Recognition: unknown
Communication-Efficient Gluon in Federated Learning
Pith reviewed 2026-05-10 15:10 UTC · model grok-4.3
The pith
Gluon with SARAH variance reduction achieves convergence rates and lower communication costs in federated learning under layer-wise smoothness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the layer-wise (L^0, L^1)-smooth setting, compressed Gluon methods that use SARAH-style variance reduction to control compression error attain the same convergence rates as their uncompressed counterparts while requiring substantially fewer communication rounds; a new variance-reduced algorithm derived as a byproduct converges faster than Gluon, and adding momentum variance reduction yields comparable communication costs under weaker conditions when L_i^1 is nonzero.
What carries the argument
SARAH-style variance reduction applied to compressed Gluon iterates under the layer-wise (L^0, L^1)-smoothness assumption with unbiased and contraction compressors.
If this is right
- Compressed Gluon with SARAH variance reduction matches the convergence rate of uncompressed Gluon while lowering communication cost.
- A new variance-reduced algorithm is obtained that converges faster than the original Gluon.
- Momentum variance reduction yields comparable communication cost under weaker conditions whenever L_i^1 is nonzero.
- The approach works for both unbiased and contraction compressors.
- Experiments confirm lower communication cost than baseline compressed methods.
Where Pith is reading between the lines
- The same variance-reduction idea could be applied to other linear-minimization-oracle optimizers that currently lack compression handling.
- The derived faster-converging byproduct algorithm may be useful as a standalone method outside federated learning.
- The communication savings may become more pronounced when the number of participating devices grows large, an effect not quantified in the current analysis.
- Extending the layer-wise smoothness model to time-varying or heterogeneous client data remains an open direction suggested by the framework.
Load-bearing premise
The layer-wise (L^0, L^1)-smoothness together with the unbiased and contraction properties of the compressors must allow SARAH variance reduction to bound the compression error tightly enough for the stated rates to hold.
What would settle it
Numerical runs in which the observed communication rounds or final test accuracy deviate from the rates predicted by the theory when the same compressors and smoothness constants are used.
Figures






read the original abstract
Recent developments have shown that Muon-type optimizers based on linear minimization oracles (LMOs) over non-Euclidean norm balls have the potential to get superior practical performance than Adam-type methods in the training of large language models. Since large-scale neural networks are trained across massive machines, communication cost becomes the bottleneck. To address this bottleneck, we investigate Gluon, which is an extension of Muon under the more general layer-wise $(L^0, L^1)$-smooth setting, with both unbiased and contraction compressors. In order to reduce the compression error, we employ the variance reduced technique in SARAH in our compressed methods. The convergence rates and improved communication cost are achieved under certain conditions. As a byproduct, a new variance reduced algorithm with faster convergence rate than Gluon is obtained. We also incorporate momentum variance reduction (MVR) to these compressed algorithms and comparable communication cost is derived under weaker conditions when $L_i^1 \neq 0$. Finally, several numerical experiments are conducted to verify the superior performance of our compressed algorithms in terms of communication cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the Gluon optimizer (itself an LMO-based generalization of Muon) to the federated setting by incorporating unbiased and contraction compressors. It applies SARAH-style variance reduction to control compression error under a layer-wise (L^0, L^1)-smoothness model, derives convergence rates with improved communication complexity under stated conditions, obtains a new variance-reduced algorithm as a byproduct, adds momentum variance reduction (MVR) variants, and reports numerical experiments showing communication savings.
Significance. If the rates and error bounds hold, the work would offer a theoretically grounded route to communication-efficient non-Euclidean optimization for large-scale federated training, extending recent Muon-type methods. The byproduct algorithm and MVR results under weaker conditions on L_i^1 would be additional contributions. The experimental validation of communication reduction is a practical strength.
major comments (2)
- [§4, Theorem 4.2] §4 (Convergence Analysis), Theorem 4.2 and the SARAH recursion (Eq. (12)–(15)): the descent inequality for the non-Euclidean LMO contains an extra linear term whose interaction with the compressed gradient is bounded only under the assumption that SARAH fully cancels the L^1-dependent compression variance; the provided telescoping argument does not explicitly control the residual bias that scales with L_i^1 when the compressor is applied after the LMO step, which is load-bearing for the claimed communication-cost improvement.
