Recognition: 2 theorem links
· Lean TheoremFast and accurate AI-based pre-decoders for surface codes
Pith reviewed 2026-05-10 15:57 UTC · model grok-4.3
The pith
An AI pre-decoder for surface codes performs fast local parallel corrections that remove most errors before a global decoder finishes the job, cutting runtimes to microseconds per round while lowering logical error rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
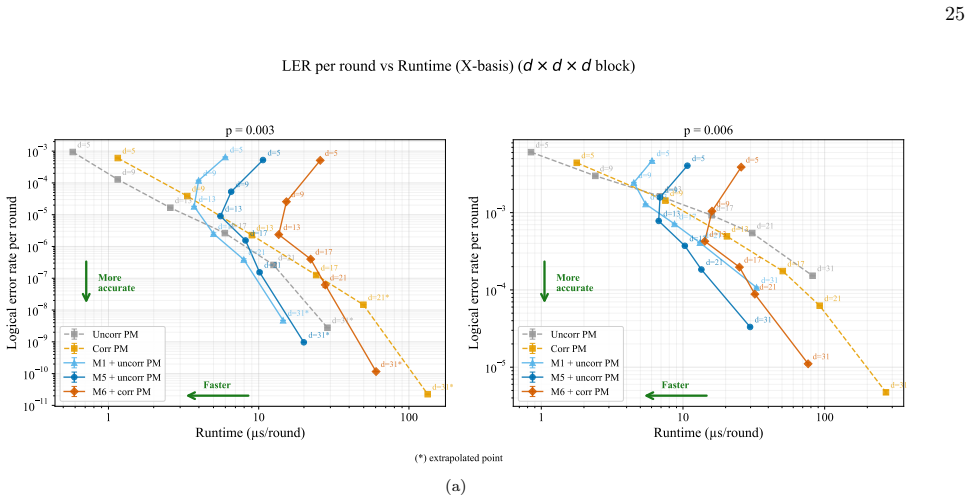
A scalable AI pre-decoder executes local, block-wise parallel error correction on surface-code syndromes, removing the majority of physical errors before residual data reaches an arbitrary global decoder. When composed with uncorrelated PyMatching this yields O(1 μs) per-round runtimes at large distances on NVIDIA GB300 GPUs together with lower logical error rates than global decoding alone; larger models outperform correlated PyMatching up to distance 13. A separate noise-learning architecture infers graph weights from experimental syndrome statistics alone, producing performance that nearly matches or exceeds standard PyMatching in several regimes without requiring an explicit circuitnoise
What carries the argument
The AI-based pre-decoder: a neural network that predicts local corrections in parallel across space-time blocks and passes only the remaining syndrome to a global decoder.
If this is right
- End-to-end decoding reaches O(1 μs) per round on single GPUs and can drop well below that with multiple GPUs in block-wise parallel mode.
- Logical error rates fall below those of global decoding alone, and a larger model beats correlated PyMatching up to distance 13.
- Purely data-driven weight estimation from syndrome statistics nearly matches uncorrelated PyMatching and exceeds correlated PyMatching in some noise regimes.
- The modular design works with any existing or future surface-code global decoder without modification.
Where Pith is reading between the lines
- The same local-pre-decoder pattern could be tested on other topological codes or with different global decoders to check whether the runtime and error-rate gains generalize.
- If the noise-learning component tracks time-varying hardware noise in real time, it could support adaptive decoding on physical devices whose error rates drift.
- Because the pre-decoder runs in parallel across many blocks, it may allow decoding latency to stay constant even as code distance grows, provided enough GPUs are available.
Load-bearing premise
The pre-decoder trained on finite-distance data continues to remove errors correctly at larger distances without creating logical errors that the global decoder cannot later fix.
What would settle it
Running the full pipeline at distance 17 or higher and measuring a logical error rate higher than that of the global decoder alone would show the pre-decoder is adding uncorrectable errors.
