Recognition: unknown
Transformers Learn the Optimal DDPM Denoiser for Multi-Token GMMs
Pith reviewed 2026-05-10 16:19 UTC · model grok-4.3
The pith
Transformers converge to the Bayes optimal denoiser for multi-token Gaussian mixture data under the DDPM objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
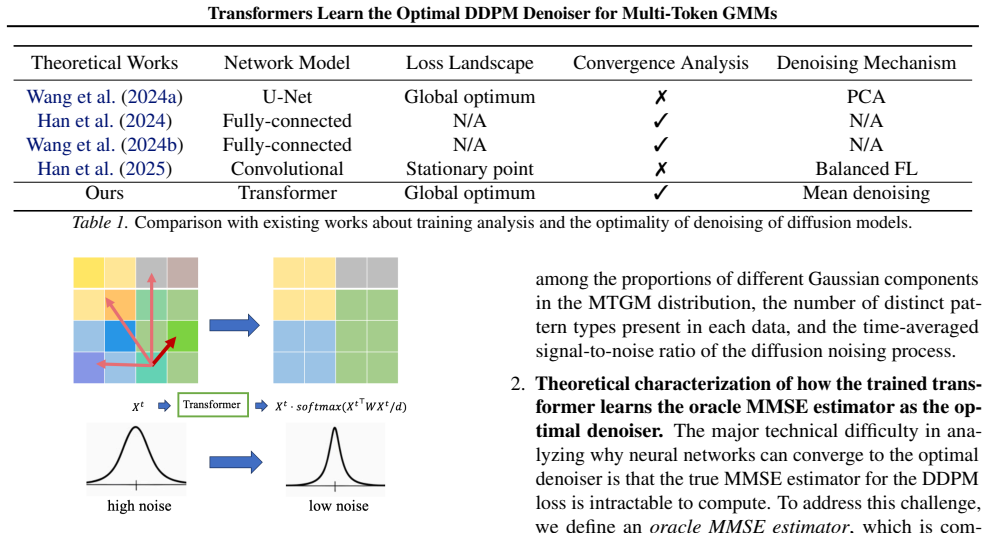
We provide the first convergence analysis showing that transformers trained on the DDPM objective for multi-token GMMs converge to the Bayes optimal denoiser, with the self-attention module implementing a mean denoising mechanism that approximates the oracle MMSE estimator of the injected noise.
What carries the argument
Self-attention module implementing a mean denoising mechanism to approximate the MMSE estimator of injected noise.
If this is right
- The model achieves the Bayes optimal risk of the denoising objective.
- A desired score matching error is attained.
- The transformer approximates the oracle MMSE estimator.
- The required number of tokens per data point and training iterations can be quantified for this convergence.
Where Pith is reading between the lines
- This convergence behavior may generalize to other data distributions that can be well-approximated by Gaussian mixtures.
- The mean denoising mechanism could inspire simpler architectures for diffusion models focused on averaging operations.
- In practice, this suggests that increasing the number of tokens in data representations could improve denoising performance in transformers.
- Extensions to finite data regimes might reveal sample complexity bounds for real-world applications.
Load-bearing premise
The analysis assumes that the data exactly follows a multi-token Gaussian mixture distribution and uses the population DDPM objective without considering finite data effects.
What would settle it
Train a transformer on multi-token GMM data with the specified number of tokens and iterations, then check whether the learned denoiser output deviates from the analytical MMSE noise estimator by more than the predicted error bound.
Figures




read the original abstract
Transformer-based diffusion models have demonstrated remarkable performance at generating high-quality samples. However, our theoretical understanding of the reasons for this success remains limited. For instance, existing models are typically trained by minimizing a denoising objective, which is equivalent to fitting the score function of the training data. However, we do not know why transformer-based models can match the score function for denoising, or why gradient-based methods converge to the optimal denoising model despite the non-convex loss landscape. To the best of our knowledge, this paper provides the first convergence analysis for training transformer-based diffusion models. More specifically, we consider the population Denoising Diffusion Probabilistic Model (DDPM) objective for denoising data that follow a multi-token Gaussian mixture distribution. We theoretically quantify the required number of tokens per data point and training iterations for the global convergence towards the Bayes optimal risk of the denoising objective, thereby achieving a desired score matching error. A deeper investigation reveals that the self-attention module of the trained transformer implements a mean denoising mechanism that enables the trained model to approximate the oracle Minimum Mean Squared Error (MMSE) estimator of the injected noise in the diffusion steps. Numerical experiments validate these findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript provides the first convergence analysis for training transformer models to minimize the population DDPM denoising objective when data are drawn from a multi-token Gaussian mixture model. It derives explicit bounds on the number of tokens per data point and gradient-descent iterations sufficient for global convergence to the Bayes-optimal risk (hence a controlled score-matching error), and shows that the learned self-attention layer realizes a mean-denoising operation that approximates the oracle MMSE estimator of the injected noise. Numerical experiments are cited in support of the theory.
