Recognition: unknown
Logical Compilation for Multi-Qubit Iceberg Patches
Pith reviewed 2026-05-10 16:42 UTC · model grok-4.3
The pith
A new compiler optimizes qubit mappings and merges gates for high-rate Iceberg codes to cut circuit depth by 34%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
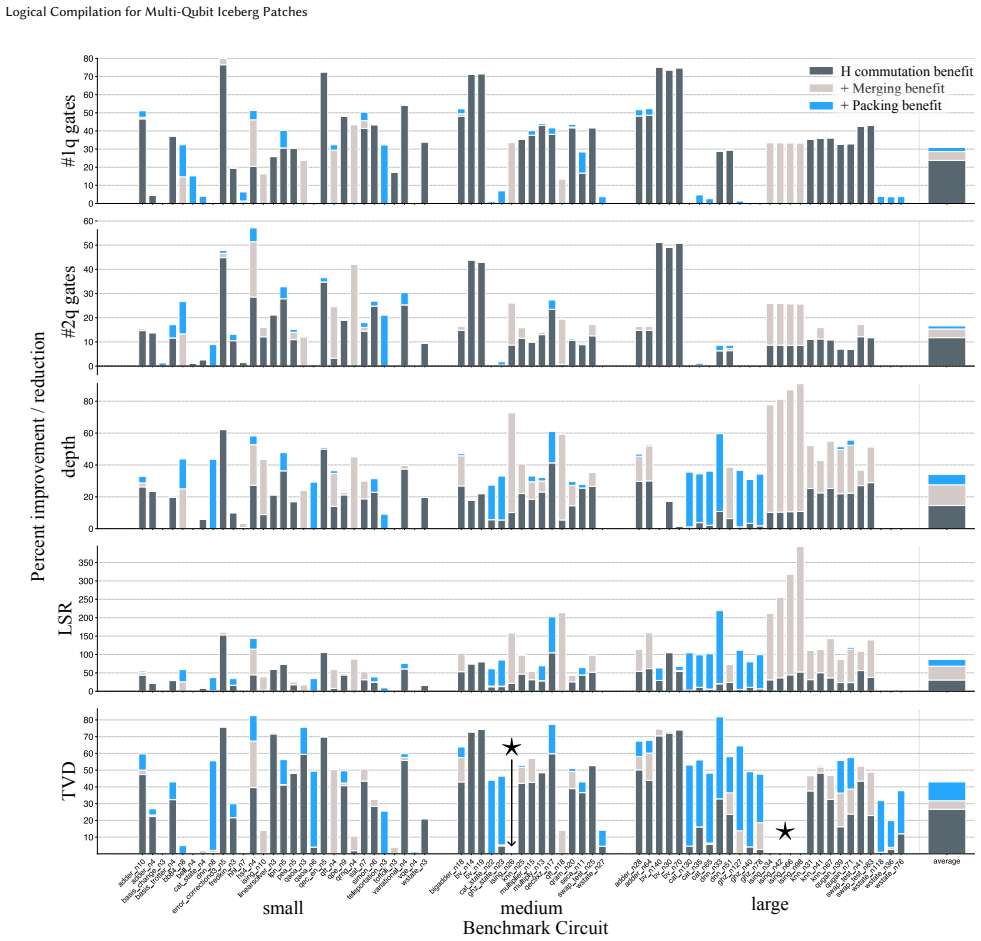
The paper claims that pairing logical-to-physical compilation via Hadamard commutation and gate merging with a merge-optimizing, noise-biased packing heuristic for qubit-to-logical assignment enables practical compilation for multi-qubit Iceberg patches. Across 71 benchmark circuits this yields a 34% average reduction in circuit depth, reductions of up to 31% in one-qubit gates and 17% in two-qubit gates, a 1.75 times improvement in total variation distance, and an 86% average improvement in logical selection rate relative to naive compilation.
