Recognition: unknown
Selecting Feature Interactions for Generalized Additive Models by Distilling Foundation Models
Pith reviewed 2026-05-10 14:56 UTC · model grok-4.3
The pith
Distilling interactions from tabular foundation models improves generalized additive models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a dataset, TabDistill first fits a tabular foundation model to the dataset, and then applies a post-hoc interaction attribution method to extract salient feature interactions from it. These interactions are used as terms in a GAM, and across tasks the resulting models show consistent improvements in predictive performance.
What carries the argument
TabDistill, the procedure that distills salient feature interactions from a fitted tabular foundation model via post-hoc attribution and inserts them into a generalized additive model.
Load-bearing premise
The interactions identified by post-hoc attribution on the tabular foundation model are stable and supply additive value that improves GAM performance beyond what heuristic selection already provides.
What would settle it
If GAMs trained with TabDistill interactions show no improvement or lower accuracy than heuristic-selected GAMs on held-out test data across multiple tasks, the claim of consistent gains would be disproven.
Figures



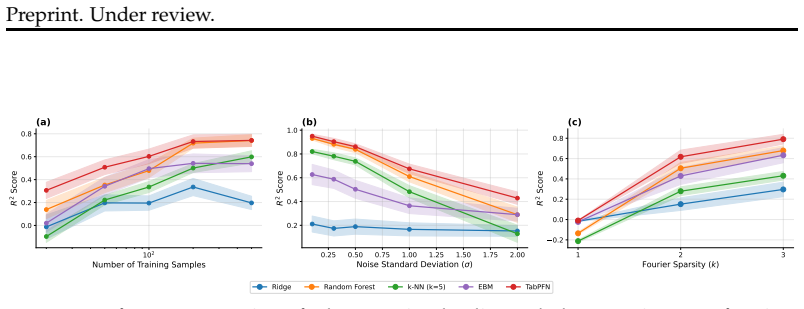
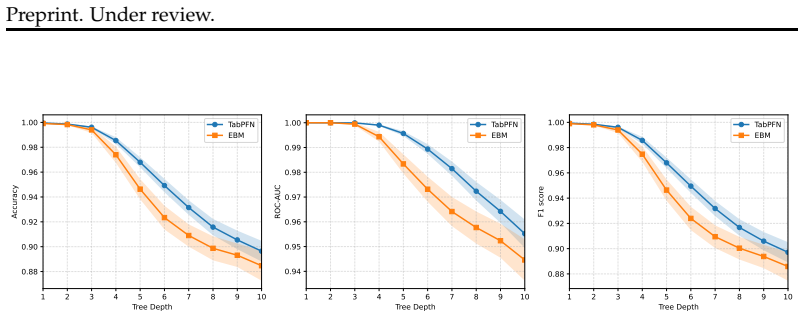
read the original abstract
Identifying meaningful feature interactions is a central challenge in building accurate and interpretable models for tabular data. Generalized additive models (GAMs) have shown great success at modeling tabular data, but often rely on heuristic procedures to select interactions, potentially missing higher-order or context-dependent effects. To meet this challenge, we propose TabDistill, a method that leverages tabular foundation models and post-hoc distillation methods. Our key intuition is that tabular foundation models implicitly learn rich, adaptive feature dependencies through large-scale representation learning. Given a dataset, TabDistill first fits a tabular foundation model to the dataset, and then applies a post-hoc interaction attribution method to extract salient feature interactions from it. We evaluate these interactions by then using them as terms in a GAM. Across tasks, we find that interactions identified by TabDistill lead to consistent improvements in downstream GAMs' predictive performance. Our results suggest that tabular foundation models can serve as effective, data-driven guides for interaction discovery, bridging high-capacity models and interpretable additive frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TabDistill, a pipeline that fits a tabular foundation model to a given dataset and applies post-hoc attribution (e.g., SHAP or integrated gradients) to extract salient feature interactions, which are then inserted as terms into a Generalized Additive Model (GAM). The central claim is that these distilled interactions produce consistent predictive gains in the downstream GAM relative to standard heuristic interaction selection.
