Recognition: 2 theorem links
· Lean TheoremNeuroFlow: Toward Unified Visual Encoding and Decoding from Neural Activity
Pith reviewed 2026-05-10 17:07 UTC · model grok-4.3
The pith
NeuroFlow unifies visual encoding and decoding from neural activity inside one reversible flow model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
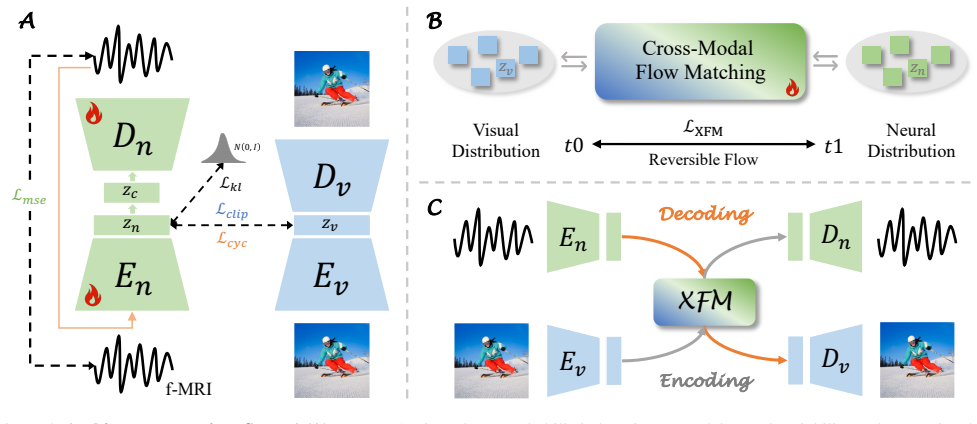
NeuroFlow is the first framework to cast visual encoding and decoding as a single time-dependent reversible process. It uses a NeuroVAE variational backbone to build a compact, semantically structured latent space that captures neural variability, then applies Cross-modal Flow Matching to learn a direct, invertible mapping between the visual and neural distributions inside that space. Encoding and decoding therefore become opposite directions of the same flow rather than independent functions.
What carries the argument
Cross-modal Flow Matching (XFM), which learns a reversibly consistent flow between visual and neural latent distributions instead of using conditioned noise-to-data diffusion.
If this is right
- Both encoding and decoding tasks improve in overall performance when trained together inside the same flow.
- Only one model must be trained and stored, yielding higher computational efficiency than any pair of isolated models.
- The learned flow reveals consistent brain activation patterns that underlie neural variability across subjects.
- Encoding and decoding become interchangeable operations along the same time-dependent trajectory in latent space.
Where Pith is reading between the lines
- The same reversible-flow idea could be tested on non-visual sensory modalities such as audition or touch.
- Brain-computer interfaces that must both read and write visual content might become simpler if they inherit the built-in consistency of this architecture.
- Principal factors identified for maintaining encoding-decoding alignment could be isolated and re-used as regularizers in other multimodal alignment tasks.
- Applying the framework to larger-scale neural recordings would test whether the consistency benefit scales beyond current dataset sizes.
Load-bearing premise
That a shared latent space and reversible flow can keep high fidelity when traveling in both directions without the accuracy losses that normally appear when models are specialized for only one direction.
What would settle it
A head-to-head test on standard fMRI visual datasets in which separately trained encoding and decoding models achieve reliably higher accuracy or reconstruction quality than the unified NeuroFlow model.
Figures







read the original abstract
Visual encoding and decoding models act as gateways to understanding the neural mechanisms underlying human visual perception. Typically, visual encoding models that predict brain activity from stimuli and decoding models that reproduce stimuli from brain activity are treated as distinct tasks, requiring separate models and training procedures. This separation is inefficient and fails to model the consistency between encoding and decoding processes. To address this limitation, we propose NeuroFlow, the first unified framework that jointly models visual encoding and decoding from neural activity within a single flow model. NeuroFlow introduces two key components: (1) NeuroVAE is designed as a variational backbone to model neural variability and establish a compact, semantically structured latent space for bidirectional modeling across visual and neural modalities. (2) Cross-modal Flow Matching (XFM) bypasses the typical paradigm of noise-to-data diffusion guided by a specific modality condition, instead learning a reversibly consistent flow model between visual and neural latent distributions. For the first time, visual encoding and decoding are reformulated as a time-dependent, reversible process within a shared latent space for unified modeling. Empirical results demonstrate that NeuroFlow achieves superior overall performance in visual encoding and decoding tasks with higher computational efficiency compared to any isolated methods. We further analyze principal factors that steer the model toward encoding-decoding consistency and, through brain functional analyses, demonstrate that NeuroFlow captures consistent activation patterns underlying neural variability. NeuroFlow marks a major step toward unified visual encoding and decoding from neural activity, providing mechanistic insights that inform future bidirectional visual brain-computer interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NeuroFlow as the first unified framework for joint visual encoding (predicting neural activity from stimuli) and decoding (reconstructing stimuli from neural activity). It introduces NeuroVAE as a variational backbone to model neural variability and produce a compact, semantically structured shared latent space, and Cross-modal Flow Matching (XFM) to learn a reversible, time-dependent flow between visual and neural latent distributions, reformulating both tasks as bidirectional processes within one model. The manuscript claims this yields superior overall performance and computational efficiency versus separately trained encoding or decoding models, while also identifying factors that promote encoding-decoding consistency and capturing consistent brain activation patterns.