Significance. If the stated theorems hold, the work supplies the first rigorous global-convergence guarantee for transformer-based diffusion models together with an interpretable structural explanation of how self-attention achieves the MMSE denoiser. The explicit token- and iteration-complexity bounds, the reduction of non-convexity via the GMM structure, and the attention-mechanism insight are all strengths that advance theoretical understanding of why transformers succeed on diffusion tasks.
minor comments (2)
- [Abstract] The abstract states that numerical experiments 'validate these findings' yet reports neither quantitative metrics (e.g., denoising MSE, score-matching error), controls, nor the precise GMM parameters used; this reduces the evidential weight of the experiments even though they are not load-bearing for the central theorems.
- [Theoretical Analysis] The dependence of the token and iteration bounds on the number of mixture components, component variances, and token dimension should be stated explicitly (ideally in the main theorem statement) so that readers can immediately assess scaling.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work and for recommending minor revision. We are pleased that the contributions regarding the first global convergence analysis for transformer-based DDPM training on multi-token GMMs, the explicit complexity bounds, and the self-attention mean-denoising interpretation were recognized as advancing theoretical understanding.
Circularity Check
No significant circularity; derivation self-contained under stated assumptions
full rationale
The paper's central results consist of a global convergence guarantee for gradient descent on the population DDPM denoising objective when data exactly follows a multi-token GMM, together with an explicit characterization that the learned self-attention realizes the MMSE mean-denoiser for that distribution. Both the iteration/token bounds and the attention interpretation are obtained by direct analysis of the GMM-structured loss landscape and the closed-form posterior mean; no parameter is fitted on a subset and then relabeled a prediction, no key uniqueness theorem is imported via self-citation, and no ansatz is smuggled in. The derivation therefore reduces only to the explicit distributional assumption and the population objective, both of which are stated up front and do not presuppose the target claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data is generated from a multi-token Gaussian mixture model
- domain assumption The DDPM objective is the population (infinite-sample) version
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
and Li, Y
Allen-Zhu, Z. and Li, Y. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning. In The Eleventh International Conference on Learning Representations, 2023
2023
-
[3]
S., Gokaslan, A., Yang, Z., Qi, Z., Han, J., Chiu, J
Arriola, M., Sahoo, S. S., Gokaslan, A., Yang, Z., Qi, Z., Han, J., Chiu, J. T., and Kuleshov, V. Block diffusion: Interpolating between autoregressive and diffusion language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=tyEyYT267x
2025
-
[4]
Azangulov, I., Deligiannidis, G., and Rousseau, J. Convergence of diffusion models under the manifold hypothesis in high-dimensions. arXiv preprint arXiv:2409.18804, 2024
-
[5]
Lumiere: A space-time diffusion model for video generation
Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al. Lumiere: A space-time diffusion model for video generation. In SIGGRAPH Asia 2024 Conference Papers, pp.\ 1--11, 2024
2024
-
[6]
M., Jacot, A., Tu, S., and Ziemann, I
Boffi, N. M., Jacot, A., Tu, S., and Ziemann, I. Shallow diffusion networks provably learn hidden low-dimensional structure. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[7]
arXiv preprint arXiv:2505.17638 , year=
Bonnaire, T., Urfin, R., Biroli, G., and M \'e zard, M. Why diffusion models don't memorize: The role of implicit dynamical regularization in training. arXiv preprint arXiv:2505.17638, 2025
-
[8]
Ditctrl: Exploring attention control in multi-modal diffusion transformer for tuning-free multi-prompt longer video generation
Cai, M., Cun, X., Li, X., Liu, W., Zhang, Z., Zhang, Y., Shan, Y., and Yue, X. Ditctrl: Exploring attention control in multi-modal diffusion transformer for tuning-free multi-prompt longer video generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 7763--7772, 2025
2025
-
[9]
