Recognition: unknown
Wearable AI in the Era of Large Sensor Models
Pith reviewed 2026-05-10 16:32 UTC · model grok-4.3
The pith
Large Sensor Models trained on large-scale multimodal wearable data can unify fragmented sensor systems into a general, scalable framework for wearable AI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
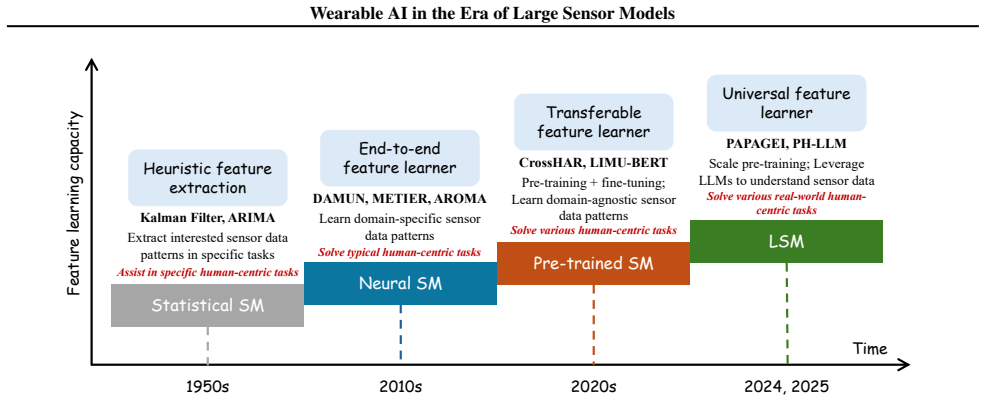
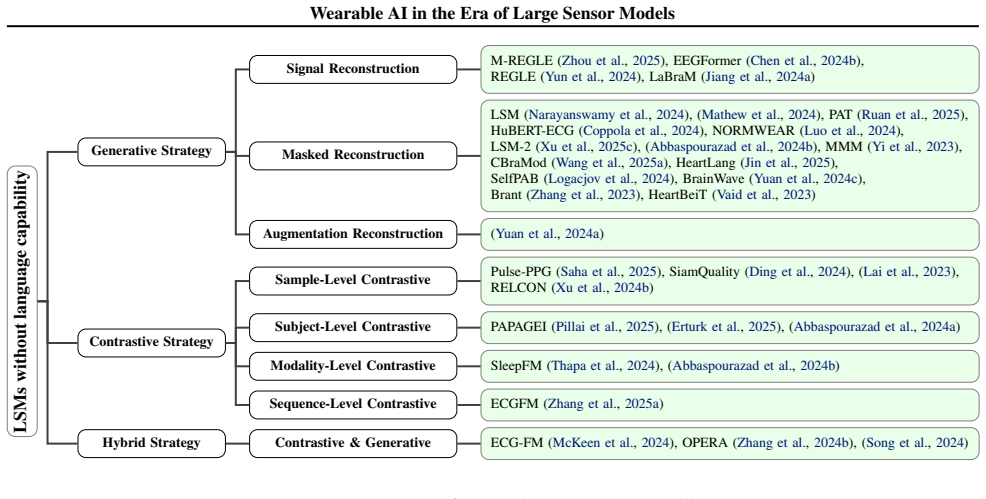
Large Sensor Models (LSMs) are defined as foundation models trained on large-scale and multimodal wearable data. They provide a pathway to a more general and scalable framework for wearable AI by integrating diverse modalities, supporting varied training strategies, and achieving robust generalization. The paper formalizes the data substrate, examines unique challenges of large-scale wearable sensing, and outlines two directions: LSMs without language capability and LSMs with language capability, plus representative applications that become feasible.
What carries the argument
Large Sensor Models (LSMs), defined as foundation models trained on large-scale multimodal wearable sensor data, which learn transferable representations to move beyond modality- and task-specific silos.
Load-bearing premise
The scaling laws and data patterns that produced effective foundation models in language and vision will also work for wearable sensor streams despite their privacy restrictions, high variability across users and environments, and shortage of labeled examples.
What would settle it
An experiment that trains a large multimodal wearable model on available datasets and finds it fails to match or exceed the accuracy and generalization of current single-modality models on held-out real-world tasks such as continuous health monitoring or activity detection.
