Recognition: unknown
The Phase Is the Gradient: Equilibrium Propagation for Frequency Learning in Kuramoto Networks
Pith reviewed 2026-05-10 15:48 UTC · model grok-4.3
The pith
In stable Kuramoto networks, phase displacement from weak output nudging equals the loss gradient with respect to natural frequencies in the zero-nudge limit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
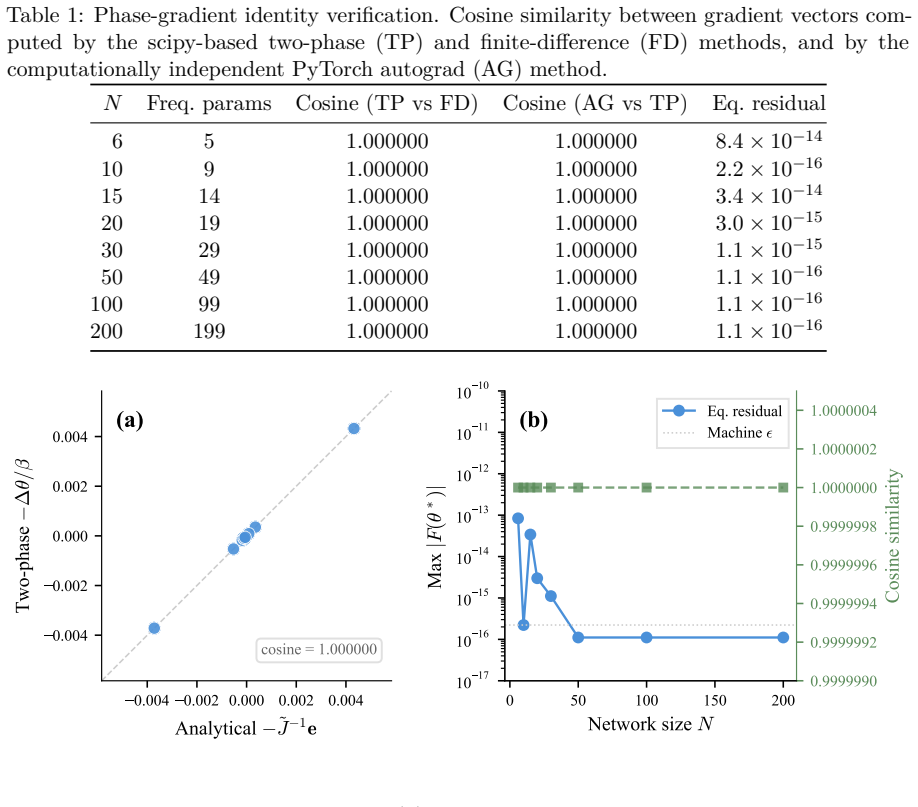
We prove that in a coupled Kuramoto oscillator network at stable equilibrium, the physical phase displacement under weak output nudging is the gradient of the loss with respect to natural frequencies, with equality as the nudging strength beta tends to zero.
What carries the argument
Phase displacement under weak nudging, which computes the gradient for updating natural frequencies without requiring explicit differentiation through the dynamics.
If this is right
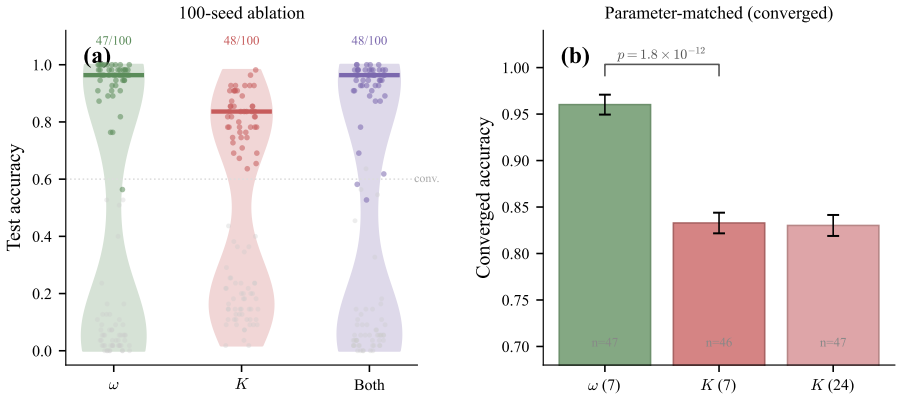
- Frequency learning achieves 96.0% accuracy compared to 83.3% for coupling-weight learning at matched parameter counts on sparse layered topologies.
