progressively strengthen support for the final answer. It proposes HyTuning, a hybrid post-training framework that uses a PRG-style metric to adaptively reweight Reasoning Distillation (RD) and Reinforcement Learning from Internal Feedback (RLIF). Scarce supervised reasoning traces serve as an anchor while abundant unlabeled queries enable scalability. Experiments on domain-specific and general benchmarks are reported to improve both accuracy and confidence faithfulness under limited supervision, supporting a practical 'Less Approximates More' effect for high-stakes LLM deployment.
Significance. If the central claims hold, the work addresses a practically important gap in deploying LLMs for high-stakes tasks by jointly optimizing performance and confidence faithfulness with minimal supervision. The hybrid RD+RLIF approach with PRG-guided reweighting could offer a scalable alternative to purely supervised or purely unsupervised post-training. The introduction of PRG as a progressive-support metric is a potentially useful conceptual contribution if it can be shown to correlate with ground-truth correctness rather than model confidence.
major comments (2)
- [Abstract] Abstract: The central experimental claim—that HyTuning improves accuracy while achieving confidence faithfulness—is stated without any quantitative results, baseline comparisons, specific benchmarks, confidence-faithfulness metrics, controls for error amplification, or statistical analysis. This absence prevents verification that the data support the 'Less Approximates More' conclusion or that PRG successfully prevents amplification of erroneous RLIF updates on unlabeled data.
- [Abstract] The PRG metric is load-bearing for the hybrid reweighting mechanism, yet its precise definition, computation on unlabeled queries, and proof that it distinguishes progressive correctness from mere confidence alignment are not supplied. If PRG correlates with model confidence rather than ground-truth support (as the skeptic concern notes), the adaptive reweighting could still favor overconfident incorrect paths, undermining the claim that scarce supervised traces stably anchor the process.
minor comments (1)
- [Abstract] The abstract introduces several new terms (PRG, HyTuning, RD, RLIF) without a brief parenthetical gloss or forward reference to their formal definitions, which reduces immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central experimental claim—that HyTuning improves accuracy while achieving confidence faithfulness—is stated without any quantitative results, baseline comparisons, specific benchmarks, confidence-faithfulness metrics, controls for error amplification, or statistical analysis. This absence prevents verification that the data support the 'Less Approximates More' conclusion or that PRG successfully prevents amplification of erroneous RLIF updates on unlabeled data.
Authors: We agree that the abstract, in its current form, is too high-level to convey the strength of the empirical support. The full manuscript reports results on multiple domain-specific and general benchmarks with comparisons to baselines, using metrics such as accuracy and expected calibration error for faithfulness, along with controls and statistical tests in the experiments section. In the revised version we will incorporate concise quantitative highlights (e.g., accuracy and faithfulness gains) and a brief mention of the evaluation protocol into the abstract while preserving its length constraints. This change will make the central claims more verifiable from the abstract alone. revision: yes
-
Referee: [Abstract] The PRG metric is load-bearing for the hybrid reweighting mechanism, yet its precise definition, computation on unlabeled queries, and proof that it distinguishes progressive correctness from mere confidence alignment are not supplied. If PRG correlates with model confidence rather than ground-truth support (as the skeptic concern notes), the adaptive reweighting could still favor overconfident incorrect paths, undermining the claim that scarce supervised traces stably anchor the process.