Figures



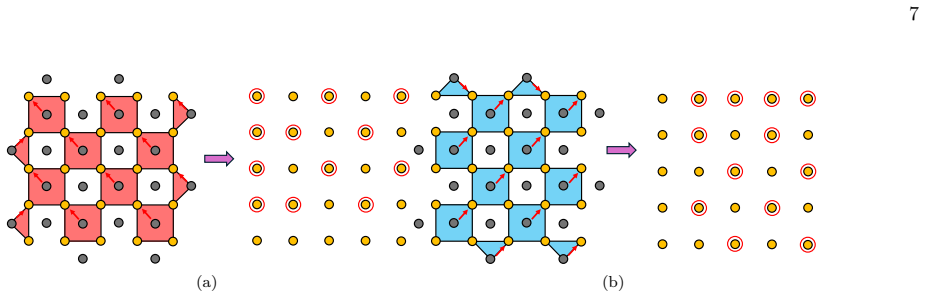
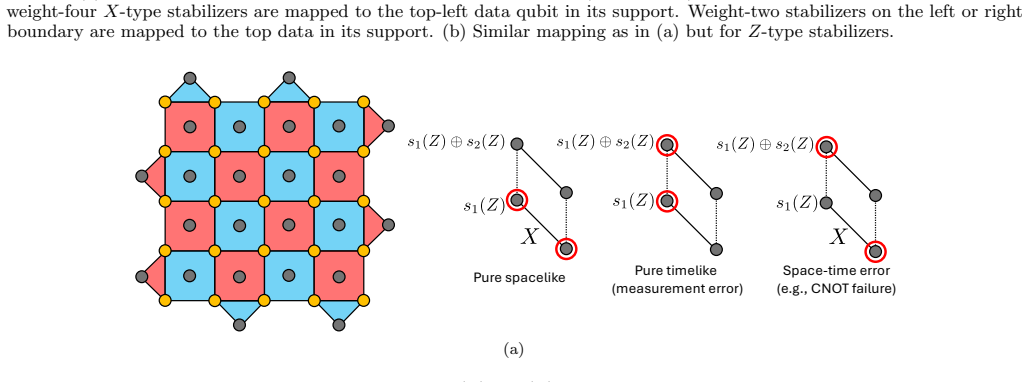

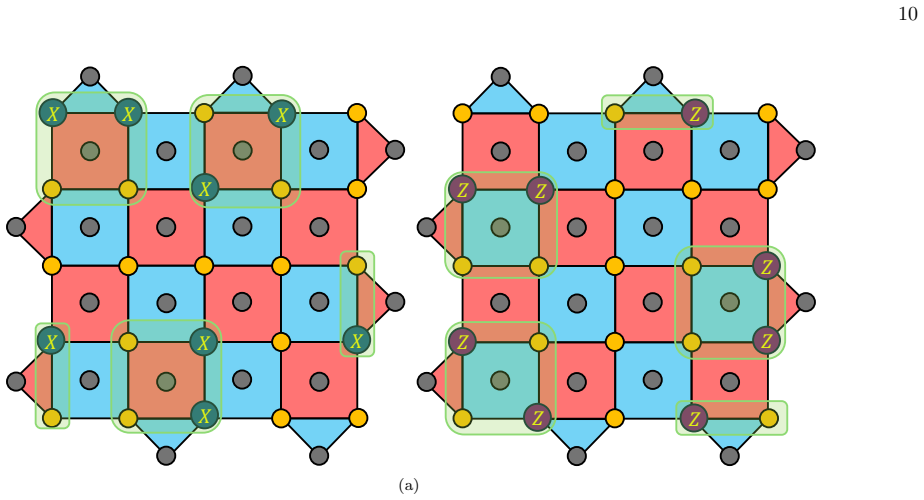
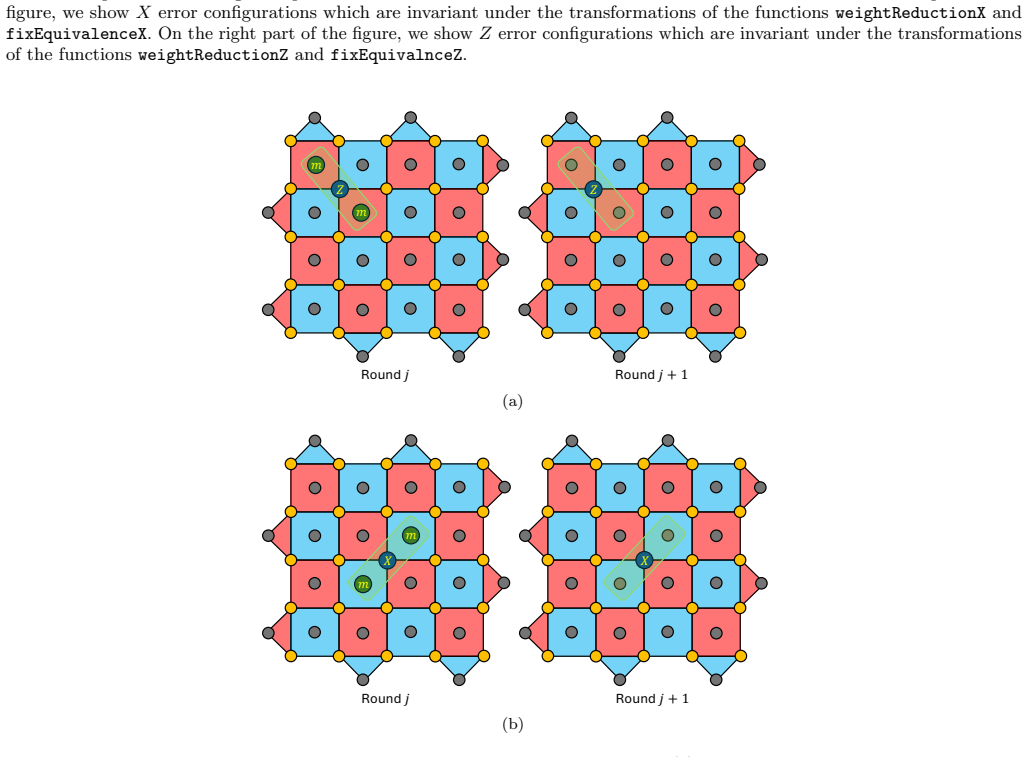











read the original abstract
Fast, scalable decoding architectures that operate in a block-wise parallel fashion across space and time are essential for real-time fault-tolerant quantum computing. We introduce a scalable AI-based pre-decoder for the surface code that performs local, parallel error correction with low decoding runtimes, removing the majority of physical errors before passing residual syndromes to a downstream global decoder. This modular architecture is backend-agnostic and composes with arbitrary global decoding algorithms designed for surface codes, and our implementation is completely open source. Integrated with uncorrelated PyMatching, the pipeline achieves end-to-end decoding runtimes of order $\mathcal{O}(1 \mu\text{s})$ per round at large code distances on NVIDIA GB300 GPUs while reducing logical error rates (LERs) relative to global decoding alone. In a block-wise parallel decoding scheme with access to multiple GPUs, the decoding runtime can be reduced to well below $\mathcal{O}(1 \mu\text{s})$ per round. We observe further LER improvements by training a larger model, outperforming correlated PyMatching up to distance-13. We additionally introduce a noise-learning architecture that infers decoding weights directly from experimentally accessible syndrome statistics without requiring an explicit circuit-level noise model. We show that purely data-driven graph weight estimation can nearly match uncorrelated PyMatching and exceed correlated PyMatching in certain regimes, enabling highly-optimized decoding when hardware noise models are unknown or time-varying, as well as training pre-decoders with realistic noise models. Together, these results establish a practical, modular, and high-throughput decoding framework suitable for large-distance surface-code implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a scalable AI-based pre-decoder for surface codes that performs local, parallel error correction on patches to remove the majority of physical errors before forwarding residual syndromes to a downstream global decoder such as uncorrelated or correlated PyMatching. It reports end-to-end runtimes of O(1 μs) per round at large distances on NVIDIA GB300 GPUs, LER reductions relative to global decoding alone, and further LER gains with larger models that outperform correlated PyMatching up to distance 13. A separate noise-learning module is presented that infers decoding graph weights directly from syndrome statistics without an explicit circuit-level noise model.