Significance. If the empirical claims hold, the work would be significant for neural encoding/decoding and brain-computer interface research by demonstrating that a single reversible model can avoid the inefficiency of separate pipelines while maintaining or improving fidelity. The introduction of NeuroVAE and XFM as mechanisms for bidirectional consistency is a novel construction; the additional analyses of principal factors and functional brain patterns provide mechanistic value beyond performance metrics.
major comments (3)
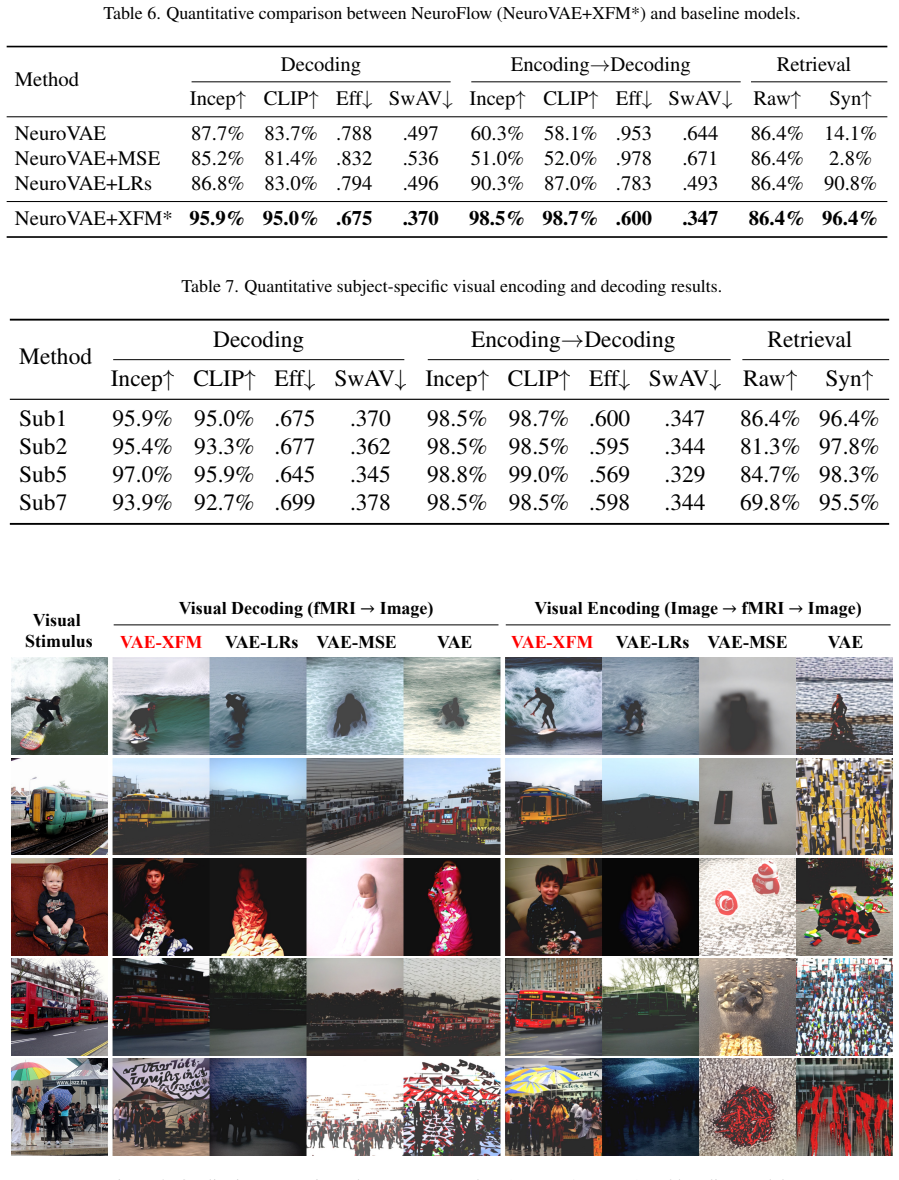
- [Results / Experiments] The central claim that NeuroFlow achieves superior performance without fidelity trade-offs (relative to isolated specialized models) is load-bearing for the contribution. The results section must include direct head-to-head quantitative comparisons (e.g., Pearson correlation or R² for encoding; perceptual reconstruction error or FID for decoding) with statistical tests, showing that the shared latent space plus reversibility constraint does not degrade either direction.
