Recognition: unknown
Unified Graph Prompt Learning via Low-Rank Graph Message Prompting
Pith reviewed 2026-05-10 16:02 UTC · model grok-4.3
The pith
A low-rank prompt representation unifies graph data prompting for all components simultaneously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By reinterpreting a wide range of existing graph data prompts from the aspect of the Graph Message Prompt paradigm, the authors develop LR-GMP, which leverages low-rank prompt representation to achieve concurrent prompting on all graph components in a unified manner, thereby achieving significantly superior generalization and robustness on diverse downstream tasks.
What carries the argument
The Graph Message Prompt paradigm reinterpreted via low-rank prompt representations that concurrently target node features, edge features, and edge weights.
Load-bearing premise
Reinterpreting existing graph data prompts as a Graph Message Prompt paradigm allows a low-rank representation to capture sufficient information across all components without significant loss of task-specific detail.
What would settle it
If LR-GMP shows no improvement or underperforms traditional component-specific prompts on multiple graph benchmark datasets, or if low-rank prompts demonstrably omit key task details in complex graphs, the central claim would be refuted.
Figures




read the original abstract
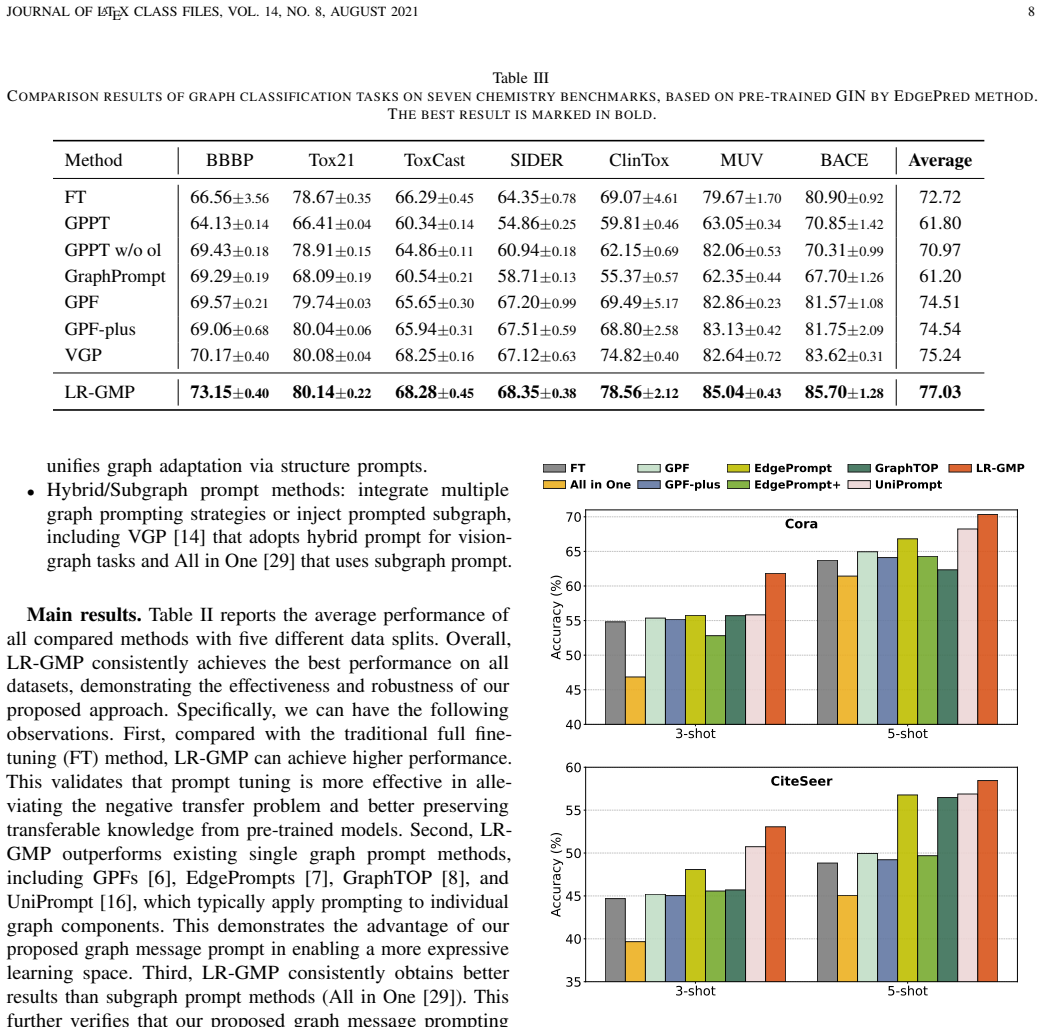
Graph Data Prompt (GDP), which introduces specific prompts in graph data for efficiently adapting pre-trained GNNs, has become a mainstream approach to graph fine-tuning learning problem. However, existing GDPs have been respectively designed for distinct graph component (e.g., node features, edge features, edge weights) and thus operate within limited prompt spaces for graph data. To the best of our knowledge, it still lacks a unified prompter suitable for targeting all graph components simultaneously. To address this challenge, in this paper, we first propose to reinterpret a wide range of existing GDPs from an aspect of Graph Message Prompt (GMP) paradigm. Based on GMP, we then introduce a novel graph prompt learning approach, termed Low-Rank GMP (LR-GMP), which leverages low-rank prompt representation to achieve an effective and compact graph prompt learning. Unlike traditional GDPs that target distinct graph components separately, LR-GMP concurrently performs prompting on all graph components in a unified manner, thereby achieving significantly superior generalization and robustness on diverse downstream tasks. Extensive experiments on several graph benchmark datasets demonstrate the effectiveness and advantages of our proposed LR-GMP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reinterprets a range of existing Graph Data Prompt (GDP) techniques as instances of a unified Graph Message Prompt (GMP) paradigm. It