Recognition: unknown
Learning How Much to Think: Difficulty-Aware Dynamic MoEs for Graph Node Classification
Pith reviewed 2026-05-10 15:55 UTC · model grok-4.3
The pith
D2MoE routes more experts to hard graph nodes using predictive entropy, raising accuracy while cutting memory and time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
D2MoE shifts Graph MoE design from static expert selection to difficulty-driven top-p routing. Predictive entropy computed from the model's outputs acts as a real-time proxy for node discriminative difficulty. The router then concentrates expert resources on high-entropy nodes while sparsifying allocation for low-entropy nodes, producing continuous fine-grained scaling of the expert budget per node.
What carries the argument
Difficulty-driven top-p routing that uses predictive entropy to decide the number of experts assigned to each node.
If this is right
- Consistent state-of-the-art accuracy on 13 node-classification benchmarks.
- Accuracy gains of up to 7.92 percent on heterophilous graphs.
- Memory reduction of up to 73.07 percent on large-scale graphs.
- Training-time reduction of up to 46.53 percent compared with prior Graph MoE models.
Where Pith is reading between the lines
- The same entropy signal could be reused at inference time to decide how many experts to activate per node without retraining.
- The method may transfer to other graph tasks such as link prediction or graph classification if difficulty can be defined analogously.
- Replacing entropy with other uncertainty measures such as margin or ensemble variance might yield further gains on specific graph topologies.
Load-bearing premise
Predictive entropy from the current model outputs is a reliable real-time indicator of true node classification difficulty and the top-p decisions based on it do not introduce instability or overhead that cancels the efficiency gains.
What would settle it
Running the same 13 benchmarks with entropy-based top-p routing replaced by either fixed expert count or random routing and observing no accuracy loss or efficiency loss on heterophilous or large-scale graphs.
Figures








read the original abstract
Mixture-of-Experts (MoE) architectures offer a scalable path for Graph Neural Networks (GNNs) in node classification tasks but typically rely on static and rigid routing strategies that enforce a uniform expert budget or coarse-grained expert toggles on all nodes. This limitation overlooks the varying discriminative difficulty of nodes and leads to under-fitting for hard nodes and redundant computation for easy ones. To resolve this issue, we propose D2MoE, a novel framework that shifts the focus from static expert selection to node-wise expert resource allocation. By using predictive entropy as a real-time proxy for difficulty, D2MoE employs a difficulty-driven top-p routing mechanism to adaptively concentrate expert resources on hard nodes while reducing overhead for easy ones, achieving continuous and fine-grained expert budget scaling for node classification. Experiments on 13 benchmarks demonstrate that D2MoE achieves consistent state-of-the-art performance, surpassing leading baselines by up to 7.92% in accuracy on heterophilous graphs. Notably, on large-scale graphs, it reduces memory consumption by up to 73.07% and training time by 46.53% compared to the best-performing Graph MoE, thereby validating its superior efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces D2MoE, a dynamic Mixture-of-Experts architecture for graph node classification. It replaces static expert routing with a difficulty-driven top-p mechanism that uses predictive entropy (computed from the model's softmax outputs) as a real-time proxy for per-node discriminative difficulty, adaptively allocating more experts to hard nodes and fewer to easy ones. Experiments on 13 benchmarks report consistent SOTA accuracy (gains up to 7.92% on heterophilous graphs) together with large efficiency improvements on big graphs (up to 73.07% memory and 46.53% training-time reduction versus the strongest static Graph MoE baseline).
