Recognition: unknown
Labeled TrustSet Guided: Batch Active Learning with Reinforcement Learning
Pith reviewed 2026-05-10 16:21 UTC · model grok-4.3
The pith
TrustSet from labeled data guides an RL policy to select better annotation batches from the unlabeled pool.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TrustSet selects the most informative labeled examples by balancing classes and removing redundancies to directly improve model performance, unlike distribution-focused methods such as CoreSet. An RL sampling policy then approximates this same selection process on the unlabeled data, producing the BRAL-T framework that delivers state-of-the-art accuracy on ten image classification benchmarks and two active fine-tuning tasks.
What carries the argument
TrustSet, a selection procedure on the labeled set that prunes redundant examples while enforcing class balance to optimize downstream model performance, extended by an RL policy that learns to replicate those selections on unlabeled candidates.
If this is right
- The method reduces required labels while raising accuracy by leveraging labeled-data feedback that prior uncertainty or diversity metrics ignore.
- Class-balanced TrustSet selection directly mitigates long-tail problems during batch construction.
- Performance gains appear consistently across ten standard image classification datasets and two fine-tuning scenarios.
- The RL policy allows the labeled-set insight to scale to large unlabeled pools without enumerating all possible TrustSets.
Where Pith is reading between the lines
- The same TrustSet-plus-RL pattern could be tested on non-image tasks such as text classification if the balance and redundancy criteria are redefined for sequences.
- One could measure how much the RL policy degrades when the underlying model architecture changes, revealing whether the learned selection rule is architecture-specific.
- Running TrustSet selection inside the training loop after each batch, rather than only at the start, might further tighten the feedback between labeled data and new selections.
Load-bearing premise
The reinforcement learning policy can reliably approximate the choices that would have been made by TrustSet if the unlabeled examples had already been labeled.
What would settle it
A controlled test in which a simpler non-RL batch selector, given the same labeled TrustSet as reference, matches or exceeds BRAL-T accuracy on the reported benchmarks would show the RL approximation is unnecessary.
Figures






read the original abstract
Batch active learning (BAL) is a crucial technique for reducing labeling costs and improving data efficiency in training large-scale deep learning models. Traditional BAL methods often rely on metrics like Mahalanobis Distance to balance uncertainty and diversity when selecting data for annotation. However, these methods predominantly focus on the distribution of unlabeled data and fail to leverage feedback from labeled data or the model's performance. To address these limitations, we introduce TrustSet, a novel approach that selects the most informative data from the labeled dataset, ensuring a balanced class distribution to mitigate the long-tail problem. Unlike CoreSet, which focuses on maintaining the overall data distribution, TrustSet optimizes the model's performance by pruning redundant data and using label information to refine the selection process. To extend the benefits of TrustSet to the unlabeled pool, we propose a reinforcement learning (RL)-based sampling policy that approximates the selection of high-quality TrustSet candidates from the unlabeled data. Combining TrustSet and RL, we introduce the Batch Reinforcement Active Learning with TrustSet (BRAL-T) framework. BRAL-T achieves state-of-the-art results across 10 image classification benchmarks and 2 active fine-tuning tasks, demonstrating its effectiveness and efficiency in various domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TrustSet, a selection method applied to the labeled dataset that prunes redundant examples while enforcing class balance to mitigate long-tail effects and improve model performance. It then trains a reinforcement learning policy on these TrustSet examples to approximate the same selection logic over the unlabeled pool, yielding the BRAL-T framework for batch active learning. The central claim is that BRAL-T attains state-of-the-art results on 10 image-classification benchmarks and 2 active fine-tuning tasks.
