Recognition: unknown
Complexity scaling and optimal policy degeneracy in quantum reinforcement learning via analytically solvable unitary-control-then-measure models
Pith reviewed 2026-05-10 17:04 UTC · model grok-4.3
The pith
Quantum RL with unitary control and measurement reduces expected return complexity from exponential to power-law scaling while revealing distinct optimal policy degeneracy patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
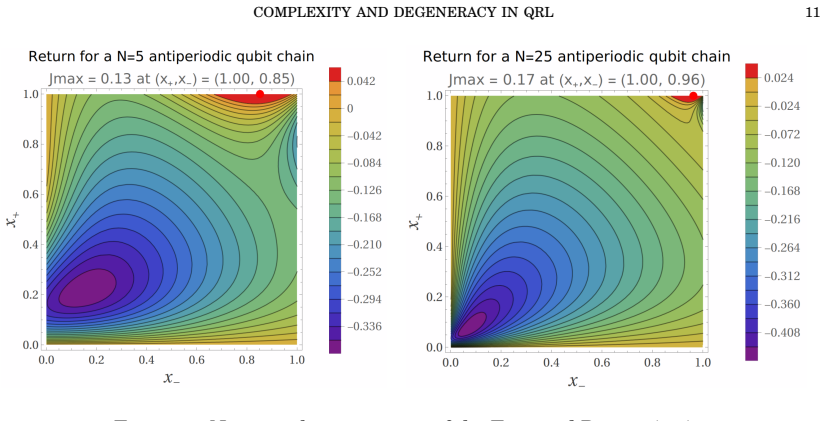
In these analytically solvable unitary-control-then-measure models of finite-horizon quantum Markov decision processes, the expected return admits exact closed-form expressions whose computational cost scales as O(N^I) rather than the nominal O(e^N), due to trajectory equivalence classes at the path level and sparsity of the allowed transition graph at the policy level; low-dimensional realizations possess unique optimal policies whose large-N limit is governed by the quantum Zeno effect, whereas the four-level system displays both plateau-type quasi-degeneracy for large horizons and genuine discrete degeneracy at critical energy parameters.
What carries the argument
The unitary-control-then-measure protocol, which applies a unitary to the quantum state and immediately follows it with a projective measurement onto a fixed reference basis, enabling closed-form trajectory probabilities and expected-return sums.
If this is right
- In the qubit and qutrit models, optimal policies remain unique for every finite horizon, with their large-N behavior fixed by the quantum Zeno effect.
- The four-level two-qubit model exhibits both continuous plateau quasi-degeneracy at large N and isolated points of discrete policy degeneracy at specific critical energy values.
- The two-level complexity reduction applies uniformly across all four realizations, converting the sum over exponentially many trajectories into a polynomial-time sum over equivalence classes.
- The sparsity of the transition graph induced by unitary constraints is what produces the second, policy-level reduction beyond the combinatorial equivalence at the trajectory level.
Where Pith is reading between the lines
- If the same equivalence-class counting extends to higher-dimensional or continuous-variable systems, then practical quantum RL algorithms could evaluate returns for horizons previously considered intractable.
- The observed discrete degeneracy at critical parameters suggests that small changes in Hamiltonian energies could be used to engineer policy multiplicity or uniqueness on demand.
- Because the models are fully solvable, they provide exact benchmarks against which approximate quantum RL methods on larger systems can be validated.
Load-bearing premise
The assumption that the chosen finite-dimensional unitary controls and fixed-basis projective measurements permit exact closed-form derivations while still capturing the essential complexity and degeneracy features of broader quantum reinforcement learning.
What would settle it
Direct numerical enumeration of all possible trajectories for the four-level model at increasing horizon lengths N, checking whether the time to compute the expected return grows as a power of N rather than exponentially.
