Recognition: unknown
Wireless Communication Enhanced Value Decomposition for Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-10 16:56 UTC · model grok-4.3
The pith
Conditioning the value mixer on the realized wireless communication graph improves multi-agent value decomposition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
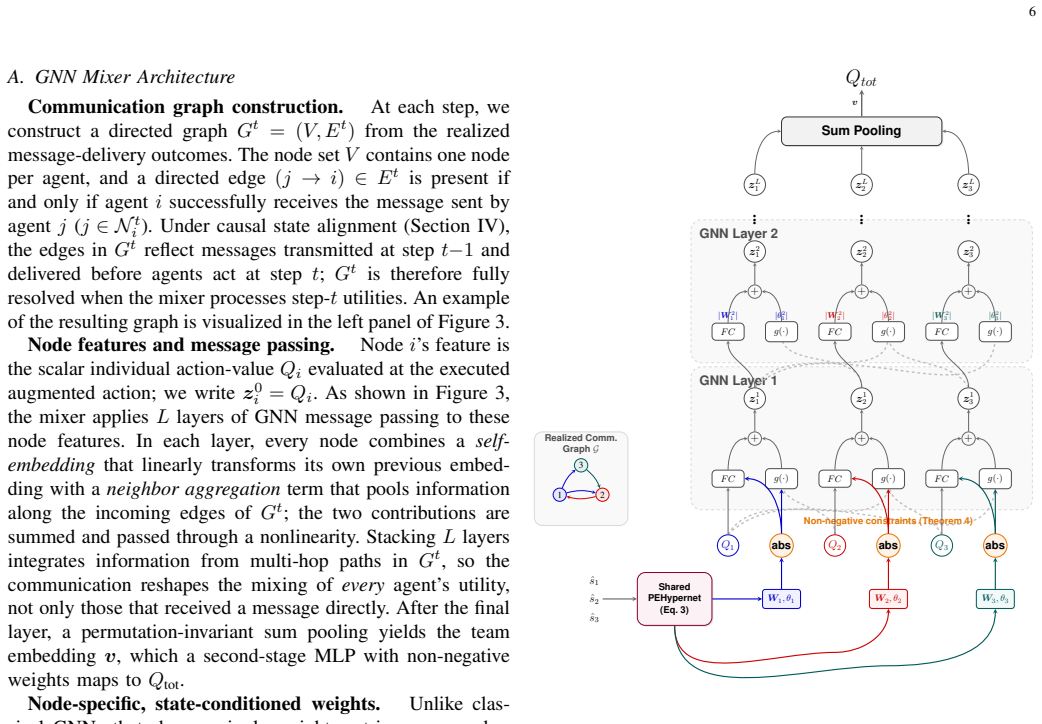
The central claim is that a communication-graph-conditioned value mixer, realized as a GNN whose node-specific weights are generated by a permutation-equivariant hypernetwork, reshapes credit assignment according to the realized wireless topology. Multi-hop propagation along communication edges lets different graphs induce different mixing functions. The mixer is proven permutation invariant, monotonic (hence IGM-preserving), and strictly more expressive than QMIX-style mixers. An augmented MDP