Significance. If the efficiency numbers survive a full accounting of auxiliary costs, the work would offer a concrete advance in scalable GNN training by moving from uniform or coarse expert budgets to fine-grained, node-wise compute allocation. The breadth of the 13-benchmark evaluation, including heterophilous and large-scale graphs, strengthens the empirical contribution. The core idea of entropy-guided dynamic routing is a natural extension of existing MoE literature to graphs and could influence follow-up work on adaptive computation.
major comments (3)
- [§3.2] §3.2 (Difficulty-Driven Top-p Routing) and the associated entropy formula: predictive entropy is obtained from the current model's node outputs, which are themselves produced by the experts chosen by the routing decision. The text does not describe whether this requires a preliminary full-expert forward pass, an auxiliary lightweight predictor, a straight-through estimator, or a prior routing step. Without an explicit procedure, the claimed 46.53% training-time reduction cannot be verified and the circular-dependency concern raised in the stress-test note remains unaddressed.
- [§4] §4 (Experiments), large-scale graph tables: the reported memory (73.07%) and time (46.53%) savings are presented as net gains, yet no breakdown or ablation quantifies the overhead of entropy computation, top-p selection, and any auxiliary forward passes. This measurement is load-bearing for the central efficiency claim.
- [§4.1] §4.1–4.2 (Benchmark results): accuracy improvements up to 7.92% are stated as SOTA, but the manuscript supplies no information on baseline re-implementations, hyper-parameter search budgets, number of random seeds, statistical significance tests, or safeguards against data leakage. These omissions weaken support for the performance claims.
minor comments (3)
- [Abstract] Abstract: the phrase 'continuous and fine-grained expert budget scaling' would benefit from an explicit statement of the discrete expert-count range actually used per node.
- [§3] Notation: the symbol for the top-p threshold is introduced without a clear definition of its range or how it is chosen; a short paragraph or table entry would improve clarity.
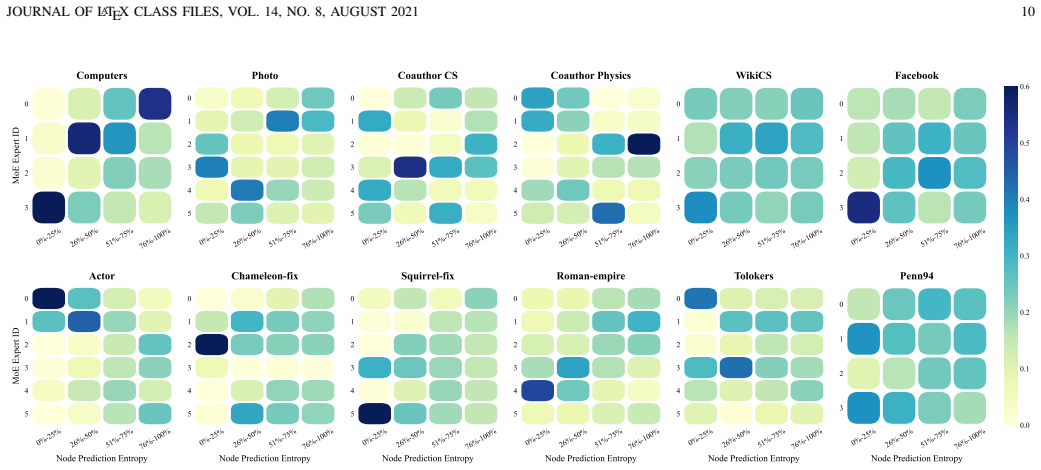
- [Figures] Figures: captions for routing-visualization figures should explicitly label the color or size encoding used for easy versus hard nodes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us improve the clarity and rigor of the manuscript. We address each major comment point by point below, providing clarifications and indicating revisions made to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Difficulty-Driven Top-p Routing) and the associated entropy formula: predictive entropy is obtained from the current model's node outputs, which are themselves produced by the experts chosen by the routing decision. The text does not describe whether this requires a preliminary full-expert forward pass, an auxiliary lightweight predictor, a straight-through estimator, or a prior routing step. Without an explicit procedure, the claimed 46.53% training-time reduction cannot be verified and the circular-dependency concern raised in the stress-test note remains unaddressed.