Significance. If the empirical results hold under rigorous validation, the modular pre-decoder architecture would represent a practical advance for real-time, high-throughput decoding in large-distance surface-code fault tolerance, by enabling block-wise parallel execution across space and time while remaining backend-agnostic. The open-source implementation and data-driven weight estimation for unknown or time-varying noise are concrete strengths that support reproducibility and hardware applicability.
major comments (2)
- [Results (d=13 LER comparisons and generalization statements)] The central performance claims (runtime O(1 μs) and LER reduction up to d=13) rest on the assumption that local AI corrections never produce residual syndromes whose combined weight with the pre-decoder output exceeds the global decoder's correction capability at the original code distance. No explicit failure-mode analysis, out-of-distribution test sets at d>13, or distance-extrapolation study is provided to verify that the pre-decoder does not complete logical operators or inflate error chains for unseen configurations.
- [Methods and experimental setup] Concrete runtime and LER numbers are reported in the abstract and results, yet the manuscript supplies no training details, validation splits, Monte Carlo sample counts, error bars, hyperparameter search procedure, or ablation studies on model size versus performance. This absence makes it impossible to determine whether the reported gains are robust or influenced by post-hoc model selection.
minor comments (2)
- [Figures and abstract] Figure captions and text should explicitly state the number of Monte Carlo shots and the precise definition of 'per round' when quoting O(1 μs) runtimes.
- [Noise-learning section] Notation for the noise-learning architecture (e.g., how syndrome statistics map to edge weights) could be formalized with a short equation or pseudocode to improve clarity for readers unfamiliar with the PyMatching interface.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the work's potential significance. We address the major comments point by point below, with plans to revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Results (d=13 LER comparisons and generalization statements)] The central performance claims (runtime O(1 μs) and LER reduction up to d=13) rest on the assumption that local AI corrections never produce residual syndromes whose combined weight with the pre-decoder output exceeds the global decoder's correction capability at the original code distance. No explicit failure-mode analysis, out-of-distribution test sets at d>13, or distance-extrapolation study is provided to verify that the pre-decoder does not complete logical operators or inflate error chains for unseen configurations.
Authors: We agree that an explicit failure-mode analysis would provide valuable additional validation. The observed LER reductions relative to global decoding alone, including outperforming correlated PyMatching up to d=13, provide empirical evidence that the pre-decoder does not systematically inflate error chains in the tested regimes. The architecture applies only local corrections within each patch, which by design targets low-weight errors and forwards residuals to the global decoder operating at the full code distance. Nevertheless, we will add a dedicated discussion of potential failure modes, including analysis of residual syndrome weights and any available out-of-distribution tests, in the revised manuscript. revision: partial
-
Referee: [Methods and experimental setup] Concrete runtime and LER numbers are reported in the abstract and results, yet the manuscript supplies no training details, validation splits, Monte Carlo sample counts, error bars, hyperparameter search procedure, or ablation studies on model size versus performance. This absence makes it impossible to determine whether the reported gains are robust or influenced by post-hoc model selection.
Authors: We acknowledge that these experimental details are missing from the current version and agree they are necessary for assessing robustness. In the revised manuscript we will include full training details, validation and test splits, the number of Monte Carlo samples used for each LER estimate, error bars computed across independent runs, the hyperparameter search procedure, and ablation studies examining model size versus both LER improvement and runtime. revision: yes
Circularity Check
No circularity: empirical training and composition with external decoders
full rationale
The paper's central results rest on training an AI pre-decoder on simulated error data and measuring empirical LER/runtime improvements when composed with PyMatching (uncorrelated or correlated). No equations, uniqueness theorems, or self-citations are invoked to derive the performance claims; the reported gains are direct experimental outcomes on held-out configurations up to distance 13. The noise-learning component similarly infers weights from syndrome statistics without reducing to a fitted quantity defined by the target result. All load-bearing steps remain falsifiable via independent simulation or hardware runs and do not collapse to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights
axioms (1)
- domain assumption Standard surface-code stabilizer formalism and syndrome extraction circuit assumptions hold.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe introduce a scalable AI-based pre-decoder for the surface code that performs local, parallel error correction with low decoding runtimes, removing the majority of physical errors before passing residual syndromes to a downstream global decoder.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearThe receptive field is given by Rl = 1 + sum (ki-1). ... homological equivalence protocol
Forward citations
Cited by 1 Pith paper
-
Real-time Surface-Code Error Correction Using an FPGA-based Neural-Network Decoder
An FPGA-based neural-network decoder achieves 550 ns deterministic closed-loop latency for real-time distance-3 surface code error correction on a superconducting processor, matching offline decoding performance.