then introduces Low-Rank GMP (LR-GMP), which applies a low-rank factorization to enable simultaneous prompting across all graph components (node features, edge features, edge weights) rather than designing separate prompts for each. The central claim is that this unified low-rank approach yields significantly better generalization and robustness on downstream tasks than component-specific GDPs, supported by experiments on standard graph benchmark datasets.
Significance. If the low-rank unification preserves expressiveness across heterogeneous components, the method could reduce the fragmentation in current graph prompt learning and offer a more compact, general-purpose adapter for pre-trained GNNs. The reinterpretation as GMP provides a useful organizing lens, and the emphasis on concurrent prompting addresses a genuine gap. However, the significance is tempered by the absence of explicit analysis showing that the shared low-rank bottleneck suffices without underfitting any component.
major comments (2)
- [§3 (Proposed Method)] §3 (Proposed Method): the claim that a single low-rank prompt representation captures sufficient information for all graph components simultaneously is load-bearing for the unification argument, yet no bound, expressiveness analysis, or justification is given for why the chosen rank avoids material loss when components have distinct statistical structures (sparse edge weights versus dense node attributes).
- [§4 (Experiments)] §4 (Experiments): no ablation is reported on the prompt-rank hyperparameter or its effect on per-component fidelity, which directly tests the skeptic's concern that the low-rank bottleneck may underfit heterogeneous components and thereby undermines the generalization-robustness claim.
minor comments (2)
- [Abstract] Abstract: the assertion of 'significantly superior generalization' is not accompanied by any quantitative deltas, dataset names, or baseline comparisons, reducing immediate clarity.
- [§3] Notation: the transition from the GMP paradigm to the low-rank matrix factorization would benefit from an explicit equation defining how the shared low-rank factors are applied to each graph component.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the theoretical and empirical foundations of LR-GMP. We address each major point below and have prepared a revised manuscript that incorporates additional justification and experiments.
read point-by-point responses
-
Referee: [§3 (Proposed Method)] the claim that a single low-rank prompt representation captures sufficient information for all graph components simultaneously is load-bearing for the unification argument, yet no bound, expressiveness analysis, or justification is given for why the chosen rank avoids material loss when components have distinct statistical structures (sparse edge weights versus dense node attributes).