plus stochastic receptive field encoder isolates stochastic channel effects from the agent computation graph, enabling training that yields adaptive signaling and listening behaviors and consistent, 0
What carries the argument
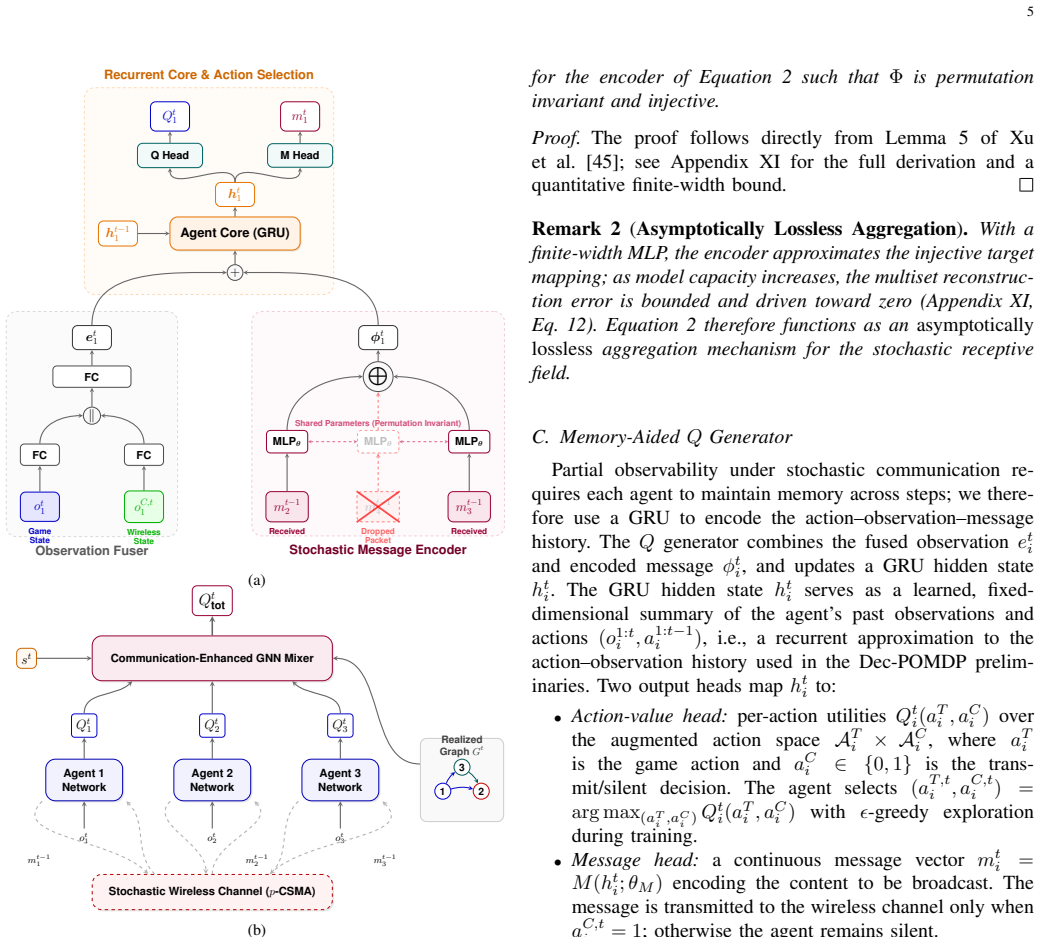
A GNN value mixer whose node-specific weights are produced by a permutation-equivariant hypernetwork and that is conditioned on the realized communication graph under the wireless channel.
If this is right
- The mixer remains monotonic and therefore compatible with IGM while representing strictly more functions than QMIX-style mixers.
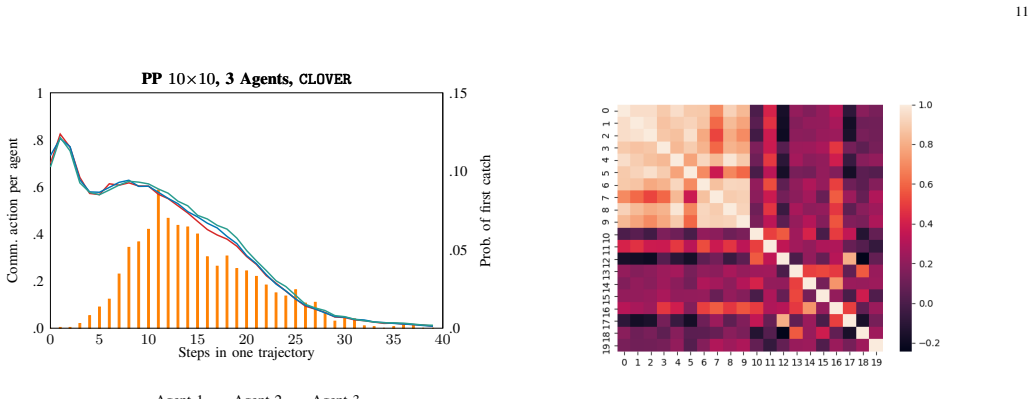
- Agents learn adaptive signaling and listening strategies that respond to the stochastic communication structure.
- End-to-end training stays differentiable through the stochastic receptive field encoder despite variable message sets.