Reference graph
Works this paper leans on
-
[1]
Sample a base error ratep base from a log-uniform dis- tribution over [ pmin, pmax], then derive the 25 noise parameters with location-specific random multipliers and random Pauli-type distributions (see Section A 1)
-
[2]
Generate B independent syndrome samples at the train- ing distancedusing the sampled noise model
-
[3]
For each sample k, compute zk = MLP(GAP(CNN(xk)))
-
[4]
Average logits: ¯z = 1 B P k zk, then ˆp = BoundedLogSpace(¯z) via Eq. (61)
-
[5]
Compute ˆPej =E j( ˆp) and ˆHk =H k( ˆp)
-
[6]
PyMatching after model X
Minimize L = Ledge + Lhyper and backpropagate through the differentiable formulas. The hierarchical noise sampling ensures diverse train- ing data spanning multiple orders of magnitude while maintaining physically reasonable correlations between parameters. E. Inference strategy At inference time, the trained network is applied to syndrome data produced b...
2048
-
[7]
• Measurement errors (2): PmX for X-basis mea- surement,P mZ forZ-basis measurement
Notation and methodology The circuit-level noise model is parameterized by 25 probabilities: • State preparation errors (2): PSX for |+⟩ prepa- ration,P SZ for|0⟩preparation. • Measurement errors (2): PmX for X-basis mea- surement,P mZ forZ-basis measurement. • Idle errors during CNOT layers (3): P (X) idle,CNOT, P (Y) idle,CNOT, P (Z) idle,CNOT for singl...
-
[8]
Arise from data qubit errors
Edge classification The matching graph contains four categories of edges: • Spacelike edges: Connect different stabilizers within the same measurement round. Arise from data qubit errors. • Timelike edges: Connect the same stabilizer across adjacent measurement rounds. Arise from ancilla/measurement errors. • Diagonal edges: Connect different stabilizers ...
-
[9]
These formulas detect ZandYerrors on data qubits
X-stabilizer graph edge formulas We provide the verified edge probability formulas for the X-stabilizer matching graph. These formulas detect ZandYerrors on data qubits. a. Spacelike edges TypeP (X) S1 : P (X) S1 = Mh P (Y Y) CX +P (ZZ) CX , P (IZ) CX +P (XZ) CX , P (Z) I , P (Z) I , P (Y Z) CX +P (ZY) CX , P (IY) CX +P (XY) CX , P (Y) I , P (Y) I i .(A4)...
-
[10]
Similar to the X-graph, it has 18 edge types: 3 spacelike (S1–S3), 4 timelike (T1–T4), 5 diagonal (D1–D5), and 6 boundary (B1–B6)
Z-stabilizer graph edge formulas The Z-stabilizer matching graph detectsX and Y errors on data qubits. Similar to the X-graph, it has 18 edge types: 3 spacelike (S1–S3), 4 timelike (T1–T4), 5 diagonal (D1–D5), and 6 boundary (B1–B6). The explicit formulas are obtained from the X-stabilizer formulas above by replacing all Z-type Paulis with X-type Paulis, ...
-
[11]
The methodology is:
Summary and verification The formulas were derived by systematically tracing error propagation through the syndrome extraction circuit for each possible Pauli error at each fault location. The methodology is:
-
[12]
For each fault location (CNOT, idle, state prepara- tion), activate a single Pauli error
-
[13]
Generate the detector error model (DEM) using Stim
-
[14]
Identify which DEM patterns contain the target edge’s detector pair
-
[15]
Group contributions by pattern and sum Paulis from the same location. 35
-
[16]
The formulas aredistance-independent: the same formulas apply identically for d = 5, 7, 9, 11, 13 and be- yond
XOR-combine all pattern contributions to get the final formula. The formulas aredistance-independent: the same formulas apply identically for d = 5, 7, 9, 11, 13 and be- yond. This is because edge probabilities depend only on local stabilizer geometry, not global code size. Only thecountof each edge type changes with distance. For example, at d = 5 the X-...
