Recognition: unknown
VVGT: Visual Volume-Grounded Transformer
Pith reviewed 2026-05-10 14:38 UTC · model grok-4.3
The pith
A feed-forward dual-transformer maps volumetric data directly to 3D Gaussian primitives for ray aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
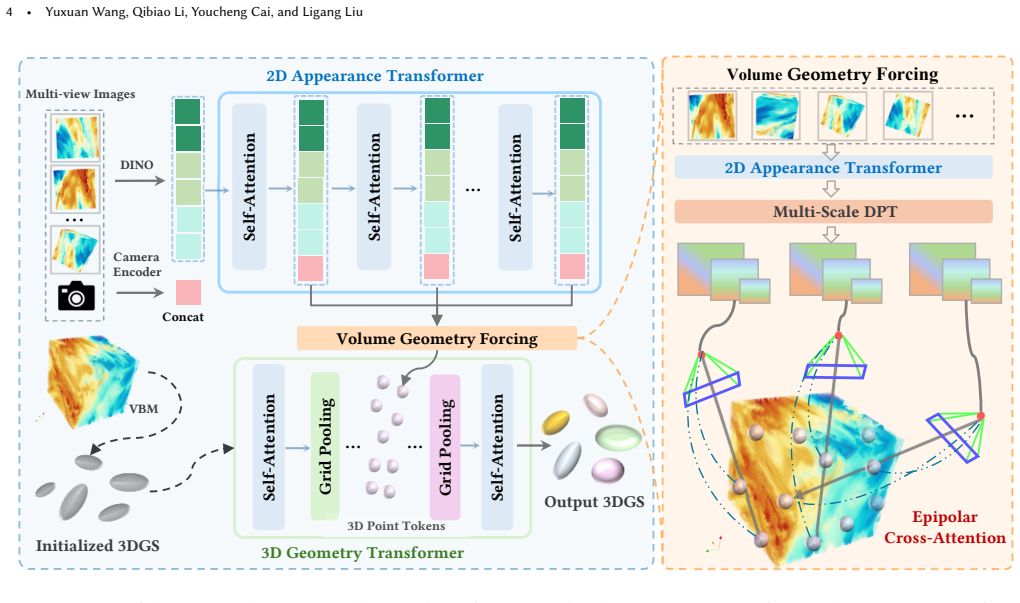
VVGT is a feed-forward framework that directly maps volumetric data to a 3D Gaussian Splatting representation through a dual-transformer network and Volume Geometry Forcing, an epipolar cross-attention mechanism that integrates multi-view observations into distributed 3D Gaussian primitives, enabling accurate volumetric ray aggregation without surface assumptions or per-scene optimization.
What carries the argument
Dual-transformer network with Volume Geometry Forcing, an epipolar cross-attention mechanism that integrates multi-view observations into distributed 3D Gaussian primitives for volumetric rendering.
If this is right
- Volumetric data can be converted to renderable form orders of magnitude faster than optimization-based approaches.
- Geometric consistency improves across views because the network explicitly enforces epipolar relations during primitive placement.
- Zero-shot application becomes possible on unseen volumetric datasets without any additional training or tuning.
- Interactive rates become feasible for high-resolution volumes that previously required offline processing.
- Scalability increases because the method avoids both dense grids and per-scene fitting.
Where Pith is reading between the lines
- The feed-forward design may allow extension to time-varying volumes by adding a temporal attention dimension without changing the core architecture.
- Hybrid pipelines could route certain regions through traditional direct volume rendering while using VVGT for the rest, improving efficiency in complex scenes.
- Deployment on edge devices becomes more plausible once the model is quantized, given the absence of iterative optimization.
Load-bearing premise
The dual-transformer network with Volume Geometry Forcing epipolar cross-attention can accurately integrate multi-view observations into distributed 3D Gaussian primitives for volumetric ray aggregation without surface assumptions or per-scene optimization.
What would settle it
A side-by-side comparison on a standard volumetric dataset in which VVGT produces visibly lower fidelity or geometrically inconsistent renderings compared with per-scene optimized 3D Gaussian splatting would falsify the claim.
