Recognition: unknown
Representation-Aligned Multi-Scale Personalization for Federated Learning
Pith reviewed 2026-05-10 15:40 UTC · model grok-4.3
The pith
FRAMP generates client-specific models from compact descriptors for personalized federated learning with representation alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
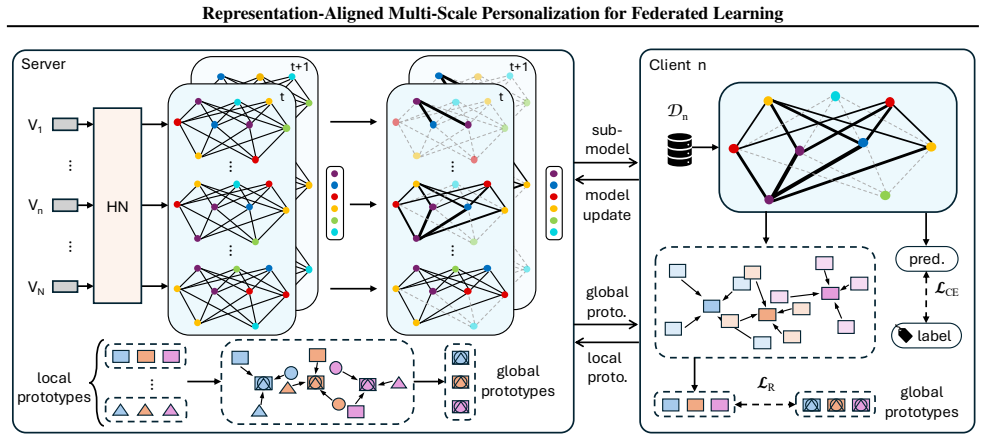
FRAMP is a unified framework that generates client-specific models from compact client descriptors. Each client trains a tailored lightweight submodel and aligns its learned representation with others to maintain global semantic consistency, enabling fine-grained adaptation to data characteristics and computational budgets without relying on a fixed global backbone.
What carries the argument
Compact client descriptors that generate tailored submodels combined with representation alignment to maintain global semantic consistency while allowing local adaptation.
If this is right
- Each client obtains a model structure and features optimized for its data distribution and hardware constraints.
- Structural diversity across clients is possible without losing the ability to share semantic knowledge.
- Performance improves on heterogeneous settings in both vision and graph benchmarks.
- The approach supports multi-scale personalization beyond pruning from one fixed backbone.
Where Pith is reading between the lines
- Descriptor-driven model generation could reduce communication costs if only compact descriptors and aligned representations are exchanged instead of full models.
- The alignment technique may extend to other distributed systems with high device heterogeneity such as mobile sensor networks.
- Testing the framework on sequential or multimodal data could check whether the consistency benefit generalizes beyond the reported vision and graph cases.
Load-bearing premise
Representation alignment across clients preserves global semantic consistency without undermining the benefits of client-specific structural and representational adaptation.
What would settle it
An experiment showing that aligned client-specific models achieve lower accuracy than a non-personalized global model on a shared test set when client data distributions differ substantially would falsify the central claim.
Figures




read the original abstract
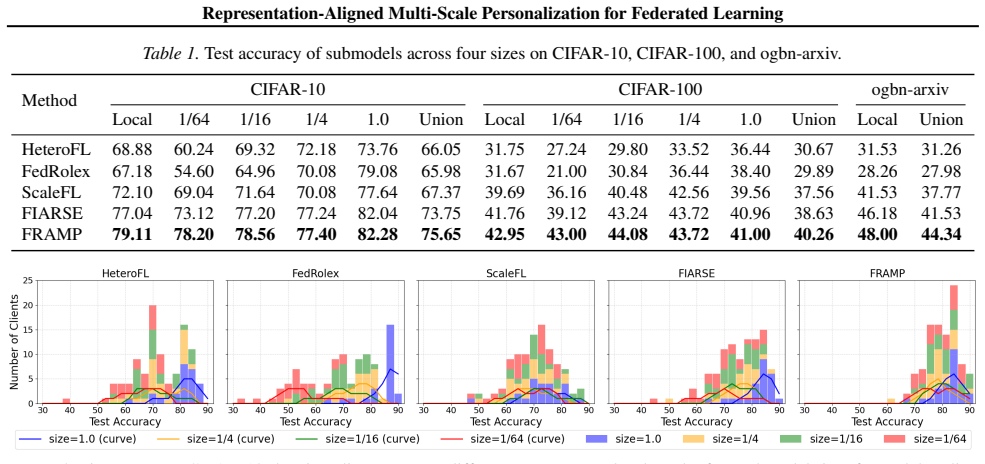
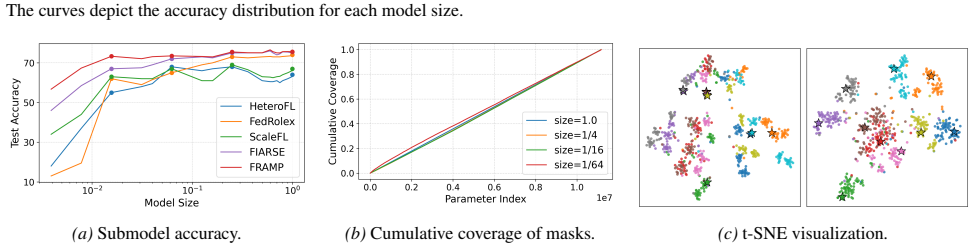
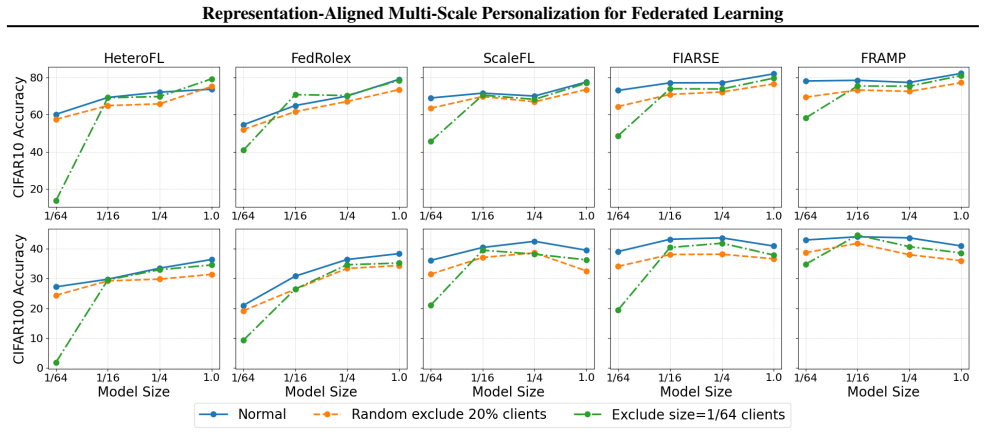
In federated learning (FL), accommodating clients with diverse resource constraints remains a significant challenge. A widely adopted approach is to use a shared full-size model, from which each client extracts a submodel aligned with its computational budget. However, regardless of the specific scoring strategy, these methods rely on the same global backbone, limiting both structural diversity and representational adaptation across clients. This paper presents FRAMP, a unified framework for personalized and resource-adaptive federated learning. Instead of relying on a fixed global model, FRAMP generates client-specific models from compact client descriptors, enabling fine-grained adaptation to both data characteristics and computational budgets. Each client