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions
Chen, S., Chewi, S., Li, J., Li, Y., Salim, A., and Zhang, A. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. In The Eleventh International Conference on Learning Representations, 2023
2023
-
[10]
On the feature learning in diffusion models
Han, A., Huang, W., Cao, Y., and Zou, D. On the feature learning in diffusion models. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[11]
Neural network-based score estimation in diffusion models: Optimization and generalization
Han, Y., Razaviyayn, M., and Xu, R. Neural network-based score estimation in diffusion models: Optimization and generalization. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[12]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
2020
-
[13]
G., Vignac, C., and Welling, M
Hoogeboom, E., Satorras, V. G., Vignac, C., and Welling, M. Equivariant diffusion for molecule generation in 3d. In International conference on machine learning, pp.\ 8867--8887. PMLR, 2022
2022
-
[14]
In-context convergence of transformers
Huang, Y., Cheng, Y., and Liang, Y. In-context convergence of transformers. In NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning, 2023
2023
-
[15]
Transformers provably learn feature-position correlations in masked image modeling
Huang, Y., Wen, Z., Chi, Y., and Liang, Y. Transformers provably learn feature-position correlations in masked image modeling. arXiv preprint arXiv:2403.02233, 2024 a
-
[16]
Huang, Z., Wei, Y., and Chen, Y. Denoising diffusion probabilistic models are optimally adaptive to unknown low dimensionality. arXiv preprint arXiv:2410.18784, 2024 b
-
[17]
Neural tangent kernel: Convergence and generalization in neural networks
Jacot, A., Gabriel, F., and Hongler, C. Neural tangent kernel: Convergence and generalization in neural networks. Advances in neural information processing systems, 31, 2018
2018
-
[18]
Vision transformers provably learn spatial structure
Jelassi, S., Sander, M., and Li, Y. Vision transformers provably learn spatial structure. Advances in Neural Information Processing Systems, 35: 0 37822--37836, 2022
2022
-
[19]
Unveil benign overfitting for transformer in vision: Training dynamics, convergence, and generalization
Jiang, J., Huang, W., Zhang, M., Suzuki, T., and Nie, L. Unveil benign overfitting for transformer in vision: Training dynamics, convergence, and generalization. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=FGJb0peY4R
2024
-
[20]
Diffwave: A versatile diffusion model for audio synthesis
Kong, Z., Ping, W., Huang, J., Zhao, K., and Catanzaro, B. Diffwave: A versatile diffusion model for audio synthesis. In International Conference on Learning Representations, 2021
2021
-
[21]
Gradient-based learning applied to document recognition
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86 0 (11): 0 2278--2324, 2002
2002
-
[22]
and Yan, Y
Li, G. and Yan, Y. Adapting to unknown low-dimensional structures in score-based diffusion models. Advances in Neural Information Processing Systems, 37: 0 126297--126331, 2024
2024
-
[23]
A theoretical understanding of shallow vision transformers: Learning, generalization, and sample complexity
Li, H., Wang, M., Liu, S., and Chen, P.-Y. A theoretical understanding of shallow vision transformers: Learning, generalization, and sample complexity. In The Eleventh International Conference on Learning Representations, 2023 a . URL https://openreview.net/forum?id=jClGv3Qjhb
2023
-
[24]
Transformers as multi-task feature selectors: Generalization analysis of in-context learning
Li, H., Wang, M., Lu, S., Wan, H., Cui, X., and Chen, P.-Y. Transformers as multi-task feature selectors: Generalization analysis of in-context learning. In NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning, 2023 b . URL https://openreview.net/forum?id=BMQ4i2RVbE
2023
-
[25]
How do nonlinear transformers learn and generalize in in-context learning? In Forty-first International Conference on Machine Learning, 2024 a
Li, H., Wang, M., Lu, S., Cui, X., and Chen, P.-Y. How do nonlinear transformers learn and generalize in in-context learning? In Forty-first International Conference on Machine Learning, 2024 a . URL https://openreview.net/forum?id=I4HTPws9P6
2024
-
[26]
How do nonlinear transformers acquire generalization-guaranteed cot ability? In High-dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning, 2024 b