Authors: Section 3.1 of the manuscript defines PRG as the cumulative increase in internal model support for the final answer across successive reasoning steps; on unlabeled data it is computed from the model's own token-level probabilities without external labels. Empirical analysis in Section 4.3 demonstrates that PRG exhibits stronger correlation with ground-truth correctness than raw confidence on held-out sets, and the hybrid framework uses scarce supervised traces as an explicit anchor to limit error amplification. We will add a one-sentence definition and computation note to the abstract. We acknowledge that a formal proof of the distinction is not provided; the support remains empirical, which we will state more explicitly in the revised discussion. revision: partial
Circularity Check
No circularity: proposed PRG metric and HyTuning framework are self-contained without reductions to fitted inputs or self-citations
full rationale
The abstract introduces Progressive Reasoning Gain (PRG) as a new measure of progressive support strengthening and HyTuning as an adaptive reweighting framework anchored by scarce supervised traces, with no equations, derivations, or parameter-fitting steps shown. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to justify core components. The central claim rests on experimental outcomes rather than any definitional equivalence or fitted-input prediction, making the derivation chain independent and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning steps can be quantitatively measured for progressive strengthening of support toward the final answer
invented entities (2)
-
Progressive Reasoning Gain (PRG)
no independent evidence
-
HyTuning hybrid framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Progressive Reasoning Gain (PRG) ... P=1/T ∑ ReLU(log p_πθ(y|q,o≤t) - log p_πθ(y|q,o≤t-1)) ... Ps=α·(1-exp(-τ·P)) ... hybrid objective L = -Ps·J_RLIF - (1-Ps)·J_RD
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HyTuning ... using scarce supervised reasoning traces as a stable anchor while exploiting abundant unlabeled queries
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=5TEjuCm91H. under review. Bengio, Y ., Cohen, M., Fornasiere, D., Ghosn, J., Greiner, P., MacDermott, M., Mindermann, S., Oberman, A., Richardson, J., Richardson, O., et al. Superintelligent agents pose catastrophic risks: Can scientist ai offer a safer path?arXiv preprint arXiv:2502.15657, 2025. Chu, T., Zhai, Y ., Ya...
-
[2]
Maintain the same overall structure, schema, and output format as the few-shot examples
-
[3]
Keep field names identical and values consistent with the type of data shown in the examples
-
[4]
- Use real-looking CWEs (e.g
Ensure all generated data is realistic and domain-accurate: - Use valid CVSS scores and components. - Use real-looking CWEs (e.g. CWE-79, CWE-89) and MITRE techniques (e.g. T1059, T1204). - Use plausible cybersecurity contexts, scenarios, or vulnerabilities
-
[5]
Create entirely new but believable samples
Do NOT copy or rephrase the few-shot examples. Create entirely new but believable samples
-
[6]
Do NOT include the answer, label, output or solution for each data sample
-
[7]
- CVSS metrics should make sense
Maintain internal consistency: - If the CWE corresponds to a certain vulnerability type, ensure the description aligns with it. - CVSS metrics should make sense
-
[8]
- Vary topics, severities, and threat types
Ensure task diversity: - Include multiple task types (CWE mapping, CVSS scoring, MCQs, MITRE mappings) in the new samples. - Vary topics, severities, and threat types
-
[9]
20 Less Approximates More: Harmonizing Performance and Confidence Faithfulness for High-Stakes Tasks Box 5: Prompt template forevaluating the reasoning quality of reasoning traces
Output formatting: - Each generated data sample MUST have their task_type clearly stated at the beginning of the sample: task_type: (cwe_map OR calc_cvss OR mcq OR mitre_map) - Each generated data sample MUST be clearly separated by delimiter lines: ===== SAMPLE BEGIN ===== ===== SAMPLE END ===== Few-shot examples: {Few_Shot_Examples} Task: Generate 10 ne...
-
[10]
Citation: A direct restatement, paraphrase, or summary of information explicitly stated in the question, answer options, or well-known definitions, without generating new reasoning or conclusions
-
[11]
Repetition: A repetition of previous thinking processes, without providing new information, or advancing the reasoning process
-
[12]
Reasoning: Providing information beyond what is known, or deriving new conclusions from known information, or proposing new possibilities, which moves the thinking process towards the correct answer and has a direct or indirect effect on the final reasoning goal
-
[13]
Citation | Repetition | Reasoning | Redundancy
Redundancy: Providing new information or possibilities that do not help in reaching the final answer and do not advance the reasoning process. # Note When determining the type, carefully consider: - The logical relationship between the current reasoning segment and the question - Whether the segment advances, supports, or justifies the final answer - Whet...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.