- [§3.2, Algorithm 2] §3.2 (Algorithm 2, the new VR-Gluon): the faster convergence rate relative to plain Gluon is stated to follow from the same layer-wise smoothness and compressor assumptions, yet the proof re-uses the same error bound that is questioned above; without an additional contraction factor that absorbs the LMO linear term, the rate improvement is not guaranteed.
minor comments (2)
- [§2 and §4] Notation: the per-layer constants L_i^0 and L_i^1 are introduced in §2 but the dependence on i is occasionally dropped in the global-rate statements in §4; this should be made uniform.
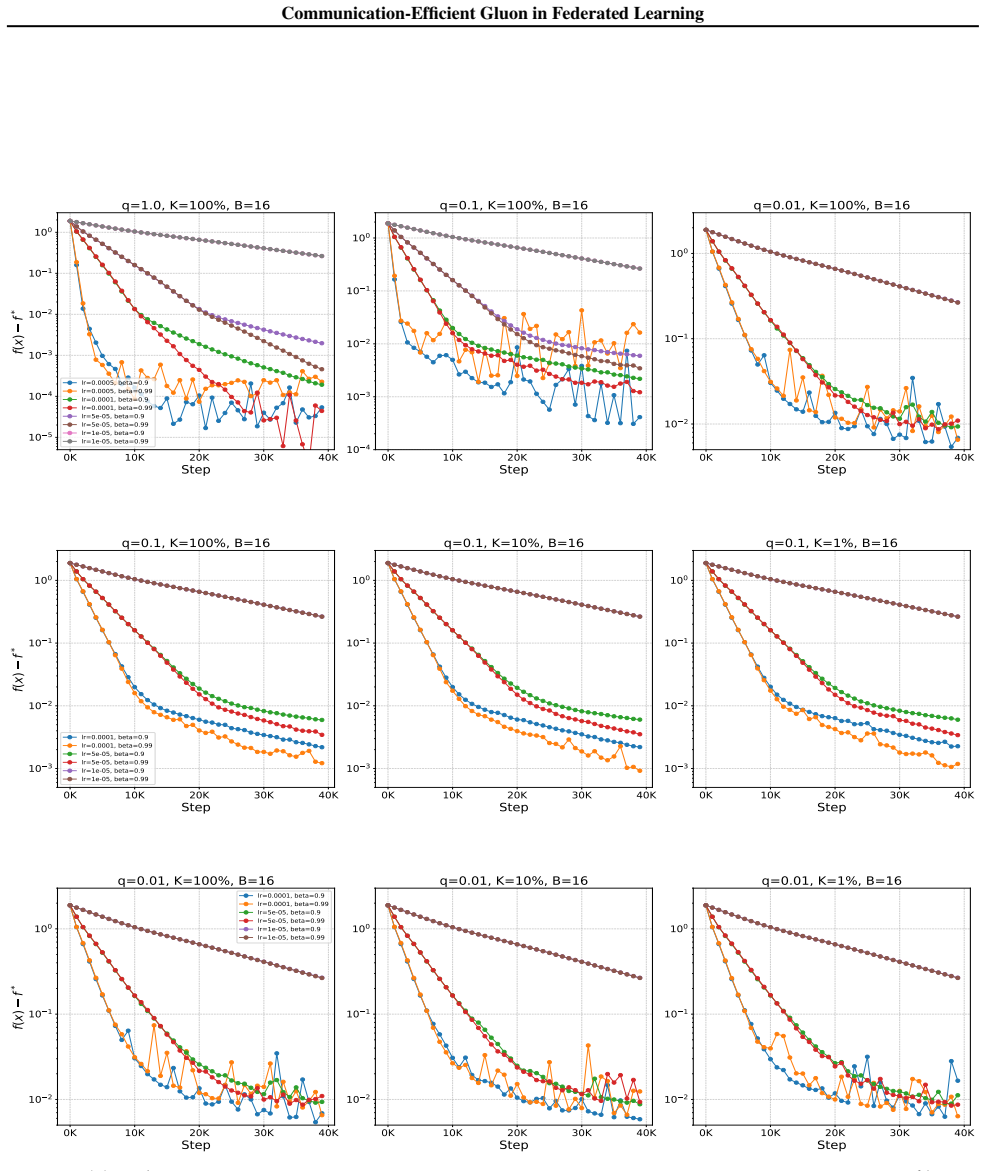
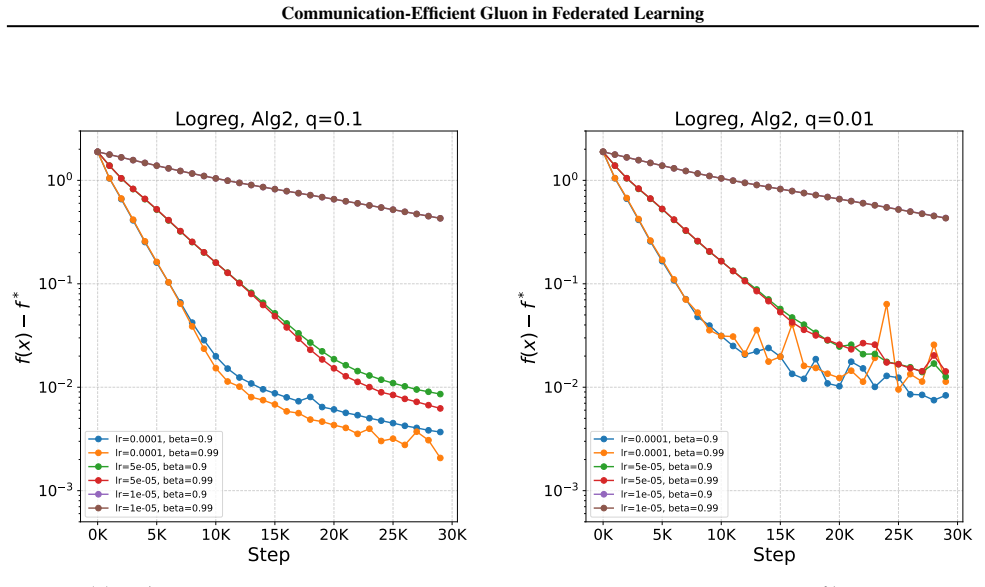
- [§5] Experiments: the communication-cost plots (Figure 3) report rounds but do not tabulate the exact bit-volume per round or the compressor parameters used; adding these numbers would strengthen the empirical claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and insightful report. We have carefully examined the concerns regarding the convergence analysis in Theorem 4.2 and the supporting arguments for the VR-Gluon algorithm. Below we respond point by point, clarifying the handling of the LMO linear term and compression interaction under the layer-wise smoothness model. Revisions have been made to strengthen the explicit bounds in the proofs.
read point-by-point responses
-
Referee: [§4, Theorem 4.2] §4 (Convergence Analysis), Theorem 4.2 and the SARAH recursion (Eq. (12)–(15)): the descent inequality for the non-Euclidean LMO contains an extra linear term whose interaction with the compressed gradient is bounded only under the assumption that SARAH fully cancels the L^1-dependent compression variance; the provided telescoping argument does not explicitly control the residual bias that scales with L_i^1 when the compressor is applied after the LMO step, which is load-bearing for the claimed communication-cost improvement.