trains a tailored lightweight submodel and aligns its learned representation with others to maintain global semantic consistency. Extensive experiments on vision and graph benchmarks demonstrate that FRAMP enhances generalization and adaptivity across a wide range of client settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FRAMP, a unified framework for personalized and resource-adaptive federated learning. Rather than extracting submodels from a shared global backbone, FRAMP generates client-specific lightweight models from compact client descriptors to adapt to heterogeneous data distributions and computational budgets. Each client independently trains its tailored submodel, after which learned representations are aligned across clients to enforce global semantic consistency. The manuscript claims that extensive experiments on vision and graph benchmarks demonstrate improved generalization and adaptivity across diverse client settings.
Significance. If the central claims hold under rigorous evaluation, FRAMP would constitute a substantive contribution to federated learning by enabling both structural diversity and fine-grained representational personalization without a fixed global model. The compact-descriptor approach and explicit alignment step could address key limitations in current heterogeneous FL methods, with potential impact on edge-device deployments where compute and data vary widely.
major comments (2)
- [Abstract] Abstract: the assertion that 'extensive experiments on vision and graph benchmarks demonstrate that FRAMP enhances generalization and adaptivity' is unsupported by any quantitative results, tables, baselines, or error bars in the provided text. This absence makes it impossible to evaluate whether the data actually substantiate the claims of fine-grained adaptation and preserved semantic consistency.
- The representation-alignment step (described in the abstract as aligning 'learned representation with others to maintain global semantic consistency') is load-bearing for the central claim yet lacks any specification of the alignment objective, loss weighting, whether it operates on shared layers or full representations, or how it accommodates architecturally heterogeneous submodels. Without these details, it is unclear whether the mechanism avoids the risk of either insufficient transfer or over-constraint that could erode personalization gains on non-IID vision and graph data.
minor comments (1)
- [Abstract] The abstract would benefit from naming the specific vision and graph benchmarks and at least one quantitative headline result to allow readers to gauge the magnitude of improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have prepared revisions to the manuscript that directly incorporate the suggestions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'extensive experiments on vision and graph benchmarks demonstrate that FRAMP enhances generalization and adaptivity' is unsupported by any quantitative results, tables, baselines, or error bars in the provided text. This absence makes it impossible to evaluate whether the data actually substantiate the claims of fine-grained adaptation and preserved semantic consistency.