What carries the argument
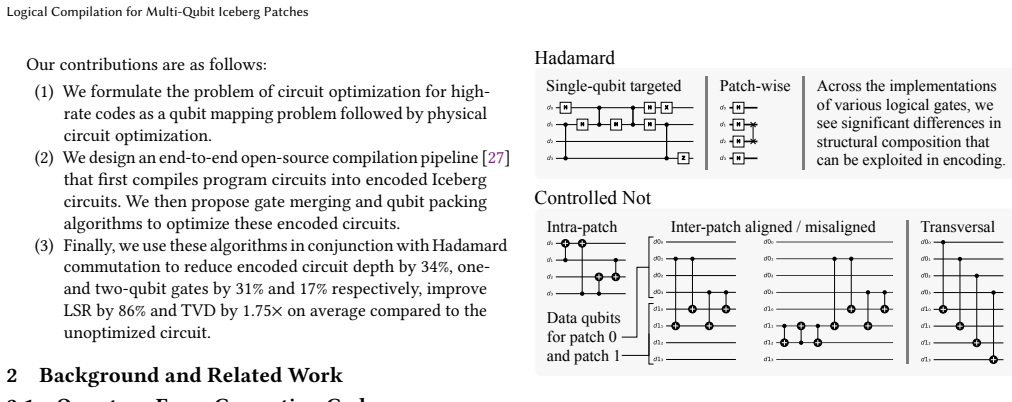
The merge-optimizing, noise-biased packing heuristic that selects qubit-to-logical mappings, supported by Hadamard commutation and gate merging during logical-to-physical translation.
If this is right
- Circuit depth falls by 34% on average across standard benchmarks.
- One-qubit gate counts decrease by as much as 31%.
- Two-qubit gate counts decrease by 17%.
- Total variation distance improves by a factor of 1.75.
- Logical selection rate rises by 86% on average.
Where Pith is reading between the lines
- The same heuristic search could be applied to other high-rate codes that place multiple logical qubits inside a single patch.
- The mapping step could be inserted into existing compilation pipelines that already perform routing or scheduling.
- Higher logical selection rates open the possibility of runtime remapping when circuit structure changes mid-execution.
Load-bearing premise
The merge-optimizing, noise-biased packing heuristic reliably identifies high-performing qubit assignments for practical circuits without exhaustive search.
What would settle it
Enumerating all mappings on small benchmark circuits and checking whether the heuristic consistently returns assignments whose fidelity lies within a few percent of the best possible mapping would directly test the claim.
Figures















read the original abstract
Recent advancements in quantum computing have enabled practical use of quantum error detecting and correcting codes. However, current architectures and future proposals of quantum computer design suffer from limited qubit counts, necessitating the use of high-rate codes. Such codes, with their code parameters denoted as $[[n, k, d]]$, have more than $1$ logical qubit per code (i.e., $k > 1$). This leads to reduced error tolerance of the code, since $\lceil (d-1)/2\rceil$ errors on any of the $n$ physical qubits can affect the logical state of all $k$ logical qubits. Therefore, it becomes critical to optimally map the input qubits of a quantum circuit to these codes, in such a way that the circuit fidelity is maximized. \par However, the problem of mapping program qubits to logical qubits for high-rate codes has not been studied in prior work. A brute force search to find the optimal mapping is super exponential (scaling as $O(n!)$, where $n$ is the number of input qubits), making exhaustive search infeasible past a small number of qubits. We propose a framework that addresses this problem on two fronts: (1) for any given mapping, it performs logical-to-physical compilation that translates input gates into efficiently encoded implementations utilizing Hadamard commutation and gate merging; and (2) it quickly searches the space of possible mappings through a merge-optimizing, noise-biased packing heuristic that identifies high-performing qubit assignments without exhaustive enumeration. To the best of our knowledge, our compiler is the first work to explore mapping and compilation for high-rate codes. Across 71 benchmark circuits, we reduce circuit depth by $34\%$, gate counts by up to $31\%$ and $17\%$ for one-qubit and two-qubit gates, and improve total variation distance by $1.75\times$, with logical selection rate improvements averaging $86\%$ relative to naive compilation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-part framework for compiling quantum circuits to high-rate error-detecting codes (e.g., Iceberg patches [[n,k,d]] with k>1). Part (1) performs logical-to-physical compilation via Hadamard commutation and gate merging to produce efficient encoded implementations. Part (2) searches the mapping space with a merge-optimizing, noise-biased packing heuristic that avoids O(n!) exhaustive enumeration. On 71 benchmark circuits the authors report 34% depth reduction, up to 31%/17% reductions in 1Q/2Q gate counts, 1.75× TVD improvement, and 86% average logical-selection-rate gain versus naive compilation.