- [Methods (XFM)] §3 (XFM description): the flow-matching objective is presented as exactly invertible between the two marginals, but it is unclear how the training avoids expressiveness compromises that typically arise when enforcing reversibility. An ablation comparing XFM to a non-reversible cross-modal baseline is needed to substantiate that unification incurs no accuracy cost.
- [Abstract / Introduction] The abstract and introduction assert 'superior overall performance … with higher computational efficiency compared to any isolated methods' and 'for the first time' unified modeling, yet the provided text supplies no numerical results, baselines, or efficiency measurements. All such claims must be grounded in the tables/figures of the results section.
minor comments (2)
- [Methods] Notation for the shared latent variables (z_v, z_n) and the time-dependent flow parameters should be introduced with explicit definitions and dimensionality to improve readability of the bidirectional formulation.
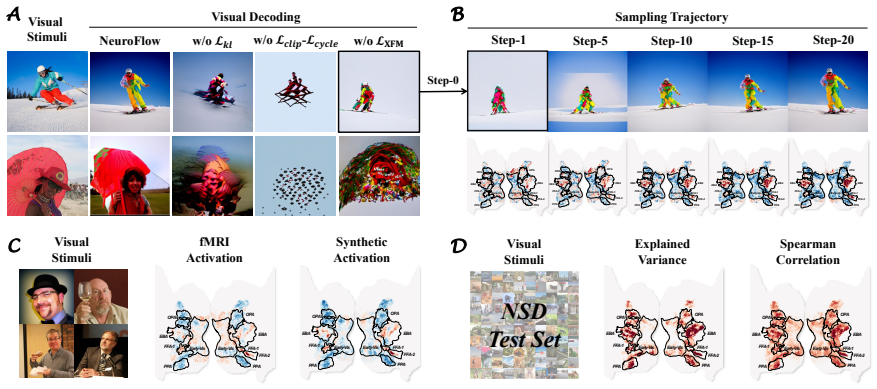
- [Figures] Figure captions for any latent-space visualizations or brain activation maps should explicitly state the number of subjects, trials, and statistical thresholds used.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We have addressed all major comments by revising the manuscript and providing additional analyses as requested. Below we respond point by point.
read point-by-point responses
-
Referee: [Results / Experiments] The central claim that NeuroFlow achieves superior performance without fidelity trade-offs (relative to isolated specialized models) is load-bearing for the contribution. The results section must include direct head-to-head quantitative comparisons (e.g., Pearson correlation or R² for encoding; perceptual reconstruction error or FID for decoding) with statistical tests, showing that the shared latent space plus reversibility constraint does not degrade either direction.
Authors: We agree that direct head-to-head comparisons with statistical tests are essential to substantiate the central claim. The revised manuscript now includes these in an expanded results section (new Table 3 and Figure 4), reporting Pearson correlation and R² for encoding, FID and perceptual error for decoding, and paired statistical tests (t-tests, p<0.05) against isolated specialized models. The data confirm no fidelity degradation from the shared latent space or reversibility constraint. revision: yes
-
Referee: [Methods (XFM)] §3 (XFM description): the flow-matching objective is presented as exactly invertible between the two marginals, but it is unclear how the training avoids expressiveness compromises that typically arise when enforcing reversibility. An ablation comparing XFM to a non-reversible cross-modal baseline is needed to substantiate that unification incurs no accuracy cost.
Authors: We have expanded §3 to detail how the flow-matching objective is trained directly on paired visual-neural latent samples without modality-specific conditioning that would restrict capacity, preserving full expressiveness for the bidirectional mapping. We also performed the requested ablation against a non-reversible cross-modal baseline (separate VAEs plus a feed-forward mapper) and added the results to Section 4.4; XFM shows equivalent or superior accuracy, confirming the reversibility constraint does not incur a cost. revision: yes
-
Referee: [Abstract / Introduction] The abstract and introduction assert 'superior overall performance … with higher computational efficiency compared to any isolated methods' and 'for the first time' unified modeling, yet the provided text supplies no numerical results, baselines, or efficiency measurements. All such claims must be grounded in the tables/figures of the results section.