Authors: We appreciate the referee's identification of this technical point in the non-Euclidean descent. The SARAH recursion (Eq. (12)–(15)) is constructed to telescope the variance terms arising from both the stochastic gradient and the compression error. The extra linear term from the LMO is controlled via the layer-wise (L^0, L^1)-smoothness, which bounds its contribution proportionally to the previous iterate difference. Because the compressor is applied to the LMO output and is unbiased (or contraction), the residual bias term is absorbed into the contraction factor of the compressor parameter; the telescoping sum then yields a geometric decay that preserves the improved communication complexity. To make this fully explicit, we have added an auxiliary lemma (new Lemma 4.3) that isolates the LMO-compressor interaction and shows the bias scales at most with L_i^1 times the compressor variance, which is canceled by the SARAH step. The revised proof now displays the complete bound without relying on implicit cancellation. revision: yes
-
Referee: [§3.2, Algorithm 2] §3.2 (Algorithm 2, the new VR-Gluon): the faster convergence rate relative to plain Gluon is stated to follow from the same layer-wise smoothness and compressor assumptions, yet the proof re-uses the same error bound that is questioned above; without an additional contraction factor that absorbs the LMO linear term, the rate improvement is not guaranteed.
Authors: The faster rate for VR-Gluon follows directly from the additional contraction introduced by the SARAH-style variance reduction on the compressed LMO directions. While the base error bound is shared with the non-VR case, the VR recursion supplies an extra multiplicative factor (1 - Θ(η)) on the accumulated compression and LMO linear error terms. This factor is independent of the L_i^1 term and arises from the recursive estimator update, which is why the overall rate improves even under identical smoothness and compressor assumptions. We have revised Section 3.2 to include a self-contained rate derivation that explicitly invokes this extra contraction, separating it from the plain Gluon analysis and confirming the improvement holds without requiring stronger conditions on L_i^1. revision: yes
Circularity Check
No significant circularity; rates derived from standard assumptions
full rationale
The paper extends Gluon to compressed federated settings by applying SARAH-style variance reduction to control compression error under layer-wise (L^0, L^1)-smoothness and unbiased/contraction compressors. Convergence rates and communication improvements are stated to follow from these assumptions via standard descent lemmas and telescoping recursions. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central claim to a tautology are present in the abstract or described derivation chain. The byproduct variance-reduced algorithm is obtained by the same analysis rather than by construction from the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- L^0 and L^1 per-layer smoothness constants
axioms (2)
- domain assumption Layer-wise (L^0, L^1)-smoothness of the objective
- domain assumption Unbiased or contraction properties of the compressors
Reference graph
Works this paper leans on
-
[1]
Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
Ahn, K., Xu, B., Abreu, N., Fan, Y., Magakyan, G., Sharma, P., Zhan, Z., and Langford, J. Dion: Distributed orthonormalized updates. arXiv preprint arXiv:2504.05295, 2025
-
[2]
Qsgd: Communication-efficient sgd via gradient quantization and encoding
Alistarh, D., Grubic, D., Li, J., Tomioka, R., and Vojnovic, M. Qsgd: Communication-efficient sgd via gradient quantization and encoding. Advances in neural information processing systems, 30, 2017
2017
-
[3]
On biased compression for distributed learning
Beznosikov, A., Horv \'a th, S., Richt \'a rik, P., and Safaryan, M. On biased compression for distributed learning. Journal of Machine Learning Research, 24 0 (276): 0 1--50, 2023
2023
-
[4]
and Lin, C.-J