Figures




read the original abstract
As an effective approach to understanding the human-centric physical world, Wearable Artificial Intelligence (AI), which leverages multimodal wearable sensors to understand human physiology and behavior, has attracted increasing attention in recent years. However, existing sensor models remain largely siloed by modality and task, lacking a unified paradigm for integrating diverse wearable modalities, training strategies, and achieving robust generalization in real-world applications. Motivated by the success of multimodal foundation models, which learn transferable representations from massive multimodal data, we argue that Large Sensor Models (LSMs), defined as foundation models trained on large-scale and multimodal wearable data, offer a promising pathway toward a more general and scalable framework for wearable AI. In this position paper, we formalize the data substrate underlying LSMs, analyze the unique challenges of large-scale wearable sensing, and articulate two directions: (i) LSMs without language capability and (ii) LSMs with language capability. We further discuss representative application areas that can be unlocked by such models. Through this paper, we encourage the community to explore LSMs as a foundational approach for the next generation of human-centric AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that Large Sensor Models (LSMs), defined as foundation models trained on large-scale multimodal wearable sensor data, offer a promising unified and scalable framework for wearable AI. Motivated by successes in multimodal foundation models from language and vision domains, the manuscript formalizes the data substrate for LSMs, analyzes challenges specific to wearable sensing (privacy, high variability, label scarcity), articulates two exploratory directions (LSMs without language capability and LSMs with language capability), and discusses representative application areas in human-centric AI systems.
Significance. If the proposed LSMs can be developed and shown to achieve robust generalization across modalities and tasks, the work could catalyze a paradigm shift in wearable AI by moving beyond siloed models toward more general representations, with potential impact on health monitoring, behavior analysis, and real-world deployment. The paper's strength is in clearly framing the vision, data substrate, and open directions to encourage community exploration, though its significance remains prospective pending empirical validation of transfer from other domains.
major comments (1)
- Section analyzing the unique challenges of large-scale wearable sensing: the discussion enumerates privacy, variability, and label scarcity but does not provide even high-level technical pathways (e.g., self-supervised pretraining objectives or privacy-preserving aggregation methods) for overcoming them at scale; this omission weakens the central claim that LSMs constitute a 'promising pathway' because the feasibility argument rests on unaddressed constraints.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the paper's role in framing a vision for wearable AI. We agree that the challenges section would benefit from additional high-level technical pathways to better support the feasibility of LSMs, and we will revise accordingly while preserving the position paper's exploratory focus.
read point-by-point responses
-
Referee: Section analyzing the unique challenges of large-scale wearable sensing: the discussion enumerates privacy, variability, and label scarcity but does not provide even high-level technical pathways (e.g., self-supervised pretraining objectives or privacy-preserving aggregation methods) for overcoming them at scale; this omission weakens the central claim that LSMs constitute a 'promising pathway' because the feasibility argument rests on unaddressed constraints.
Authors: We agree with the referee that the current enumeration of challenges (privacy, variability, and label scarcity) would be strengthened by including high-level technical pathways, as this would more concretely illustrate how LSMs could address these issues at scale. As a position paper, the manuscript prioritizes identifying open problems to motivate community efforts rather than providing exhaustive solutions; however, we acknowledge that this leaves the 'promising pathway' claim somewhat underspecified. In the revision, we will expand the challenges section with brief, high-level examples drawn from related domains, such as self-supervised pretraining via contrastive or masked modeling on multimodal time-series data to mitigate label scarcity, and privacy-preserving methods like federated learning with secure aggregation or differential privacy for cross-device training. These additions will clarify potential directions without shifting the paper toward a technical survey. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a position piece that defines LSMs by explicit analogy to external multimodal foundation models in language and vision, lists known wearable constraints (privacy, variability, label scarcity), and proposes exploratory directions without any equations, derivations, fitted parameters, or empirical claims. No load-bearing step reduces to its own inputs by construction, self-citation, or renaming; the central advocacy holds as a hypothesis independent of whether scaling laws ultimately transfer.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Success of multimodal foundation models in language and vision domains will transfer to wearable sensor data despite domain-specific constraints.
invented entities (1)
-
Large Sensor Models (LSMs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abbasian, M., Azimi, I., Rahmani, A. M., and Jain, R. Con- versational health agents: A personalized llm-powered agent framework.arXiv preprint arXiv:2310.02374,
-
[2]
Abbaspourazad, S., Elachqar, O., Miller, A., Emrani, S., Nal- lasamy, U., and Shapiro, I. Large-scale training of foun- dation models for wearable biosignals. InThe Twelfth International Conference on Learning Representations, 2024a. Abbaspourazad, S., Mishra, A., Futoma, J., Miller, A. C., and Shapiro, I. Wearable accelerometer foundation mod- els for he...