Authors: We have revised the abstract and introduction to explicitly reference the supporting tables and figures for every performance and efficiency claim (e.g., 'as shown in Tables 1–3, NeuroFlow achieves...'). We added quantitative efficiency metrics (training time, inference FLOPs) to the results section. The 'for the first time' phrasing is retained only for the specific unified reversible flow construction, which is novel relative to prior separate pipelines. revision: partial
Circularity Check
No circularity: NeuroFlow is a novel architectural proposal, not a derived quantity.
full rationale
The manuscript presents NeuroFlow as a newly constructed unified framework that combines a NeuroVAE variational backbone with a Cross-modal Flow Matching (XFM) module. These components are introduced by design to jointly handle encoding and decoding in a shared latent space; the text does not contain any equations, fitted parameters, or self-citations that reduce the claimed performance or consistency properties back to the inputs by construction. No load-bearing step equates a 'prediction' to a fit, renames a known result, or imports uniqueness from prior author work. The superiority claim rests on empirical comparisons rather than a closed mathematical derivation. This is the expected non-circular outcome for a methods paper that proposes a new model architecture.
Axiom & Free-Parameter Ledger
invented entities (2)
-
NeuroVAE
no independent evidence
-
Cross-modal Flow Matching (XFM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NeuroFlow reformulates visual encoding and decoding as a time-dependent, reversible process within a shared latent space... Cross-modal Flow Matching (XFM) ... cosine interpolation ... dz(t)/dt = v_θ(z_t, t)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NeuroVAE ... probabilistic learning to model neural variability and establish a compact, semantically structured latent space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pre- dicting brain activity using transformers.bioRxiv, pages 2023–08, 2023
Hossein Adeli, Sun Minni, and Nikolaus Kriegeskorte. Pre- dicting brain activity using transformers.bioRxiv, pages 2023–08, 2023. 3
2023
-
[2]
A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1):116–126, 2022
Emily J Allen, Ghislain St-Yves, Yihan Wu, Jesse L Breedlove, Jacob S Prince, Logan T Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, et al. A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1):116–126, 2022. 5, 12
2022
-
[3]
Guangyin Bao, Qi Zhang, Zixuan Gong, Zhuojia Wu, and Duoqian Miao. Mindsimulator: Exploring brain concept localization via synthetic fmri.arXiv preprint arXiv:2503.02351, 2025. 2, 3, 5, 6, 12
-
[4]
From voxels to pixels and back: Self-supervision in natural-image reconstruction from fmri.Advances in Neural Information Processing Systems, 32, 2019
Roman Beliy, Guy Gaziv, Assaf Hoogi, Francesca Strappini, Tal Golan, and Michal Irani. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fmri.Advances in Neural Information Processing Systems, 32, 2019. 2, 3
2019
-
[5]
Yohann Benchetrit, Hubert Banville, and Jean-R ´emi King. Brain decoding: toward real-time reconstruction of visual perception.arXiv preprint arXiv:2310.19812, 2023. 3
-
[6]
Unsupervised learning of visual features by contrasting cluster assignments.Ad- vances in neural information processing systems, 33:9912– 9924, 2020
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Pi- otr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments.Ad- vances in neural information processing systems, 33:9912– 9924, 2020. 5
2020
-
[7]
Seeing beyond the brain: Conditional dif- fusion model with sparse masked modeling for vision decod- ing
Zijiao Chen, Jiaxin Qing, Tiange Xiang, Wan Lin Yue, and Juan Helen Zhou. Seeing beyond the brain: Conditional dif- fusion model with sparse masked modeling for vision decod- ing. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 22710–22720,
-
[8]
Cinematic mindscapes: High-quality video reconstruction from brain activity.Advances in Neural Information Processing Sys- tems, 36, 2024
Zijiao Chen, Jiaxin Qing, and Juan Helen Zhou. Cinematic mindscapes: High-quality video reconstruction from brain activity.Advances in Neural Information Processing Sys- tems, 36, 2024. 3