-
[17]
P. W. Shor, Scheme for reducing decoherence in quantum computer memory, Phys. Rev. A52, R2493 (1995)
1995
-
[18]
Knill, R
E. Knill, R. Laflamme, and L. Viola, Theory of quantum error correction for general noise, Phys. Rev. Lett.84, 2525 (2000)
2000
-
[19]
Chao and B
R. Chao and B. W. Reichardt, Quantum error correction with only two extra qubits, Phys. Rev. Lett.121, 050502 (2018)
2018
-
[20]
Chamberland and M
C. Chamberland and M. E. Beverland, Flag fault-tolerant error correction with arbitrary distance codes, Quantum 2, 53 (2018)
2018
-
[21]
Chao and B
R. Chao and B. W. Reichardt, Flag fault-tolerant er- ror correction for any stabilizer code, PRX Quantum1, 010302 (2020)
2020
-
[22]
Chamberland and A
C. Chamberland and A. W. Cross, Fault-tolerant magic state preparation with flag qubits, Quantum3, 143 (2019)
2019
-
[23]
Chamberland and K
C. Chamberland and K. Noh, Very low overhead fault- tolerant magic state preparation using redundant ancilla encoding and flag qubits, npj Quantum Information6, 91 (2020)
2020
-
[24]
B. M. Terhal, Quantum error correction for quantum memories, Rev. Mod. Phys.87, 307 (2015)
2015
-
[25]
Chamberland, L
C. Chamberland, L. Goncalves, P. Sivarajah, E. Peterson, and S. Grimberg, Techniques for combining fast local decoders with global decoders under circuit-level noise, Quantum Science and Technology8, 045011 (2023)
2023
-
[26]
Skoric, D
L. Skoric, D. E. Browne, K. M. Barnes, N. I. Gillespie, and E. T. Campbell, Parallel window decoding enables scalable fault tolerant quantum computation, Nature Communica- tions14, 7040 (2023)
2023
- [27]
-
[28]
Chamberland and E
C. Chamberland and E. T. Campbell, Universal quantum computing with twist-free and temporally encoded lattice surgery, PRX Quantum3, 010331 (2022)
2022
-
[29]
New magic state distillation factories optimized by temporally encoded lattice surgery , publisher =
P. Prabhu and C. Chamberland, New magic state dis- tillation factories optimized by temporally encoded lat- tice surgery, arXiv e-prints , arXiv:2210.15814 (2022), arXiv:2210.15814 [quant-ph]
-
[30]
Chamberland and P
C. Chamberland and P. Ronagh, Deep neural decoders for near term fault-tolerant experiments, Quantum Science and Technology3, 044002 (2018)
2018
-
[31]
Baireuther, M
P. Baireuther, M. D. Caio, B. Criger, C. W. J. Beenakker, and T. E. O’Brien, Neural network decoder for topological color codes with circuit level noise, New Journal of Physics 21, 013003 (2019)
2019
-
[32]
Bausch, A
J. Bausch, A. W. Senior, F. J. H. Heras, T. Edlich, A. Davies, M. Newman, C. Jones, K. Satzinger, M. Y. Niu, S. Blackwell, G. Holland, D. Kafri, J. Atalaya, C. Gidney, D. Hassabis, S. Boixo, H. Neven, and P. Kohli, Learn- ing high-accuracy error decoding for quantum processors, Nature635, 834 (2024)
2024
-
[33]
A. W. Senior, T. Edlich, F. J. H. Heras, L. M. Zhang, O. Higgott, J. S. Spencer, T. Applebaum, S. Black- well, J. Ledford, A. ˇZemgulyt˙ e, A. ˇZ´ ıdek, N. Shutty, A. Cowie, Y. Li, G. Holland, P. Brooks, C. Beattie, M. Newman, A. Davies, C. Jones, S. Boixo, H. Neven, P. Kohli, and J. Bausch, A scalable and real-time neural decoder for topological quantum ...