Authors: We agree that the abstract, being a concise overview, does not embed the specific numerical results, tables or error bars that appear in the full experimental section. The manuscript body (Section 4) contains the complete evaluation on vision and graph benchmarks, including baseline comparisons and standard deviations across repeated runs. To make the abstract claim more self-contained, we have revised it to include a short, high-level summary of the observed gains in generalization and adaptivity. This change keeps the abstract within normal length limits while directly addressing the concern. revision: yes
-
Referee: [—] The representation-alignment step (described in the abstract as aligning 'learned representation with others to maintain global semantic consistency') is load-bearing for the central claim yet lacks any specification of the alignment objective, loss weighting, whether it operates on shared layers or full representations, or how it accommodates architecturally heterogeneous submodels. Without these details, it is unclear whether the mechanism avoids the risk of either insufficient transfer or over-constraint that could erode personalization gains on non-IID vision and graph data.
Authors: We appreciate the referee pointing out the need for greater technical precision on this component. In the revised manuscript we have expanded Section 3.3 with an explicit description of the alignment procedure, including the objective function, the scalar weighting applied to the alignment term, the fact that alignment is performed on the full client representations (rather than shared layers), and the design choices that allow it to operate across heterogeneous submodel architectures. We have also added a short ablation study confirming that the chosen weighting preserves personalization benefits on non-IID data while still enforcing semantic consistency. revision: yes
Circularity Check
No circularity; framework is a descriptive proposal without derivations or self-referential predictions
full rationale
The paper describes FRAMP as a method that generates client-specific models from compact descriptors and aligns representations for consistency, supported by experiments on vision and graph benchmarks. No equations, derivations, fitted parameters, or load-bearing self-citations appear in the abstract or description that could reduce any claim to its own inputs by construction. The approach is presented as a methodological framework rather than a mathematical derivation chain, rendering it self-contained with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Federated Learning with Personalization Layers
Arivazhagan, M. G., Aggarwal, V ., Singh, A. K., and Choud- hary, S. Federated learning with personalization layers. arXiv preprint arXiv:1912.00818,
work page internal anchor Pith review arXiv 1912
-
[2]
Brock, A., Lim, T., Ritchie, J. M., and Weston, N. SMASH: one-shot model architecture search through hypernet- works.arXiv preprint arXiv:1708.05344,
- [3]
-
[4]
arXiv preprint arXiv:2204.12703 , year=
Cho, Y . J., Manoel, A., Joshi, G., Sim, R., and Dimitriadis, D. Heterogeneous ensemble knowledge transfer for train- ing large models in federated learning.arXiv preprint arXiv:2204.12703,
-
[5]
Dai, R., Shen, L., He, F., Tian, X., and Tao, D. Dispfl: Towards communication-efficient personalized federated learning via decentralized sparse training.arXiv preprint arXiv:2206.00187,
-
[6]
Heterofl: Computation and communication efficient federated learning for heterogeneous clients,
Diao, E., Ding, J., and Tarokh, V . Heterofl: Computation and communication efficient federated learning for het- erogeneous clients.arXiv preprint arXiv:2010.01264,
-
[7]
The lottery ticket hypothesis: Finding sparse, trainable neural networks,
Frankle, J. and Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635,
-
[8]
Isik, B., Pase, F., Gunduz, D., Weissman, T., and Zorzi, M. Sparse random networks for communication-efficient 9 Representation-Aligned Multi-Scale Personalization for Federated Learning federated learning.arXiv preprint arXiv:2209.15328,
-
[9]
Improving federated learning personalization via model agnostic meta learning
Jiang, Y ., Koneˇcn`y, J., Rush, K., and Kannan, S. Improving federated learning personalization via model agnostic meta learning.arXiv preprint arXiv:1909.12488,
-
[10]
Kang, H., Cha, S., Shin, J., Lee, J., and Kang, J. Nefl: Nested model scaling for federated learning with system heterogeneous clients.arXiv preprint arXiv:2308.07761,
-
[11]
Subgraph federated learning for local generalization.arXiv preprint arXiv:2503.03995,
Kim, S., Lee, Y ., Oh, Y ., Lee, N., Yun, S., Lee, J., Kim, S., Yang, C., and Park, C. Subgraph federated learning for local generalization.arXiv preprint arXiv:2503.03995,
-
[12]
Federated Learning: Strategies for Improving Communication Efficiency
Koneˇcn`y, J. Federated learning: Strategies for im- proving communication efficiency.arXiv preprint arXiv:1610.05492,
work page internal anchor Pith review arXiv
-
[13]
Li, A., Sun, J., Wang, B., Duan, L., Li, S., Chen, Y ., and Li, H. Lotteryfl: Personalized and communication-efficient federated learning with lottery ticket hypothesis on non- iid datasets.arXiv preprint arXiv:2008.03371, 2020a. Li, A., Sun, J., Zeng, X., Zhang, M., Li, H., and Chen, Y . Fedmask: Joint computation and communication- efficient personalize...
