Recognition: 2 theorem links
· Lean TheoremModality-Aware Zero-Shot Pruning and Sparse Attention for Efficient Multimodal Edge Inference
Pith reviewed 2026-05-10 18:02 UTC · model grok-4.3
The pith
SentryFuse learns modality-conditioned importance scores during training to enable zero-shot pruning of attention heads and channels plus sparse grouped-query attention, cutting memory 28 percent and latency up to 1.63 times without fine-t
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
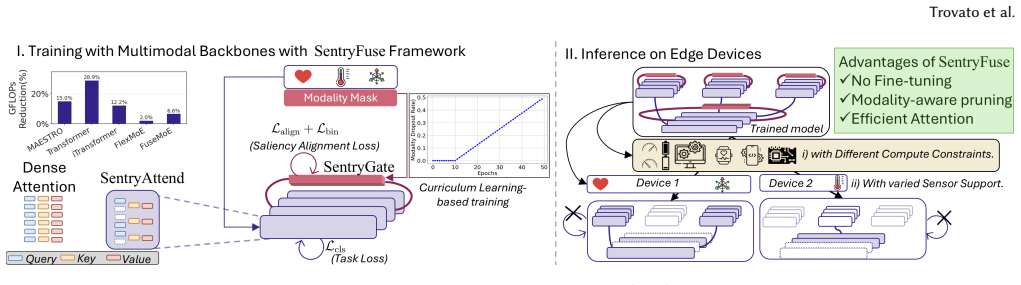
The central claim is that the SentryFuse framework solves the joint challenges of modality dropout and varying power on edge hardware through two components. SentryGate learns modality-conditioned importance scores via first-order saliency supervision so that attention heads and feed-forward channels can be pruned at deployment for the currently available sensors without fine-tuning. SentryAttend replaces dense self-attention with sparse grouped-query attention. On three multimodal backbones and applications this yields a 12.7 percent average accuracy gain over the strongest pruning baseline, up to 18 percent under modality dropout, 28.2 percent memory reduction, and up to 1.63 times lower
What carries the argument
SentryGate, which computes modality-conditioned importance scores from first-order saliency supervision to guide zero-shot pruning of attention heads and feed-forward channels, together with SentryAttend, which substitutes dense self-attention by sparse grouped-query attention.
If this is right
- Pruning can be performed on the fly for whichever sensors remain active at inference time.
- No extra fine-tuning energy cost is incurred after the model is compressed for a given power budget.
- Accuracy is maintained or improved while memory footprint drops by more than a quarter.
- Latency improves by up to 63 percent on the tested multimodal architectures.
Where Pith is reading between the lines
- The same first-order saliency supervision could be extended to prune other model parts such as embedding layers or cross-attention blocks.
- Edge systems might store only one set of scores and apply different pruning masks in real time rather than keeping multiple model copies.
- The method's robustness would be clarified by systematic tests on modality dropout patterns that are rarer than those used in the original training distribution.
Load-bearing premise
The importance scores learned from first-order saliency during training remain accurate enough to decide which heads and channels to prune when the set of active modalities at deployment differs from any pattern seen in training.
What would settle it
Measure accuracy of the zero-shot pruned model on a held-out multimodal task using a modality combination never encountered during training; if accuracy falls below the dense baseline or below a version that was fine-tuned after the same pruning, the zero-shot claim does not hold.