Authors: We acknowledge that the original manuscript did not include a formal expressiveness analysis. The low-rank design is motivated by the fact that GMP operates on the message-passing level, where node, edge, and weight components are already coupled through the pre-trained GNN's embedding space rather than being fully independent. In the revision we have added a new paragraph in §3.3 that applies the Eckart-Young-Mirsky theorem to the concatenated component matrix and shows that the rank-r truncation error is bounded by the sum of the discarded singular values; empirical singular-value plots (now included as Figure 3) confirm rapid decay across the evaluated benchmarks, supporting that a modest shared rank suffices even when raw component statistics differ. We also note that component-specific prompts would require separate low-rank factors whose total parameter count exceeds the unified version, but we accept that a tighter per-component guarantee remains an open direction. revision: yes
-
Referee: [§4 (Experiments)] no ablation is reported on the prompt-rank hyperparameter or its effect on per-component fidelity, which directly tests the skeptic's concern that the low-rank bottleneck may underfit heterogeneous components and thereby undermines the generalization-robustness claim.
Authors: We agree that an explicit rank ablation is necessary to address concerns about underfitting. The revised §4.4 now reports results for r ∈ {1,2,4,8,16} on all five benchmark datasets, measuring both end-task metrics (node classification accuracy, link-prediction AUC) and per-component fidelity (MSE on reconstructed node features, edge features, and edge weights after prompting). The curves show that performance plateaus at r=8 with negligible additional gain at higher ranks and no disproportionate degradation on the sparse edge-weight component relative to dense node attributes, thereby empirically supporting the unified low-rank choice. revision: yes
Circularity Check
No significant circularity in LR-GMP derivation
full rationale
The paper proposes reinterpreting existing GDPs as a GMP paradigm and then introduces LR-GMP as a new low-rank unified prompting method. This is a methodological contribution with empirical validation on benchmarks rather than any derivation chain that reduces predictions or results to fitted inputs, self-definitions, or load-bearing self-citations by construction. No equations or steps equate outputs to inputs via the enumerated circular patterns; the central unification claim is presented as novel and tested independently.
Axiom & Free-Parameter Ledger
free parameters (1)
- prompt rank
axioms (2)
- domain assumption Existing GDPs can be uniformly reinterpreted as instances of a Graph Message Prompt paradigm
- domain assumption Low-rank prompt matrices preserve essential information for all graph components
invented entities (1)
-
Graph Message Prompt (GMP) paradigm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Graph foundation models: Concepts, opportunities and challenges,
J. Liu, C. Yang, Z. Lu, J. Chen, Y . Li, M. Zhang, T. Bai, Y . Fang, L. Sun, P. S. Yu,et al., “Graph foundation models: Concepts, opportunities and challenges,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 6, pp. 5023–5044, 2025
2025
-
[2]
Adaptergnn: Parameter-efficient fine-tuning improves generalization in gnns,
S. Li, X. Han, and J. Bai, “Adaptergnn: Parameter-efficient fine-tuning improves generalization in gnns,” inProceedings of the AAAI Conference on Artificial Intelligence, pp. 13600–13608, 2024
2024
-
[3]
G-adapter: Towards structure-aware parameter-efficient transfer learning for graph transformer networks,