Significance. If the claimed gains are robust and exceed those of established heuristics, the work would offer a practical bridge between high-capacity tabular foundation models and interpretable additive models, potentially improving both accuracy and transparency on tabular tasks. The approach is noteworthy for attempting to leverage large-scale representation learning for interaction discovery rather than relying solely on domain-specific heuristics.
major comments (3)
- [Abstract / Experimental Results] Abstract and Experimental Results section: the claim that TabDistill yields 'consistent improvements' is unsupported by any reported numbers, baselines, statistical tests, or ablation details. Without these, it is impossible to determine whether the gains are robust, statistically significant, or merely artifacts of the foundation model's capacity.
- [Method / Experiments] Method and Experiments sections: the central assumption that post-hoc attributions from the foundation model extract stable, additive interactions (rather than non-additive correlations) is not tested via stability checks across random seeds, attribution methods, or data splits. If attributions primarily reflect the foundation model's internal capacity instead of transferable additive structure, the distillation step adds no value beyond standard heuristics such as mutual information or tree-based pairwise selection.
- [Experiments] Experiments section: missing ablations that isolate the contribution of the tabular foundation model versus the choice of attribution technique, and direct comparisons against established GAM interaction-selection procedures (e.g., EBM-style or tree-based methods). Without these controls, the claim that TabDistill improves upon heuristic selection cannot be evaluated.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific foundation models and attribution methods employed, along with a one-sentence summary of the datasets and metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and will revise the paper to provide stronger empirical support, additional analyses, and direct comparisons. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results section: the claim that TabDistill yields 'consistent improvements' is unsupported by any reported numbers, baselines, statistical tests, or ablation details. Without these, it is impossible to determine whether the gains are robust, statistically significant, or merely artifacts of the foundation model's capacity.
Authors: We acknowledge that the abstract and results could more explicitly quantify the improvements. The manuscript reports predictive performance on multiple tabular datasets, showing gains from TabDistill interactions over GAMs without interactions. To address the concern, we will revise the Experimental Results section to include specific numerical deltas, comparisons against heuristic baselines, and statistical significance tests (e.g., paired t-tests across datasets and folds) demonstrating that the gains are robust rather than artifacts. revision: yes
-
Referee: [Method / Experiments] Method and Experiments sections: the central assumption that post-hoc attributions from the foundation model extract stable, additive interactions (rather than non-additive correlations) is not tested via stability checks across random seeds, attribution methods, or data splits. If attributions primarily reflect the foundation model's internal capacity instead of transferable additive structure, the distillation step adds no value beyond standard heuristics such as mutual information or tree-based pairwise selection.
Authors: This concern about stability and transferability is well-taken. The current version does not include explicit stability experiments. In the revision we will add analyses measuring consistency of the extracted interactions across random seeds, multiple attribution methods, and data splits. We will also report performance when substituting TabDistill interactions with standard heuristics (mutual information, tree-based selection) to quantify the incremental value of the distillation step. revision: yes
-
Referee: [Experiments] Experiments section: missing ablations that isolate the contribution of the tabular foundation model versus the choice of attribution technique, and direct comparisons against established GAM interaction-selection procedures (e.g., EBM-style or tree-based methods). Without these controls, the claim that TabDistill improves upon heuristic selection cannot be evaluated.