Figures







read the original abstract
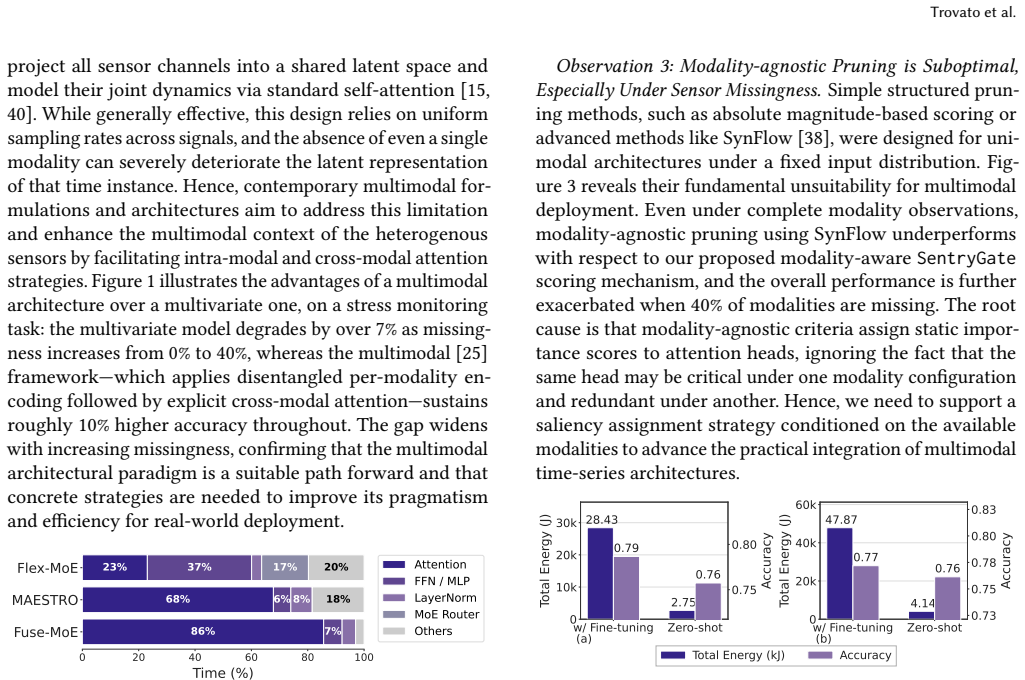
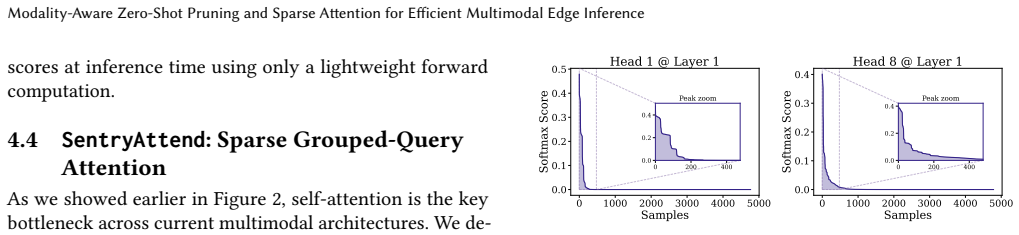
Edge devices increasingly run multimodal sensing pipelines that must remain accurate despite fluctuating power budgets and unpredictable sensor dropout. Existing pruning methods fail under these conditions: they generally require fine-tuning after compression, consuming over $10\times$ the deployment energy, and they assign static importance scores that are blind to which sensors are present. We present the SentryFuse framework, which addresses both challenges jointly through two key components. First, SentryGate learns modality-conditioned importance scores during training via first-order saliency supervision and then prunes attention heads and feed-forward channels at deployment without fine-tuning. Second, SentryAttend replaces dense self-attention, a key bottleneck in contemporary multimodal architectures, with sparse grouped-query attention, yielding a net 15% reduction in GFLOPs across three different multimodal architectures. Across three applications and multimodal backbones, SentryGate achieves a 12.7% average accuracy improvement over the strongest pruning baseline, and upto to 18% under modality dropout conditions. Together, SentryFuse reduces memory by 28.2% and lowers latency by up to $1.63\times$ without further fine-tuning, establishing modality-aware zero-shot compression as a practical path to multimodal intelligence on heterogeneous edge hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the SentryFuse framework for efficient multimodal inference on edge devices facing fluctuating power budgets and sensor dropout. SentryGate learns modality-conditioned importance scores via first-order saliency supervision during training to enable zero-shot pruning of attention heads and feed-forward channels without fine-tuning at deployment. SentryAttend replaces dense self-attention with sparse grouped-query attention for a net 15% GFLOPs reduction. Across three applications and backbones, the framework claims a 12.7% average accuracy gain over the strongest pruning baseline (up to 18% under modality dropout), 28.2% memory reduction, and up to 1.63× lower latency without post-pruning adaptation.