2024
-
[9]
Yuqin Dai, Zhouheng Yao, Chunfeng Song, Qihao Zheng, Weijian Mai, Kunyu Peng, Shuai Lu, Wanli Ouyang, Jian Yang, and Jiamin Wu. Mindaligner: Explicit brain func- tional alignment for cross-subject visual decoding from lim- ited fmri data.arXiv preprint arXiv:2502.05034, 2025. 3
-
[10]
arXiv preprint arXiv:2209.11737 , volume=
Adrien Doerig, Tim C Kietzmann, Emily Allen, Yihan Wu, Thomas Naselaris, Kendrick Kay, and Ian Charest. Semantic scene descriptions as an objective of human vision.arXiv preprint arXiv:2209.11737, 2022. 3
-
[11]
Population recep- tive field estimates in human visual cortex.Neuroimage, 39 (2):647–660, 2008
Serge O Dumoulin and Brian A Wandell. Population recep- tive field estimates in human visual cortex.Neuroimage, 39 (2):647–660, 2008. 3
2008
-
[12]
Seeing it all: Convolutional network layers map the function of the human visual system.Neu- roImage, 152:184–194, 2017
Michael Eickenberg, Alexandre Gramfort, Ga ¨el Varoquaux, and Bertrand Thirion. Seeing it all: Convolutional network layers map the function of the human visual system.Neu- roImage, 152:184–194, 2017. 3
2017
-
[13]
Considerations for implanting speech brain computer interfaces based on functional magnetic resonance imaging.Journal of Neural Engineering, 21(3):036005,
F Guerreiro Fernandes, M Raemaekers, Z Freudenburg, and N Ramsey. Considerations for implanting speech brain computer interfaces based on functional magnetic resonance imaging.Journal of Neural Engineering, 21(3):036005,
-
[14]
Matteo Ferrante, Furkan Ozcelik, Tommaso Boccato, Rufin VanRullen, and Nicola Toschi. Brain captioning: Decoding human brain activity into images and text.arXiv preprint arXiv:2305.11560, 2023. 3
-
[15]
Softclip: Softer cross-modal alignment makes clip stronger
Yuting Gao, Jinfeng Liu, Zihan Xu, Tong Wu, Enwei Zhang, Ke Li, Jie Yang, Wei Liu, and Xing Sun. Softclip: Softer cross-modal alignment makes clip stronger. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 1860–1868, 2024. 4
2024
-
[16]
Self- supervised natural image reconstruction and large-scale se- mantic classification from brain activity.NeuroImage, 254: 119121, 2022
Guy Gaziv, Roman Beliy, Niv Granot, Assaf Hoogi, Francesca Strappini, Tal Golan, and Michal Irani. Self- supervised natural image reconstruction and large-scale se- mantic classification from brain activity.NeuroImage, 254: 119121, 2022. 2, 3
2022
-
[17]
What opportunities do large-scale visual neural datasets offer to the vision sciences community?Journal of Vision, 24(10): 152–152, 2024
Alessandro T Gifford, Benjamin Lahner, Pablo Oyarzo, Aude Oliva, Gemma Roig, and Radoslaw M Cichy. What opportunities do large-scale visual neural datasets offer to the vision sciences community?Journal of Vision, 24(10): 152–152, 2024. 3
2024
-
[18]
Lite-mind: Towards efficient and robust brain representation learning
Zixuan Gong, Qi Zhang, Guangyin Bao, Lei Zhu, Yu Zhang, KE LIU, Liang Hu, and Duoqian Miao. Lite-mind: Towards efficient and robust brain representation learning. InACM Multimedia 2024, 2024. 3
2024
-
[19]
Personalized visual encoding model construc- tion with small data.Communications Biology, 5(1):1382,
Zijin Gu, Keith Jamison, Mert Sabuncu, and Amy Kuceyeski. Personalized visual encoding model construc- tion with small data.Communications Biology, 5(1):1382,
-
[20]
Deep neural net- works reveal a gradient in the complexity of neural represen- tations across the ventral stream.Journal of Neuroscience, 35(27):10005–10014, 2015
Umut G ¨uc ¸l¨u and Marcel AJ Van Gerven. Deep neural net- works reveal a gradient in the complexity of neural represen- tations across the ventral stream.Journal of Neuroscience, 35(27):10005–10014, 2015. 3
2015
-
[21]
Neuro-3d: Towards 3d visual decoding from eeg signals
Zhanqiang Guo, Jiamin Wu, Yonghao Song, Jiahui Bu, Wei- jian Mai, Qihao Zheng, Wanli Ouyang, and Chunfeng Song. Neuro-3d: Towards 3d visual decoding from eeg signals. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 23870–23880, 2025. 3
2025
-
[22]
Variational au- toencoder: An unsupervised model for encoding and decod- ing fmri activity in visual cortex.NeuroImage, 198:125–136,