-
[3]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Chronos: Learning the Language of Time Series
Ansari, A. F., Stella, L., Turkmen, C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P., Kapoor, S., et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815,
work page internal anchor Pith review arXiv
-
[5]
Asif Imran Shouborno, S., Khan, M. N. H., Biswas, S., and Islam, B. Llasa: A sensor-aware llm for natural language reasoning of human activity from imu data. InCom- panion of the 2025 ACM International Joint Conference on Pervasive and Ubiquitous Computing, pp. 893–899,
2025
-
[6]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosse- lut, A., Brunskill, E., et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Towards generalizable human activity recognition: A survey.arXiv preprint arXiv:2508.12213, 2025
Cai, Y ., Guo, B., Salim, F., and Hong, Z. Towards generaliz- able human activity recognition: A survey.arXiv preprint arXiv:2508.12213,
-
[8]
Chen, W., Cheng, J., Wang, L., Zhao, W., and Matusik, W. Sensor2text: Enabling natural language interactions for daily activity tracking using wearable sensors.Proceed- ings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(4):1–26, 2024a. Chen, Y ., Ren, K., Song, K., Wang, Y ., Wang, Y ., Li, D., and Qiu, L. EEGFormer: Towards t...
2024
-
[9]
S., and Choi, E
Chung, H., Kim, J., Kwon, J.-M., Jeon, K.-H., Lee, M. S., and Choi, E. Text-to-ecg: 12-lead electrocardiogram synthesis conditioned on clinical text reports. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2023
-
[10]
Hubert-ecg as a self-supervised foundation model for broad and scalable cardiac applica- tions.medRxiv, pp
Coppola, E., Savardi, M., Massussi, M., Adamo, M., Metra, M., and Signoroni, A. Hubert-ecg as a self-supervised foundation model for broad and scalable cardiac applica- tions.medRxiv, pp. 2024–11,
2024
-
[11]
Y ., and Narain, J
Demirel, I., Thakkar, K., Elizalde, B., Ren, S. Y ., and Narain, J. Using LLMs for late multimodal sensor fusion for activ- ity recognition. InNeurIPS 2025 Workshop on Learning from Time Series for Health,
2025
-
[12]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[13]
Ding, C., Guo, Z., Chen, Z., Lee, R. J., Rudin, C., and Hu, X. Siamquality: A convnet-based foundation model for imperfect physiological signals.arXiv preprint arXiv:2404.17667,
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
- [15]
-
[16]
Timegpt-1.arXiv preprint arXiv:2310.03589, 2023
Garza, A., Challu, C., and Mergenthaler-Canseco, M. Timegpt-1.arXiv preprint arXiv:2310.03589,
-
[17]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Jiang, W., Zhao, L., and liang Lu, B. Large brain model for learning generic representations with tremendous EEG data in BCI. InThe Twelfth International Conference on Learning Representations, 2024a. Jiang, W.-B., Wang, Y ., Lu, B.-L., and Li, D. Neurolm: A universal multi-task foundation model for bridging the gap between language and eeg signals.arXiv ...
-
[19]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
- [20]
-
[21]
LeCun, Y . et al. A path towards autonomous machine intel- ligence version 0.9. 2, 2022-06-27.Open Review, 62(1): 1–62,
2022
-
[22]
Li, Z., Chen, B., Xue, H., and Salim, F. D. Zara: Zero-shot motion time-series analysis via knowledge and retrieval driven llm agents.arXiv preprint arXiv:2508.04038, 2025d. Lim, D., Jeong, J., Song, Y . M., Cho, C.-H., Yeom, J. W., Lee, T., Lee, J.-B., Lee, H.-J., and Kim, J. K. Accurately predicting mood episodes in mood disorder patients using wearable...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Lin, Z., Basu, S., Beigi, M., Manjunatha, V ., Rossi, R. A., Wang, Z., Zhou, Y ., Balasubramanian, S., Zarei, A., Rezaei, K., et al. A survey on mechanistic interpretabil- ity for multi-modal foundation models.arXiv preprint arXiv:2502.17516,
-
[24]
14 Wearable AI in the Era of Large Sensor Models Luo, Y ., Chen, Y ., Salekin, A., and Rahman, T. Toward foundation model for multivariate wearable sensing of physiological signals.arXiv preprint arXiv:2412.09758,
-
[25]
Ecg-fm: An open electrocardiogram foundation model,
McKeen, K., Masood, S., Toma, A., Rubin, B., and Wang, B. Ecg-fm: An open electrocardiogram foundation model. arXiv preprint arXiv:2408.05178,
-
[26]
Narayanswamy, G., Liu, X., Ayush, K., Yang, Y ., Xu, X., Liao, S., Garrison, J., Tailor, S., Sunshine, J., Liu, Y ., et al. Scaling wearable foundation models.arXiv preprint arXiv:2410.13638,
-
[27]
Uwb/imu-assisted gesture recognition using learning approaches for vr/xr applications
Oh, H., Bhattacharya, S., and Seo, S. Uwb/imu-assisted gesture recognition using learning approaches for vr/xr applications. InICC 2024-IEEE International Conference on Communications, pp. 4838–4844. IEEE,
2024
-
[28]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El- Nouby, A., et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Qiu, J., Han, W., Zhu, J., Xu, M., Rosenberg, M., Liu, E., Weber, D., and Zhao, D. Transfer knowledge from natural language to electrocardiography: Can we detect cardio- vascular disease through language models? InFindings of the Association for Computational Linguistics: EACL 2023, pp. 442–453, 2023a. Qiu, J., Han, W., Zhu, J., Xu, M., Weber, D., Li, B.,...