A. Gui, J. Ye, and H. Xiao, “G-adapter: Towards structure-aware parameter-efficient transfer learning for graph transformer networks,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 12226–12234, 2024
2024
-
[4]
Graphlora: Structure- aware contrastive low-rank adaptation for cross-graph transfer learning,
Z.-R. Yang, J. Han, C.-D. Wang, and H. Liu, “Graphlora: Structure- aware contrastive low-rank adaptation for cross-graph transfer learning,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pp. 1785–1796, 2025
2025
-
[5]
Gppt: Graph pre- training and prompt tuning to generalize graph neural networks,
M. Sun, K. Zhou, X. He, Y . Wang, and X. Wang, “Gppt: Graph pre- training and prompt tuning to generalize graph neural networks,” in ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 1717–1727, 2022
2022
-
[6]
Universal prompt tuning for graph neural networks,
T. Fang, Y . Zhang, Y . Yang, C. Wang, and L. Chen, “Universal prompt tuning for graph neural networks,” inAdvances in Neural Information Processing Systems, pp. 52464–52489, 2023
2023
-
[7]
Edge prompt tuning for graph neural networks,
X. Fu, Y . He, and J. Li, “Edge prompt tuning for graph neural networks,” inInternational Conference on Learning Representations, 2025
2025
-
[8]
Graphtop: Graph topology-oriented prompting for graph neural networks,
X. Fu, Z. Lei, Z. Chen, B. Zhang, C. Zhang, and J. Li, “Graphtop: Graph topology-oriented prompting for graph neural networks,” inThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[9]
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,
P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,”ACM computing surveys, vol. 55, no. 9, pp. 1–35, 2023
2023
-
[10]
Prompt-based adaptation in large-scale vision models: A survey.arXiv preprint arXiv:2510.13219, 2025
X. Xiao, Y . Zhang, L. Zhao, Y . Liu, X. Liao, Z. Mai, X. Li, X. Wang, H. Xu, J. Hamm,et al., “Prompt-based adaptation in large-scale vision models: A survey,”arXiv preprint arXiv:2510.13219, 2025
-
[11]
Graph prompt learning: A comprehensive survey and beyond,
X. Sun, J. Zhang, X. Wu, H. Cheng, Y . Xiong, and J. Li, “Graph prompt learning: A comprehensive survey and beyond,”arXiv preprint arXiv:2311.16534, 2023
-
[12]
A survey of graph prompting methods: techniques, applications, and challenges,
X. Wu, K. Zhou, M. Sun, X. Wang, and N. Liu, “A survey of graph prompting methods: techniques, applications, and challenges,”arXiv preprint arXiv:2303.07275, 2023
-
[13]
Graphprompt: Unifying pre- training and downstream tasks for graph neural networks,
Z. Liu, X. Yu, Y . Fang, and X. Zhang, “Graphprompt: Unifying pre- training and downstream tasks for graph neural networks,” inProceedings of the ACM Web Conference 2023, pp. 417–428, 2023
2023
-
[14]
Vision graph prompting via semantic low- rank decomposition,
Z. Ai, Z. Liu, and J. Zhou, “Vision graph prompting via semantic low- rank decomposition,” inInternational Conference on Machine Learning, 2025
2025
-
[15]
A data-centric framework to endow graph neural networks with out-of-distribution detection ability,
Y . Guo, C. Yang, Y . Chen, J. Liu, C. Shi, and J. Du, “A data-centric framework to endow graph neural networks with out-of-distribution detection ability,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 638–648, 2023
2023
-
[16]
One prompt fits all: Universal graph adaptation for pretrained models,
Y . Huang, J. Zhao, D. He, X. Wang, Y . Li, Y . Huang, D. Jin, and Z. Feng, “One prompt fits all: Universal graph adaptation for pretrained models,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[17]
Instance-aware graph prompt learning,
J. Li, J. Li, and C. Zhang, “Instance-aware graph prompt learning,”arXiv preprint arXiv:2411.17676, 2024
-
[18]
Fairness-aware prompt tuning for graph neural networks,
