Recognition: unknown
Analyzing the Effect of Noise in LLM Fine-tuning
Pith reviewed 2026-05-10 15:14 UTC · model grok-4.3
The pith
Label noise causes the largest performance drop in LLM fine-tuning while grammatical and typographical noise sometimes improve results slightly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Corrupting labels consistently causes the largest performance degradation, whereas grammatical noise and typographical noise can occasionally yield mild regularization benefits. Noise effects are localized primarily to task-specific layers, while attention structures remain comparatively stable.
What carries the argument
Controlled synthetic perturbations of label, grammatical, and typographical noise combined with layer-wise representation tracking and attention pattern comparison.
If this is right
- Label noise produces more severe accuracy loss than grammatical or typographical noise on the same tasks.
- Grammatical and typographical noise can improve performance in some fine-tuning settings.
- Representation changes from noise appear mainly in the final task-specific layers.
- Attention head patterns show little alteration under any of the tested noise conditions.
Where Pith is reading between the lines
- Data cleaning pipelines should allocate more effort to label verification than to grammar or spelling fixes.
- Mild grammatical or typographical variation could be added deliberately as a low-cost regularization step.
- Monitoring tools could focus on the last few layers rather than the entire model to detect harmful noise.
Load-bearing premise
The artificially added noise types match the distribution and impact of real annotation errors, preprocessing issues, and automated data collection noise.
What would settle it
Apply the same three noise types to naturally occurring noisy datasets collected from crowdsourcing platforms or web scrapes, then measure whether label noise still produces the largest accuracy drop.
Figures






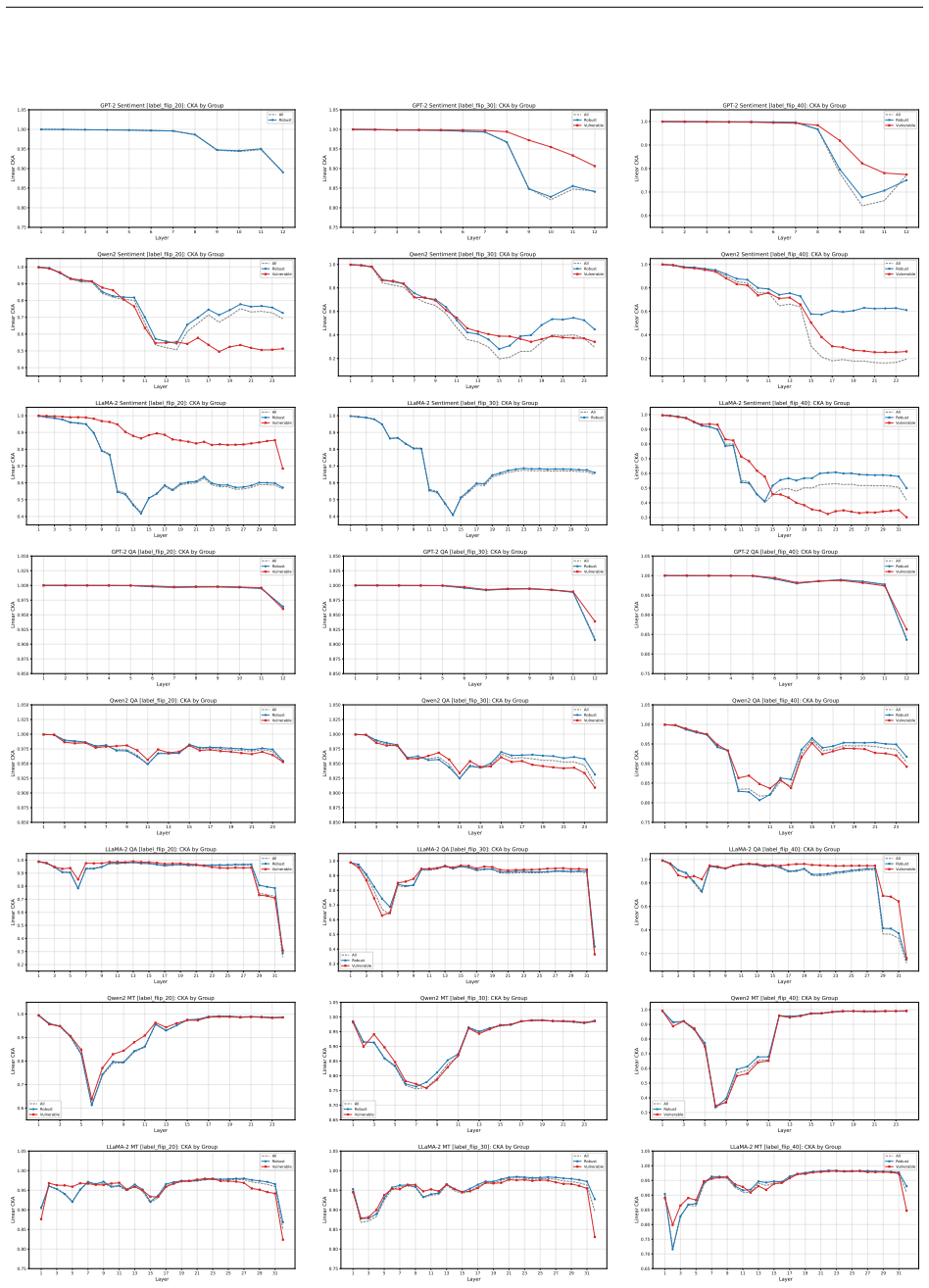
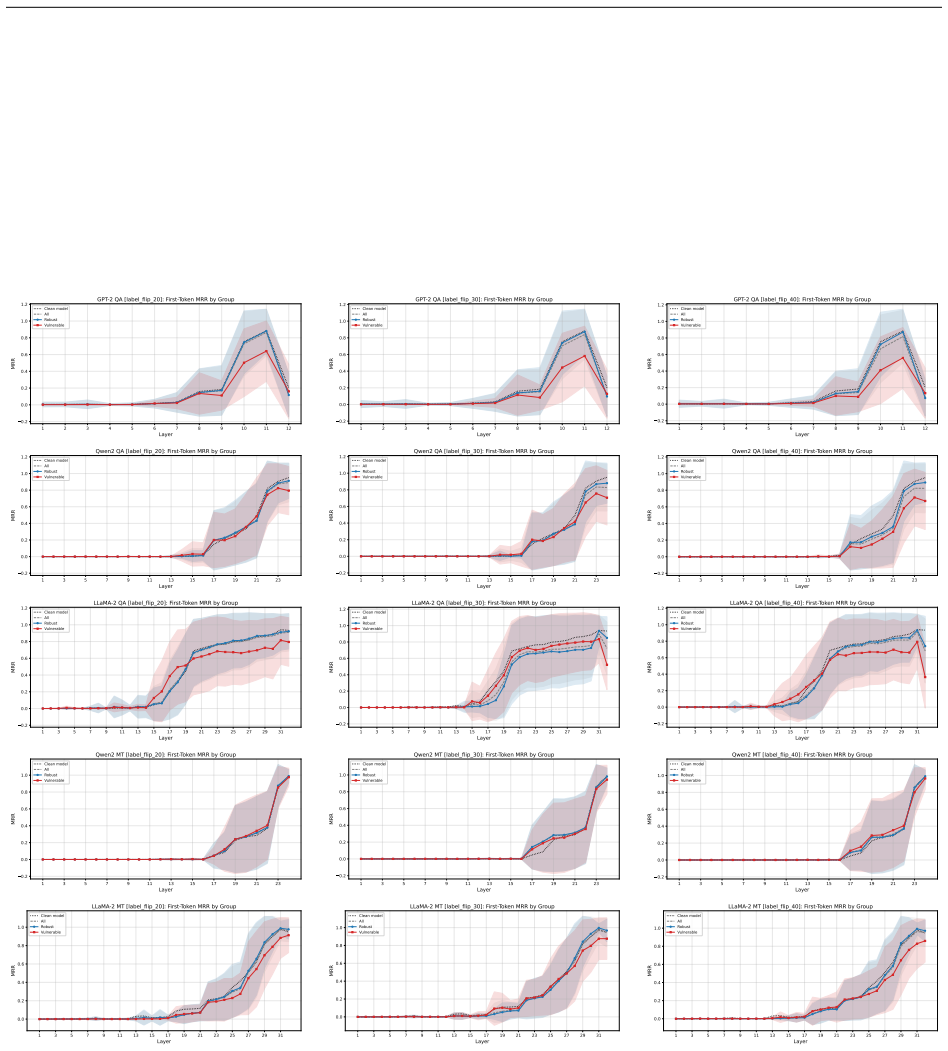


read the original abstract
Fine-tuning is the dominant paradigm for adapting pretrained large language models (LLMs) to downstream NLP tasks. In practice, fine-tuning datasets may contain various forms of noise arising from annotation errors, preprocessing artifacts, or automated data collection. While prior work has focused on designing robust learning algorithms to mitigate performance degradation under noisy conditions, comparatively little is known about how different types of noise affect the internal learning dynamics of LLMs during fine-tuning. In