Significance. If the RL policy demonstrably transfers the TrustSet selection criterion rather than learning generic diversity or uncertainty signals, the work would offer a concrete mechanism for feeding labeled-data feedback into batch selection. This could be a useful addition to the BAL literature, particularly for long-tailed or fine-tuning regimes, provided the experimental attribution is made rigorous.
major comments (2)
- [§4 and §5] §4 (Method) and §5 (Experiments): the manuscript asserts that the RL policy approximates TrustSet selection from the unlabeled pool, yet provides neither an overlap metric against an oracle TrustSet nor an ablation that replaces the learned policy with random sampling from the same feature space. Without such a check, it remains possible that reported gains derive from the underlying uncertainty/diversity baseline rather than the claimed TrustSet guidance.
- [§5] §5 (Experiments): the SOTA claim across 10 benchmarks and 2 fine-tuning tasks is presented without enumeration of the exact baselines, labeling budgets, performance metrics, number of runs, or statistical tests. This absence prevents verification that the improvements are both substantial and attributable to the novel component.
minor comments (1)
- [Abstract / §1] The abstract and introduction would benefit from a concise formal definition of the TrustSet objective (e.g., the precise pruning and balancing criterion) before describing the RL transfer.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects for rigorously validating the transfer of the TrustSet criterion via the RL policy and for ensuring the SOTA claims are fully verifiable. We address each major comment below and will revise the manuscript to incorporate the suggested checks and details.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Method) and §5 (Experiments): the manuscript asserts that the RL policy approximates TrustSet selection from the unlabeled pool, yet provides neither an overlap metric against an oracle TrustSet nor an ablation that replaces the learned policy with random sampling from the same feature space. Without such a check, it remains possible that reported gains derive from the underlying uncertainty/diversity baseline rather than the claimed TrustSet guidance.
Authors: We agree that direct evidence of the RL policy transferring the TrustSet selection logic (rather than learning generic uncertainty or diversity signals) would strengthen the central claim. In the revised manuscript, we will add an overlap metric that compares the batch selections produced by the trained RL policy against an oracle TrustSet selector run on the unlabeled pool (using held-out ground-truth labels solely for this diagnostic). We will also include an ablation that replaces the learned RL policy with uniform random sampling from the same feature embedding space while keeping all other components fixed. These additions will allow readers to quantify how much of the performance gain is attributable to the TrustSet-guided approximation. revision: yes
-
Referee: [§5] §5 (Experiments): the SOTA claim across 10 benchmarks and 2 fine-tuning tasks is presented without enumeration of the exact baselines, labeling budgets, performance metrics, number of runs, or statistical tests. This absence prevents verification that the improvements are both substantial and attributable to the novel component.
Authors: We acknowledge that the current presentation of the experimental results does not provide sufficient detail for independent verification of the SOTA claims. In the revised manuscript, we will expand §5 with a dedicated table (or subsection) that explicitly lists: (i) all baseline methods compared, (ii) the precise labeling budgets used on each dataset, (iii) the evaluation metrics (top-1 accuracy and any others), (iv) the number of independent runs with different random seeds, and (v) the statistical tests performed (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) to establish significance of the improvements over the strongest baselines. This will make the attribution to BRAL-T transparent. revision: yes
Circularity Check
No circularity: TrustSet and RL policy form an independent heuristic transfer
full rationale