Authors: We agree that isolating components and benchmarking against established procedures is necessary. The experiments focus on end-to-end GAM performance with TabDistill interactions. We will expand the section with ablations that separately vary the foundation model and the attribution method, plus direct comparisons to EBM-style interaction selection and tree-based pairwise methods. These controls will allow readers to evaluate whether TabDistill provides gains beyond existing heuristics. revision: yes
Circularity Check
No significant circularity in TabDistill's empirical pipeline
full rationale
The paper describes an empirical method: fit a tabular foundation model to data, apply post-hoc attribution (e.g., SHAP or integrated gradients) to extract interactions, then insert those terms into a GAM and evaluate predictive performance. No equations appear that define the extracted interactions in terms of a fitted parameter from the same model, nor any 'prediction' that reduces by construction to a subset of the input data. The abstract and description contain no self-citations that serve as load-bearing uniqueness theorems or ansatzes. The central claim rests on downstream empirical gains rather than a derivation that loops back to its own inputs. This is a standard distillation pipeline with independent content; the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vahid Balazadeh, Hamidreza Kamkari, Valentin Thomas, Benson Li, Junwei Ma, Jesse C Cresswell, and Rahul G Krishnan. Causalpfn: Amortized causal effect estimation via in-context learning.arXiv preprint arXiv:2506.07918,
-
[2]
Brown, and Bin Yu
Sumanta Basu, Karl Kumbier, James B. Brown, and Bin Yu. Iterative random forests to discover predictive and stable high-order interactions.Proceedings of the National Academy of Sciences, 115(8):1943–1948, 2
1943
-
[3]
Proceedings of the National Academy of Sciences120(33) (2023) https://doi.org/10.1073/pnas
ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas. 1711236115. publisher: National Academy of Sciences section: Biological Sciences PMID: 29351989. K. Bouchiat, A. Immer, H. Y ˜Aˇsche, G. R¨atsch, and V . Fortuin. Improving neural additive models with bayesian principles. InProceedings of the 41st International Conference on Machine Learning (ICML), volume 235...
-
[4]
URLhttps://proceedings.mlr.press/v235/bouchiat24a.html. Landon Butler, Abhineet Agarwal, Justin Singh Kang, Yigit Efe Erginbas, Bin Yu, and Kannan Ramchandran. Proxyspex: Inference-efficient interpretability via sparse feature interactions in llms.arXiv preprint arXiv:2505.17495,
-
[5]
Black box causal inference: Effect estimation via meta prediction.arXiv:2503.05985, 2025
Lucius EJ Bynum, Aahlad Manas Puli, Diego Herrero-Quevedo, Nhi Nguyen, Carlos Fernandez-Granda, Kyunghyun Cho, and Rajesh Ranganath. Black box causal infer- ence: Effect estimation via meta prediction.arXiv preprint arXiv:2503.05985,
-
[6]
Giovanni Dispoto, Paolo Bonetti, and Marcello Restelli. ” so, tell me about your policy...”: Distillation of interpretable policies from deep reinforcement learning agents.arXiv preprint arXiv:2507.07848,
-
[7]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzm ¨uller, Prateek Mutalik Desai, David Salinas, and Frank Hutter. Tabarena: A living benchmark for machine learning on tabular data.arXiv preprint arXiv:2506.16791,
-
[8]
Human-ai co-design for clinical prediction models.arXiv preprint arXiv:2601.09072, 2026
Jean Feng, Avni Kothari, Patrick Vossler, Andrew Bishara, Lucas Zier, Newton Addo, Aaron Kornblith, Yan Shuo Tan, and Chandan Singh. Human-ai co-design for clinical prediction models.arXiv preprint arXiv:2601.09072,
-
[9]
doi: 10.1214/07-aoas148. 11 Preprint. Under review. Shantanu Ghosh, Ke Yu, and Kayhan Batmanghelich. Distilling blackbox to interpretable models for efficient transfer learning. InInternational Conference on Medical Image Comput- ing and Computer-Assisted Intervention, pp. 628–638. Springer,
-
[10]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
L´eo Grinsztajn, Klemens Fl¨oge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Ben- jamin J¨ager, Dominik Safaric, Simone Alessi, Adrian Hayler, et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models.arXiv preprint arXiv:2511.08667,
