Recognition: unknown
When Can You Poison Rewards? A Tight Characterization of Reward Poisoning in Linear MDPs
Pith reviewed 2026-05-10 16:30 UTC · model grok-4.3
The pith
Linear MDPs are vulnerable to reward poisoning exactly when the attack budget exceeds their intrinsic robustness threshold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper proves that a linear MDP admits a successful reward-poisoning attack with budget B if and only if B is at least as large as the minimum cost required to change the optimal policy; that minimum cost is fully determined by the MDP's linear feature representation, transition structure, and reward function.
What carries the argument
The intrinsic robustness measure of the linear MDP, equal to the smallest total reward perturbation that alters the optimal policy.
If this is right
- Below the threshold, even standard non-robust RL algorithms cannot be forced to adopt the attacker's target policy.
- Above the threshold, an attacker can efficiently construct a poisoning strategy that succeeds.
- The same threshold approximately predicts attackability when deep RL environments are treated as linear MDPs.
- Robust linear MDPs remain safe under vanilla learning even when the attacker knows the full model.
Where Pith is reading between the lines
- Designers could adjust MDP features or transitions to push the robustness threshold higher and create inherently safe tasks.
- In deployed systems the threshold could be computed first to decide whether extra defense layers are worth the cost.
- The same budget-comparison logic may apply to other forms of reward or dynamics poisoning in reinforcement learning.
- Controlled experiments on synthetic linear MDPs with known thresholds would directly test whether attack success matches the predicted boundary.
Load-bearing premise
The environment is exactly representable as a linear MDP whose features and transitions are known to the attacker.
What would settle it
A concrete linear MDP together with a budget B below the computed robustness threshold for which a poisoning attack nevertheless succeeds in changing the learned policy.
Figures




read the original abstract
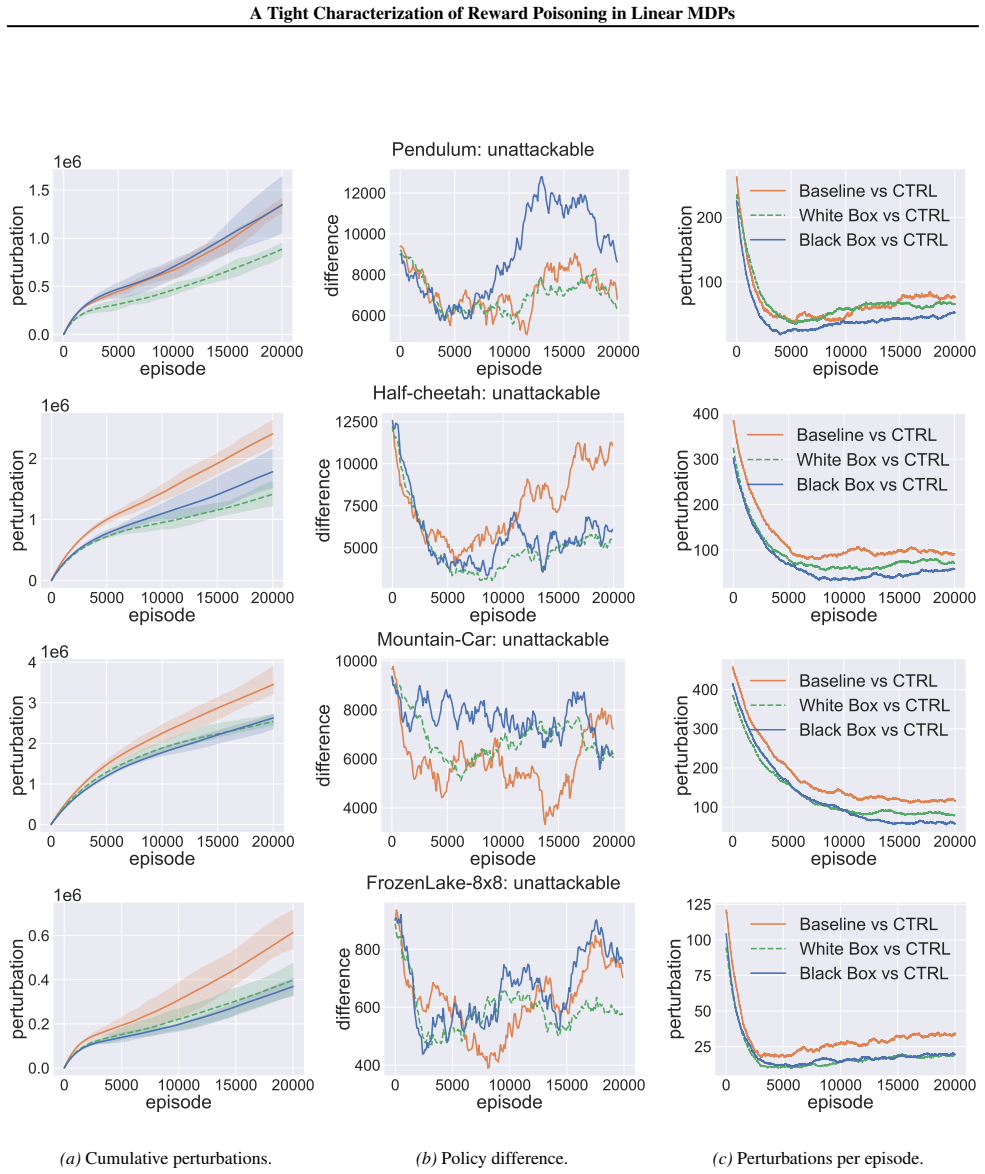
We study reward poisoning attacks in reinforcement learning (RL), where an adversary manipulates rewards within constrained budgets to force the target RL agent to adopt a policy that aligns with the attacker's objectives. Prior works on reward poisoning mainly focused on sufficient conditions to design a successful attacker, while only a few studies discussed the infeasibility of targeted attacks. This paper provides the first precise necessity and sufficiency characterization of the attackability of a linear MDP under reward poisoning attacks. Our characterization draws a bright line between the vulnerable RL instances, and the intrinsically robust ones which cannot be attacked without large costs even running vanilla non-robust RL algorithms. Our theory extends beyond linear MDPs -- by approximating deep RL environments as linear MDPs, we show that our theoretical framework effectively distinguishes the attackability and efficiently attacks the vulnerable ones, demonstrating both the theoretical and practical significance of our characterization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies reward poisoning attacks in reinforcement learning where an adversary manipulates rewards under a budget to force a target policy. It claims to deliver the first tight necessity-and-sufficiency characterization of attackability for linear MDPs (with linear rewards and transitions in a known feature map), cleanly separating vulnerable instances from intrinsically robust ones that resist attacks even under vanilla non-robust RL. The work further approximates deep RL environments as linear MDPs to demonstrate both attackability prediction and efficient attacks on vulnerable cases.