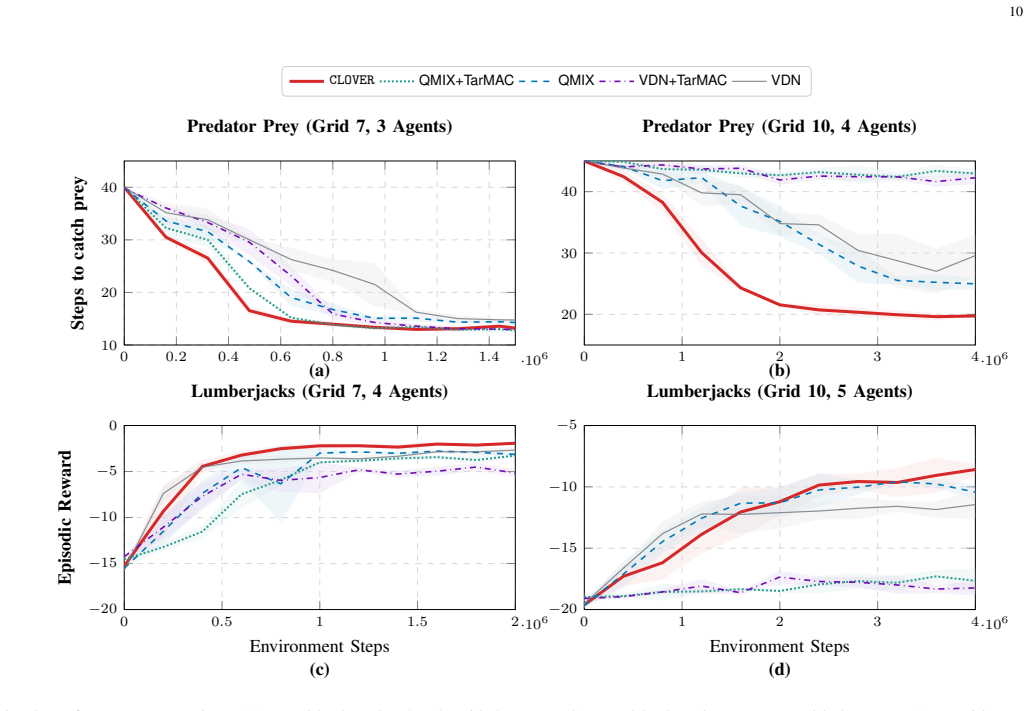
- Consistent gains appear in both convergence speed and final performance on Predator-Prey and Lumberjacks under p-CSMA relative to VDN, QMIX, and TarMAC hybrids.
Where Pith is reading between the lines
- The same graph-conditioning idea could be tested on other channel models such as Rayleigh fading if graph estimation accuracy is maintained.
- The relational bias may help credit assignment in larger agent teams where partial observability is more severe.
- Ablations already isolate the graph input as the main source of gain, suggesting the mechanism is largely independent of the particular hypernetwork design.
Load-bearing premise
The centralized mixer can be conditioned on an accurately observed or estimated communication graph at training time and the augmented MDP fully isolates stochastic channel effects without introducing unmodeled dependencies.
What would settle it
An ablation that removes the communication-graph input to the mixer while keeping every other component fixed and still observes identical convergence speed and final performance on the Predator-Prey benchmark under p-CSMA would falsify the claim that the graph supplies the key inductive bias.
Figures



read the original abstract
Cooperation in multi-agent reinforcement learning (MARL) benefits from inter-agent communication, yet most approaches assume idealized channels and existing value decomposition methods ignore who successfully shared information with whom. We propose CLOVER, a cooperative MARL framework whose centralized value mixer is conditioned on the communication graph realized under a realistic wireless channel. This graph introduces a relational inductive bias into value decomposition, constraining how individual utilities are mixed based on the realized communication structure. The mixer is a GNN with node-specific weights generated by a Permutation-Equivariant Hypernetwork: multi-hop propagation along communication edges reshapes credit assignment so that different topologies induce different mixing. We prove this mixer is permutation invariant, monotonic (preserving the IGM condition), and strictly more expressive than QMIX-style mixers. To handle realistic channels, we formulate an augmented MDP isolating stochastic channel effects from the agent computation graph, and employ a stochastic receptive field encoder for variable-size message sets, enabling end-to-end differentiable training. On Predator-Prey and Lumberjacks benchmarks under p-CSMA wireless channels, CLOVER consistently improves convergence speed and final performance over VDN, QMIX, TarMAC+VDN, and TarMAC+QMIX. Behavioral analysis confirms agents learn adaptive signaling and listening strategies, and ablations isolate the communication-graph inductive bias as the key source of improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CLOVER, a cooperative MARL framework that conditions a centralized value mixer on the realized communication graph under realistic p-CSMA wireless channels. The mixer is implemented as a GNN whose node weights are generated by a permutation-equivariant hypernetwork, introducing a relational inductive bias that reshapes credit assignment according to topology. The authors claim to prove that this mixer is permutation invariant, monotonic (preserving the IGM condition), and strictly more expressive than QMIX-style mixers. They introduce an augmented MDP to isolate stochastic channel effects and use a stochastic receptive field encoder for variable message sets, enabling end-to-end training. Empirical results on Predator-Prey and Lumberjacks benchmarks show faster convergence and higher performance than VDN, QMIX, TarMAC+VDN, and TarMAC+QMIX, with ablations attributing gains to the graph-conditioned bias.