Figures



read the original abstract
Volumetric visualization has long been dominated by Direct Volume Rendering (DVR), which operates on dense voxel grids and suffers from limited scalability as resolution and interactivity demands increase. Recent advances in 3D Gaussian Splatting (3DGS) offer a representation-centric alternative; however, existing volumetric extensions still depend on costly per-scene optimization, limiting scalability and interactivity. We present VVGT (Visual Volume-Grounded Transformer), a feed-forward, representation-first framework that directly maps volumetric data to a 3D Gaussian Splatting representation, advancing a new paradigm for volumetric visualization beyond DVR. Unlike prior feed-forward 3DGS methods designed for surface-centric reconstruction, VVGT explicitly accounts for volumetric rendering, where each pixel aggregates contributions along a ray. VVGT employs a dual-transformer network and introduces Volume Geometry Forcing, an epipolar cross-attention mechanism that integrates multi-view observations into distributed 3D Gaussian primitives without surface assumptions. This design eliminates per-scene optimization while enabling accurate volumetric representations. Extensive experiments show that VVGT achieves high-quality visualization with orders-of-magnitude faster conversion, improved geometric consistency, and strong zero-shot generalization across diverse datasets, enabling truly interactive and scalable volumetric visualization. The code will be publicly released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VVGT, a feed-forward dual-transformer architecture that maps multi-view volumetric observations directly to a set of distributed 3D Gaussian primitives via a novel Volume Geometry Forcing module based on epipolar cross-attention; the method claims to produce representations suitable for volumetric ray aggregation without surface assumptions or per-scene optimization, yielding orders-of-magnitude faster conversion, improved geometric consistency, and strong zero-shot generalization across datasets.
Significance. If the central technical claims are substantiated, the work would represent a meaningful advance in representation-centric volumetric visualization by adapting 3D Gaussian Splatting to continuous density fields, potentially enabling interactive, scalable rendering pipelines that avoid both the memory costs of dense DVR and the optimization overhead of existing 3DGS extensions.
major comments (3)
- [§3.2] §3.2 (Volume Geometry Forcing): the description of epipolar cross-attention does not specify how feature correspondences along epipolar lines are converted into constraints on the integrated transmittance and emission along full rays; because 3DGS primitives are discrete and typically surface-oriented, it is unclear whether the learned Gaussians satisfy the continuous volume rendering integral rather than only local 2D-3D consistency.
- [§4] §4 (Experiments): the abstract and available text assert 'high-quality visualization,' 'orders-of-magnitude faster conversion,' and 'strong zero-shot generalization' yet supply no quantitative metrics, error bars, ablation tables, or dataset specifications; without these, the load-bearing claims of superiority over DVR and prior feed-forward 3DGS methods cannot be evaluated.
- [§3.1] §3.1 (Dual-transformer network): the architecture is stated to eliminate per-scene optimization, but no derivation or empirical verification is given showing that the output Gaussians produce ray integrals matching the volume rendering equation on datasets with complex internal structures (e.g., participating media or semi-transparent volumes).
minor comments (2)
- [Abstract] The abstract refers to 'extensive experiments' without naming the datasets or baselines; this should be expanded with concrete references to tables or figures in the main text.
- [§3.2] Notation for the epipolar cross-attention operation is introduced without an accompanying equation; adding a compact mathematical definition would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each of the major comments in detail below and have made revisions to the manuscript to incorporate the feedback where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Volume Geometry Forcing): the description of epipolar cross-attention does not specify how feature correspondences along epipolar lines are converted into constraints on the integrated transmittance and emission along full rays; because 3DGS primitives are discrete and typically surface-oriented, it is unclear whether the learned Gaussians satisfy the continuous volume rendering integral rather than only local 2D-3D consistency.
Authors: We agree that the original description in §3.2 focuses on the epipolar cross-attention mechanism but does not fully elaborate on the translation to ray integrals. In the revised manuscript, we have added a detailed explanation and mathematical formulation showing how the aggregated features from epipolar lines are used to set the parameters of the 3D Gaussians to ensure their splatting approximates the continuous volume rendering integral. This includes a discussion of the discretization and its validity for volumetric data. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract and available text assert 'high-quality visualization,' 'orders-of-magnitude faster conversion,' and 'strong zero-shot generalization' yet supply no quantitative metrics, error bars, ablation tables, or dataset specifications; without these, the load-bearing claims of superiority over DVR and prior feed-forward 3DGS methods cannot be evaluated.
Authors: We acknowledge the need for quantitative support. The revised manuscript now includes a comprehensive experimental section with quantitative metrics such as PSNR and SSIM for rendering quality, timing comparisons demonstrating the speed advantage, ablation studies on the key components, error bars from multiple runs, and full specifications of the datasets used. These additions allow direct evaluation of the claims. revision: yes
-
Referee: [§3.1] §3.1 (Dual-transformer network): the architecture is stated to eliminate per-scene optimization, but no derivation or empirical verification is given showing that the output Gaussians produce ray integrals matching the volume rendering equation on datasets with complex internal structures (e.g., participating media or semi-transparent volumes).