Kuan Han, Haiguang Wen, Junxing Shi, Kun-Han Lu, Yizhen Zhang, Di Fu, and Zhongming Liu. Variational au- toencoder: An unsupervised model for encoding and decod- ing fmri activity in visual cortex.NeuroImage, 198:125–136,
-
[23]
Natural speech reveals the semantic maps that tile human cerebral cortex
Alexander G Huth, Wendy A De Heer, Thomas L Griffiths, Fr´ed´eric E Theunissen, and Jack L Gallant. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600):453–458, 2016. 1
2016
-
[24]
Decoding the visual and subjective contents of the human brain.Nature neuroscience, 8(5):679–685, 2005
Yukiyasu Kamitani and Frank Tong. Decoding the visual and subjective contents of the human brain.Nature neuroscience, 8(5):679–685, 2005. 3 9
2005
-
[25]
High-level visual ar- eas act like domain-general filters with strong selectivity and functional specialization.bioRxiv, pages 2022–03, 2022
Meenakshi Khosla and Leila Wehbe. High-level visual ar- eas act like domain-general filters with strong selectivity and functional specialization.bioRxiv, pages 2022–03, 2022. 3
2022
-
[26]
Characterizing the ventral visual stream with response-optimized neural encoding models.Advances in Neural Information Processing Systems, 35:9389–9402,
Meenakshi Khosla, Keith Jamison, Amy Kuceyeski, and Mert Sabuncu. Characterizing the ventral visual stream with response-optimized neural encoding models.Advances in Neural Information Processing Systems, 35:9389–9402,
-
[27]
what” and “where
David Klindt, Alexander S Ecker, Thomas Euler, and Matthias Bethge. Neural system identification for large pop- ulations separating “what” and “where”.Advances in neural information processing systems, 30, 2017. 3
2017
-
[28]
Parallel backpropagation for shared-feature visualization.Advances in Neural Information Processing Systems, 37:22993–23012, 2024
Alexander Lappe, Anna Bogn ´ar, Ghazaleh Ghamkahri Ne- jad, Albert Mukovskiy, Lucas Martini, Martin Giese, and Rufin V ogels. Parallel backpropagation for shared-feature visualization.Advances in Neural Information Processing Systems, 37:22993–23012, 2024. 3
2024
-
[29]
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Haoyang Qin, and Quanying Liu. Visual decoding and reconstruction via eeg embeddings with guided diffusion.arXiv preprint arXiv:2403.07721, 2024. 3
-
[30]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages 740–755,
-
[31]
Flow matching for generative mod- eling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling. In11th International Conference on Learning Repre- sentations, ICLR 2023, 2023. 5
2023
-
[32]
Yulong Liu, Yongqiang Ma, Wei Zhou, Guibo Zhu, and Nan- ning Zheng. Brainclip: Bridging brain and visual-linguistic representation via clip for generic natural visual stimulus de- coding from fmri.arXiv preprint arXiv:2302.12971, 2023. 3
-
[33]
Weiheng Lu, Chunfeng Song, Jiamin Wu, Pengyu Zhu, Yuchen Zhou, Weijian Mai, Qihao Zheng, and Wanli Ouyang. Unimind: Unleashing the power of llms for unified multi-task brain decoding.arXiv preprint arXiv:2506.18962, 2025
work page internal anchor Pith review arXiv 2025
-
[34]
Yizhuo Lu, Changde Du, Dianpeng Wang, and Huiguang He. Minddiffuser: Controlled image reconstruction from human brain activity with semantic and structural diffusion.arXiv preprint arXiv:2303.14139, 2023. 3
-
[35]
Brain diffusion for visual exploration: Cortical discov- ery using large scale generative models.Advances in Neural Information Processing Systems, 36, 2024
Andrew Luo, Maggie Henderson, Leila Wehbe, and Michael Tarr. Brain diffusion for visual exploration: Cortical discov- ery using large scale generative models.Advances in Neural Information Processing Systems, 36, 2024. 2, 3
2024
-
[36]
Sit: Explor- ing flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Explor- ing flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Com- puter Vision, pages 23–40. Springer, 2024. 5, 13
2024
-
[37]
Weijian Mai and Zhijun Zhang. Unibrain: Unify image reconstruction and captioning all in one diffusion model from human brain activity.arXiv preprint arXiv:2308.07428,
-
[38]
Brain-conditional multimodal synthesis: A survey and tax- onomy.IEEE Transactions on Artificial Intelligence, 2024