this work, we systematically study the impact of noise on model behavior across three pretrained model families (GPT-2, Qwen2 and Llama-2) and three diverse NLP tasks. We introduce controlled perturbations corresponding to three common real-world noise types: label noise, grammatical noise, and typographical noise. Beyond task-level performance, we analyze layer-wise representation changes and attention patterns to understand how noise propagates through the network. Our results show that corrupting labels (i.e. label noise) consistently causes the largest performance degradation, whereas grammatical noise and typographical noise can occasionally yield mild regularization benefits. We further find that noise effects are localized primarily to task-specific layers, while attention structures remain comparatively stable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically studies the effects of three synthetic noise types—label noise, grammatical noise, and typographical noise—introduced during fine-tuning of three LLM families (GPT-2, Qwen2, Llama-2) on three NLP tasks. It reports that label noise produces the largest task-performance degradation, that grammatical and typographical noise occasionally yield mild regularization, and that these effects concentrate in task-specific layers while attention patterns remain comparatively stable.
Significance. If the quantitative trends and layer-wise analyses hold, the work supplies useful empirical evidence on how different noise sources propagate through LLM fine-tuning, which could inform data-cleaning priorities and layer-targeted regularization strategies. The multi-model, multi-task design and internal-representation analysis are positive features.
major comments (3)
- [Abstract and §4 (Results)] Abstract and §4 (Results): the reported trends (largest degradation from label noise, occasional regularization from other noises) are stated without numerical performance deltas, standard deviations, number of random seeds, or statistical tests. This absence prevents assessment of effect sizes and reliability.
- [§3 (Methodology)] §3 (Methodology): the generation procedures for the three controlled perturbations are described at a high level only; no concrete parameters (label-flip fraction, edit-distance distribution for typographical noise, or grammatical-edit rules) are supplied, undermining reproducibility and the claim that the perturbations correspond to real-world noise.