Z. Li, M. Lin, J. Wang, and S. Wang, “Fairness-aware prompt tuning for graph neural networks,” inProceedings of the ACM on Web Conference 2025, pp. 3586–3597, 2025
2025
-
[19]
Neural message passing for quantum chemistry,
J. Gilmer, S. S. Schoenholz, P. F. Riley, O. Vinyals, and G. E. Dahl, “Neural message passing for quantum chemistry,” inInternational conference on machine learning, pp. 1263–1272, Pmlr, 2017
2017
-
[20]
Magprompt: Message-adaptive graph prompt tuning for graph neural networks,
L. D. Nguyen and B. P. Nguyen, “Magprompt: Message-adaptive graph prompt tuning for graph neural networks,”arXiv preprint arXiv:2602.05567, 2026
-
[21]
Unifying graph contrastive learning via graph message augmentation,
Z. Zhang, B. Jiang, J. Tang, and B. Luo, “Unifying graph contrastive learning via graph message augmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–17, 2025
2025
-
[22]
Gcc: Graph contrastive coding for graph neural network pre-training,
J. Qiu, Q. Chen, Y . Dong, J. Zhang, H. Yang, M. Ding, K. Wang, and J. Tang, “Gcc: Graph contrastive coding for graph neural network pre-training,” inACM SIGKDD international conference on knowledge discovery & data mining, pp. 1150–1160, 2020
2020
-
[23]
Graph con- trastive learning with augmentations,
Y . You, T. Chen, Y . Sui, T. Chen, Z. Wang, and Y . Shen, “Graph con- trastive learning with augmentations,” inAdvances in Neural Information Processing Systems, pp. 5812–5823, 2020
2020
-
[24]
Graphmae: Self-supervised masked graph autoencoders,
Z. Hou, X. Liu, Y . Cen, Y . Dong, H. Yang, C. Wang, and J. Tang, “Graphmae: Self-supervised masked graph autoencoders,” inACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 594– 604, 2022. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
2022
-
[25]
Rethinking and simplifying bootstrapped graph latents,
W. Sun, J. Li, L. Chen, B. Wu, Y . Bian, and Z. Zheng, “Rethinking and simplifying bootstrapped graph latents,” inACM International Conference on Web Search and Data Mining, pp. 665–673, 2024
2024
-
[26]
Simple unsupervised graph representation learning,
Y . Mo, L. Peng, J. Xu, X. Shi, and X. Zhu, “Simple unsupervised graph representation learning,” inProceedings of the AAAI conference on artificial intelligence, pp. 7797–7805, 2022
2022
-
[27]
Graph prompt clustering,
M.-S. Chen, P.-Y . Lai, D.-Z. Liao, C.-D. Wang, and J.-H. Lai, “Graph prompt clustering,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[28]
Relief: Reinforcement learning empowered graph feature prompt tuning,
J. Zhu, Z. Ding, J. Yu, J. Tan, X. Li, and W. Qian, “Relief: Reinforcement learning empowered graph feature prompt tuning,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 2159–2170, 2025
2025
-
[29]
All in one: Multi-task prompting for graph neural networks,
X. Sun, H. Cheng, J. Li, B. Liu, and J. Guan, “All in one: Multi-task prompting for graph neural networks,” inACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 2120–2131, 2023
2023
-
[30]
Virtual node tuning for few- shot node classification,
Z. Tan, R. Guo, K. Ding, and H. Liu, “Virtual node tuning for few- shot node classification,” inProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 2177–2188, 2023
2023
-
[31]
Psp: Pre-training and structure prompt tuning for graph neural networks,
Q. Ge, Z. Zhao, Y . Liu, A. Cheng, X. Li, S. Wang, and D. Yin, “Psp: Pre-training and structure prompt tuning for graph neural networks,” inJoint European Conference on Machine Learning and Knowledge Discovery in Databases, 2024
2024
-
[32]
Message passing all the way up,
P. Veliˇckovi´c, “Message passing all the way up,” inICLR Workshop on Geometrical and Topological Representation Learning, 2022
2022
-
[33]
Semi-supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” inInternational Conference on Learning Representation, 2017