Significance. If the proofs of invariance, monotonicity, and expressiveness hold and the augmented MDP successfully isolates channel stochasticity, the work provides a principled way to embed realistic communication constraints into value decomposition without violating IGM. The explicit theoretical guarantees, the use of permutation-equivariant hypernetworks for topology-dependent mixing, and the ablations isolating the communication-graph inductive bias are clear strengths. The benchmark results under p-CSMA channels offer concrete, falsifiable predictions for wireless MARL.
major comments (2)
- [§3 (Augmented MDP and graph observation)] §3 (Augmented MDP and graph observation): The central claim that end-to-end training remains valid rests on the augmented MDP isolating stochastic p-CSMA effects from the agent computation graph. This formulation assumes the realized communication graph is accurately observed or estimated at training time so that the GNN mixer receives the exact topology used in the expressiveness and monotonicity proofs. In p-CSMA, collisions or delayed ACKs can produce missing edges or noisy graphs; the manuscript provides no robustness analysis or experiments with imperfect graph inputs. If such noise is present, the inductive bias used to prove IGM preservation and strict expressiveness is violated, and the learned mixer may offer no advantage over a standard QMIX hypernetwork.
- [Proof of strict expressiveness (likely §4)] Proof of strict expressiveness (likely §4): The claim that the GNN mixer is 'strictly more expressive than QMIX-style mixers' is load-bearing for the novelty argument. The proof must exhibit a concrete mixing function that the permutation-equivariant hypernetwork can represent but a QMIX hypernetwork cannot, under identical monotonicity constraints. If the hypernetwork reduces to a standard one when the graph is complete or empty, the strictness may hold only conditionally rather than universally.
minor comments (2)
- [Abstract and §5] Abstract and §5: The behavioral analysis states that agents learn 'adaptive signaling and listening strategies,' yet no quantitative metrics (e.g., message entropy, listening rates per topology) or figure references are provided in the summary. Adding these would strengthen the claim.
- [Notation] Notation: The stochastic receptive field encoder for variable-size message sets is described at a high level; a short pseudocode block or diagram would clarify how messages are aggregated before the GNN update.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments highlight important assumptions in the augmented MDP and the need for clarity in the expressiveness proof. We address each point below with references to the relevant sections, providing clarifications and noting where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: §3 (Augmented MDP and graph observation): The central claim that end-to-end training remains valid rests on the augmented MDP isolating stochastic p-CSMA effects from the agent computation graph. This formulation assumes the realized communication graph is accurately observed or estimated at training time so that the GNN mixer receives the exact topology used in the expressiveness and monotonicity proofs. In p-CSMA, collisions or delayed ACKs can produce missing edges or noisy graphs; the manuscript provides no robustness analysis or experiments with imperfect graph inputs. If such noise is present, the inductive bias used to prove IGM preservation and strict expressiveness is violated, and the learned mixer may offer no advantage over a standard QMIX hypernetwork.
Authors: The augmented MDP in Section 3 explicitly includes the realized communication graph as part of the observable state for the central mixer, with stochastic channel effects (collisions, etc.) isolated in the transition dynamics. This setup ensures that the GNN receives the exact topology at training time under the model assumptions, preserving the conditions for the IGM and expressiveness proofs. We agree that real-world p-CSMA implementations may yield noisy or incomplete graphs due to ACK failures. The current work focuses on establishing the core theoretical framework under perfect observation; we will add a limitations paragraph in the revised manuscript discussing this assumption and outlining future directions such as robust GNN variants or graph imputation, without altering the main claims. revision: partial
-
Referee: Proof of strict expressiveness (likely §4): The claim that the GNN mixer is 'strictly more expressive than QMIX-style mixers' is load-bearing for the novelty argument. The proof must exhibit a concrete mixing function that the permutation-equivariant hypernetwork can represent but a QMIX hypernetwork cannot, under identical monotonicity constraints. If the hypernetwork reduces to a standard one when the graph is complete or empty, the strictness may hold only conditionally rather than universally.