- [§5 (Layer-wise and Attention Analysis)] §5 (Layer-wise and Attention Analysis): the localization of noise effects to “task-specific layers” is asserted without an explicit definition of which layers qualify as task-specific or quantitative metrics (e.g., cosine similarity or probing accuracy) showing the contrast with earlier layers.
minor comments (2)
- [Figures] Figure captions and legends should explicitly state the number of runs averaged and the error metric used.
- [Introduction] A short paragraph contrasting the synthetic perturbations with documented real-world noise statistics (e.g., from annotation-error studies) would strengthen the motivation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive suggestions. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] Abstract and §4 (Results): the reported trends (largest degradation from label noise, occasional regularization from other noises) are stated without numerical performance deltas, standard deviations, number of random seeds, or statistical tests. This absence prevents assessment of effect sizes and reliability.
Authors: We agree that the current presentation would benefit from explicit quantitative support. In the revised manuscript we will augment both the abstract and §4 with concrete performance deltas (e.g., mean accuracy drops), standard deviations computed across the random seeds used in our experiments, and the results of appropriate statistical tests (paired t-tests or Wilcoxon signed-rank tests) to establish the reliability of the observed trends. revision: yes
-
Referee: [§3 (Methodology)] §3 (Methodology): the generation procedures for the three controlled perturbations are described at a high level only; no concrete parameters (label-flip fraction, edit-distance distribution for typographical noise, or grammatical-edit rules) are supplied, undermining reproducibility and the claim that the perturbations correspond to real-world noise.
Authors: We acknowledge that the current description is insufficient for exact reproduction. We will expand §3 with the precise parameters employed: the label-flip fractions applied, the edit-distance distributions and character-level operations used to generate typographical noise, and the specific grammatical-edit rules together with their sources. These details will also be accompanied by a brief justification linking each perturbation to documented real-world noise patterns. revision: yes
-
Referee: [§5 (Layer-wise and Attention Analysis)] §5 (Layer-wise and Attention Analysis): the localization of noise effects to “task-specific layers” is asserted without an explicit definition of which layers qualify as task-specific or quantitative metrics (e.g., cosine similarity or probing accuracy) showing the contrast with earlier layers.