- Convergence failure rates of about 50% under random initialization stem from the loss landscape and are eliminated by topology-aware spectral seeding, reaching 100% convergence.
- Natural frequency updates remain viable when coupling weights are fixed.
- The method applies to both the primary classification task and additional settings including larger architectures.
Where Pith is reading between the lines
- The phase-gradient identity could enable direct hardware implementations where phase measurements replace computed gradients in oscillator-based processors.
- If the identity holds approximately at finite nudge strengths, training could use larger beta values to accelerate convergence without sacrificing accuracy.
- Similar gradient extraction might be possible in other phase-based dynamical systems beyond Kuramoto oscillators.
Load-bearing premise
The network reaches a stable equilibrium under the chosen dynamics, and the gradient equality holds strictly only as the nudging strength beta approaches zero.
What would settle it
Measure the phase displacements for decreasing values of beta and compare them to independently computed gradients of the loss with respect to natural frequencies; persistent mismatch as beta shrinks would disprove the equality.
Figures



read the original abstract
We prove that in a coupled Kuramoto oscillator network at stable equilibrium, the physical phase displacement under weak output nudging is the gradient of the loss with respect to natural frequencies, with equality as the nudging strength beta tends to zero. Prior oscillator equilibrium propagation work explicitly set aside natural frequency as a learnable parameter; we show that on sparse layered architectures, frequency learning outperforms coupling-weight learning among converged seeds (96.0% vs. 83.3% at matched parameter counts, p = 1.8e-12). The approximately 50% convergence failure rate under random initialization is a loss-landscape property, not a gradient error; topology-aware spectral seeding eliminates it in all settings tested (46/100 to 100/100 seeds on the primary task; 50/50 on a second task, K-only training, and a larger architecture).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proves that in a coupled Kuramoto oscillator network at stable equilibrium, the physical phase displacement under weak output nudging equals the gradient of the loss with respect to natural frequencies, with equality in the limit as nudging strength β tends to zero. It reports that frequency learning outperforms coupling-weight learning on sparse layered architectures (96.0% vs. 83.3% accuracy at matched parameter counts, p=1.8e-12) and that topology-aware spectral seeding eliminates the ~50% random-initialization convergence failures observed across tasks and architectures.
Significance. If the central equality holds and is practically usable, the work extends equilibrium propagation to natural-frequency parameters in oscillator networks, providing a physically grounded, parameter-free gradient mechanism. The reported performance edge for frequency learning and the seeding fix for convergence could be relevant for hardware oscillator implementations, provided the β→0 approximation is validated and equilibria remain stable under nudging.
major comments (3)
- [Proof and §4 (experiments)] The main theorem states equality only as β→0 at a stable fixed point, yet the experiments use finite β without any numerical verification that Δθ/β approximates the true gradient (e.g., via implicit differentiation of the equilibrium equations or autodiff on the same loss).
- [§3 (dynamics) and §5 (initialization)] The ~50% random-init failure rate is attributed to the loss landscape, but no analysis is given of how the nudging term modifies the Jacobian eigenvalues or basin size; this directly affects whether the stable-equilibrium assumption required for the gradient equality holds during training.
- [Results tables and §4.3] Table reporting 96.0% vs. 83.3% accuracy gives p=1.8e-12 but omits error bars, exact number of independent seeds per condition, data-exclusion rules, and whether the statistical test accounts for the spectral-seeding vs. random-init split.
minor comments (2)
- [§2] Notation for the nudging term and loss function should be cross-referenced to prior equilibrium-propagation literature to clarify differences.
- [Abstract and §5] The abstract and main text use 'approximately 50%' for convergence failures; replace with exact fractions (e.g., 46/100) for precision.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on the manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the work.
read point-by-point responses
-
Referee: [Proof and §4 (experiments)] The main theorem states equality only as β→0 at a stable fixed point, yet the experiments use finite β without any numerical verification that Δθ/β approximates the true gradient (e.g., via implicit differentiation of the equilibrium equations or autodiff on the same loss).
