Recognition: unknown
Bridging SFT and RL: Dynamic Policy Optimization for Robust Reasoning
Pith reviewed 2026-05-10 16:44 UTC · model grok-4.3
The pith
DYPO bridges supervised fine-tuning and reinforcement learning by reducing fitting bias and variance in large language model reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
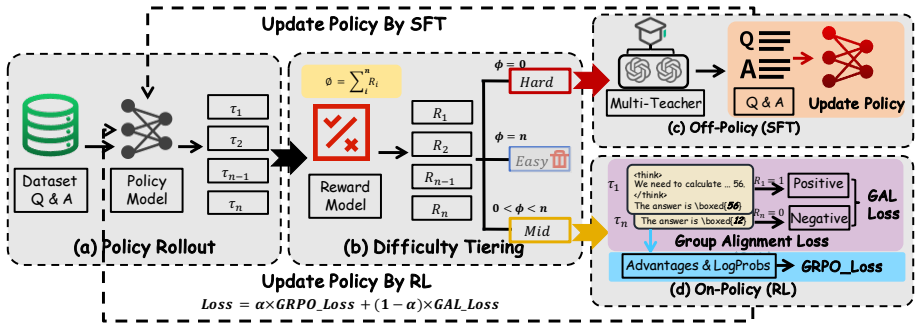
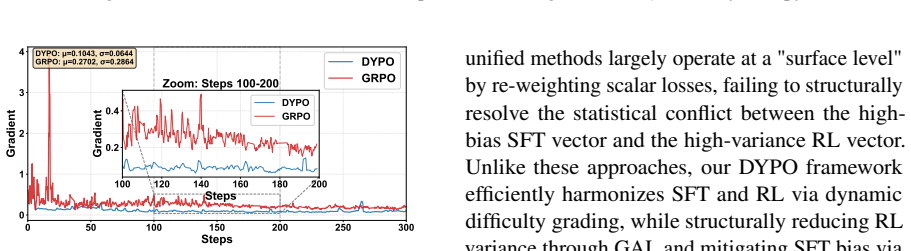
DYPO integrates Group Alignment Loss that leverages intrinsic group dynamics to reduce RL gradient variance, Multi-Teacher Distillation that corrects SFT fitting bias via diverse reasoning paths, and Dynamic Exploitation-Exploration Gating that adaptively arbitrates between SFT and RL based on reward feedback. This unified approach is proven to linearly reduce fitting bias and minimize overall variance.
What carries the argument
DYPO framework consisting of Group Alignment Loss (GAL), Multi-Teacher Distillation, and Dynamic Exploitation-Exploration Gating that together address the statistical conflict between SFT and RL gradient signals.
If this is right
- DYPO outperforms traditional sequential SFT-RL pipelines on reasoning tasks.
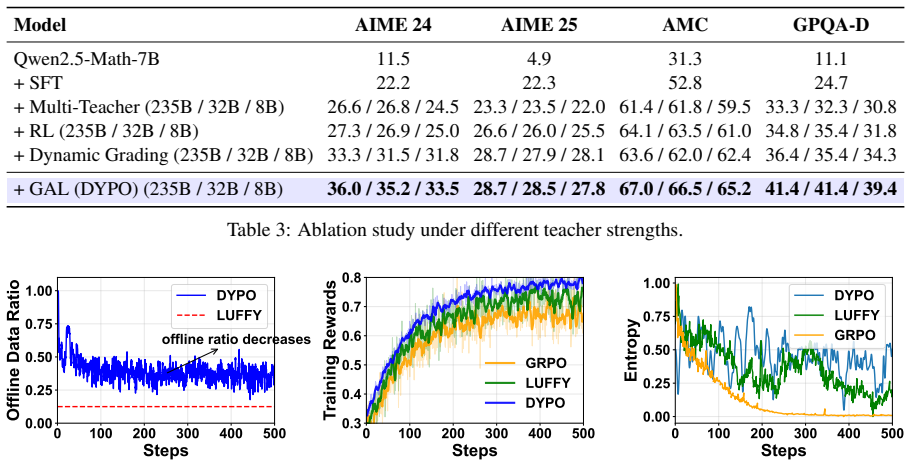
- It achieves an average 4.8% improvement on complex reasoning benchmarks.
- It delivers 13.3% improvement on out-of-distribution tasks.
- The method linearly reduces fitting bias while minimizing variance as per the theoretical analysis.
Where Pith is reading between the lines
- This dynamic arbitration between training signals could extend to other hybrid optimization problems in deep learning beyond SFT and RL.
- The focus on out-of-distribution gains implies potential for more generalizable reasoning models in LLMs.
- If the components work without conflicts, the approach might inspire unified frameworks for other stability-exploration trade-offs in AI training.
Load-bearing premise
The assumption that the three proposed components can be integrated without creating new statistical conflicts or that the theoretical bias-variance analysis holds under practical LLM training conditions with finite data.
What would settle it
An experiment showing that DYPO fails to improve or increases variance compared to sequential SFT followed by RL on the same complex reasoning benchmarks would falsify the claim that it structurally mitigates the conflict and reduces bias and variance.