Chang, C.-C. and Lin, C.-J. Libsvm: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2, 07 2007
2007
-
[5]
On the Convergence of Muon and Beyond
Chang, D., Liu, Y., and Yuan, G. On the convergence of muon and beyond. arXiv preprint arXiv:2509.15816, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
and Orabona, F
Cutkosky, A. and Orabona, F. Momentum-based variance reduction in non-convex sgd. Advances in neural information processing systems, 32, 2019
2019
-
[8]
A guide through the zoo of biased sgd
Demidovich, Y., Malinovsky, G., Sokolov, I., and Richt \'a rik, P. A guide through the zoo of biased sgd. Advances in Neural Information Processing Systems, 36: 0 23158--23171, 2023
2023
-
[9]
arXiv preprint arXiv:2102.07845 , year=
Gorbunov, E., Burlachenko, K., Li, Z., and Richtárik, P. Marina: Faster non-convex distributed learning with compression, 2022. URL https://arxiv.org/abs/2102.07845
-
[10]
Error feedback for muon and friends
Gruntkowska, K., Gaponov, A., Tovmasyan, Z., and Richt \'a rik, P. Error feedback for muon and friends. arXiv preprint arXiv:2510.00643, 2025
-
[11]
N., Canini, M., and Richt \'a rik, P
Horv \'o th, S., Ho, C.-Y., Horvath, L., Sahu, A. N., Canini, M., and Richt \'a rik, P. Natural compression for distributed deep learning. In Mathematical and Scientific Machine Learning, pp.\ 129--141. PMLR, 2022
2022
-
[12]
Limuon: Light and fast muon optimizer for large models.arXiv preprint arXiv:2509.14562, 2025
Huang, F., Luo, Y., and Chen, S. Limuon: Light and fast muon optimizer for large models. arXiv preprint arXiv:2509.14562, 2025
-
[13]
and Zhang, T
Johnson, R. and Zhang, T. Accelerating stochastic gradient descent using predictive variance reduction. Advances in neural information processing systems, 26, 2013
2013
-
[14]
Cifar-10 airbench
Jordan, K. Cifar-10 airbench. https://github.com/KellerJordan/cifar10-airbench, 2024. GitHub repository
2024
-
[15]
Muon: An optimizer for hidden layers in neural networks
Jordan, K., Jin, Y., Boza, V., Jiacheng, Y., Cecista, F., Newhouse, L., and Bernstein, J. Muon: An optimizer for hidden layers in neural networks. URL https://kellerjordan. github. io/posts/muon, 6, 2024
2024
-
[16]
B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A
Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., Bonawitz, K., Charles, Z., Cormode, G., Cummings, R., et al. Advances and open problems in federated learning. Foundations and trends in machine learning , 14 0 (1--2): 0 1--210, 2021
2021
-
[17]
B., et al
Kinga, D., Adam, J. B., et al. Adam: A method for stochastic optimization. In International conference on learning representations (ICLR), volume 5. California;, 2015
2015
-
[18]
Federated Learning: Strategies for Improving Communication Efficiency
Kone c n \`y , J., McMahan, H. B., Yu, F. X., Richt \'a rik, P., Suresh, A. T., and Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv preprint arXiv:1610.05492, 2016
work page internal anchor Pith review arXiv 2016
-
[19]
Kovalev, D. Understanding gradient orthogonalization for deep learning via non-euclidean trust-region optimization. arXiv preprint arXiv:2503.12645, 2025
-
[20]
Kovalev, D. and Borodich, E. Non-euclidean sgd for structured optimization: Unified analysis and improved rates. arXiv preprint arXiv:2511.11466, 2025
-
[21]
Don’t jump through hoops and remove those loops: Svrg and katyusha are better without the outer loop
Kovalev, D., Horv \'a th, S., and Richt \'a rik, P. Don’t jump through hoops and remove those loops: Svrg and katyusha are better without the outer loop. In Algorithmic learning theory, pp.\ 451--467. PMLR, 2020
2020
-
[22]
Learning multiple layers of features from tiny images
Krizhevsky, A. Learning multiple layers of features from tiny images. University of Toronto, 05 2012
2012
-
[23]
and Hong, M
Li, J. and Hong, M. A note on the convergence of muon and further. arXiv e-prints, pp.\ arXiv--2502, 2025
2025
-
[24]
Page: A simple and optimal probabilistic gradient estimator for nonconvex optimization