The derivation defines TrustSet explicitly on the labeled set as a pruning-and-balancing procedure, then trains a separate RL policy whose reward is derived from that labeled procedure to guide selection on the unlabeled pool. This is a standard supervised-to-unsupervised transfer via RL rather than a self-referential loop; no equation equates the final batch selection or reported performance directly back to the same fitted quantities by construction. The SOTA claims rest on external benchmark comparisons, not on internal re-use of the same data statistics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1906.03671 , year=
Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds.arXiv preprint arXiv:1906.03671,
-
[2]
Reinforced active learning for image segmentation.arXiv preprint arXiv:2002.06583,
Arantxa Casanova, Pedro O Pinheiro, Negar Rostamzadeh, and Christopher J Pal. Reinforced active learning for image segmentation.arXiv preprint arXiv:2002.06583,
-
[3]
Meng Fang, Yuan Li, and Trevor Cohn. Learning how to active learn: A deep reinforcement learning approach.arXiv preprint arXiv:1708.02383,
-
[4]
Identity mappings in deep residual net- works
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual net- works. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Nether- lands, October 11–14, 2016, Proceedings, Part IV 14, pp. 630–645. Springer,
2016
-
[5]
Identifying medical diag- noses and treatable diseases by image-based deep learning.cell, 172(5):1122–1131,
10 Published as a conference paper at IJCNN 2026 Daniel S Kermany, Michael Goldbaum, Wenjia Cai, Carolina CS Valentim, Huiying Liang, Sally L Baxter, Alex McKeown, Ge Yang, Xiaokang Wu, Fangbing Yan, et al. Identifying medical diag- noses and treatable diseases by image-based deep learning.cell, 172(5):1122–1131,
2026
-
[6]
Active learning by acquiring contrastive examples.arXiv preprint arXiv:2109.03764,
Katerina Margatina, Giorgos Vernikos, Lo ¨ıc Barrault, and Nikolaos Aletras. Active learning by acquiring contrastive examples.arXiv preprint arXiv:2109.03764,
-
[7]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wier- stra, and Martin Riedmiller. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602,
work page internal anchor Pith review arXiv
-
[8]
Compute-efficient active learning.arXiv preprint arXiv:2401.07639,
G´abor N ´emeth and Tam ´as Matuszka. Compute-efficient active learning.arXiv preprint arXiv:2401.07639,
-
[9]
11 Published as a conference paper at IJCNN 2026 Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generaliza- tion.arXiv preprint arXiv:1911.08731,
work page internal anchor Pith review arXiv 2026
-
[10]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489,
-
[11]
Deep active learning for named entity recognition,
Yanyao Shen, Hyokun Yun, Zachary C Lipton, Yakov Kronrod, and Animashree Anandkumar. Deep active learning for named entity recognition.arXiv preprint arXiv:1707.05928,
-
[12]
Akshay Smit, Damir Vrabac, Yujie He, Andrew Y Ng, Andrew L Beam, and Pranav Rajpurkar. Medselect: Selective labeling for medical image classification combining meta-learning with deep reinforcement learning.arXiv preprint arXiv:2103.14339,
-
[13]
Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geoffrey J Gordon. An empirical study of example forgetting during deep neural network learning.arXiv preprint arXiv:1812.05159,
-
[14]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmark- ing machine learning algorithms.arXiv preprint arXiv:1708.07747,
work page internal anchor Pith review arXiv
-
[15]
Michelle Yuan, Hsuan-Tien Lin, and Jordan Boyd-Graber. Cold-start active learning through self- supervised language modeling.arXiv preprint arXiv:2010.09535,
-
[16]
Xueying Zhan, Qing Li, and Antoni B Chan. Multiple-criteria based active learning with fixed-size determinantal point processes.arXiv preprint arXiv:2107.01622, 2021a. 12 Published as a conference paper at IJCNN 2026 Xueying Zhan, Huan Liu, Qing Li, and Antoni B Chan. A comparative survey: Benchmarking for pool-based active learning. InIJCAI, pp. 4679–468...
-
[17]
Jifan Zhang, Shuai Shao, Saurabh Verma, and Robert Nowak. Algorithm selection for deep active learning with imbalanced datasets.arXiv preprint arXiv:2302.07317,
-
[18]
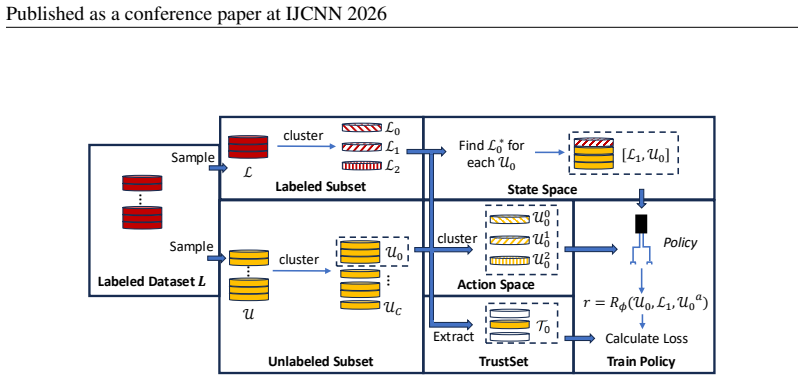
As illustrated in Section 4.2, we clustered labeled set into{L m}M m=1 and unlabeled set into{U c}C c=1 to formulate state space of RL
17:end for 18: 19:// Sample New DataSet 20:SampleS i :=π(R ϕi , Li, Ui); 21:UpdateL i+1 :=L i ∪S i andU i+1 :=U i \S i; 22:end for 13 Published as a conference paper at IJCNN 2026 In algorithm 2, we show the pseudocode of data extraction for RL (line 15 of algorithm 1). As illustrated in Section 4.2, we clustered labeled set into{L m}M m=1 and unlabeled s...