Weijian Mai, Jian Zhang, Pengfei Fang, and Zhijun Zhang. Brain-conditional multimodal synthesis: A survey and tax- onomy.IEEE Transactions on Artificial Intelligence, 2024. 2
2024
-
[39]
Weijian Mai, Jiamin Wu, Yu Zhu, Zhouheng Yao, Dongzhan Zhou, Andrew F Luo, Qihao Zheng, Wanli Ouyang, and Chunfeng Song. Synbrain: Enhancing visual-to-fmri synthe- sis via probabilistic representation learning.arXiv preprint arXiv:2508.10298, 2025. 2, 3, 4, 5, 6, 12, 13
-
[40]
Predicting human brain activity associ- ated with the meanings of nouns.science, 320(5880):1191– 1195, 2008
Tom M Mitchell, Svetlana V Shinkareva, Andrew Carlson, Kai-Min Chang, Vicente L Malave, Robert A Mason, and Marcel Adam Just. Predicting human brain activity associ- ated with the meanings of nouns.science, 320(5880):1191– 1195, 2008. 1
2008
-
[41]
Encoding and decoding in fmri.Neuroimage, 56(2):400–410, 2011
Thomas Naselaris, Kendrick N Kay, Shinji Nishimoto, and Jack L Gallant. Encoding and decoding in fmri.Neuroimage, 56(2):400–410, 2011. 2, 3, 5
2011
-
[42]
Beyond mind-reading: multi-voxel pattern analysis of fmri data.Trends in cognitive sciences, 10(9): 424–430, 2006
Kenneth A Norman, Sean M Polyn, Greg J Detre, and James V Haxby. Beyond mind-reading: multi-voxel pattern analysis of fmri data.Trends in cognitive sciences, 10(9): 424–430, 2006. 3
2006
-
[43]
Natural scene recon- struction from fmri signals using generative latent diffusion
Furkan Ozcelik and Rufin VanRullen. Natural scene recon- struction from fmri signals using generative latent diffusion. Scientific Reports, 13(1):15666, 2023. 3, 6
2023
-
[44]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[45]
LEA: Learning latent em- bedding alignment model for fMRI decoding and encoding
Xuelin Qian, Yikai Wang, Xinwei Sun, Yanwei Fu, Xi- angyang Xue, and Jianfeng Feng. LEA: Learning latent em- bedding alignment model for fMRI decoding and encoding. Transactions on Machine Learning Research, 2024. 2, 3
2024
-
[46]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3, 5
2021
-
[47]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[48]
Reconstructing seen image from brain activity by visually-guided cognitive representation and ad- versarial learning.NeuroImage, 228:117602, 2021
Ziqi Ren, Jie Li, Xuetong Xue, Xin Li, Fan Yang, Zhicheng Jiao, and Xinbo Gao. Reconstructing seen image from brain activity by visually-guided cognitive representation and ad- versarial learning.NeuroImage, 228:117602, 2021. 3
2021
-
[49]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 3
2022
-
[50]
Brain dissection: fmri-trained networks re- veal spatial selectivity in the processing of natural images
Gabriel H Sarch, Michael J Tarr, Katerina Fragkiadaki, and Leila Wehbe. Brain dissection: fmri-trained networks re- veal spatial selectivity in the processing of natural images. bioRxiv, pages 2023–05, 2023. 3
2023
-
[51]
Re- constructing the mind’s eye: fmri-to-image with contrastive learning and diffusion priors.Advances in Neural Informa- tion Processing Systems, 36:24705–24728, 2023
Paul Scotti, Atmadeep Banerjee, Jimmie Goode, Stepan Sha- balin, Alex Nguyen, Aidan Dempster, Nathalie Verlinde, 10 Elad Yundler, David Weisberg, Kenneth Norman, et al. Re- constructing the mind’s eye: fmri-to-image with contrastive learning and diffusion priors.Advances in Neural Informa- tion Processing Systems, 36:24705–24728, 2023. 5, 6
2023
-
[52]
Paul S Scotti, Mihir Tripathy, Cesar Kadir Torrico Vil- lanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A Norman, et al. Mindeye2: Shared-subject mod- els enable fmri-to-image with 1 hour of data.arXiv preprint arXiv:2403.11207, 2024. 3, 5, 6, 12, 13
-
[53]
Generative adver- sarial networks for reconstructing natural images from brain activity.NeuroImage, 181:775–785, 2018
Katja Seeliger, Umut G ¨uc ¸l¨u, Luca Ambrogioni, Yagmur G¨uc ¸l¨ut¨urk, and Marcel AJ van Gerven. Generative adver- sarial networks for reconstructing natural images from brain activity.NeuroImage, 181:775–785, 2018. 3
2018
-
[54]
Deep image reconstruction from human brain activity.PLoS computational biology, 15(1):e1006633,
Guohua Shen, Tomoyasu Horikawa, Kei Majima, and Yukiyasu Kamitani. Deep image reconstruction from human brain activity.PLoS computational biology, 15(1):e1006633,