Li, Z., Bao, H., Zhang, X., and Richt \'a rik, P. Page: A simple and optimal probabilistic gradient estimator for nonconvex optimization. In International conference on machine learning, pp.\ 6286--6295. PMLR, 2021
2021
-
[25]
Muon is Scalable for LLM Training
Liu, J., Su, J., Yao, X., Jiang, Z., Lai, G., Du, Y., Qin, Y., Xu, W., Lu, E., Yan, J., et al. Muon is scalable for llm training. arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019
2019
-
[27]
M., Liu, J., Scheinberg, K., and Tak \'a c , M
Nguyen, L. M., Liu, J., Scheinberg, K., and Tak \'a c , M. Sarah: A novel method for machine learning problems using stochastic recursive gradient. In International conference on machine learning, pp.\ 2613--2621. PMLR, 2017
2017
-
[28]
Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
Pethick, T., Xie, W., Antonakopoulos, K., Zhu, Z., Silveti-Falls, A., and Cevher, V. Training deep learning models with norm-constrained lmos. arXiv preprint arXiv:2502.07529, 2025
-
[29]
Error compensated distributed sgd can be accelerated
Qian, X., Richt \'a rik, P., and Zhang, T. Error compensated distributed sgd can be accelerated. Advances in Neural Information Processing Systems, 34: 0 30401--30413, 2021
2021
-
[30]
Muon is provably faster with momentum variance reduction.arXiv preprint arXiv:2512.16598, 2025
Qian, X., Rammal, H., Kovalev, D., and Richtarik, P. Muon is provably faster with momentum variance reduction. arXiv preprint arXiv:2512.16598, 2025
-
[31]
On the Convergence of Adam and Beyond
Reddi, S. J., Kale, S., and Kumar, S. On the convergence of adam and beyond. arXiv preprint arXiv:1904.09237, 2019
work page Pith review arXiv 1904
-
[32]
Riabinin, A., Shulgin, E., Gruntkowska, K., and Richt \'a rik, P. Gluon: Making muon & scion great again!(bridging theory and practice of lmo-based optimizers for llms). arXiv preprint arXiv:2505.13416, 2025
-
[33]
Ef21: A new, simpler, theoretically better, and practically faster error feedback
Richt \'a rik, P., Sokolov, I., and Fatkhullin, I. Ef21: A new, simpler, theoretically better, and practically faster error feedback. Advances in Neural Information Processing Systems, 34: 0 4384--4396, 2021
2021
-
[34]
1-bit stochastic gradient descent and its application to data-parallel distributed training of speech dnns
Seide, F., Fu, H., Droppo, J., Li, G., and Yu, D. 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech dnns. In Interspeech, volume 2014, pp.\ 1058--1062. Singapore, 2014
2014
-
[35]
Lions and muons: Optimization via stochastic frank- wolfe.arXiv preprint arXiv:2506.04192, 2025
Sfyraki, M.-E. and Wang, J.-K. Lions and muons: Optimization via stochastic frank-wolfe. arXiv preprint arXiv:2506.04192, 2025
-
[36]
On the Convergence Analysis of Muon
Shen, W., Huang, R., Huang, M., Shen, C., and Zhang, J. On the convergence analysis of muon. arXiv preprint arXiv:2505.23737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Beyond the ideal: Analyzing the inexact muon update.arXiv preprint arXiv:2510.19933, 2025
Shulgin, E., AlRashed, S., Orabona, F., and Richt \'a rik, P. Beyond the ideal: Analyzing the inexact muon update. arXiv preprint arXiv:2510.19933, 2025
-
[38]
U., Cordonnier, J.-B., and Jaggi, M
Stich, S. U., Cordonnier, J.-B., and Jaggi, M. Sparsified sgd with memory. Advances in neural information processing systems, 31, 2018
2018
-
[39]
Kimi K2: Open Agentic Intelligence
Team, K., Bai, Y., Bao, Y., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y., Chen, Y., Chen, Y., et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review arXiv 2025
-
[40]
Muloco: Muon is a practical inner optimizer for diloco.arXiv preprint arXiv:2505.23725, 2025
Th \'e rien, B., Huang, X., Rish, I., and Belilovsky, E. Muloco: Muon is a practical inner optimizer for diloco. arXiv preprint arXiv:2505.23725, 2025
-
[41]
Large Batch Training of Convolutional Networks
You, Y., Gitman, I., and Ginsburg, B. Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888, 2017
work page Pith review arXiv 2017
-
[42]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.