Li, H., Wang, M., Lu, S., Cui, X., and Chen, P.-Y. How do nonlinear transformers acquire generalization-guaranteed cot ability? In High-dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning, 2024 b
2024
-
[27]
What improves the generalization of graph transformers? a theoretical dive into the self-attention and positional encoding
Li, H., Wang, M., Ma, T., Liu, S., ZHANG, Z., and Chen, P.-Y. What improves the generalization of graph transformers? a theoretical dive into the self-attention and positional encoding. In Forty-first International Conference on Machine Learning, 2024 c . URL https://openreview.net/forum?id=mJhXlsZzzE
2024
-
[28]
Learning on transformers is provable low-rank and sparse: A one-layer analysis
Li, H., Wang, M., Zhang, S., Liu, S., and Chen, P.-Y. Learning on transformers is provable low-rank and sparse: A one-layer analysis. In 2024 IEEE 13rd Sensor Array and Multichannel Signal Processing Workshop (SAM), pp.\ 1--5. IEEE, 2024 d
2024
-
[29]
Training nonlinear transformers for chain-of-thought inference: A theoretical generalization analysis
Li, H., Lu, S., Chen, P.-Y., Cui, X., and Wang, M. Training nonlinear transformers for chain-of-thought inference: A theoretical generalization analysis. In The Thirteenth International Conference on Learning Representations, 2025 a
2025
-
[30]
Can mamba learn in context with outliers? a theoretical generalization analysis
Li, H., Lu, S., Cui, X., Chen, P.-Y., and Wang, M. Can mamba learn in context with outliers? a theoretical generalization analysis. arXiv preprint arXiv:2510.00399, 2025 b
-
[31]
When is task vector provably effective for model editing? a generalization analysis of nonlinear transformers
Li, H., Zhang, Y., Zhang, S., Chen, P.-Y., Liu, S., and Wang, M. When is task vector provably effective for model editing? a generalization analysis of nonlinear transformers. In The Thirteenth International Conference on Learning Representations, 2025 c
2025
-
[32]
On the generalization properties of diffusion models
Li, P., Li, Z., Zhang, H., and Bian, J. On the generalization properties of diffusion models. Advances in Neural Information Processing Systems, 36: 0 2097--2127, 2023 c
2097
-
[33]
A., and Buzzicotti, M
Li, T., Biferale, L., Bonaccorso, F., Scarpolini, M. A., and Buzzicotti, M. Synthetic lagrangian turbulence by generative diffusion models. Nature Machine Intelligence, 6 0 (4): 0 393--403, 2024 e
2024
-
[34]
Understanding generalizability of diffusion models requires rethinking the hidden gaussian structure
Li, X., Dai, Y., and Qu, Q. Understanding generalizability of diffusion models requires rethinking the hidden gaussian structure. Advances in neural information processing systems, 37: 0 57499--57538, 2024 f
2024
-
[35]
Li, X., Zhang, Z., Li, X., Chen, S., Zhu, Z., Wang, P., and Qu, Q. Understanding representation dynamics of diffusion models via low-dimensional modeling. arXiv preprint arXiv:2502.05743, 2025 d
-
[36]
arXiv preprint arXiv:2501.12982 , year=
Liang, J., Huang, Z., and Chen, Y. Low-dimensional adaptation of diffusion models: Convergence in total variation. arXiv preprint arXiv:2501.12982, 2025
-
[37]
Luo, C. Understanding diffusion models: A unified perspective. arXiv preprint arXiv:2208.11970, 2022
-
[38]
Enhancing graph transformers with hierarchical distance structural encoding
Luo, Y., Li, H., Shi, L., and Wu, X.-M. Enhancing graph transformers with hierarchical distance structural encoding. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=U4KldRgoph
2024
-
[39]
and Vidal, R
Min, H. and Vidal, R. Gradient flow provably learns robust classifiers for orthonormal gmms. In Forty-second International Conference on Machine Learning, 2025
2025
-
[40]
Foundations of machine learning
Mohri, M., Rostamizadeh, A., and Talwalkar, A. Foundations of machine learning. MIT press, 2018
2018
-
[41]
and Xie, S
Peebles, W. and Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 4195--4205, 2023
2023
-
[42]
Pham, B., Raya, G., Negri, M., Zaki, M. J., Ambrogioni, L., and Krotov, D. Memorization to generalization: Emergence of diffusion models from associative memory. arXiv preprint arXiv:2505.21777, 2025
-
[43]
R., El-Kadi, A., Masters, D., Ewalds, T., Stott, J., Mohamed, S., Battaglia, P., et al
Price, I., Sanchez-Gonzalez, A., Alet, F., Andersson, T. R., El-Kadi, A., Masters, D., Ewalds, T., Stott, J., Mohamed, S., Battaglia, P., et al. Probabilistic weather forecasting with machine learning. Nature, 637 0 (8044): 0 84--90, 2025
2025
-
[44]
and Recht, B