Authors: Section 4 proves strict expressiveness by constructing an explicit monotonic mixing function f that conditions the aggregation weights on the presence or absence of a specific directed edge in the communication graph. This function cannot be represented by any QMIX-style hypernetwork, which lacks graph input and thus cannot differentiate mixing based on topology. The proof proceeds via a counterexample: consider two agents whose utilities are combined differently when they share a direct link versus when they do not, while satisfying monotonicity in each case. When the graph is complete, our hypernetwork can recover QMIX behavior by equivariance, but the class of representable functions is strictly larger because it includes all graph-conditioned monotonic mixers. The strict inclusion holds universally over the space of possible graphs, not conditionally. revision: no
Circularity Check
No significant circularity; claims rest on explicit proofs and external benchmarks.
full rationale
The paper defines a GNN-based mixer conditioned on the realized communication graph, proves its permutation invariance, monotonicity (IGM preservation), and strict expressiveness advantage over QMIX-style mixers via direct mathematical arguments, introduces an augmented MDP to separate channel stochasticity, and reports empirical gains on standard benchmarks against baselines. None of these steps reduce by construction to fitted parameters renamed as predictions, self-citations that bear the central load, or ansatzes smuggled in without independent justification. The proofs and benchmark comparisons are presented as verifiable external content rather than tautological restatements of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The IGM condition must be preserved by the mixer
Reference graph
Works this paper leans on
-
[1]
Learning to communicate with deep multi-agent reinforcement learning,
J. Foerster, Y . M. Assael, N. de Freitas, and S. Whiteson, “Learning to communicate with deep multi-agent reinforcement learning,” in Advances in Neural Information Processing Systems, 2016
2016
-
[2]
Tarmac: Targeted multi-agent communication,
A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “Tarmac: Targeted multi-agent communication,” inInterna- tional Conference on Machine Learning, 2019
2019
-
[3]
Collaborative multi-robot systems for search and rescue: Coordination and perception,
J. P. Queralta, J. Taipalmaa, B. C. Pullinen, V . K. Sarker, T. N. Gia, H. Tenhunen, M. Gabbouj, J. Raitoharju, and T. Westerlund, “Collaborative multi-robot systems for search and rescue: Coordination and perception,”arXiv:2008.12610, 2020
-
[4]
Distributed deep reinforcement learn- ing for fighting forest fires with a network of aerial robots,
R. N. Haksar and M. Schwager, “Distributed deep reinforcement learn- ing for fighting forest fires with a network of aerial robots,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2018
2018
-
[5]
Value- decomposition networks for cooperative multi-agent learning,
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V . Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Leibo, K. Tuylset al., “Value- decomposition networks for cooperative multi-agent learning,”Interna- tional Conference on Autonomous Agents and MultiAgent Systems, 2017
2017
-
[6]
Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. de Witt, G. Farquhar, J. N. Foerster, and S. Whiteson, “Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning,” inInternational Conference on Machine Learning, 2018
2018
-
[7]
Learning to schedule communication in multi-agent reinforcement learning,
D. Kim, S. Moon, D. Hostallero, W. J. Kang, T. Lee, K. Son, and Y . Yi, “Learning to schedule communication in multi-agent reinforcement learning,” inInternational Conference on Learning Representations, 2019
2019
-
[8]
Efficient communication in multi- agent reinforcement learning via variance based control,
S. Q. Zhang, Q. Zhang, and J. Lin, “Efficient communication in multi- agent reinforcement learning via variance based control,” inAdvances in Neural Information Processing Systems, 2019. 16
2019
-
[9]
R-maddpg for partially observable environments and limited communication,
R. E. Wang, M. Everett, and J. P. How, “R-maddpg for partially observable environments and limited communication,”International Conference on Machine Learning, 2020
2020
-
[10]
Learning implicit credit assignment for cooperative multi-agent reinforcement learning,
M. Zhou, Z. Liu, P. Sui, Y . Li, and Y . Y . Chung, “Learning implicit credit assignment for cooperative multi-agent reinforcement learning,”Ad- vances in Neural Information Processing Systems, vol. 33, pp. 11 853– 11 864, 2020