Figures








read the original abstract
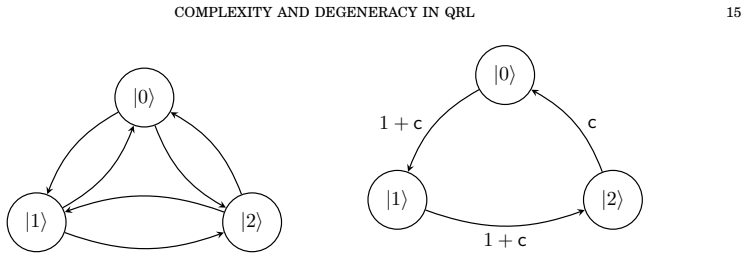
We propose and analyse a class of analytically solvable models of quantum reinforcement learning (QRL), formulated as finite-horizon Markov decision processes in finite-dimensional Hilbert spaces. The models are built around a `unitary-control-then-measure' protocol, in which a learning agent applies unitary transformations to a quantum state and interleaves each control step with a projective measurement onto a prescribed reference basis. Exact closed-form expressions for trajectory probabilities, rewards, and the expected return are derived for four concrete realisations: a closed-chain and an anti-periodic qubit implementation, a qutrit model with ladder coupling, and a four-level two-qubit system. Two structural features of these QRL protocols are rigorously analysed. First, we identify and quantify a two-level reduction in the computational complexity of the expected return, from the nominally exponential $O(e^N)$ scaling in the trajectory length~$N$ to an explicit power-law $O(N^{\mathcal{I}})$: a trajectory-based level, arising from equivalence classes of paths sharing the same unordered state counts and transition frequencies, and a policy-based level, arising from the sparsity of the transition graph enforced by constrained unitary actions. Second, we characterise the degeneracy of optimal policies. The low-dimensional models exhibit unique optima whose asymptotic behaviour with~$N$ is governed by the quantum Zeno effect, while the four-level system displays both plateau-type quasi-degeneracy at large horizons and genuine discrete degeneracy at critical energy parameters -- phenomena with no counterpart in the measurement-free quantum optimal control landscape.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes and analyzes a class of analytically solvable quantum reinforcement learning models formulated as finite-horizon MDPs in finite-dimensional Hilbert spaces. These are constructed around a unitary-control-then-measure protocol, with exact closed-form expressions derived for trajectory probabilities, rewards, and expected returns in four explicit low-dimensional realizations (closed-chain qubit, anti-periodic qubit, qutrit ladder, and four-level two-qubit systems). The central results are a two-level complexity reduction for the expected return—from nominal O(e^N) to O(N^I) scaling, arising from trajectory equivalence classes (unordered state counts and transition frequencies) plus unitary-enforced transition-graph sparsity—and a characterization of optimal-policy degeneracy, including unique optima with quantum-Zeno asymptotics in the qubit/qutrit cases and both plateau quasi-degeneracy and discrete degeneracy at critical energies in the four-level model.
Significance. If the closed-form derivations and scaling claims hold, the work supplies rare exactly solvable benchmarks in QRL that quantify how unitary constraints and projective measurements induce polynomial complexity and specific degeneracy structures absent from measurement-free quantum control. The explicit model constructions and analytical results constitute a clear strength, enabling reproducible verification and potential generalization of the equivalence-class and sparsity mechanisms.
major comments (2)
- [§4] §4 (complexity reduction): the reduction from O(e^N) to O(N^I) is asserted to follow from equivalence classes of trajectories and sparsity of the transition graph; however, the manuscript must explicitly compute or bound the exponent I for each of the four models as a function of N and Hilbert-space dimension, including verification that the number of distinct (state-count, transition-frequency) classes remains polynomial for arbitrary N rather than merely for the small-N cases examined.
- [§5.2] §5.2 (four-level degeneracy): the distinction between plateau-type quasi-degeneracy at large N and genuine discrete degeneracy at critical energy parameters is central to the claim of phenomena with no classical counterpart; the analysis should supply the explicit algebraic condition on the energy parameters that produces the discrete degeneracy and demonstrate that it is not an artifact of the finite-N truncation.
minor comments (2)
- The notation for the polynomial degree I is introduced without a dedicated definition or table summarizing its value per model; a compact table or explicit formula in the main text would improve readability.
- Figure captions for the degeneracy plots should state the precise numerical tolerances used to identify 'plateau' versus 'discrete' degeneracy.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment, and recommendation for minor revision. We address each major comment below and will incorporate the requested clarifications and extensions into the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (complexity reduction): the reduction from O(e^N) to O(N^I) is asserted to follow from equivalence classes of trajectories and sparsity of the transition graph; however, the manuscript must explicitly compute or bound the exponent I for each of the four models as a function of N and Hilbert-space dimension, including verification that the number of distinct (state-count, transition-frequency) classes remains polynomial for arbitrary N rather than merely for the small-N cases examined.