Authors: Thank you for this observation. The manuscript claims the elimination of per-scene optimization through the feed-forward design, but we agree that explicit verification for complex volumes is beneficial. We have added both a derivation in §3.1 linking the Gaussian outputs to the volume rendering equation and empirical results on datasets featuring participating media and semi-transparent structures to confirm the match in ray integrals. revision: yes
Circularity Check
No significant circularity; method is architectural proposal without self-referential derivations.
full rationale
The paper describes a feed-forward dual-transformer architecture with Volume Geometry Forcing via epipolar cross-attention to map volumetric inputs to 3D Gaussian primitives for ray aggregation. No equations, derivations, or first-principles predictions are present in the abstract or described claims. Performance assertions (speed, consistency, zero-shot generalization) are empirical outcomes of the proposed network rather than quantities fitted or defined in terms of themselves. No self-citations, ansatzes smuggled via prior work, or uniqueness theorems are invoked in the provided text to justify core components. The central claim reduces to the design and training of the network, which is externally falsifiable via experiments on held-out data and does not collapse to input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Volumetric rendering requires aggregating contributions along rays from multi-view observations without surface assumptions.
invented entities (1)
-
Volume Geometry Forcing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nli4volvis: Natural language interaction for volume visualization via llm multi-agents and editable 3d gaussian splatting.arXiv preprint arXiv:2507.126211, 2 (2025). Tushar M. Athawale, Zhe Wang, David Pugmire, Kenneth Moreland, Qian Gong, Scott Klasky, Chris R. Johnson, and Paul Rosen
-
[2]
IEEE Transactions on Visualization and Computer Graphics(2024)
Uncertainty Visualization of Critical Points of 2D Scalar Fields for Parametric and Nonparametric Probabilistic Models. IEEE Transactions on Visualization and Computer Graphics(2024). Johanna Beyer, Markus Hadwiger, and Hanspeter Pfister
2024
-
[3]
Imma Boada, Isabel Navazo, and Roberto Scopigno
State-of-the-Art in GPU-Based Large-Scale Volume Visualization.Computer Graphics Forum34, 8 (2015), 13–37. Imma Boada, Isabel Navazo, and Roberto Scopigno
2015
-
[4]
Multiresolution Volume Visualization with a Texture-Based Octree.The Visual Computer17, 3 (2001), 185–
2001
-
[5]
William T
Ex- plorable INR: An Implicit Neural Representation for Ensemble Simulation Enabling Efficient Spatial and Parameter Exploration.IEEE Transactions on Visualization and Computer Graphics31, 6 (2025), 3758–3770. William T. Correa, James T. Klosowski, and Claudio T. Silva
2025
-
[6]
Thomas Fogal, Alexander Schiewe, and Jens Krüger
Volume Encoding Gaussians: Transfer Function-Agnostic 3D Gaussians for Volume Rendering.arXiv preprint arXiv:2504.13339(2025). Thomas Fogal, Alexander Schiewe, and Jens Krüger
-
[7]
COVRA: A Compression-Domain Output-Sensitive Volume Rendering Architecture Based on a Sparse Representation of Voxel Blocks.Computer Graphics Forum31, 3 (2012), 1125–1134. S. Guthe, M. Wand, J. Gonser, and W. Strasser
2012
-
[8]
Jakob Jakob, Markus Gross, and Tobias Günther
Interac- tive Volume Exploration of Petascale Microscopy Data Streams Using a Visualization- Driven Virtual Memory Approach.IEEE Transactions on Visualization and Computer Graphics18, 12 (2012), 2285–2294. Jakob Jakob, Markus Gross, and Tobias Günther
2012
-
[9]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al
A Fluid Flow Data Set for Machine Learning and its Application to Neural Flow Map Interpolation.IEEE Transactions on Visualization and Computer Graphics27, 2 (2021), 1279–1289. Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al
2021
-
[10]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis
AnySplat: Feed-Forward 3D Gaussian Splatting from Unconstrained Views.ACM Transactions on Graphics44, 6 (2025), 1–16. Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis
2025
-
[11]
Pavol Klacansky
3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Transactions on Graphics42, 4 (2023). Pavol Klacansky
2023
-
[12]
Guan Li, Yang Liu, Guihua Shan, Shiyu Cheng, Weiqun Cao, Junpeng Wang, and Ko-Chih Wang