Authors: We thank the referee for highlighting this ambiguity. The predictive entropy is computed from a lightweight preliminary forward pass through the router (gating network) and a single shared expert, prior to the top-p selection and full expert dispatch. This step uses only the initial node features and does not invoke the full set of experts, thereby avoiding circularity. We have revised §3.2 to include a detailed algorithmic description (Algorithm 1) and an accompanying figure that explicitly outlines the sequence: router prediction → entropy estimation → top-p routing → expert execution. The reported training-time reductions already incorporate this overhead, which our measurements show is minimal relative to the savings from reduced expert activation on easy nodes. revision: yes
-
Referee: [§4] §4 (Experiments), large-scale graph tables: the reported memory (73.07%) and time (46.53%) savings are presented as net gains, yet no breakdown or ablation quantifies the overhead of entropy computation, top-p selection, and any auxiliary forward passes. This measurement is load-bearing for the central efficiency claim.
Authors: We agree that an explicit accounting of auxiliary costs is essential to substantiate the efficiency claims. In the revised manuscript, we have added a new ablation subsection (§4.3) that measures and reports the isolated overhead of entropy computation and top-p selection. This overhead constitutes less than 4% of total training time on the large-scale graphs, confirming that the net savings (73.07% memory and 46.53% time) remain valid after full accounting. We also include per-component timing tables for the two largest graphs to allow direct verification. revision: yes
-
Referee: [§4.1] §4.1–4.2 (Benchmark results): accuracy improvements up to 7.92% are stated as SOTA, but the manuscript supplies no information on baseline re-implementations, hyper-parameter search budgets, number of random seeds, statistical significance tests, or safeguards against data leakage. These omissions weaken support for the performance claims.
Authors: We acknowledge the importance of full experimental transparency. The revised §4.1 and §4.2 now specify: (i) baselines were re-implemented from official repositories or faithfully reproduced following the original papers, with hyper-parameters tuned via grid search on validation sets using the same search space as the original works; (ii) all results are averaged over 10 independent random seeds with reported standard deviations; (iii) statistical significance is assessed via paired t-tests (p < 0.05 for all reported gains); and (iv) experiments adhere to the standard fixed train/validation/test splits provided in each benchmark, with no data leakage. These additions strengthen the empirical support for the SOTA claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces D2MoE as a design choice that uses predictive entropy from model outputs as a proxy to drive top-p routing for adaptive expert allocation per node. Efficiency gains and accuracy improvements are presented as outcomes of experiments on 13 benchmarks rather than as first-principles derivations or predictions that reduce by construction to fitted inputs or self-referential definitions. No equations or load-bearing steps in the abstract reduce the claimed results to tautological renamings, self-citations, or fitted parameters masquerading as independent predictions. The method is self-contained against external benchmarks, with the routing mechanism serving as an empirical heuristic whose validity is tested directly rather than assumed via circular logic.