Significance. If the necessity and sufficiency conditions hold under the standard linear-MDP definition, the result would be significant: it supplies the first precise boundary between attackable and robust linear MDPs, directly informing when non-robust algorithms suffice and when defenses are required. The extension via linear approximation to deep RL adds practical relevance by showing how the theory can guide real-world attack and defense design.
minor comments (3)
- [Abstract] Abstract: the claim of a 'tight characterization' and 'bright line' would be strengthened by a one-sentence statement of the main necessary and sufficient condition (e.g., in terms of the feature map or value-function gap) rather than leaving it entirely implicit.
- [Section 5 (or equivalent experimental section)] The linear-MDP approximation step for deep RL environments is described at a high level; adding a short paragraph on the approximation error, the choice of feature map, and any empirical validation of the approximation quality would improve clarity and reproducibility.
- [Preliminaries / Notation] Notation: ensure consistent use of the feature map φ and the budget parameter across all theorems; a small table collecting the key symbols and their meanings would aid readers.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our paper and the recommendation for minor revision. The referee's summary accurately captures the core contribution: the first tight necessity-and-sufficiency characterization of reward poisoning attackability in linear MDPs, along with the practical extension via linear approximation to deep RL environments. As no specific major comments were provided in the report, we have no points requiring rebuttal or revision at this time. We remain available to incorporate any minor changes the editor or referee may suggest.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper derives a necessity-and-sufficiency characterization of reward-poisoning attackability directly from the standard definition of linear MDPs (linear rewards and transitions over a known feature map). No fitted parameters, self-referential definitions, or load-bearing self-citations are invoked to force the separation between vulnerable and intrinsically robust instances; the conditions follow from the linear structure and attack budget constraints without reducing any claimed result to its own inputs by construction. The extension to deep RL is presented as an approximation-based application rather than a closed loop, and the abstract and claim description contain no equations or renamings that equate predictions to fitted quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The environment is a linear MDP
Reference graph
Works this paper leans on
-
[1]
cc/paper_files/paper/2021/file/ 678004486c119599ed7d199f47da043a-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ 678004486c119599ed7d199f47da043a-Paper. pdf. Ma, Y ., Wu, Y ., and Zhu, X. Game redesign in no- regret game playing.The 31st International Joint Con- ference on Artificial Intelligence and the 25th Euro- pean Conference on Artificial Intelligence, 2022. doi: 10.24963/ijcai.2022/461. URL http...
-
[2]
Rakhsha, A., Zhang, X., Zhu, X., and Singla, A
URL https://proceedings.mlr.press/ v206/nika23a.html. Rakhsha, A., Zhang, X., Zhu, X., and Singla, A. Reward poisoning in reinforcement learning: Attacks against unknown learners in unknown environments.CoRR, abs/2102.08492, 2021. URL https://arxiv.org/ abs/2102.08492. Rangi, A., Xu, H., Tran-Thanh, L., and Franceschetti, M. Understanding the limits of po...