-
[14]
K., Zaheer, M., Sanjabi, M., Talwalkar, A., and Smith, V
Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., and Smith, V . Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020b. Liang, W., Zhao, Y ., She, R., Li, Y ., and Tay, W. P. Personal- ized subgraph federated learning with sheaf collaboration. arXiv preprint arXiv:2508.13642,
-
[15]
Ma, X., Zhang, J., Guo, S., and Xu, W
doi: 10.1109/TAI.2024.3490557. Ma, X., Zhang, J., Guo, S., and Xu, W. Layer-wised model aggregation for personalized federated learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10092–10101,
-
[16]
Learn- ing the pareto front with hypernetworks.arXiv preprint arXiv:2010.04104,
Navon, A., Shamsian, A., Chechik, G., and Fetaya, E. Learn- ing the pareto front with hypernetworks.arXiv preprint arXiv:2010.04104,
-
[17]
Feddse: Distribution-aware sub- model extraction for federated learning over resource- constrained devices
Wang, H., Jia, Y ., Zhang, M., Hu, Q., Ren, H., Sun, P., Wen, Y ., and Zhang, T. Feddse: Distribution-aware sub- model extraction for federated learning over resource- constrained devices. InProceedings of the ACM Web Conference 2024, pp. 2902–2913,
2024
-
[18]
Flexifed: Personalized federated learning for edge clients with heterogeneous model architectures
Wang, K., He, Q., Chen, F., Chen, C., Huang, F., Jin, H., and Yang, Y . Flexifed: Personalized federated learning for edge clients with heterogeneous model architectures. InProceedings of the ACM Web Conference 2023, pp. 2979–2990,
2023
-
[19]
Yi, K., Gazagnadou, N., Richtárik, P., and Lyu, L. Fedp3: Federated personalized and privacy-friendly network pruning under model heterogeneity.arXiv preprint arXiv:2404.09816,
-
[20]
Graph hypernetworks for neural architecture search
Zhang, C., Ren, M., and Urtasun, R. Graph hypernet- works for neural architecture search.arXiv preprint arXiv:1810.05749,
-
[21]
Related Works A.1
11 Representation-Aligned Multi-Scale Personalization for Federated Learning A. Related Works A.1. Model Sparsification in FL Model sparsification, or pruning, has gained attention following the introduction of the lottery ticket hypothesis (Frankle & Carbin, 2018), which suggests that within large models lie smaller subnetworks that can be trained to per...
2018
-
[22]
Recently, hardware innovations have further advanced the feasibility of training and deploying sparse models (Kurtz et al., 2020; Hoefler et al., 2021; Iofinova et al., 2022)
leveraged sparsity to reduce computational overhead. Recently, hardware innovations have further advanced the feasibility of training and deploying sparse models (Kurtz et al., 2020; Hoefler et al., 2021; Iofinova et al., 2022). In FL, two main approaches are used to obtain sparse submodels: dense-to-sparse (Li et al., 2021; Isik et al., 2022; Deng et al....
2020
-
[23]
The target weights can be dynamically adapted based on the HNs’ input vectors
are neural networks designed to generate weights for another network. The target weights can be dynamically adapted based on the HNs’ input vectors. (Klocek et al., 2019; Navon et al., 2020). SMASH (Brock et al.,
2019
-
[24]
Direct comparison with HN-based FL baselines is not applicable, as they are designed for uniform models and do not support varying model sizes
extended GHNs to support heterogeneous local models through graph-based reasoning. Direct comparison with HN-based FL baselines is not applicable, as they are designed for uniform models and do not support varying model sizes. B. Algorithm Algorithm 1 details the full procedure of FRAMP. Algorithm 1FRAMP Input:Communication roundsR, number of clientsN, lo...
1997
-
[25]
13 Representation-Aligned Multi-Scale Personalization for Federated Learning Table 7.Test accuracy on CIFAR-100 with stronger data heterogeneity (α= 0.05). Method CIFAR-100 Local 1/64 1/16 1/4 1.0 Union HeteroFL 22.24 17.28 21.96 22.16 27.56 21.48 FedRolex 12.63 3.08 5.84 16.12 25.48 11.67 ScaleFL 29.14 28.68 32.04 28.64 27.20 27.71 FIARSE 29.29 25.68 31....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.