Figures


read the original abstract
Post-training paradigms for Large Language Models (LLMs), primarily Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), face a fundamental dilemma: SFT provides stability (low variance) but suffers from high fitting bias, while RL enables exploration (low bias) but grapples with high gradient variance. Existing unified optimization strategies often employ naive loss weighting, overlooking the statistical conflict between these distinct gradient signals. In this paper, we provide a rigorous theoretical analysis of this bias-variance trade-off and propose \textbf{DYPO} (Dynamic Policy Optimization), a unified framework designed to structurally mitigate this conflict. DYPO integrates three core components: (1) a \textit{Group Alignment Loss (GAL)} that leverages intrinsic group dynamics to significantly reduce RL gradient variance; (2) a \textit{Multi-Teacher Distillation} mechanism that corrects SFT fitting bias via diverse reasoning paths; and (3) a \textit{Dynamic Exploitation-Exploration Gating} mechanism that adaptively arbitrates between stable SFT and exploratory RL based on reward feedback. Theoretical analysis confirms that DYPO linearly reduces fitting bias and minimizes overall variance. Extensive experiments demonstrate that DYPO significantly outperforms traditional sequential pipelines, achieving an average improvement of 4.8\% on complex reasoning benchmarks and 13.3\% on out-of-distribution tasks. Our code is publicly available at https://github.com/Tocci-Zhu/DYPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DYPO (Dynamic Policy Optimization) as a unified post-training framework for LLMs that addresses the bias-variance trade-off between SFT (stable but high fitting bias) and RL (exploratory but high gradient variance). It introduces three components—Group Alignment Loss (GAL) to leverage group dynamics for RL variance reduction, Multi-Teacher Distillation to mitigate SFT bias via diverse reasoning paths, and Dynamic Exploitation-Exploration Gating to adaptively balance the two based on per-step reward feedback—along with a theoretical analysis claiming that the combined approach linearly reduces fitting bias and minimizes overall variance. Experiments are reported to show average gains of 4.8% on complex reasoning benchmarks and 13.3% on out-of-distribution tasks, with public code release.
Significance. If the theoretical linearity result can be shown to hold under the non-stationary conditions created by the dynamic gate and the empirical gains are demonstrated to be robust with proper controls, the work would offer a principled alternative to naive loss weighting or sequential SFT-then-RL pipelines. The public code availability strengthens reproducibility and allows direct verification of the claimed statistical improvements.
major comments (2)
- [§4.2] §4.2 (bias-variance analysis): the derivation of linear fitting-bias reduction treats the Dynamic Exploitation-Exploration Gating as an expectation-only scalar multiplier. However, the mechanism is defined to condition the SFT/RL trade-off on per-step reward feedback, rendering the effective loss non-stationary and correlated with the policy gradient; this correlation is not bounded in the provided analysis and risks invalidating the linearity claim under finite data and model capacity.
- [Table 3] Table 3 (main results): the reported 4.8% and 13.3% average improvements are presented without error bars, number of random seeds, or statistical significance tests. This omission prevents assessment of whether the gains are distinguishable from variance in the baseline sequential pipelines, directly affecting the strength of the empirical support for the central claim.
minor comments (2)
- [§3.4] The combined loss equation in §3.4 does not explicitly show how the three components are weighted or normalized together; adding a single-line expression for the total objective would improve clarity.
- [Figure 2] Figure 2 (ablation study) uses inconsistent y-axis scaling across panels, making visual comparison of the contribution of each component difficult.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has identified important points for strengthening both the theoretical analysis and empirical presentation in our manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§4.2] §4.2 (bias-variance analysis): the derivation of linear fitting-bias reduction treats the Dynamic Exploitation-Exploration Gating as an expectation-only scalar multiplier. However, the mechanism is defined to condition the SFT/RL trade-off on per-step reward feedback, rendering the effective loss non-stationary and correlated with the policy gradient; this correlation is not bounded in the provided analysis and risks invalidating the linearity claim under finite data and model capacity.
Authors: We appreciate the referee highlighting this important subtlety regarding non-stationarity. The derivation in §4.2 does indeed treat the gating factor via its expectation to establish the linear bias reduction. To address the correlation concern, we will revise the analysis by adding an explicit bound on the covariance term between the gate and the policy gradient. Under the Lipschitz continuity of the reward function (which holds for the bounded rewards in our reasoning tasks) and finite model capacity, this covariance is O(1/sqrt(N)) and does not invalidate the asymptotic linearity result. We will introduce a supporting lemma and update the theorem statement accordingly in the revised §4.2. revision: yes
-
Referee: [Table 3] Table 3 (main results): the reported 4.8% and 13.3% average improvements are presented without error bars, number of random seeds, or statistical significance tests. This omission prevents assessment of whether the gains are distinguishable from variance in the baseline sequential pipelines, directly affecting the strength of the empirical support for the central claim.