Authors: We agree that the central theorem establishes the exact gradient equality only in the limit as β → 0 at a stable fixed point. The experiments employ finite β for practical training, and we did not include explicit numerical checks comparing Δθ/β to the true gradient. We will add such verification to §4 by computing the true gradient via implicit differentiation of the equilibrium equations (or autodiff on the loss) and reporting the approximation error for the specific β values used across tasks and architectures. revision: yes
-
Referee: [§3 (dynamics) and §5 (initialization)] The ~50% random-init failure rate is attributed to the loss landscape, but no analysis is given of how the nudging term modifies the Jacobian eigenvalues or basin size; this directly affects whether the stable-equilibrium assumption required for the gradient equality holds during training.
Authors: The referee correctly identifies that we provide no explicit analysis of the nudging term's influence on Jacobian eigenvalues or basin size. While the manuscript attributes the ~50% random-initialization failures to the loss landscape (supported by the fact that failures occur even in control settings without nudging), we acknowledge that a direct examination of how β perturbs the eigenvalues would better justify the stable-equilibrium assumption throughout training. We will add a concise discussion and numerical eigenvalue examples in §3 and §5 to address this. revision: partial
-
Referee: [Results tables and §4.3] Table reporting 96.0% vs. 83.3% accuracy gives p=1.8e-12 but omits error bars, exact number of independent seeds per condition, data-exclusion rules, and whether the statistical test accounts for the spectral-seeding vs. random-init split.
Authors: We agree that the statistical reporting in the tables and §4.3 is incomplete. We will revise the tables to include error bars (standard deviations across runs), state the exact number of independent seeds (100 for the primary task, 50 for secondary tasks), clarify data-exclusion rules (accuracy reported only on converged seeds, with separate convergence rates), and specify that the two-sample t-test is applied to the converged runs while accounting for the spectral-seeding versus random-initialization split. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from model equations
full rationale
The paper's core claim is a mathematical proof that phase displacement under weak output nudging equals the gradient of the loss w.r.t. natural frequencies exactly in the beta to 0 limit, obtained via implicit differentiation of the equilibrium condition from the standard nudged Kuramoto dynamics. This is a direct consequence of the oscillator equations and equilibrium propagation definitions rather than any fitted parameter, self-definition, or load-bearing self-citation chain. Prior oscillator EP work is referenced only for context on why frequency learning was previously set aside; the new proof and sparse-layer experiments stand independently. No step reduces by construction to its inputs, and the reported convergence issues are treated as loss-landscape properties separate from the gradient equality.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The coupled Kuramoto network reaches a stable equilibrium under the given dynamics
- domain assumption Nudging strength beta can be taken to the limit of zero while preserving stability and differentiability
Reference graph
Works this paper leans on
-
[1]
S. Bai, J. Z. Kolter, and V. Koltun. Deep equilibrium models. In NeurIPS, 2019
2019
-
[2]
F. R. K. Chung. Spectral Graph Theory. AMS, 1997
1997
-
[3]
Dillavou, B
S. Dillavou, B. Beyer, M. Stern, M. Z. Miskin, A. J. Liu, and D. J. Durian. Machine learning without a processor: Emergent learning in a nonlinear analog network. PNAS, 121(8):e2319718121, 2024
2024
-
[4]
Ernoult, J
M. Ernoult, J. Grollier, D. Querlioz, Y. Bengio, and B. Scellier. Updates of equilibrium prop match gradients of backprop through time in an RNN with static input. In NeurIPS, 2019
2019
-
[5]