2020
-
[11]
Learning practical communication strategies in cooperative multi-agent reinforcement learning,
D. Hu, C. Zhang, V . Prasanna, and B. Krishnamachari, “Learning practical communication strategies in cooperative multi-agent reinforcement learning,” inProceedings of The 14th Asian Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 189. PMLR, 2023, pp. 467–482. [Online]. Available: https://proceedings.mlr.press/v189/hu23a.html
2023
-
[12]
Mobile ad hoc network overview,
D. P. I. I. Ismail and M. H. F. Ja’afar, “Mobile ad hoc network overview,” inAsia-Pacific Conference on Applied Electromagnetics, 2007
2007
-
[13]
The saturation throughput region of p-persistent csma,
Y . Gai, S. Ganesan, and B. Krishnamachari, “The saturation throughput region of p-persistent csma,” inInformation Theory and Applications Workshop. IEEE, 2011
2011
-
[14]
Learning multiagent com- munication with backpropagation,
S. Sukhbaatar, a. szlam, and R. Fergus, “Learning multiagent com- munication with backpropagation,” inAdvances in Neural Information Processing Systems, 2016
2016
-
[15]
P. Peng, Q. Yuan, Y . Wen, Y . Yang, Z. Tang, H. Long, and J. Wang, “Multiagent bidirectionally-coordinated nets for learning to play starcraft combat games,”arXiv:1703.10069, 2017
-
[16]
Multi-agent graph-attention communication and teaming,
Y . Niu, R. Paleja, and M. Gombolay, “Multi-agent graph-attention communication and teaming,” inProceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, 2021
2021
-
[17]
A survey of multi-agent deep reinforcement learning with communication,
C. Zhu, M. Dastani, and S. Wang, “A survey of multi-agent deep reinforcement learning with communication,”Autonomous Agents and Multi-Agent Systems, vol. 38, no. 1, 2024
2024
-
[18]
Robust and efficient communication in multi-agent reinforcement learning,
Z. Liu, Y . Li, J. Wang, J. Tu, Y . Hong, F. Li, Y . Liu, T. Sugawara, and Y . Tang, “Robust and efficient communication in multi-agent reinforcement learning,”arXiv preprint arXiv:2511.11393, 2025
-
[19]
Event-triggered communication network with limited-bandwidth constraint for multi- agent reinforcement learning,
G. Hu, Y . Zhu, D. Zhao, M. Zhao, and J. Hao, “Event-triggered communication network with limited-bandwidth constraint for multi- agent reinforcement learning,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 8, pp. 3966–3978, 2021
2021
-
[20]
Learning individually inferred commu- nication for multi-agent cooperation,
Z. Ding, T. Huang, and Z. Lu, “Learning individually inferred commu- nication for multi-agent cooperation,”Advances in neural information processing systems, vol. 33, pp. 22 069–22 079, 2020
2020
-
[21]
Efficient commu- nications for multi-agent reinforcement learning in wireless networks,
Z. Lv, Y . Du, Y . Chen, L. Xiao, S. Han, and X. Ji, “Efficient commu- nications for multi-agent reinforcement learning in wireless networks,” inIEEE Global Communications Conference (GLOBECOM). IEEE, 2023, pp. 583–588
2023
-
[22]
Robust multi-agent communication with graph information bottleneck optimiza- tion,
S. Ding, W. Du, L. Ding, J. Zhang, L. Guo, and B. An, “Robust multi-agent communication with graph information bottleneck optimiza- tion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, 2024
2024
-
[23]
Multi- agent reinforcement learning with communication-constrained priors,
G. Yang, T. Yang, J. Qiao, Y . Wu, J. Huo, X. Chen, and Y . Gao, “Multi- agent reinforcement learning with communication-constrained priors,” 2025
2025
-
[24]
Multi-agent reinforcement learning as a rehearsal for decentralized planning,
L. Kraemer and B. Banerjee, “Multi-agent reinforcement learning as a rehearsal for decentralized planning,”Neurocomputing, 2016
2016
-
[25]
Weighted qmix: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning,
T. Rashid, G. Farquhar, B. Peng, and S. Whiteson, “Weighted qmix: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning,”Advances in neural information processing systems, vol. 33, pp. 10 199–10 210, 2020
2020
-
[26]
Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning,
K. Son, D. Kim, W. J. Kang, D. E. Hostallero, and Y . Yi, “Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning,” inInternational conference on machine learn- ing. PMLR, 2019, pp. 5887–5896
2019
-
[27]
QPLEX: Duplex du- eling multi-agent Q-learning,
J. Wang, Z. Ren, T. Liu, Y . Yu, and C. Zhang, “QPLEX: Duplex du- eling multi-agent Q-learning,” inInternational Conference on Learning Representations, 2021
2021
-
[28]
Rode: Learning roles to decompose multi-agent tasks,