Rahimi, A. and Recht, B. Random features for large-scale kernel machines. In Advances in Neural Information Processing Systems, volume 20, 2007
2007
-
[45]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022
2022
-
[46]
J., Jin, Q., and Guo, B
Ruan, L., Ma, Y., Yang, H., He, H., Liu, B., Fu, J., Yuan, N. J., Jin, Q., and Guo, B. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 10219--10228, 2023
2023
-
[47]
Simple and effective masked diffusion language models
Sahoo, S., Arriola, M., Schiff, Y., Gokaslan, A., Marroquin, E., Chiu, J., Rush, A., and Kuleshov, V. Simple and effective masked diffusion language models. Advances in Neural Information Processing Systems, 37: 0 130136--130184, 2024
2024
-
[48]
A phase transition in diffusion models reveals the hierarchical nature of data
Sclocchi, A., Favero, A., and Wyart, M. A phase transition in diffusion models reveals the hierarchical nature of data. Proceedings of the National Academy of Sciences, 122 0 (1): 0 e2408799121, 2025
2025
-
[49]
A theoretical analysis of mamba’s training dynamics: Filtering relevant features for generalization in state space models
Shandirasegaran, M., Li, H., Zhang, S., Wang, M., and Zhang, S. A theoretical analysis of mamba’s training dynamics: Filtering relevant features for generalization in state space models. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[50]
On the training convergence of transformers for in-context classification of gaussian mixtures
Shen, W., Zhou, R., Yang, J., and Shen, C. On the training convergence of transformers for in-context classification of gaussian mixtures. In Forty-second International Conference on Machine Learning, 2025
2025
-
[51]
Deep unsupervised learning using nonequilibrium thermodynamics
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pp.\ 2256--2265. pmlr, 2015
2015
-
[52]
and Ermon, S
Song, Y. and Ermon, S. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019
2019
-
[53]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021
2021
-
[54]
Contrastive learning with data misalignment: Feature purity, training dynamics and theoretical generalization guarantees
Sun, J., Zhang, S., Li, H., and Wang, M. Contrastive learning with data misalignment: Feature purity, training dynamics and theoretical generalization guarantees. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[55]
A., Li, Y., Thrampoulidis, C., and Oymak, S
Tarzanagh, D. A., Li, Y., Thrampoulidis, C., and Oymak, S. Transformers as support vector machines. arXiv preprint arXiv:2308.16898, 2023 a
-
[56]
A., Li, Y., Zhang, X., and Oymak, S
Tarzanagh, D. A., Li, Y., Zhang, X., and Oymak, S. Max-margin token selection in attention mechanism. CoRR, 2023 b
2023
-
[57]
Introduction to the non-asymptotic analysis of random matrices
Vershynin, R. Introduction to the non-asymptotic analysis of random matrices. arXiv preprint arXiv:1011.3027, 2010
work page Pith review arXiv 2010
-
[58]
and Pehlevan, C
Wang, B. and Pehlevan, C. An analytical theory of spectral bias in the learning dynamics of diffusion models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[59]
Diffusion Models Learn Low-Dimensional Distributions via Subspace Clustering
Wang, P., Zhang, H., Zhang, Z., Chen, S., Ma, Y., and Qu, Q. Diffusion models learn low-dimensional distributions via subspace clustering. arXiv preprint arXiv:2409.02426, 2024 a
-
[60]
Evaluating the design space of diffusion-based generative models
Wang, Y., He, Y., and Tao, M. Evaluating the design space of diffusion-based generative models. Advances in Neural Information Processing Systems, 37: 0 19307--19352, 2024 b
2024
-
[61]
A survey on video diffusion models
Xing, Z., Feng, Q., Chen, H., Dai, Q., Hu, H., Xu, H., Wu, Z., and Jiang, Y.-G. A survey on video diffusion models. ACM Computing Surveys, 57 0 (2): 0 1--42, 2024
2024
-
[62]
Merging smarter, generalizing better: Enhancing model merging on ood data
Zhang, B., Li, H., Shi, C., Rong, G., Zhao, H., Wang, D., Guo, D., and Wang, M. Merging smarter, generalizing better: Enhancing model merging on ood data. arXiv preprint arXiv:2506.09093, 2025 a
- [63]
- [64]
-
[65]
Visual prompting reimagined: The power of activation prompts
Zhang, Y., Li, H., Yao, Y., Chen, A., Zhang, S., Chen, P.-Y., Wang, M., and Liu, S. Visual prompting reimagined: The power of activation prompts. In The Second Conference on Parsimony and Learning (Recent Spotlight Track), 2025 b
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.