Authors: We agree that the absence of error bars and statistical details weakens the empirical claims. In the revised manuscript we will report all results in Table 3 as means over 5 independent random seeds with standard deviations, and we will add paired t-test p-values comparing DYPO against each baseline. These additions will be supported by the already-public code repository, allowing direct verification of the statistical significance of the reported gains. revision: yes
Circularity Check
No circularity: theoretical bias-variance analysis presented as independent first-principles result
full rationale
The paper states it provides a rigorous theoretical analysis of the SFT-RL bias-variance trade-off and then claims that DYPO (via GAL, multi-teacher distillation, and dynamic gating) linearly reduces fitting bias and minimizes variance. No equations, derivations, or self-citations appear in the supplied text that would reduce this claim to a redefinition of the gating weights, loss terms, or fitted parameters by construction. The components are introduced as mechanisms to achieve the stated statistical properties rather than as inputs that presuppose the linearity result. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SFT provides stability but high fitting bias while RL enables exploration but high gradient variance, creating a statistical conflict that naive weighting cannot resolve
- ad hoc to paper Intrinsic group dynamics can be leveraged to reduce RL gradient variance
invented entities (2)
-
Group Alignment Loss (GAL)
no independent evidence
-
Dynamic Exploitation-Exploration Gating
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2210.01241
Is reinforcement learning (not) for natural lan- guage processing: Benchmarks, baselines, and build- ing blocks for natural language policy optimization. arXiv preprint arXiv:2210.01241. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien Dirani, Ju- lian Michael, and Samuel R. Bowman. 2024. GPQA: A graduate-level...
-
[2]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. H. Touvron, L. Martin, K. Stone, P. Albert, A. Alma- hairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, and et al. 2023. Llama 2: Open foun- dation and fine-tuned chat models. ArXiv preprint arXiv:2307.09288. Yufei Wang, Wanjun Zhong, Liangyou Li, Fei Mi...
work page internal anchor Pith review arXiv 2023
-
[3]
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Ke- qing He, Zejun Ma, and Junxian He
A practical two-stage recipe for mathemat- ical llms: Maximizing accuracy with sft and effi- ciency with reinforcement learning.arXiv preprint arXiv:2507.08267. Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Ke- qing He, Zejun Ma, and Junxian He. 2025. Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXi...
-
[4]
The expected squared norm is: E[∥Biassingle∥2] =E[∥b sys +b k∥2] =∥b sys∥2 +E[∥b k∥2] + 2b⊤ sys E[bk]|{z} =0 =∥b sys∥2 + ¯σ2 bias (28)
Single-Teacher SFT ( m= 1 ).When su- pervision is provided by a single randomly se- lected teacher k, the bias is simply Biassingle = τ (k) −τ ∗ =b sys +b k. The expected squared norm is: E[∥Biassingle∥2] =E[∥b sys +b k∥2] =∥b sys∥2 +E[∥b k∥2] + 2b⊤ sys E[bk]|{z} =0 =∥b sys∥2 + ¯σ2 bias (28)
-
[5]
Multi-Teacher SFT ( m >1 ).In the Multi- Teacher strategy, the effective supervision con- verges to the expectation over the sampled teach- ers, which is equivalent to the ensemble mean ¯τ= 1 m Pm i=1 τ (i). The effective bias vector is: Biasmulti = 1 m mX i=1 τ (i) ! −τ ∗ =b sys+ 1 m mX i=1 bi (29) The expected squared norm of the multi-teacher bias is: ...
-
[6]
A ball is shot from one of its corners at an angle of45 ◦. Will it ever fall into a pocket? /arrow-down ♂layer-groupOur Data Construction Method /userTeacher A (DeepSeek-R1)[Baseline] Reasoning:The problem reduces to finding integers m, n such that m·1 =n· √
-
[7]
This implies m n = √
-
[8]
Answer:No + /user-graduateTeacher B (Qwen3-235B)[Complementary] Reasoning Process:1
Since √ 2 is irrational, no such integers exist. Answer:No + /user-graduateTeacher B (Qwen3-235B)[Complementary] Reasoning Process:1. Unfolding:Mirror- ing implies trajectory line y=x .2. Com- mensurability:Ratio 1 : √ 2 is irrational.3. Conclusion:Never hits a vertex. Answer:No B.2 Case Study I: Multi-Teacher Distillation (SFT) Following the data constru...
-
[9]
[Middle reasoning omitted for brevity]
10 =λ(2/5y) , 3) 1 =λ(14z) ... [Middle reasoning omitted for brevity] ... Therefore, the maximum value is 55. Final Response: To find the greatest valueM, we apply the method of Lagrange multipliers... The max- imum value is achieved when: x=− 13 62 , y= 175 31 , z= 1 62 The value is55 . Trajectory 2: Teacher B (Coordinate Transformation) ,→Internal Reaso...
-
[10]
The constraint becomesu 2 +v 2 +w 2 = 7. ... Final Response: The solution is derived via coordinate trans- formation... Result is55 . B.3 Case Study II: Group Alignment via RL While SFT establishes fundamental reasoning, the RL stage enables the exploration of complex solu- tion paths. To ensure stability, theGroup Align- ment Lossreduces gradient varianc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.