Axiom & Free-Parameter Ledger
free parameters (1)
- top-p threshold
invented entities (1)
-
difficulty-driven top-p routing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Beyond homophily in graph neural networks: current limitations and effective designs,
J. Zhu, Y . Yan, L. Zhao, M. Heimann, L. Akoglu, and D. Koutra, “Beyond homophily in graph neural networks: current limitations and effective designs,” inAdvances in Neural Information Processing Systems, ser. NIPS ’20, Red Hook, NY , USA, 2020
2020
-
[2]
Beyond low-frequency information in graph convolutional networks,
D. Bo, X. Wang, C. Shi, and H. Shen, “Beyond low-frequency information in graph convolutional networks,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 5, 2021, pp. 3950–3957
2021
-
[3]
Revisiting heterophily for graph neural networks,
S. Luan, C. Hua, Q. Lu, J. Zhu, M. Zhao, S. Zhang, X.-W. Chang, and D. Precup, “Revisiting heterophily for graph neural networks,”Advances in neural information processing systems, vol. 35, pp. 1362–1375, 2022
2022
-
[4]
Nagphormer: A tokenized graph transformer for node classification in large graphs,
J. Chen, K. Gao, G. Li, and K. He, “Nagphormer: A tokenized graph transformer for node classification in large graphs,” inProceedings of the International Conference on Learning Representations, 2023
2023
-
[5]
Hierarchical graph transformer with adaptive node sampling,
Z. Zhang, Q. Liu, Q. Hu, and C.-K. Lee, “Hierarchical graph transformer with adaptive node sampling,”Advances in Neural Information Processing Systems, vol. 35, pp. 21 171–21 183, 2022
2022
-
[6]
Difformer: Scalable (graph) transformers induced by energy constrained diffusion,
Q. Wu, C. Yang, W. Zhao, Y . He, D. Wipf, and J. Yan, “Difformer: Scalable (graph) transformers induced by energy constrained diffusion,” inInternational Conference on Learning Representations, 2023
2023
-
[7]
Exphormer: sparse transformers for graphs,
H. Shirzad, A. Velingker, B. Venkatachalam, D. J. Sutherland, and A. K. Sinop, “Exphormer: sparse transformers for graphs,” inICML, 2023
2023
-
[8]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inInternational Conference on Learning Representations, 2017
2017
-
[9]
Graph mixture of experts: Learning on large-scale graphs with explicit diversity modeling,
H. Wang, Z. Jiang, Y . You, Y . Han, G. Liu, J. Srinivasa, R. Kompella, Z. Wanget al., “Graph mixture of experts: Learning on large-scale graphs with explicit diversity modeling,”Advances in Neural Information Processing Systems, vol. 36, pp. 50 825–50 837, 2023
2023
-
[10]
Mixture of weak and strong experts on graphs,
H. Zeng, H. Lyu, D. Hu, Y . Xia, and J. Luo, “Mixture of weak and strong experts on graphs,” inThe Twelfth International Conference on Learning Representations, 2024, pp. 1–41
2024
-
[11]
Harder task needs more experts: Dynamic routing in moe models,
Q. Huang, Z. An, N. Zhuang, M. Tao, C. Zhang, Y . Jin, K. Xu, L. Chen, S. Huang, and Y . Feng, “Harder task needs more experts: Dynamic routing in moe models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024, pp. 12 883–12 895
2024
-
[12]
Da-moe: addressing depth-sensitivity in graph-level analysis through mixture of experts,
Z. Yao, M. Chen, C. Liu, X. Meng, Y . Zhan, J. Wu, S. Pan, H. Xu, and W. Hu, “Da-moe: addressing depth-sensitivity in graph-level analysis through mixture of experts,”Neural Networks, p. 108064, 2025
2025
-
[13]
Node-wise filtering in graph neural networks: A mixture of experts approach,
H. Han, J. Li, W. Huang, X. Tang, H. Lu, C. Luo, H. Liu, and J. Tang, “Node-wise filtering in graph neural networks: A mixture of experts approach,”arXiv preprint arXiv:2406.03464, 2024
-
[14]
Mixture of experts meets decou- pled message passing: Towards general and adaptive node classification,
X. Chen, J. Zhou, S. Yu, and Q. Xuan, “Mixture of experts meets decou- pled message passing: Towards general and adaptive node classification,” inCompanion Proceedings of the ACM on Web Conference 2025, 2025, pp. 907–910
2025
-
[15]
Mixture of scope experts at test: Generalizing deeper graph neural networks with shallow variants,
G. Deng, H. Zhou, R. Kannan, and V . Prasanna, “Mixture of scope experts at test: Generalizing deeper graph neural networks with shallow variants,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025, pp. 1–44