Significance. If the zero-shot generalization holds, the work is significant for practical multimodal edge deployment, as it jointly tackles compression and dynamic modality availability while avoiding the >10× energy cost of fine-tuning after pruning. The combination of saliency-based pruning and sparse attention could enable more robust inference on heterogeneous hardware.
major comments (3)
- [Section 3.2] The central zero-shot claim rests on the untested assumption that first-order saliency scores learned on the training distribution remain accurate for arbitrary unseen modality dropout patterns at inference (see skeptic note on higher-order cross-modal interactions). Section 3.2 should include an explicit ablation or analysis showing that scores are dynamically conditioned on the active modalities present at runtime rather than using static scores.
- [Section 5.3] Section 5.3 and associated tables: the reported 12.7% and 18% accuracy improvements under modality dropout lack confirmation that test-time dropout patterns are disjoint from any dropout used in training or saliency supervision. Without this, the generalization guarantee cannot be verified and the gains may reflect in-distribution behavior rather than true zero-shot robustness.
- [Section 3] No equations or derivations for the saliency supervision loss or the importance score computation appear in the abstract or early sections; if these are parameter-free as implied, the manuscript should state the exact formulation (e.g., Eq. (X) in Section 3) to allow reproduction and to rule out hidden dependencies on the training modality distribution.
minor comments (2)
- [Abstract] Abstract contains a typographical error: 'upto to 18%' should read 'up to 18%'.
- [Section 2] The description of SentryAttend as 'sparse grouped-query attention' would benefit from a brief comparison to standard GQA or other sparse attention variants in Section 2 to clarify the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments have helped us identify areas where additional clarity and analysis can strengthen the presentation of the zero-shot claims. We address each major comment point by point below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Section 3.2] The central zero-shot claim rests on the untested assumption that first-order saliency scores learned on the training distribution remain accurate for arbitrary unseen modality dropout patterns at inference (see skeptic note on higher-order cross-modal interactions). Section 3.2 should include an explicit ablation or analysis showing that scores are dynamically conditioned on the active modalities present at runtime rather than using static scores.
Authors: We agree that an explicit demonstration of dynamic conditioning is necessary to support the zero-shot generalization. In the SentryGate design, importance scores are computed at runtime based on the specific set of active modalities, using first-order saliency supervision that incorporates modality conditioning during training. To address the concern directly, we have added a new ablation study in Section 3.2. This study evaluates the learned scores under multiple unseen dropout patterns at inference and contrasts them against static (non-conditioned) baselines, confirming adaptation to the runtime modality set. We have also included a brief discussion of higher-order cross-modal interactions to contextualize the first-order approximation and its limitations. revision: yes
-
Referee: [Section 5.3] Section 5.3 and associated tables: the reported 12.7% and 18% accuracy improvements under modality dropout lack confirmation that test-time dropout patterns are disjoint from any dropout used in training or saliency supervision. Without this, the generalization guarantee cannot be verified and the gains may reflect in-distribution behavior rather than true zero-shot robustness.
Authors: We acknowledge that explicit confirmation of disjoint patterns is required to substantiate the zero-shot robustness claim. In our experimental protocol, test-time modality dropout patterns were generated via independent sampling and constructed to have no overlap with the dropout configurations used in training or for saliency supervision. We have revised Section 5.3 to state this explicitly, including a description of the sampling method used for test patterns to ensure disjointness from the training distribution. This update verifies that the accuracy gains reflect generalization rather than in-distribution behavior. revision: yes
-
Referee: [Section 3] No equations or derivations for the saliency supervision loss or the importance score computation appear in the abstract or early sections; if these are parameter-free as implied, the manuscript should state the exact formulation (e.g., Eq. (X) in Section 3) to allow reproduction and to rule out hidden dependencies on the training modality distribution.