Direct numerical simulation of turbulent channel flow up to𝑅𝑒 𝜏 ≈5200.Journal of Fluid Mechanics774 (2015), 395–415. Guan Li, Yang Liu, Guihua Shan, Shiyu Cheng, Weiqun Cao, Junpeng Wang, and Ko-Chih Wang
2015
-
[13]
Qibiao Li, Yuxuan Wang, Youcheng Cai, Huangsheng Du, and Ligang Liu
ParamsDrag: Interactive Parameter Space Exploration via Image-Space Dragging.IEEE Transactions on Visualization and Computer Graphics (2024). Qibiao Li, Yuxuan Wang, Youcheng Cai, Huangsheng Du, and Ligang Liu
2024
-
[14]
Variable Basis Mapping for Real-Time Volumetric Visualization.arXiv preprint arXiv:2601.09417(2026). Yi Li, Eric Perlman, Minping Wan, Yunke Yang, Charles Meneveau, Randal Burns, Shiyi Chen, Alexander Szalay, and Gregory Eyink
-
[15]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo
A public turbulence database cluster and applications to study Lagrangian evolution of velocity increments in turbulence.Journal of Turbulence9 (2008), 1–29. Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo
2008
-
[16]
8•Yuxuan Wang, Qibiao Li, Youcheng Cai, and Ligang Liu Ben Mildenhall, Pratul P
Optical models for direct volume rendering.IEEE Transactions on Visualization and Computer Graphics1, 2 (1995), 99–108. 8•Yuxuan Wang, Qibiao Li, Youcheng Cai, and Ligang Liu Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ra- mamoorthi, and Ren Ng
1995
-
[17]
ACM65, 1 (2021), 99–106
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.Commun. ACM65, 1 (2021), 99–106. Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller
2021
-
[18]
Simon Niedermayr, Christoph Neuhauser, Kaloian Petkov, Klaus Engel, and Rüdiger Westermann
Instant neural graphics primitives with a multiresolution hash encoding.ACM Transactions on Graphics41, 4 (2022), 1–15. Simon Niedermayr, Christoph Neuhauser, Kaloian Petkov, Klaus Engel, and Rüdiger Westermann
2022
-
[19]
DINOv2: Learning Robust Visual Features without Supervision
DINOv2: Learning Robust Visual Features without Supervision.arXiv preprint arXiv:2304.07193(2023). Haosong Peng, Hao Li, Yalun Dai, Yushi Lan, Yihang Luo, Tianyu Qi, Zhengshen Zhang, Yufeng Zhan, Junfei Zhang, Wenchao Xu, and Ziwei Liu
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
OmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer.arXiv preprint arXiv:2511.10560(2025). René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun
-
[21]
Naveen Venkat, Mayank Agarwal, Maneesh Singh, and Shubham Tulsiani
iVR-GS: Inverse volume rendering for explorable visualization via editable 3D Gaussian splatting.IEEE Transactions on Visualization and Computer Graphics(2025). Naveen Venkat, Mayank Agarwal, Maneesh Singh, and Shubham Tulsiani
2025
-
[22]
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny
Geometry-biased transformers for novel view synthesis.arXiv preprint arXiv:2301.04650(2023). Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny
-
[23]
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing13, 4 (2004), 600–612. Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao
2004
-
[24]
Skylar W
Point transformer v2: Grouped vector attention and partition-based pooling.Advances in Neural Information Processing Systems35 (2022), 33330–33342. Skylar W. Wurster, Tianyu Xiong, Han-Wei Shen, Hanqi Guo, and Tom Peterka
2022
-
[25]
Botao Ye, Boqi Chen, Haofei Xu, Daniel Barath, and Marc Pollefeys
Adaptively Placed Multi-Grid Scene Representation Networks for Large-Scale Data Visualization.IEEE Transactions on Visualization and Computer Graphics30, 1 (2024), 965–974. Botao Ye, Boqi Chen, Haofei Xu, Daniel Barath, and Marc Pollefeys
2024
-
[26]
YoNoSplat: You Only Need One Model for Feedforward 3D Gaussian Splatting.arXiv preprint arXiv:2511.07321(2025). Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng
- [27]
-
[28]
Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa
Dissipation, enstrophy and pressure statistics in turbulence simulations at high Reynolds numbers.Journal of Fluid Mechanics700 (2012), 5–15. Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa
2012
-
[29]
VVGT: Visual Volume-Grounded Transformer•9 GTIVRGS3DGSAnySplatVVGTVVGT_100VVGT_200 Fig
EWA Splatting.IEEE Transactions on Visualization and Computer Graphics8, 3 (2002), 223–238. VVGT: Visual Volume-Grounded Transformer•9 GTIVRGS3DGSAnySplatVVGTVVGT_100VVGT_200 Fig
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.