Authors: We agree that explicit per-model expressions for the exponent I are needed to substantiate the claim. In the revision we will derive and state the precise polynomial degree I for each of the four realizations (closed-chain qubit, anti-periodic qubit, qutrit ladder, four-level two-qubit), expressing I explicitly in terms of horizon N and Hilbert-space dimension d. We will also supply a general counting argument showing that the number of distinct equivalence classes—unordered state-visit multisets and transition-frequency vectors compatible with the unitary transition graph—is bounded by a polynomial of degree at most d−1 in N for arbitrary N, thereby confirming the O(N^I) scaling holds beyond the small-N examples. revision: yes
-
Referee: [§5.2] §5.2 (four-level degeneracy): the distinction between plateau-type quasi-degeneracy at large N and genuine discrete degeneracy at critical energy parameters is central to the claim of phenomena with no classical counterpart; the analysis should supply the explicit algebraic condition on the energy parameters that produces the discrete degeneracy and demonstrate that it is not an artifact of the finite-N truncation.
Authors: We thank the referee for this observation. The discrete degeneracy occurs precisely when the energy parameters satisfy a specific algebraic relation obtained by requiring that two distinct policy parameters yield identical expected returns; this relation is independent of N because the return expression factors into an N-independent prefactor times a polynomial whose roots determine the critical energies. In the revision we will state the explicit algebraic condition and prove that the same roots persist for all N by direct inspection of the closed-form return, confirming the degeneracy is not an artifact of finite-horizon truncation. revision: yes
Circularity Check
No significant circularity; derivations are direct consequences of model definitions
full rationale
The paper defines a specific 'unitary-control-then-measure' protocol in finite-dimensional Hilbert spaces and constructs four concrete low-dimensional models (closed-chain qubit, anti-periodic qubit, qutrit ladder, four-level two-qubit). It then derives exact closed-form expressions for trajectory probabilities, rewards, and expected returns directly from these definitions. The claimed two-level complexity reduction to O(N^I) follows mathematically from grouping trajectories into equivalence classes by unordered state counts and transition frequencies (a combinatorial consequence of the finite state space and measurement basis) plus the sparsity of the transition graph enforced by the constrained unitaries. No parameters are fitted to data and then relabeled as predictions; no self-citations or uniqueness theorems from prior author work are invoked as load-bearing steps; and no ansatz is smuggled in. The results are therefore self-contained analytical consequences rather than reductions to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- critical energy parameters
axioms (3)
- standard math Unitary operators on finite-dimensional Hilbert spaces preserve state norms and enable coherent control
- standard math Projective measurements onto a fixed reference basis produce probabilistic outcomes according to Born rule
- domain assumption Finite-horizon Markov decision process formulation applies to the quantum state evolution
Reference graph
Works this paper leans on
-
[1]
Aharonov, L
Y. Aharonov, L. Davidovich, and N. Zagury , Quantum random walks , Phys. Rev. A, 48 (1993), pp. 1687--1690
1993
-
[2]
Arulkumaran, M
K. Arulkumaran, M. P. Deisenroth, M. Brundage, and A. A. Bharath , Deep reinforcement learning: A brief survey , IEEE signal processing magazine, 34 (2017), pp. 26--38
2017
-
[3]
Attal, F
S. Attal, F. Petruccione, C. Sabot, and I. Sinayskiy , Open Quantum Random Walks , J. Stat. Phys., 147 (2012), pp. 832--852
2012
-
[4]
R. B. Bapat , Graphs and Matrices , Universitext , Springer, London, 2 ed., 2014
2014
-
[5]
A. Barr, W. Gispen, and A. Lamacraft , Quantum Ground States from Reinforcement Learning , in Proceedings of Machine Learning Research , vol. 107, PMLR, 2020, pp. 635--653