Significance. If the heuristic is shown to be reliable, the work would be significant as the first systematic treatment of mapping and compilation for high-rate codes, directly addressing the tension between limited physical qubit counts and the need for k>1 logical qubits. The concrete benchmark gains and the explicit separation of compilation from mapping search provide a practical path toward higher-fidelity execution on near-term hardware.
major comments (1)
- [§5 (Evaluation)] §5 (Evaluation): The headline performance numbers (34% depth, 31%/17% gate-count, 1.75× TVD, 86% selection-rate gains) are generated exclusively by the merge-optimizing noise-biased packing heuristic. No comparison against the exact optimum is supplied for any circuit with ≤6 program qubits, where brute-force enumeration of all mappings is computationally feasible. Because the central claim is that the heuristic reliably identifies high-performing assignments, the absence of this sanity check leaves open the possibility that the reported advantage over the (unspecified) naive baseline is smaller than claimed or even absent on some instances.
minor comments (2)
- [Abstract and §3] Abstract and §3: the baseline labeled 'naive compilation' is never defined; the reader cannot determine whether it corresponds to random mapping, identity mapping, or some other standard procedure.
- [Abstract] Abstract: the statement 'super exponential (scaling as O(n!))' is imprecise; factorial growth is exponential in n log n. A brief clarification of the precise complexity would aid readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment below and will revise the manuscript to strengthen the evaluation as indicated.
read point-by-point responses
-
Referee: The headline performance numbers (34% depth, 31%/17% gate-count, 1.75× TVD, 86% selection-rate gains) are generated exclusively by the merge-optimizing noise-biased packing heuristic. No comparison against the exact optimum is supplied for any circuit with ≤6 program qubits, where brute-force enumeration of all mappings is computationally feasible. Because the central claim is that the heuristic reliably identifies high-performing assignments, the absence of this sanity check leaves open the possibility that the reported advantage over the (unspecified) naive baseline is smaller than claimed or even absent on some instances.
Authors: We agree that a direct comparison of the heuristic to the exact optimal mapping for circuits with ≤6 program qubits would provide valuable validation of its reliability. While the manuscript emphasizes results on larger benchmarks where exhaustive search is intractable, we acknowledge that including this sanity check for small instances would address the concern about the magnitude of improvement over the naive baseline. In the revised manuscript, we will add a new subsection to §5 that enumerates all mappings for every benchmark circuit with up to 6 program qubits, reports the optimality gap of the heuristic, and confirms that it consistently identifies high-performing assignments. revision: yes
Circularity Check
No circularity: empirical evaluation of independent heuristic against naive baseline
full rationale
The paper defines a merge-optimizing noise-biased packing heuristic and a logical-to-physical compilation procedure, then reports empirical improvements on 71 external benchmark circuits relative to an unspecified naive baseline. No equations, parameters, or results are shown to reduce by construction to the inputs (no fitted-input-called-prediction, no self-definitional mapping, no load-bearing self-citation chain). The central claims remain independent of the reported numbers.
Axiom & Free-Parameter Ledger
free parameters (1)
- noise bias weight
axioms (1)
- domain assumption Hadamard commutation and gate merging preserve correctness when translating gates into the encoded patch.
Reference graph
Works this paper leans on
-
[1]
Bedalov, Matt Blakely, Peter D
Matt J. Bedalov, Matt Blakely, Peter D. Buttler, Caitlin Carnahan, Frederic T. Chong, Woo Chang Chung, Dan C. Cole, Palash Goiporia, Pranav Gokhale, Bettina Heim, Garrett T. Hickman, Eric B. Jones, Ryan A. Jones, Pradnya Khalate, Jin-Sung Kim, Kevin W. Kuper, Martin T. Lichtman, Stephanie Lee, David Mason, Nathan A. Neff-Mallon, Thomas W. Noel, Victory Om...