Authors: We appreciate the recommendation to improve early accessibility and reproducibility. The saliency supervision loss and importance score computation are indeed parameter-free, with full equations and derivations provided in Section 3. To address the comment, we have inserted a concise statement of the formulation at the close of the introduction and within Section 2, with an explicit forward reference to Equation (X) in Section 3. This addition states the exact formulation upfront and confirms the absence of hidden dependencies on the training modality distribution beyond the intended conditioning mechanism. revision: yes
Circularity Check
No significant circularity; empirical validation only
full rationale
The paper presents SentryFuse as an empirical framework consisting of SentryGate (modality-conditioned saliency-based pruning) and SentryAttend (sparse grouped-query attention). All reported results—12.7% average accuracy gain, 28.2% memory reduction, 1.63× latency improvement—are obtained from experimental comparisons on three applications and backbones under modality dropout. No equations, derivations, or closed-form predictions appear in the provided text; the methodology trains importance scores on the training distribution and evaluates zero-shot generalization on held-out conditions. Because the central claims are externally falsifiable benchmark outcomes rather than any self-referential fitting, self-definition, or load-bearing self-citation chain, the derivation chain is self-contained with no circular reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SentryGate learns modality-conditioned importance scores during training via first-order saliency supervision and then prunes attention heads and feed-forward channels at deployment without fine-tuning.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SentryAttend replaces dense self-attention with sparse grouped-query attention, yielding a net 15% reduction in GFLOPs.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Kerem Altun, Billur Barshan, and Orkun Tunçel. 2010. Comparative study on classifying human activities with miniature inertial and magnetic sensors. Pattern Recognition 43, 10 (2010), 3605–3620
2010
- [3]
-
[4]
Jonathan Frankle and Michael Carbin. 2018. The lottery ticket hy- pothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635 (2018)
work page Pith review arXiv 2018
-
[5]
Elias Frantar and Dan Alistarh. 2023. Sparsegpt: Massive lan- guage models can be accurately pruned in one-shot. In International conference on machine learning. PMLR, 10323–10337
2023
-
[6]
Yingchun Fu, Zhe Zhu, Liangyun Liu, Wenfeng Zhan, Tao He, Huan- feng Shen, Jun Zhao, Yongxue Liu, Hongsheng Zhang, Zihan Liu, et al. 2024. Remote sensing time series analysis: A review of data and applications. Journal of Remote Sensing 4 (2024), 0285
2024
-
[7]
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. 2023. Im- agebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15180–15190
2023
-
[8]
Ary L Goldberger, Luis AN Amaral, Leon Glass, Jeffrey M Hausdorff, Plamen Ch Ivanov, Roger G Mark, Joseph E Mietus, George B Moody, Chung-Kang Peng, and H Eugene Stanley. 2000. PhysioBank, Phys- ioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. circulation 101, 23 (2000), e215–e220
2000
-
[9]
Song Han, Jeff Pool, John Tran, and William J. Dally. 2015. Learn- ing both weights and connections for efficient neural networks. In Proceedings of the 29th International Conference on Neural Information Processing Systems (NeurIPS). 1135–1143
2015
-
[10]
Xing Han, Huy Nguyen, Carl Harris, Nhat Ho, and Suchi Saria. 2024. FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion. In Advances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 67850–67900
2024
-
[11]