work page internal anchor Pith review arXiv
-
[11]
Hyeongrok Han, Siwon Kim, Hyun-Soo Choi, and Sungroh Yoon. On the impact of knowl- edge distillation for model interpretability.arXiv preprint arXiv:2305.15734,
-
[12]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel M ¨uller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second.arXiv preprint arXiv:2207.01848,
work page internal anchor Pith review arXiv
-
[13]
Foundation models for causal inference via prior-data fitted networks, 2025
Yuchen Ma, Dennis Frauen, Emil Javurek, and Stefan Feuerriegel. Foundation models for causal inference via prior-data fitted networks.arXiv preprint arXiv:2506.10914,
-
[14]
Gamformer: In-context learning for generalized additive models.arXiv preprint arXiv:2410.04560, 2024
Andreas Mueller, Julien Siems, Harsha Nori, David Salinas, Arber Zela, Rich Caruana, and Frank Hutter. Gamformer: In-context learning for generalized additive models.arXiv preprint arXiv:2410.04560,
-
[15]
arXiv preprint arXiv:1909.09223 , year=
12 Preprint. Under review. Harsha Nori, Samuel Jenkins, Paul Koch, and Rich Caruana. InterpretML: A unified framework for machine learning interpretability.arXiv preprint arXiv:1909.09223,
-
[16]
Olson, William La Cava, Patryk Orzechowski, Ryan J
ISSN 1756-0381. doi: 10.1186/s13040-017-0154-4. URLhttps://doi.org/10.1186/s13040-017-0154-4. Maxime Peyrard and Kyunghyun Cho. Meta-statistical learning: Supervised learning of statistical inference.arXiv preprint arXiv:2502.12088,
-
[17]
Jingang Qu, David Holzm ˜Aˇzller, Gael Varoquaux, and Marine Le Morvan. Tabicl: A tabular foundation model for in-context learning on large data.arXiv preprint arXiv:2502.05564,
-
[18]
Do-pfn: In-context learning for causal effect estimation.arXiv preprint arXiv:2506.06039, 2025
Jake Robertson, Arik Reuter, Siyuan Guo, Noah Hollmann, Frank Hutter, and Bernhard Sch¨olkopf. Do-pfn: In-context learning for causal effect estimation.arXiv preprint arXiv:2506.06039,
-
[19]
pyGAM: Generalized Additive Models in Python
Daniel Serv´en and Charlie Brummitt. pyGAM: Generalized Additive Models in Python. URL:https://zenodo.org/records/1476122,
-
[20]
Jacob Si, Wendy Yusi Cheng, Michael Cooper, and Rahul G Krishnan. Interpretabnet: Distilling predictive signals from tabular data by salient feature interpretation.arXiv preprint arXiv:2406.00426,
-
[21]
Distill-and-Compare: Auditing black- box models using transparent model distillation
Sarah Tan, Rich Caruana, Giles Hooker, and Yin Lou. Distill-and-Compare: Auditing black- box models using transparent model distillation. InProceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, pp. 303–310,
2018
-
[22]
arXiv:1705.04977 [cs, stat] , author =
Michael Tsang, Dehua Cheng, and Yan Liu. Detecting statistical interactions from neural network weights.arXiv preprint arXiv:1705.04977,
-
[23]
Zijie J Wang, Alex Kale, Harsha Nori, Peter Stella, Mark Nunnally, Duen Horng Chau, Mi- haela Vorvoreanu, Jennifer Wortman Vaughan, and Rich Caruana. Gam changer: Editing generalized additive models with interactive visualization.arXiv preprint arXiv:2112.03245,
-
[24]
Under review
13 Preprint. Under review. Shiyun Xu, Zhiqi Bu, Pratik Chaudhari, and Ian J Barnett. Sparse neural additive model: Interpretable deep learning with feature selection via group sparsity. InICLR 2022 Workshop on P AIR 2Struct: Privacy, Accountability, Interpretability, Robustness, Reasoning on Structured Data,
2022
-
[25]
Xiaoyu Yang, Qiujia Li, Chao Zhang, and Philip C Woodland. Knowledge distillation from multiple foundation models for end-to-end speech recognition.arXiv preprint arXiv:2303.10917,
-
[26]
A closer look at deep learning methods on tabular datasets, 2025
Han-Jia Ye, Si-Yang Liu, Hao-Run Cai, Qi-Le Zhou, and De-Chuan Zhan. A closer look at deep learning methods on tabular datasets.arXiv preprint arXiv:2407.00956,
-
[27]
Learning a decision tree algorithm with transformers.arXiv preprint arXiv:2402.03774, 2024
Yufan Zhuang, Liyuan Liu, Chandan Singh, Jingbo Shang, and Jianfeng Gao. Learning a decision tree algorithm with transformers.arXiv preprint arXiv:2402.03774,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.