Authors: We will add an explicit operational definition of task-specific layers (the final transformer blocks immediately preceding the task head, identified via layer-wise probing) and will report quantitative supporting metrics. Specifically, we will include cosine-similarity differences between clean and noisy representations across layers as well as probing-classifier accuracies that demonstrate the concentration of noise-induced changes in the later layers relative to earlier ones. revision: yes
Circularity Check
No circularity: purely empirical study with no derivations or fitted predictions
full rationale
The paper performs a controlled empirical investigation: it defines three synthetic noise types (label flips, grammatical edits, typographical changes), applies them to fine-tuning datasets, trains GPT-2/Qwen2/Llama-2 models, and reports task accuracy, layer-wise representation shifts, and attention stability. No equations derive new quantities from prior ones, no parameters are fitted on a subset and then called predictions, and no self-citations supply uniqueness theorems or ansatzes that the central claims rest upon. All reported effects (label noise causing largest degradation, occasional regularization from other noises, localization to task-specific layers) are direct experimental outcomes, not reductions to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diego Alves, Marko Tadi´c, and Georg Rehm. Which domains, tasks and languages are in the focus of NLP research on the languages of Europe? In Federico Gaspari, Joss Moorkens, Itziar Aldabe, Aritz Farwell, Begona Altuna, Stelios Piperidis, Georg Rehm, and German Rigau (eds.),Proceedings of the Second International Workshop Towards Digital Language Equality...
2024
-
[2]
How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.),Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processin...
2019
-
[3]
Association for Computational Linguistics. doi: 10.18653/v1/D19-1006. URLhttps://aclanthology.org/D19-1006/. Benoit Frenay and Michel Verleysen. Classification in the presence of label noise: A survey.IEEE Transactions on Neural Networks and Learning Systems, 25(5):845–869,
-
[4]
doi: 10.1109/TNNLS.2013.2292894. Ji Gao, Jack Lanchantin, Mary Lou Soffa, and Yanjun Qi. Black-box generation of adversarial text sequences to evade deep learning classifiers,
-
[5]
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson
URLhttps://arxiv.org/abs/1801.04354. Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.),Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 12216–12235, Singapore, Decem- ber
-
[6]
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.751. URLhttps: //aclanthology.org/2023.emnlp-main.751/. Aritra Ghosh, Himanshu Kumar, and P. S. Sastry. Robust loss functions under label noise for deep neural networks. Proceedings of the AAAI Conference on Artificial Intelligence, 31(1), Feb
-
[7]
URLhttps://ojs.aaai.org/index.php/AAAI/article/view/10894
doi: 10.1609/aaai.v31i1.10894. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/10894. Bo Han, Quanming Yao, Xingrui Yu, Gang Niu, Miao Xu, Weihua Hu, Ivor Tsang, and Masashi Sugiyama. Co- teaching: Robust training of deep neural networks with extremely noisy labels.Advances in neural information processing systems, 31,
-
[8]
On large language models’ hallucination with regard to known facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, and Jie Zhou. On large language models’ hallucination with regard to known facts. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.),Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language...
2024
-
[9]
doi: 10.18653/v1/2024.naacl-long.60
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.60. URL https://aclanthology.org/2024.naacl-long.60/. Haotian Ju, Dongyue Li, and Hongyang R Zhang. Robust fine-tuning of deep neural networks with hessian- based generalization guarantees. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sab...
-
[10]
11 Vladimir Karpukhin, Omer Levy, Jacob Eisenstein, and Marjan Ghazvininejad
URL https://proceedings.mlr.press/v162/ju22a.html. 11 Vladimir Karpukhin, Omer Levy, Jacob Eisenstein, and Marjan Ghazvininejad. Training on synthetic noise improves robustness to natural noise in machine translation. In Wei Xu, Alan Ritter, Tim Baldwin, and Afshin Rahimi (eds.), Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019), p...