2017
-
[34]
Graph Attention Networks,
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Li `o, and Y . Bengio, “Graph Attention Networks,” inInternational Conference on Learning Representations, 2018
2018
-
[35]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022
2022
-
[36]
Lor-vp: Low-rank visual prompting for efficient vision model adaptation,
C. Jin, Y . Li, M. Zhao, S. Zhao, Z. Wang, X. He, L. Han, T. Che, and D. N. Metaxas, “Lor-vp: Low-rank visual prompting for efficient vision model adaptation,” inInternational Conference on Learning Representations, 2025
2025
-
[37]
Open graph benchmark: Datasets for machine learning on graphs,
W. Hu, M. Fey, M. Zitnik, Y . Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec, “Open graph benchmark: Datasets for machine learning on graphs,” inAdvances in Neural Information Processing Systems, pp. 22118–22133, 2020
2020
-
[38]
GraphSAINT: Graph sampling based inductive learning method,
H. Zeng, H. Zhou, A. Srivastava, R. Kannan, and V . Prasanna, “GraphSAINT: Graph sampling based inductive learning method,” in International Conference on Learning Representations, 2020
2020
-
[39]
Zinc 15–ligand discovery for everyone,
T. Sterling and J. J. Irwin, “Zinc 15–ligand discovery for everyone,” Journal of chemical information and modeling, vol. 55, no. 11, pp. 2324– 2337, 2015
2015
-
[40]
Collective classification in network data,
P. Sen, G. Namata, M. Bilgic, L. Getoor, B. Galligher, and T. Eliassi-Rad, “Collective classification in network data,”AI Magazine, vol. 29, no. 3, pp. 93–93, 2008
2008
-
[41]
Pitfalls of Graph Neural Network Evaluation
O. Shchur, M. Mumme, A. Bojchevski, and S. G ¨unnemann, “Pitfalls of graph neural network evaluation,”arXiv preprint arXiv:1811.05868, 2018
work page Pith review arXiv 2018
-
[42]
Strategies for pre-training graph neural networks,
W. Hu, B. Liu, J. Gomes, M. Zitnik, P. Liang, V . Pande, and J. Leskovec, “Strategies for pre-training graph neural networks,” inInternational Conference on Learning Representations, 2020
2020
-
[43]
How powerful are graph neural networks?,
K. Xu, W. Hu, J. Leskovec, and S. Jegelka, “How powerful are graph neural networks?,” inInternational Conference on Learning Representations, 2019
2019
-
[44]
arXiv preprint arXiv:2406.02953 , year=
Z. Hou, H. Li, Y . Cen, J. Tang, and Y . Dong, “Graphalign: Pretraining one graph neural network on multiple graphs via feature alignment,” arXiv preprint arXiv:2406.02953, 2024
-
[45]
Deeprobust: A pytorch library for adversarial attacks and defenses,
Y . Li, W. Jin, H. Xu, and J. Tang, “Deeprobust: A pytorch library for adversarial attacks and defenses,”arXiv preprint arXiv:2005.06149, 2020
-
[46]
Adversarial attacks on neural networks for graph data,
D. Z ¨ugner, A. Akbarnejad, and S. G ¨unnemann, “Adversarial attacks on neural networks for graph data,” inACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2847–2856, 2018
2018
-
[47]
Graph structure learning for robust graph neural networks,
W. Jin, Y . Ma, X. Liu, X. Tang, S. Wang, and J. Tang, “Graph structure learning for robust graph neural networks,” inACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 66–74, 2020
2020
-
[48]
Predict then propagate: Graph neural networks meet personalized pagerank,
J. Klicpera, A. Bojchevski, and S. G ¨unnemann, “Predict then propagate: Graph neural networks meet personalized pagerank,” inInternational Conference on Learning Representations, 2019
2019
-
[49]
Simple and deep graph convolutional networks,
M. Chen, Z. Wei, Z. Huang, B. Ding, and Y . Li, “Simple and deep graph convolutional networks,” inInternational conference on machine learning, pp. 1725–1735, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.