-
[34]
K. Zhang, Z. Yi, S. Guo, L. Kong, S. Wang, X. Zhan, T. He, W. Lin, T. Jiang, D. Gao, Y. Zhang, F. Liu, F. Zhang, Z. Ji, F. Chen, and J. Chen, Learning to De- code in Parallel: Self-Coordinating Neural Network for Real-Time Quantum Error Correction, arXiv e-prints , arXiv:2601.09921 (2026), arXiv:2601.09921 [quant-ph]
- [35]
-
[36]
arXiv preprint arXiv:1808.02892 , year=
D. Litinski, A Game of Surface Codes: Large-Scale Quan- tum Computing with Lattice Surgery, Quantum3, 128 (2019), 1808.02892
-
[37]
Chamberland and E
C. Chamberland and E. T. Campbell, Circuit-level pro- tocol and analysis for twist-based lattice surgery, Phys. Rev. Research4, 023090 (2022)
2022
-
[38]
Gicev, L
S. Gicev, L. C. L. Hollenberg, and M. Usman, A scalable and fast artificial neural network syndrome decoder for surface codes, Quantum7, 1058 (2023)
2023
-
[39]
Fully convolutional 3D neural network decoders for surface codes with syndrome circuit noise
S. Gicev, L. C. L. Hollenberg, and M. Usman, Fully convo- lutional 3D neural network decoders for surface codes with syndrome circuit noise, arXiv e-prints , arXiv:2506.16113 (2025), arXiv:2506.16113 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
arXiv preprint arXiv:2509.03954 , year=
K. Zhang, J. Xu, F. Zhang, L. Kong, Z. Ji, and J. Chen, LATTE: A Decoding Architecture for Quantum Comput- ing with Temporal and Spatial Scalability, arXiv e-prints , arXiv:2509.03954 (2025), arXiv:2509.03954 [quant-ph]
-
[41]
L. Caune, B. Reid, J. Camps, and E. Campbell, Belief propagation as a partial decoder (2023), arXiv:2306.17142 [quant-ph]
-
[42]
Dennis, A
E. Dennis, A. Kitaev, A. Landahl, and J. Preskill, Topolog- ical quantum memory, Journal of Mathematical Physics 43, 4452 (2002)
2002
-
[43]
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, Surface codes: Towards practical large-scale quantum computation, Phys. Rev. A86, 032324 (2012)
2012
-
[44]
Tomita and K
Y. Tomita and K. M. Svore, Low-distance surface codes under realistic quantum noise, Phys. Rev. A90, 062320 (2014)
2014
-
[45]
O. Higgott, Pymatching: A python package for de- coding quantum codes with minimum-weight perfect matching, ACM Transactions on Quantum Computing3, 36 10.1145/3505637 (2022)
-
[46]
Litinski and F
D. Litinski and F. v. Oppen, Lattice surgery with a twist: Simplifying Clifford gates of surface codes, Quantum2, 62 (2018)
2018
-
[47]
Delfosse and N
N. Delfosse and N. H. Nickerson, Almost-linear time de- coding algorithm for topological codes, Quantum5, 595 (2021)
2021
-
[48]
Edmonds, Paths, trees, and flowers, Canadian Journal of Mathematics17, 449–467 (1965)
J. Edmonds, Paths, trees, and flowers, Canadian Journal of Mathematics17, 449–467 (1965)
1965
-
[49]
Higgott and C
O. Higgott and C. Gidney, Sparse Blossom: correcting a million errors per core second with minimum-weight matching, Quantum9, 1600 (2025)
2025
-
[50]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, Distilling the knowl- edge in a neural network, arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[51]
S. A. Caldwell, M. Khazraee, E. Agostini, T. Las- siter, C. Simpson, O. Kahalon, M. Kanuri, J.-S. Kim, S. Stanwyck, M. Li, J. Olle, C. Chamberland, B. Howe, B. Schmitt, J. G. Lietz, A. McCaskey, J. Ye, A. Li, A. B. Magann, C. I. Ostrove, K. Rudinger, R. Blume- Kohout, K. Young, N. E. Miller, Y. Xu, G. Huang, I. Sid- diqi, J. Lange, C. Zimmer, and T. Humbl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.