2020
-
[6]
Bertsekas , Reinforcement learning and optimal control , vol
D. Bertsekas , Reinforcement learning and optimal control , vol. 1, Athena Scientific, 2019
2019
-
[7]
height 2pt depth -1.6pt width 23pt, A course in reinforcement learning , Athena Scientific, 2024
2024
-
[8]
H. J. Briegel and G. De las Cuevas , Projective simulation for artificial intelligence , Sci. Rep., 2 (2012), p. 400
2012
-
[9]
Clarke and F
J. Clarke and F. K. Wilhelm , Superconducting quantum bits , Nature, 453 (2008), pp. pages 1031--1042
2008
-
[10]
Cohen-Tannoudji, B
C. Cohen-Tannoudji, B. Diu, and F. Lalo \"e , Quantum mechanics , Wiley, New York, NY, 1977. Trans. of : M \'e canique quantique. Paris : Hermann, 1973
1977
-
[11]
D. Dong, C. Chen, H. Li, and T.-J. Tarn , Quantum Reinforcement Learning , IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 38 (2008), pp. 1207--1220
2008
-
[12]
1207--1220
height 2pt depth -1.6pt width 23pt, Quantum reinforcement learning , IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 38 (2008), pp. 1207--1220
2008
-
[13]
Facchi and S
P. Facchi and S. Pascazio , Quantum Zeno dynamics: mathematical and physical aspects , Journal of Physics A: Mathematical and Theoretical, 41 (2008), p. 493001
2008
-
[14]
Hsieh and H
M. Hsieh and H. Rabitz , Optimal control landscape for the generation of unitary transformations , Phys. Rev. A, 77 (2008), p. 042306
2008
-
[15]
Hsieh, R
M. Hsieh, R. Wu, H. Rabitz, and D. Lidar , Optimal control landscape for the generation of unitary transformations with constrained dynamics , Phys. Rev. A, 81 (2010), p. 062352
2010
-
[16]
L. P. Kaelbling, M. L. Littman, and A. W. Moore , Reinforcement learning: A survey , Journal of artificial intelligence research, 4 (1996), pp. 237--285
1996
-
[17]
Leibfried, R
D. Leibfried, R. Blatt, C. Monroe, and D. Wineland , Quantum dynamics of single trapped ions , Rev. Mod. Phys., 75 (2003), pp. 281--324
2003
-
[18]
A survey on quantum reinforcement learning,
N. Meyer, C. Ufrecht, M. Periyasamy, D. D. Scherer, A. Plinge, and C. Mutschler , A Survey on Quantum Reinforcement Learning , arXiv:2211.03464 (2022)
-
[19]
G. D. Paparo, V. Dunjko, A. Makmal, M. A. Martin-Delgado, and H. J. Briegel , Quantum speed-up for active learning agents , Phys. Rev. X, 4 (2014), p. 031002
2014
-
[20]
M. L. Puterman , Markov decision processes: discrete stochastic dynamic programming , John Wiley & Sons, 2014
2014
-
[21]
S. M. Reimann and M. Manninen , Electronic structure of quantum dots , Rev. Mod. Phys., 74 (2002), pp. 1283--1342
2002
-
[22]
Schenk, E
M. Schenk, E. F. Combarro, M. Grossi, V. Kain, K. S. B. Li, M.-M. Popa, and S. Vallecorsa , Hybrid actor-critic algorithm for quantum reinforcement learning at cern beam lines , Quantum Science and Technology, 9 (2024), p. 025012
2024
-
[23]
Sugny and C
D. Sugny and C. Kontz , Optimal control of a three-level quantum system by laser fields plus von Neumann measurements , Phys. Rev. A, 77 (2008), p. 063420
2008
-
[24]
R. S. Sutton and A. G. Barto , Reinforcement Learning: An Introduction , The MIT Press, second ed., 2018
2018
-
[25]
Szepesv \'a ri , Algorithms for reinforcement learning , Springer nature, 2022
C. Szepesv \'a ri , Algorithms for reinforcement learning , Springer nature, 2022
2022
-
[26]
S. E. Venegas-Andraca , Quantum walks: a comprehensive review , Quantum Inf. Process., 11 (2012), pp. 1015--1106
2012
-
[27]
Volkov, A
B. Volkov, A. Myachkova, and A. Pechen , Phenomenon of a stronger trapping behavior in -type quantum systems with symmetry , Phys. Rev. A, 111 (2025), p. 022617
2025
-
[28]
Wendin , Quantum information processing with superconducting circuits: a review , Reports on Progress in Physics, 80 (2017), p
G. Wendin , Quantum information processing with superconducting circuits: a review , Reports on Progress in Physics, 80 (2017), p. 106001
2017
-
[29]
S. Wu, S. Jin, D. Wen, D. Han, and X. Wang , Quantum reinforcement learning in continuous action space , Quantum, 9 (2025), p. 1660
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.