2023
-
[31]
M., Aguilar- Aguilar, E., Fern´andez-Cabezas, J., Cruz-Gil, S., Molina, S., et al
Romero-Tapiador, S., Lacruz-Pleguezuelos, B., Tolosana, R., Freixer, G., Daza, R., Fern´andez-D´ıaz, C. M., Aguilar- Aguilar, E., Fern´andez-Cabezas, J., Cruz-Gil, S., Molina, S., et al. Ai4fooddb: a database for personalized e-health nutrition and lifestyle through wearable devices and arti- ficial intelligence.Database, 2023:baad049,
2023
-
[32]
A., Mao, W., Neupane, S., Rehg, J
Saha, M., Xu, M. A., Mao, W., Neupane, S., Rehg, J. M., and Kumar, S. Pulse-ppg: An open-source field-trained ppg foundation model for wearable applications across lab and field settings.arXiv preprint arXiv:2502.01108,
-
[33]
Singh, C., Inala, J. P., Galley, M., Caruana, R., and Gao, J. Rethinking interpretability in the era of large language models.arXiv preprint arXiv:2402.01761,
-
[34]
S., Faisal, M
Siraj, M. S., Faisal, M. A. A., Shahid, O., Abir, F. F., Hos- sain, T., Inoue, S., and Ahad, M. A. R. Upic: user and position independent classical approach for locomotion and transportation modes recognition. InAdjunct Pro- ceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM Intern...
2020
- [35]
-
[36]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Meit: Multimodal electrocardiogram instruction tuning on large language models for report generation
Wan, Z., Liu, C., Wang, X., Tao, C., Shen, H., Xiong, J., Arcucci, R., Yao, H., and Zhang, M. Meit: Multimodal electrocardiogram instruction tuning on large language models for report generation. InFindings of the associa- tion for computational linguistics: ACL 2025, pp. 14510– 14527,
2025
-
[38]
Ubiphysio: Support daily functioning, fitness, and rehabilitation with action understanding and feedback in natural language
16 Wearable AI in the Era of Large Sensor Models Wang, C., Feng, Y ., Zhong, L., Zhu, S., Zhang, C., Zheng, S., Liang, C., Wang, Y ., He, C., Yu, C., et al. Ubiphysio: Support daily functioning, fitness, and rehabilitation with action understanding and feedback in natural language. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Tec...
2025
-
[39]
Pene- trative ai: Making llms comprehend the physical world
Xu, H., Han, L., Yang, Q., Li, M., and Srivastava, M. Pene- trative ai: Making llms comprehend the physical world. InProceedings of the 25th International Workshop on Mobile Computing Systems and Applications, pp. 1–7, 2024a. Xu, H., Zhang, Y ., Gao, W., Shen, G., and Li, M. Experi- ence paper: Adopting activity recognition in on-demand food delivery busi...
-
[40]
BrainWave : A brain signal foundation model for clinical applications, 2024
Yuan, H., Chan, S., Creagh, A. P., Tong, C., Acquah, A., Clifton, D. A., and Doherty, A. Self-supervised learning for human activity recognition using 700,000 person-days of wearable data.NPJ digital medicine, 7(1):91, 2024a. Yuan, J., Yang, C., Cai, D., Wang, S., Yuan, X., Zhang, Z., Li, X., Zhang, D., Mei, H., Jia, X., et al. Mobile foundation model as ...
-
[41]
Ali Heydari, Girish Narayanswamy, Maxwell A
Zhang, D., Yu, Y ., Dong, J., Li, C., Su, D., Chu, C., and Yu, D. Mm-llms: Recent advances in multimodal large language models.Findings of the Association for Compu- tational Linguistics: ACL 2024, pp. 12401–12430, 2024a. Zhang, S., Du, Y ., Wang, W., He, X., Cui, F., Zhao, L., Wang, B., Hu, Z., Wang, Z., Xia, Q., et al. Ecgfm: A foundation model for ecg ...
-
[42]
Zhou, J., Duan, Y ., Chang, F., Do, T., Wang, Y .-K., and Lin, C.-T. Belt-2: Bootstrapping eeg-to-language repre- sentation alignment for multi-task brain decoding.arXiv preprint arXiv:2409.00121,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.