Yihui He, Xiangyu Zhang, and Jian Sun. 2017. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE international conference on computer vision. 1389–1397
2017
- [12]
-
[13]
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. 2017. Pruning Filters for Efficient ConvNets. arXiv:1608.08710 [cs.CV]
work page Pith review arXiv 2017
-
[14]
Paul Pu Liang, Yiwei Lyu, Xiang Fan, Zetian Wu, Yun Cheng, Jason Wu, Leslie Chen, Peter Wu, Michelle A Lee, Yuke Zhu, et al . 2021. Multibench: Multiscale benchmarks for multimodal representation learning. Advances in neural information processing systems 2021, DB1 (2021), 1
2021
-
[15]
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lin- tao Ma, and Mingsheng Long. 2023. iTransformer: Inverted Trans- formers Are Effective for Time Series Forecasting. arXiv preprint arXiv:2310.06625 (2023). Trovato et al
work page internal anchor Pith review arXiv 2023
-
[16]
Lyken17. 2022. THOP: PyTorch-OpCounter. https://github.com/ Lyken17/pytorch-OpCounter. Software package, accessed: 2026- 03-13
2022
-
[17]
Mengmeng Ma, Jian Ren, Long Zhao, Davide Testuggine, and Xi Peng
-
[18]
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Are multimodal transformers robust to missing modality?. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 18177–18186
-
[19]
Mengmeng Ma, Jian Ren, Long Zhao, Sergey Tulyakov, Cathy Wu, and Xi Peng. 2021. Smil: Multimodal learning with severely missing modal- ity. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 2302–2310
2021
-
[20]
Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2023. Llm-pruner: On the structural pruning of large language models. Advances in neural information processing systems 36 (2023), 21702–21720
2023
-
[21]
Mohsen Masoumian Hosseini, Seyedeh Toktam Masoumian Hosseini, Karim Qayumi, Shahriar Hosseinzadeh, and Seyedeh Saba Sajadi Tabar
-
[22]
BMC Medical Informatics and Decision Making 23, 1 (2023), 248
Smartwatches in healthcare medicine: assistance and monitoring; a scoping review. BMC Medical Informatics and Decision Making 23, 1 (2023), 248
2023
-
[23]
Matthew Middlehurst, Patrick Schäfer, and Anthony Bagnall. 2024. Bake off redux: a review and experimental evaluation of recent time se- ries classification algorithms. Data Mining and Knowledge Discovery 38, 4 (2024), 1958–2031
2024
-
[24]
Payal Mohapatra, Vasudev Aravind, Marisa Bisram, Young-Joong Lee, Hyoyoung Jeong, Katherine Jinkins, Richard Gardner, Jill Streamer, Brent Bowers, Lora Cavuoto, et al. 2024. Wearable network for mul- tilevel physical fatigue prediction in manufacturing workers. PNAS nexus 3, 10 (2024), pgae421
2024
-
[25]
Payal Mohapatra, Shamika Likhite, Subrata Biswas, Bashima Islam, and Qi Zhu. 2024. Missingness-resilient Video-enhanced Multimodal Disfluency Detection. In Interspeech 2024. 5093–5097. doi:10.21437/ Interspeech.2024-1458
2024
-
[26]
Payal Mohapatra, Akash Pandey, Xiaoyuan Zhang, and Qi Zhu. 2025. Can LLMs Understand Unvoiced Speech? Exploring EMG-to-Text Conversion with LLMs. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). Association for Computational Linguistics
2025
- [27]
- [28]
-
[29]
Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila, and Jan Kautz. 2017. Pruning convolutional neural networks based on the Taylor expansion. In International Conference on Learning Representations (ICLR)
2017
-
[30]
Akash Pandey, Payal Mohapatra, Wei Chen, Qi Zhu, and Sinan Keten
-
[31]
arXiv preprint arXiv:2601.21289 (2026)
TimeSliver: Symbolic-Linear Decomposition for Explainable Time Series Classification. arXiv preprint arXiv:2601.21289 (2026)
-
[32]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems, Vol. 32
2019
-
[33]
PyTorch Team. 2025. ExecuTorch. https://docs.pytorch.org/ executorch/stable/. Version 1.1 (stable), accessed: 2026-03-13
2025
-
[34]