-
[2]
Sergey Bravyi, Andrew W. Cross, Jay M. Gambetta, Dmitri Maslov, Patrick Rall, and Theodore J. Yoder. 2024. High-threshold and low-overhead fault-tolerant quantum memory.Nature627 (2024), 778–782. https://doi.org/10.1038/s41586- 024-07107-7
- [3]
-
[4]
Poulami Das, Eric Kessler, and Yunong Shi. 2023. The Imitation Game: Leveraging CopyCats for Robust Native Gate Selection in NISQ Programs. In2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 787–801. https://doi.org/10.1109/HPCA56546.2023.10071025
-
[5]
Austin G Fowler, Matteo Mariantoni, John M Martinis, and Andrew N Cleland
-
[6]
Surface codes: Towards practical large-scale quantum computation.Physi- cal Review A—Atomic, Molecular, and Optical Physics86, 3 (2012), 032324
2012
-
[7]
Craig Gidney. 2021. Stim: a fast stabilizer circuit simulator.Quantum5 (July 2021), 497. https://doi.org/10.22331/q-2021-07-06-497
-
[8]
Craig Gidney and Martin Ekerå. 2021. How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits.Quantum5 (April 2021), 433. https: //doi.org/10.22331/q-2021-04-15-433 arXiv:1905.09749 [quant-ph]
-
[9]
Craig Gidney, Michael Newman, Peter Brooks, and Cody Jones. 2023. Yoked surface codes. https://doi.org/10.48550/arXiv.2312.04522 arXiv:2312.04522 [quant-ph]
-
[10]
Tom Ginsberg and Vyom Patel. 2025. Quantum Error Detection For Early Term Fault-Tolerant Quantum Algorithms. https://doi.org/10.48550/arXiv.2503.10790 arXiv:2503.10790 [quant-ph]
-
[11]
Williamson, and Theodore J
Zhiyang He, Alexander Cowtan, Dominic J. Williamson, and Theodore J. Yoder
-
[12]
Extractors: QLDPC Architectures for Efficient Pauli-Based Computation,
Extractors: QLDPC Architectures for Efficient Pauli-Based Computation. https://doi.org/10.48550/arXiv.2503.10390 arXiv:2503.10390 [quant-ph]
-
[13]
Dominic Horsman, Austin G Fowler, Simon Devitt, and Rodney Van Meter. 2012. Surface code quantum computing by lattice surgery.New Journal of Physics14, 12 (2012), 123011
2012
-
[14]
Fei Hua, Yanhao Chen, Yuwei Jin, Chi Zhang, Ari Hayes, Youtao Zhang, and Eddy Z Zhang. 2021. Autobraid: A framework for enabling efficient surface code communication in quantum computing. InMICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture. 925–936
2021
-
[15]
Yuwei Jin, Zichang He, Tianyi Hao, David Amaro, Swamit Tannu, Ruslan Shaydulin, and Marco Pistoia. 2025. Iceberg Beyond the Tip: Co-Compilation of a Quantum Error Detection Code and a Quantum Algorithm. https: //doi.org/10.48550/arXiv.2504.21172 arXiv:2504.21172 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.21172 2025
-
[16]
Aleksander Marek Kubica. 2018.The ABCs of the Color Code: A Study of Topo- logical Quantum Codes as Toy Models for Fault-Tolerant Quantum Computa- tion and Quantum Phases Of Matter. phd. California Institute of Technology. https://doi.org/10.7907/059V-MG69
-
[17]
Tyler LeBlond, Christopher Dean, George Watkins, and Ryan Bennink. 2024. Realistic cost to execute practical quantum circuits using direct clifford+ t lattice surgery compilation.ACM Transactions on Quantum Computing5, 4 (2024), 1–28
2024
- [18]
-
[19]
Daniel Litinski. 2018. A Game of Surface Codes: Large-Scale Quantum Computing with Lattice Surgery.Quantum3 (Aug. 2018). https://doi.org/10.22331/q-2019- 03-05-128
-
[20]
Daniel Litinski. 2025. Blocklet concatenation: Low-overhead fault-tolerant pro- tocols for fusion-based quantum computation. https://doi.org/10.48550/arXiv. 2506.13619 arXiv:2506.13619 [quant-ph]
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[21]
Hannah J Manetsch, Gyohei Nomura, Elie Bataille, Xudong Lv, Kon H Leung, and Manuel Endres. 2025. A tweezer array with 6,100 highly coherent atomic qubits.Nature647, 8088 (2025), 60–67
2025
-
[22]
Manetsch, Gyohei Nomura, Elie Bataille, Kon H
Hannah J. Manetsch, Gyohei Nomura, Elie Bataille, Xudong Lv, Kon H. Leung, and Manuel Endres. 2025. A tweezer array with 6,100 highly coherent atomic qubits. Nature647, 8088 (Nov. 2025), 60–67. https://doi.org/10.1038/s41586-025-09641-4
-
[23]
Abtin Molavi, Amanda Xu, Swamit Tannu, and Aws Albarghouthi. 2025. Dependency-aware compilation for surface code quantum architectures.Pro- ceedings of the ACM on Programming Languages9, OOPSLA1 (2025), 57–84
2025
-
[24]
Demonstration of logical qubits and repeated error correction with better-than-physical error rates,
A. Paetznick, M. P. da Silva, C. Ryan-Anderson, J. M. Bello-Rivas, J. P. Campora, A. Chernoguzov, J. M. Dreiling, C. Foltz, F. Frachon, J. P. Gaebler, T. M. Gatterman, 12 Logical Compilation for Multi-Qubit Iceberg Patches L. Grans-Samuelsson, D. Gresh, D. Hayes, N. Hewitt, C. Holliman, C. V. Horst, J. Johansen, D. Lucchetti, Y. Matsuoka, M. Mills, S. A. ...