T. Wang, T. Gupta, A. Mahajan, B. Peng, S. Whiteson, and C. Zhang, “Rode: Learning roles to decompose multi-agent tasks,” inInternational Conference on Learning Representations, 2021
2021
-
[29]
Celebrating diversity in shared multi-agent reinforcement learning,
C. Li, T. Wang, C. Wu, Q. Zhao, J. Yang, and C. Zhang, “Celebrating diversity in shared multi-agent reinforcement learning,”Advances in Neural Information Processing Systems, vol. 34, pp. 3991–4002, 2021
2021
-
[30]
Fop: Factorizing optimal joint policy of maximum-entropy multi-agent reinforcement learning,
T. Zhang, Y . Li, C. Wang, G. Xie, and Z. Lu, “Fop: Factorizing optimal joint policy of maximum-entropy multi-agent reinforcement learning,” inInternational conference on machine learning. PMLR, 2021, pp. 12 491–12 500
2021
-
[31]
XMIX: Graph-based temporal credit assignment and attention-augmented value decomposition for multi-agent cooperative reinforcement learning,
S. Wang, W. Ji, H. Gui, K. Zhang, L. Wang, and S. Pang, “XMIX: Graph-based temporal credit assignment and attention-augmented value decomposition for multi-agent cooperative reinforcement learning,”Neu- rocomputing, vol. 637, 2025
2025
-
[32]
Hyper- MARL: Adaptive hypernetworks for multi-agent RL,
K.-a. A. Tessera, A. Rahman, A. Storkey, and S. V . Albrecht, “Hyper- MARL: Adaptive hypernetworks for multi-agent RL,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[33]
Learning nearly decompos- able value functions via communication minimization,
T. Wang, J. Wang, Y . Wu, and C. Zhang, “Learning nearly decompos- able value functions via communication minimization,” inInternational Conference on Learning Representations, 2020
2020
-
[34]
arXiv preprint arXiv:2102.03479 , year=
J. Hu, S. Jiang, S. A. Harding, H. Wu, and S.-w. Liao, “Rethinking the implementation tricks and monotonicity constraint in cooperative multi-agent reinforcement learning,”arXiv preprint arXiv:2102.03479, 2024, shows QMIX achieves state-of-the-art on SMAC with proper implementation
-
[35]
W. Jin, H. Du, B. Zhao, X. Tian, B. Shi, and G. Yang, “A comprehensive survey on multi-agent cooperative decision-making: Scenarios, approaches, challenges and perspectives,”arXiv preprint arXiv:2503.13415, 2025
-
[36]
Deep coordination graphs,
W. B ¨ohmer, V . Kurin, and S. Whiteson, “Deep coordination graphs,” in Proceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 2020
2020
-
[37]
Deep implicit coordination graphs for multi-agent reinforcement learning,
S. Li, J. K. Gupta, P. Morales, R. Allen, and M. J. Kochenderfer, “Deep implicit coordination graphs for multi-agent reinforcement learning,” in Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, 2021, pp. 764–772
2021
-
[38]
Deep meta coordination graphs for multi-agent reinforcement learning,
N. Gupta, J. Z. Hare, J. Milzman, R. Kannan, and V . Prasanna, “Deep meta coordination graphs for multi-agent reinforcement learning,” 2025
2025
-
[39]
Dynamic deep factor graph for multi-agent reinforcement learning,
Y . Shi, S. Duan, C. Xu, R. Wang, F. Ye, and C. Yuen, “Dynamic deep factor graph for multi-agent reinforcement learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[40]
Graph convolutional reinforce- ment learning,
J. Jiang, C. Dun, T. Huang, and Z. Lu, “Graph convolutional reinforce- ment learning,” inInternational Conference on Learning Representa- tions, 2020
2020
-
[41]
Breaking the curse of dimensionality in multiagent state space: A unified agent permutation framework,
X. Hao, H. Mao, W. Wang, Y . Yang, D. Li, Y . Zheng, Z. Wang, and J. Hao, “Breaking the curse of dimensionality in multiagent state space: A unified agent permutation framework,” inInternational Conference on Learning Representations, 2023
2023
-
[42]
VGN: Value decomposition with graph attention networks for multiagent reinforcement learning,
Q. Wei, Y . Li, J. Zhang, and F.-Y . Wang, “VGN: Value decomposition with graph attention networks for multiagent reinforcement learning,” IEEE Transactions on Neural Networks and Learning Systems, 2022
2022
-
[43]
Stochastic graph neural network-based value decomposition for MARL in internet of vehicles,
B. Xiao, R. Li, F. Wang, C. Peng, J. Wu, Z. Zhao, and H. Zhang, “Stochastic graph neural network-based value decomposition for MARL in internet of vehicles,”IEEE Transactions on Vehicular Technology, vol. 73, no. 2, 2024
2024
-
[44]
Interpretable credit assignment in multi-agent reinforcement learning via graph cooperation modeling,
X. Li, J. Zhang, Y . Zhu, and D. Zhao, “Interpretable credit assignment in multi-agent reinforcement learning via graph cooperation modeling,” IEEE Transactions on Neural Networks and Learning Systems, 2024
2024
-
[45]
How powerful are graph neural networks?