Mohamed Ragab, Emadeldeen Eldele, Wee Ling Tan, Chuan-Sheng Foo, Zhenghua Chen, Min Wu, Chee-Keong Kwoh, and Xiaoli Li. 2023. Adatime: A benchmarking suite for domain adaptation on time series data. ACM Transactions on Knowledge Discovery from Data 17, 8 (2023), 1–18
2023
-
[35]
Attila Reiss, Ina Indlekofer, Philip Schmidt, and Kristof Van Laerhoven
-
[36]
Sensors 19, 14 (2019), 3079
Deep PPG: Large-scale heart rate estimation with convolutional neural networks. Sensors 19, 14 (2019), 3079
2019
-
[37]
Philip Schmidt, Attila Reiss, Robert Duerichen, Claus Marberger, and Kristof Van Laerhoven. 2018. Introducing wesad, a multimodal dataset for wearable stress and affect detection. In Proceedings of the 20th ACM international conference on multimodal interaction. 400–408
2018
-
[38]
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakr- ishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision. 618–626
2017
-
[39]
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. 2017. SmoothGrad: removing noise by adding noise. In ICML workshop on Visualization for Deep Learning
2017
-
[40]
Haoqin Sun, Shiwan Zhao, Shaokai Li, Xiangyu Kong, Xuechen Wang, Jiaming Zhou, Aobo Kong, Yong Chen, Wenjia Zeng, and Yong Qin
-
[41]
In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Enhancing Emotion Recognition in Incomplete Data: A Novel Cross-Modal Alignment, Reconstruction, and Refinement Framework. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
- [42]
-
[43]
Hidenori Tanaka, Daniel Kunin, Daniel L Yamins, and Surya Ganguli
-
[44]
Advances in neural information processing systems 33 (2020), 6377–6389
Pruning neural networks without any data by iteratively con- serving synaptic flow. Advances in neural information processing systems 33 (2020), 6377–6389
2020
-
[45]
FAIR Computer Vision Team. 2022. fvcore: Light-weight Core Library for Computer Vision. https://github.com/facebookresearch/fvcore
2022
-
[46]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention is all you need. Advances in neural information processing systems 30 (2017)
2017
-
[47]
Hu Wang, Yuanhong Chen, Congbo Ma, Jodie Avery, Louise Hull, and Gustavo Carneiro. 2023. Multi-modal learning with missing modality via shared-specific feature modelling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15878–15887
2023
-
[48]
Hanrui Wang, Zhekai Zhang, and Song Han. 2021. Spatten: Efficient sparse attention architecture with cascade token and head pruning. In 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 97–110
2021
-
[49]
Yunshi Wen, Tengfei Ma, Ronny Luss, Debarun Bhattacharjya, Achille Fokoue, and Anak Agung Julius. 2025. Shedding light on time series classification using interpretability gated networks. InThe Thirteenth International Conference on Learning Representations
2025
-
[50]
Chenwei Wu, Zitao Shuai, Zhengxu Tang, Luning Wang, and Liyue Shen. [n. d.]. Dynamic Modeling of Patients, Modalities and Tasks via Multi-modal Multi-task Mixture of Experts. In The Thirteenth International Conference on Learning Representations
- [51]
-
[52]
Sukwon Yun, Inyoung Choi, Jie Peng, Yangfan Wu, Jingxuan Bao, Qiyi- wen Zhang, Jiayi Xin, Qi Long, and Tianlong Chen. 2024. Flex-MoE: Modeling Arbitrary Modality Combination via the Flexible Mixture- of-Experts. In Advances in Neural Information Processing Systems, Vol. 37. Curran Associates, Inc., 98782–98805. Modality-Aware Zero-Shot Pruning and Sparse ...
2024
-
[53]
Sukwon Yun, Inyoung Choi, Jie Peng, Yangfan Wu, Jingxuan Bao, Qiyiwen Zhang, Jiayi Xin, Qi Long, and Tianlong Chen. 2024. Flex-moe: Modeling arbitrary modality combination via the flexible mixture- of-experts. Advances in Neural Information Processing Systems 37 (2024), 98782–98805
2024
-
[54]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond efficient trans- former for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, Vol. 35. 11106–11115
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.