-
[25]
Teo, Joshua Viszlai, Daniel C
Rich Rines, Benjamin Hall, Mariesa H. Teo, Joshua Viszlai, Daniel C. Cole, David Mason, Cameron Barker, Matt J. Bedalov, Matt Blakely, Tobias Bothwell, Caitlin Carnahan, Frederic T. Chong, Samuel Y. Eubanks, Brian Fields, Matthew Gillette, Palash Goiporia, Pranav Gokhale, Garrett T. Hickman, Marin Iliev, Eric B. Jones, Ryan A. Jones, Kevin W. Kuper, Steph...
-
[26]
Demonstration of a Logical Architecture Uniting Motion and In-Place Entanglement
Demonstration of a Logical Architecture Uniting Motion and In-Place Entanglement: Shor’s Algorithm, Constant-Depth CNOT Ladder, and Many- Hypercube Code. https://doi.org/10.48550/arXiv.2509.13247 arXiv:2509.13247 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.13247
-
[27]
Self, Marcello Benedetti, and David Amaro
Chris N. Self, Marcello Benedetti, and David Amaro. 2024. Protecting Expressive Circuits with a Quantum Error Detection Code.Nature Physics20, 2 (Feb. 2024), 219–224. https://doi.org/10.1038/s41567-023-02282-2 arXiv:2211.06703 [quant- ph]
- [28]
-
[29]
Barbara M Terhal. 2015. Quantum error correction for quantum memories. Reviews of Modern Physics87, 2 (2015), 307–346
2015
-
[30]
2026.https:// github.com/ Baker-Group-UT/ iceberg-compiler
Baker Group UT. 2026.https:// github.com/ Baker-Group-UT/ iceberg-compiler. GitHub repository, accessed April 10, 2026
2026
-
[31]
Joshua Viszlai, Willers Yang, Sophia Fuhui Lin, Junyu Liu, Natalia Nottingham, Jonathan M Baker, and Frederic T Chong. 2025. Matching Generalized-Bicycle Codes to Neutral Atoms for Low-Overhead Fault-Tolerance. In2025 IEEE In- ternational Conference on Quantum Computing and Engineering (QCE), Vol. 01. 688–699. https://doi.org/10.1109/QCE65121.2025.00080
-
[32]
George Watkins, Hoang Minh Nguyen, Keelan Watkins, Steven Pearce, Hoi- Kwan Lau, and Alexandru Paler. 2024. A high performance compiler for very large scale surface code computations.Quantum8 (2024), 1354
2024
-
[33]
Pablo Bonilla Ataides, Christopher A
Qian Xu, J. Pablo Bonilla Ataides, Christopher A. Pattison, Nithin Raveendran, Dolev Bluvstein, Jonathan Wurtz, Bane Vasić, Mikhail D. Lukin, Liang Jiang, and Hengyun Zhou. 2024. Constant-overhead fault-tolerant quantum computation with reconfigurable atom arrays.Nature Physics20 (2024), 1084–1090. https: //doi.org/10.1038/s41567-024-02479-z
-
[34]
Min Ye and Nicolas Delfosse. 2025. Quantum error correction for long chains of trapped ions.arXiv(2025). https://doi.org/10.48550/arxiv.2503.22071 A Appendix We utilize the following gates seen in Figures 14, 16, 15 in the translation pass for creating encoded circuits from input program circuits. A.1 Fidelity Improvement Reducing spacetime resources is a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.