-
[55]
Neuro-vision to language: Enhancing brain recording-based visual reconstruction and language interaction.Advances in Neural Information Processing Systems, 37:98083–98110,
Guobin Shen, Dongcheng Zhao, Xiang He, Linghao Feng, Yiting Dong, Jihang Wang, Qian Zhang, and Yi Zeng. Neuro-vision to language: Enhancing brain recording-based visual reconstruction and language interaction.Advances in Neural Information Processing Systems, 37:98083–98110,
-
[56]
Rethinking the inception archi- tecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception archi- tecture for computer vision. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2818–2826, 2016. 5
2016
-
[57]
High-resolution image recon- struction with latent diffusion models from human brain ac- tivity
Y Takagi and S Nishimoto. High-resolution image recon- struction with latent diffusion models from human brain ac- tivity. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 14453–14463,
-
[58]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational conference on machine learning, pages 6105–6114. PMLR,
-
[59]
Brain encoding models based on multimodal trans- formers can transfer across language and vision.Advances in neural information processing systems, 36:29654–29666,
Jerry Tang, Meng Du, Vy V o, Vasudev Lal, and Alexander Huth. Brain encoding models based on multimodal trans- formers can transfer across language and vision.Advances in neural information processing systems, 36:29654–29666,
-
[60]
Mindbridge: A cross-subject brain decoding frame- work
Shizun Wang, Songhua Liu, Zhenxiong Tan, and Xinchao Wang. Mindbridge: A cross-subject brain decoding frame- work. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 11333–11342,
-
[61]
Neural encoding and decod- ing with deep learning for dynamic natural vision.Cerebral cortex, 28(12):4136–4160, 2018
Haiguang Wen, Junxing Shi, Yizhen Zhang, Kun-Han Lu, Ji- ayue Cao, and Zhongming Liu. Neural encoding and decod- ing with deep learning for dynamic natural vision.Cerebral cortex, 28(12):4136–4160, 2018. 3
2018
-
[62]
Dream: Visual decoding from reversing human vi- sual system
Weihao Xia, Raoul de Charette, Cengiz Oztireli, and Jing- Hao Xue. Dream: Visual decoding from reversing human vi- sual system. InProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, pages 8226–8235,
-
[63]
Umbrae: Unified multimodal brain decoding
Weihao Xia, Raoul de Charette, Cengiz Oztireli, and Jing- Hao Xue. Umbrae: Unified multimodal brain decoding. In European Conference on Computer Vision, pages 242–259. Springer, 2024. 3
2024
-
[64]
Versatile diffusion: Text, images and variations all in one diffusion model
Xingqian Xu, Zhangyang Wang, Gong Zhang, Kai Wang, and Humphrey Shi. Versatile diffusion: Text, images and variations all in one diffusion model. InProceedings of the IEEE/CVF international conference on computer vision, pages 7754–7765, 2023. 3
2023
-
[65]
AlignedCut: Visual Concepts Discovery on Brain-Guided Universal Feature Space
Huzheng Yang, James Gee, and Jianbo Shi. Alignedcut: Visual concepts discovery on brain-guided universal feature space.arXiv preprint arXiv:2406.18344, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Brain decodes deep nets
Huzheng Yang, James Gee, and Jianbo Shi. Brain decodes deep nets. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23030– 23040, 2024. 3
2024
-
[67]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review arXiv
-
[68]
Muquan Yu, Mu Nan, Hossein Adeli, Jacob S Prince, John A Pyles, Leila Wehbe, Margaret M Henderson, Michael J Tarr, and Andrew F Luo. Meta-learning an in-context trans- former model of human higher visual cortex.arXiv preprint arXiv:2505.15813, 2025. 3
-
[69]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 3
2023
-
[70]
Yuchen Zhou, Jiamin Wu, Zichen Ren, Zhouheng Yao, Weiheng Lu, Kunyu Peng, Qihao Zheng, Chunfeng Song, Wanli Ouyang, and Chao Gou. Csbrain: A cross-scale spa- tiotemporal brain foundation model for eeg decoding.arXiv preprint arXiv:2506.23075, 2025. 3 11 A. NSD Dataset In this study, we leverage the largest publicly available fMRI-image dataset, the Natura...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.