K. Xu, W. Hu, J. Leskovec, and S. Jegelka, “How powerful are graph neural networks?” 2019
2019
-
[46]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
J. Chung, C ¸ . G¨ulc ¸ehre, K. Cho, and Y . Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,”CoRR, vol. abs/1412.3555, 2014
work page internal anchor Pith review arXiv 2014
-
[47]
Individualized controlled contin- uous communication model for multiagent cooperative and competitive tasks,
A. Singh, T. Jain, and S. Sukhbaatar, “Individualized controlled contin- uous communication model for multiagent cooperative and competitive tasks,” inInternational Conference on Learning Representations, 2019
2019
-
[48]
S. V . Albrecht and S. Ramamoorthy, “A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems,”arXiv:1506.01170, 2015
-
[49]
Differentiable approximations for multi-resource spatial coverage problems,
N. Kamra and Y . Liu, “Differentiable approximations for multi-resource spatial coverage problems,” 2020
2020
-
[50]
The starcraft multi-agent challenge.arXiv preprint arXiv:1902.04043, 2019
M. Samvelyan, T. Rashid, C. S. De Witt, G. Farquhar, N. Nardelli, T. G. Rudner, C.-M. Hung, P. H. Torr, J. Foerster, and S. Whiteson, “The starcraft multi-agent challenge,”arXiv:1902.04043, 2019
-
[51]
Monotonic value function factorisation for deep multi- agent reinforcement learning
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. N. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi- agent reinforcement learning.”J. Mach. Learn. Res., 2020
2020
-
[52]
Learning to ground multi-agent communication with autoencoders,
T. Lin, J. Huh, C. Stauffer, S. N. Lim, and P. Isola, “Learning to ground multi-agent communication with autoencoders,”Advances in Neural Information Processing Systems, vol. 34, pp. 15 230–15 242, 2021
2021
-
[53]
On the pitfalls of measuring emergent communication,
R. Lowe, J. Foerster, Y .-L. Boureau, J. Pineau, and Y . Dauphin, “On the pitfalls of measuring emergent communication,”arXiv preprint arXiv:1903.05168, 2019
-
[54]
Social influence as intrinsic motivation for multi-agent deep reinforcement learning,
N. Jaques, A. Lazaridou, E. Hughes, C. Gulcehre, P. Ortega, D. Strouse, J. Z. Leibo, and N. De Freitas, “Social influence as intrinsic motivation for multi-agent deep reinforcement learning,” inInternational conference on machine learning. PMLR, 2019, pp. 3040–3049
2019
-
[55]
Approximation by superpositions of a sigmoidal function,
G. Cybenko, “Approximation by superpositions of a sigmoidal function,” Mathematics of Control, Signals and Systems, vol. 2, no. 4, pp. 303–314, 1989. 17
1989
-
[56]
Computer solution of large linear systems,
“Computer solution of large linear systems,” inStudies in Mathematics and Its Applications, G. Meurant, Ed. Elsevier, 1999, vol. 28, pp. 397–540
1999
-
[57]
D. Ha, A. M. Dai, and Q. V . Le, “Hypernetworks,”CoRR, 2016. [Online]. Available: http://arxiv.org/abs/1609.09106
work page internal anchor Pith review arXiv 2016
-
[58]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inInternational Conference on Learning Representations, 2015. [Online]. Available: http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.