A. Gower et al. How to train an oscillator I sing machine using equilibrium propagation. arXiv:2505.02103, 2025
-
[6]
A. Gower et al. Learning at the speed of physics. arXiv:2510.12934, 2025
-
[7]
Energy-based trans- formers are scalable learners and thinkers.arXiv preprint arXiv:2507.02092, 2025
A. Gladstone et al. Energy-based transformers are scalable learners and thinkers. arXiv:2507.02092, 2025
-
[8]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Hillenbrand, L
J. Hillenbrand, L. A. Getty, M. J. Clark, and K. Wheeler. Acoustic characteristics of A merican E nglish vowels. J.\ Acoust.\ Soc.\ Am., 97(5):3099--3111, 1995
1995
-
[10]
J. J. Hopfield. Neural networks and physical systems with emergent collective computational abilities. PNAS, 79(8):2554--2558, 1982
1982
-
[11]
F. C. Hoppensteadt and E. M. Izhikevich. Oscillatory neurocomputers with dynamic connectivity. Physical Review Letters, 82(14):2983--2986, 1999
1999
-
[12]
J. Kendall, R. Pantone, K. Manickavasagam, Y. Bengio, and B. Scellier. Training end-to-end analog neural networks with equilibrium propagation. arXiv:2006.01981, 2020
-
[13]
Korthikanti, J
V. Korthikanti, J. Casper, S. Lym, L. McAfee, M. Andersch, M. Shoeybi, and B. Catanzaro. Reducing activation recomputation in large transformer models. In MLSys, 2023
2023
-
[14]
Kuramoto
Y. Kuramoto. Chemical Oscillations, Waves, and Turbulence. Springer, 1984
1984
-
[15]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
A. Liu et al. DeepSeek-V2 : A strong, economical, and efficient mixture-of-experts language model. arXiv:2405.04434, 2024
work page internal anchor Pith review arXiv 2024
-
[16]
S. Ma et al. The era of 1-bit LLMs : All large language models are in 1.58 bits. arXiv:2402.17764, 2024
-
[17]
Miyato, S
T. Miyato, S. L\"owe, A. Geiger, and M. Welling. Artificial K uramoto oscillatory neurons. In ICLR, 2025
2025
-
[18]
Momeni, B
A. Momeni, B. Rahmani, B. Scellier, L. G. Wright, P. L. McMahon, C. C. Wanjura, et al. Training of physical neural networks. Nature, 645:53--61, 2025
2025
-
[19]
Carbon Emissions and Large Neural Network Training
D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean. Carbon emissions and large neural network training. arXiv:2104.10350, 2021
work page internal anchor Pith review arXiv 2021
-
[20]
T. Rageau and J. Grollier. Training and synchronizing oscillator networks with equilibrium propagation. arXiv:2504.11884, 2025
-
[21]
Scellier and Y
B. Scellier and Y. Bengio. Equilibrium propagation: Bridging the gap between energy-based models and backpropagation. Frontiers in Computational Neuroscience, 11:24, 2017
2017
- [22]
-
[23]
Shazeer et al
N. Shazeer et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In ICLR, 2017
2017
-
[24]
S. H. Strogatz. From K uramoto to C rawford: exploring the onset of synchronization. Physica D, 143(1--4):1--20, 2000
2000
-
[25]
Todri-Sanial, C
A. Todri-Sanial, C. Delacour, M. Abernot, and F. Sabo. Computing with oscillators from theoretical underpinnings to applications and demonstrators. npj Unconventional Computing, 1:15, 2024
2024
-
[26]
Q. Wang, C. C. Wanjura, and F. Marquardt. Training coupled phase oscillators as a neuromorphic platform using equilibrium propagation. Neuromorphic Computing and Engineering, 4:034014, 2024
2024
-
[27]
C. C. Wanjura and F. Marquardt. Quantum equilibrium propagation for efficient training of quantum systems based on O nsager reciprocity. Nature Communications, 16:3592, 2025
2025
-
[28]
Xie and H
X. Xie and H. S. Seung. Equivalence of backpropagation and contrastive H ebbian learning in a layered network. Neural Computation, 15(2):441--454, 2003
2003
-
[29]
Zucchet and J
N. Zucchet and J. Sacramento. Beyond backpropagation: Bilevel optimization through implicit differentiation and equilibrium propagation. Neural Computation, 34(12):2309--2346, 2022
2022
-
[30]
Zoppo, F
G. Zoppo, F. Marrone, M. Bonnin, and F. Corinto. Equilibrium propagation and (memristor-based) oscillatory neural networks. In IEEE International Symposium on Circuits and Systems (ISCAS), pp. 639--643, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.