2025
-
[16]
Image-based recommendations on styles and substitutes,
J. McAuley, C. Targett, Q. Shi, and A. Van Den Hengel, “Image-based recommendations on styles and substitutes,” inProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval, 2015, pp. 43–52
2015
-
[17]
Pitfalls of Graph Neural Network Evaluation
O. Shchur, M. Mumme, A. Bojchevski, and S. G ¨unnemann, “Pitfalls of graph neural network evaluation,”arXiv preprint arXiv:1811.05868, 2018
work page Pith review arXiv 2018
-
[18]
Multi-scale attributed node embedding,
B. Rozemberczki, C. Allen, and R. Sarkar, “Multi-scale attributed node embedding,”J. Complex Netw., vol. 9, no. 2, p. cnab014, 2021
2021
-
[19]
Open graph benchmark: Datasets for machine learning on graphs,
W. Hu, M. Fey, M. Zitnik, Y . Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec, “Open graph benchmark: Datasets for machine learning on graphs,”Advances in neural information processing systems, vol. 33, pp. 22 118–22 133, 2020
2020
-
[20]
Social influence analysis in large- scale networks,
J. Tang, J. Sun, C. Wang, and Z. Yang, “Social influence analysis in large- scale networks,” inProceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’09. New York, NY , USA: Association for Computing Machinery, 2009, p. 807–816
2009
-
[21]
A critical look at evaluation of gnns under heterophily: Are we really making progress?
O. Platonov, D. Kuznedelev, M. Diskin, A. Babenko, and L. Prokhorenkova, “A critical look at evaluation of gnns under heterophily: Are we really making progress?” inInternational Conference on Learning Representations, 2023
2023
-
[22]
Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods,
D. Lim, F. Hohne, X. Li, S. L. Huang, V . Gupta, O. Bhalerao, and S. N. Lim, “Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods,” inAdvances in Neural Information Processing Systems, vol. 34, 2021, pp. 20 887–20 902
2021
-
[23]
Semi-supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” inInternational Conference on Learning Representations, 2017. [Online]. Available: https://openreview.net/forum? id=SJU4ayYgl
2017
-
[24]
Inductive representation learning on large graphs,
W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” inAdvances in Neural Information Processing Systems, vol. 30, 2017, pp. 1–11
2017
-
[25]
Graph attention networks,
P. Veli ˇckovi´c, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y . Bengio, “Graph attention networks,” inInternational Conference on Learning Representations, 2018, pp. 1–12
2018
-
[26]
Adaptive universal generalized pagerank graph neural network,
E. Chien, J. Peng, P. Li, and O. Milenkovic, “Adaptive universal generalized pagerank graph neural network,” inInternational Conference on Learning Representations, 2021, pp. 1–24
2021
-
[27]
Simplifying approach to node classification in graph neural networks,
S. K. Maurya, X. Liu, and T. Murata, “Simplifying approach to node classification in graph neural networks,”Journal of Computational Science, vol. 62, p. 101695, 2022
2022
-
[28]
Simplifying and empowering transformers for large-graph representations,
Q. Wu, W. Zhao, C. Yang, H. Zhang, F. Nie, H. Jiang, Y . Bian, and J. Yan, “Simplifying and empowering transformers for large-graph representations,”Advances in Neural Information Processing Systems, vol. 36, 2024. Jiajun Zhoureceived the Ph.D degree in control theory and engineering from Zhejiang University of Technology, Hangzhou, China, in 2023. He is ...
2024
-
[29]
From 2012 to 2014, he was a Post-Doctoral Fellow with the Department of Computer Science, University of California at Davis, CA, USA. He is a senior member of the IEEE and is currently a Professor with the Institute of Cyberspace Security, College of Information Engineering, Zhejiang University of Technology, Hangzhou, China. His current research interest...
2012
-
[30]
half half
We analyze the generalization error of a sparse Mixture- of-Experts (MoE) system under realistic conditions: weighted expert aggregation and non-zero inter-expert correlation. A-1 Generalization Error Decomposition Consider a node v with a ground-truth label y. Let Xi be the prediction of the i-th expert for node v, where experts are indexed i= 1,2, . . ....
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.