-
[3]
International Joint Conferences on Artificial Intel- ligence Organization, 7 2022. doi: 10.24963/ijcai.2022/
-
[5]
Tang, Z., Chen, X., Li, Y ., and Chen, J
URL https://openreview.net/forum? id=9r30XCjf5Dt. Tang, Z., Chen, X., Li, Y ., and Chen, J. Efficient and generalized end-to-end autonomous driving system with latent deep reinforcement learning and demonstrations. arXiv preprint arXiv:2401.11792, 2024. URL https: //arxiv.org/abs/2401.11792. Wang, H., Xu, H., and Wang, H. When are linear stochas- tic band...
-
[6]
URL https://proceedings.mlr.press/ v162/wang22ai.html. Wang, J., Karatzoglou, A., Arapakis, I., and Jose, J. M. Easyrl4rec: An easy-to-use library for reinforcement learning-based recommender systems.Proceedings of the 31st ACM International Conference on Information and Knowledge Management, pp. 2345–2354, 2024a. doi: 10.1145/3626772.3657868. URL https:/...
-
[7]
cc/paper_files/paper/2021/file/ be315e7f05e9f13629031915fe87ad44-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ be315e7f05e9f13629031915fe87ad44-Paper. pdf. Xu, Y ., Zeng, Q., and Singh, G. Efficient reward poisoning attacks on online deep reinforcement learning.Transac- tions on Machine Learning Research, 2023. ISSN 2835-
2021
-
[8]
URL https://openreview.net/forum? id=25G63lDHV2. Featured Certification. Xu, Y ., Gumaste, R., and Singh, G. Universal black-box reward poisoning attack against offline reinforcement learning.arXiv preprint arXiv:2402.09695, 2024. URL https://arxiv.org/abs/2402.09695. Yen-Chen, L., Zhang-Wei, H., Yuan-Hong, L., Meng-Li, S., Ming-Yu, L., and Min, S. Tactic...
-
[9]
URL https://arxiv.org/abs/1908. 08796. Zhang, T., Ren, T., Yang, M., Gonzalez, J., Schuurmans, D., and Dai, B. Making linear MDPs practical via contrastive representation learning. In Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., and Sabato, S. (eds.), Proceedings of the 39th International Conference on Ma- chine Learning, volume 162 ofPr...
1908
-
[10]
Zhang, X., Ma, Y ., Singla, A., and Zhu, X
URL https://proceedings.mlr.press/ v162/zhang22x.html. Zhang, X., Ma, Y ., Singla, A., and Zhu, X. Adaptive reward- poisoning attacks against reinforcement learning.CoRR, abs/2003.12613, 2020. URL https://arxiv.org/ abs/2003.12613. Zheng, H., Li, X., Chen, J., Dong, J., Zhang, Y ., and Lin, C. One4all: Manipulate one agent to poison the cooperative multi-...
-
[11]
URL https://www.sciencedirect.com/ science/article/pii/S0167404822003972
doi: https://doi.org/10.1016/j.cose.2022.103005. URL https://www.sciencedirect.com/ science/article/pii/S0167404822003972. 12 A Tight Characterization of Reward Poisoning in Linear MDPs A. Notation S State space of the MDP. A Action space of the MDP. H Horizon (number of steps in each episode). ϕ Feature map for linear MDPs. Ph The step-htransition probab...
-
[12]
For all(s, a)withd π† h+1(s, a)>0, the estimated Q-value satisfies ˜Qh+1,Th(s, a)−Q ∗ h+1(s, a) = o(Th) Th
-
[13]
17 A Tight Characterization of Reward Poisoning in Linear MDPs
For allswithd π† h+1(s)>0, we have arg max a ˜Qh+1,Th(s, a)∈ {a ′ |(s, a ′)∈A h+1}. 17 A Tight Characterization of Reward Poisoning in Linear MDPs
-
[14]
For allswithd π† h (s)>0, we have arg max a Q∗ h(s, a)∈ {a ′ |(s, a ′)∈A h}
-
[15]
For all(s, a)withd π† h+1(s, a)>0,(s, a)is visited at leastΩ(T h)times
-
[16]
Stage 1 certifies by time T1 and yields a fixed attacked MDP on which the target policy is best on the certified support
For all(s, a)withd π† h (s, a)>0,(s, a)is visited at leastΩ(T h)times. We define(wh)∥ Ah to be the projection of wh onto the subspace spanned by {ϕ(s, a)|(s, a)∈A h}, and (wh)⊥ Ahx is the component ofw h perpendicular to{ϕ(s, a)|(s, a)∈A h}. Then with probability at least1−O(δ), the Q-value estimation error for stephsatisfies ϕ(s, a)⊤( ˆwh)∥ Ah −ϕ(s, a) ⊤...
2011
-
[17]
Summing overh∈[H]andt≤T 1 proves the claim
For each fixed(t, h), at most one target action is taken. Summing overh∈[H]andt≤T 1 proves the claim. Assume there exists an admissible predictable compensation schedule{c t h}t>T1 such that Ccorr(T1) := HX h=1 X t>T1 |ct h| ≤ HX h=1 |Dtar h |.(72) The actual Stage 2 reward is then ˆr(2) h,t(s, a) = ( rh(s, a) +c t h, a=π †(s), ¯rh(s, a), a∈ A cmp h (s). ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.