2019
-
[11]
Junnan Li, Richard Socher, and Steven CH Hoi
URLhttps://openreview.net/forum?id=j7buX9nsfis. Junnan Li, Richard Socher, and Steven CH Hoi. Dividemix: Learning with noisy labels as semi-supervised learning. arXiv preprint arXiv:2002.07394,
-
[12]
arXiv preprint arXiv:2412.14922 , year=
URLhttps://arxiv.org/abs/2412.14922. Milad Moradi and Matthias Samwald. Evaluating the robustness of neural language models to input perturbations. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 1558–1570,
-
[13]
Association for Computational Linguistics. doi: 10.18653/v1/W18-6319. URLhttps: //aclanthology.org/W18-6319/. Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! InThe Twelfth International Conference on Learning Representations,
-
[14]
SQuAD: 100,000+ questions for machine com- prehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine com- prehension of text. In Jian Su, Kevin Duh, and Xavier Carreras (eds.),Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2383–2392, Austin, Texas, November
2016
-
[15]
SQuAD : 100,000+ questions for machine comprehension of text
Association for Computational Linguistics. doi: 10.18653/v1/D16-1264. URLhttps://aclanthology.org/D16-1264. 12 Alexander Ratner, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré. Snorkel: rapid training data creation with weak supervision.Proc. VLDB Endow., 11(3):269–282, November
-
[16]
Available: http://dx.doi.org/10.14778/3157794.3157797
doi: 10.14778/3157794.3157797. URLhttps://doi.org/10.14778/3157794.3157797. Domenic Rosati, Jan Wehner, Kai Williams, Lukasz Bartoszcze, Robie Gonzales, carsten maple, Subhabrata Ma- jumdar, Hassan Sajjad, and Frank Rudzicz. Representation noising: A defence mechanism against harmful finetuning. InThe Thirty-eighth Annual Conference on Neural Information ...
-
[17]
It takes two to tango: Navigating concep- tualizations of NLP tasks and measurements of performance
Arjun Subramonian, Xingdi Yuan, Hal Daumé III, and Su Lin Blodgett. It takes two to tango: Navigating concep- tualizations of NLP tasks and measurements of performance. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.),Findings of the Association for Computational Linguistics: ACL 2023, pp. 3234–3279, July
2023
-
[18]
doi: 10.18653/v1/2022.acl-long.521
Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.521. URLhttps://aclanthology. org/2022.acl-long.521/. Jörg Tiedemann. The tatoeba translation challenge–realistic data sets for low resource and multilingual mt. InPro- ceedings of the fifth conference on machine translation, pp. 1174–1182,
-
[19]
Llama 2: Open Foundation and Fine-Tuned Chat Models
URLhttps://arxiv.org/abs/2307.09288. Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Reinforcement Learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Song Wang, Zhen Tan, Ruocheng Guo, and Jundong Li
URLhttps: //github.com/huggingface/trl. Song Wang, Zhen Tan, Ruocheng Guo, and Jundong Li. Noise-robust fine-tuning of pretrained language models via external guidance. InThe 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[21]
URL https://openreview.net/forum?id=DSmHC8bi3j. An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Kemi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
doi: https://doi.org/10.1016/j.engappai.2025.110157
ISSN 0952-1976. doi: https://doi.org/10.1016/j.engappai.2025.110157. URLhttps://www. sciencedirect.com/science/article/pii/S0952197625001575. 13 Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification.Advances in neural information processing systems, 28,
-
[23]
cc/paper_files/paper/2018/file/f2925f97bc13ad2852a7a551802feea0-Paper.pdf
URLhttps://proceedings.neurips. cc/paper_files/paper/2018/file/f2925f97bc13ad2852a7a551802feea0-Paper.pdf. Dawei Zhu, Michael A. Hedderich, Fangzhou Zhai, David Ifeoluwa Adelani, and Dietrich Klakow. Is BERT robust to label noise? a study on learning with noisy labels in text classification. In Shabnam Tafreshi, João Sedoc, Anna Rogers, Aleksandr Drozd, A...
2018
-
[24]
doi: 10.18653/v1/2022.insights-1.8
Association for Computational Linguistics. doi: 10.18653/v1/2022.insights-1.8. URLhttps://aclanthology.org/2022.insights-1.8/. Dawei Zhu, Pinzhen Chen, Miaoran Zhang, Barry Haddow, Xiaoyu Shen, and Dietrich Klakow. Fine-tuning large language models to translate: Will a touch of noisy data in misaligned languages suffice? In Yaser Al-Onaizan, Mohit Bansal,...
-
[25]
The food was terrible and the service was even worse
Association for Computational Lin- guistics. doi: 10.18653/v1/2024.emnlp-main.24. URLhttps://aclanthology.org/2024.emnlp-main.24/. A Dataset Statistics and Prompt Templates Dataset statistics.Table 3 summarises the datasets and split sizes used for each task. All models share the same training, validation, and test samples for a given task. Table 3: Datas...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.