2026
-
[19]
and Chest X-Ray Pneumonia classification (Pneumonia-MNIST) (Kermany et al., 2018). Additionally, we assessed our framework on an object recognition dataset with correlated backgrounds (Waterbird) (Sagawa et al., 2019; Koh et al., 2021), which contains waterbird and landbird classes manually mixed with water and land backgrounds. To further evaluate BRAL-T...
2018
-
[20]
Model Details.Following the setting of Zhan et al
The detail setting for each benchmark are shown in Table 5, including initial data size of labeled dataset|L 0|and unlabeled dataset|U 0|, final budgetQof labeled dataset, batch sizebfor data subset selection in each active learning iteration, training epoch#efor target model training, and category numberCfor dataset. Model Details.Following the setting o...
2022
-
[21]
After 20 epochs, only the gradient from the classification loss is back-propagated through the target model
For LossPrediction, the target model is trained with both classification loss and loss prediction loss for the first 20 epochs. After 20 epochs, only the gradient from the classification loss is back-propagated through the target model. Model and Hyperparameters Setting:We constructed the reward functionR ϕ using a fully con- nected network comprising 2 h...
2020
-
[22]
on Cifar10, Cifar10-imb and FashionMNIST datasets by pairwise penalty matrix following Ash et al. (2021). For each benchmark, we collect accuracy results achieved by all baselines. For pairwise comparison between the method forith row (r i) and the method injth column (cj), we add a score to elementeij wheneverr i achieves better accuracy result in one bu...
2021
-
[23]
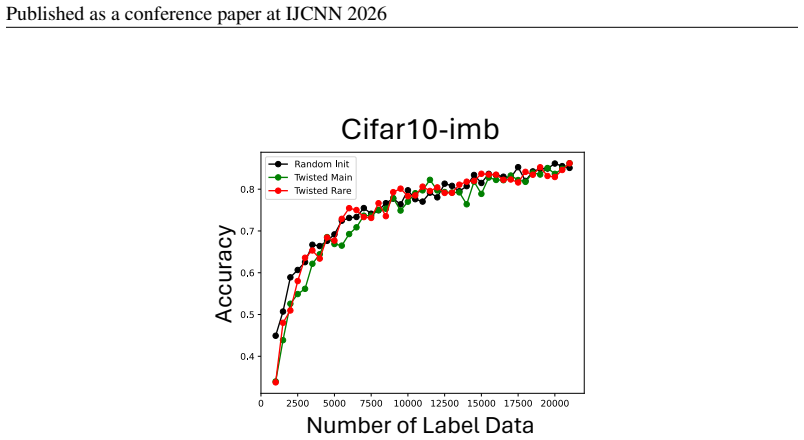
Cifar10Cifar10-imbalance Number of Label DataNumber of Label Data Accuracy Accuracy Cifar10Cifar10-imbalance Number of Label DataNumber of Label Data Accuracy Accuracy Figure 8: Comparison between BRAL-T with RL policy and Ground Truth Labels. 18 Published as a conference paper at IJCNN 2026 # Actions AUBC F-Acc 5 0.762 0.851 10 0.763 0.853 50 0.755 0.851...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.