Recognition: unknown
AeTHERON: Autoregressive Topology-aware Heterogeneous Graph Operator Network for Fluid-Structure Interaction
Pith reviewed 2026-05-10 12:36 UTC · model grok-4.3
The pith
AeTHERON mirrors immersed boundary stencils in a dual-graph operator to extrapolate fluid-structure vortex flows with mean error 0.168.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
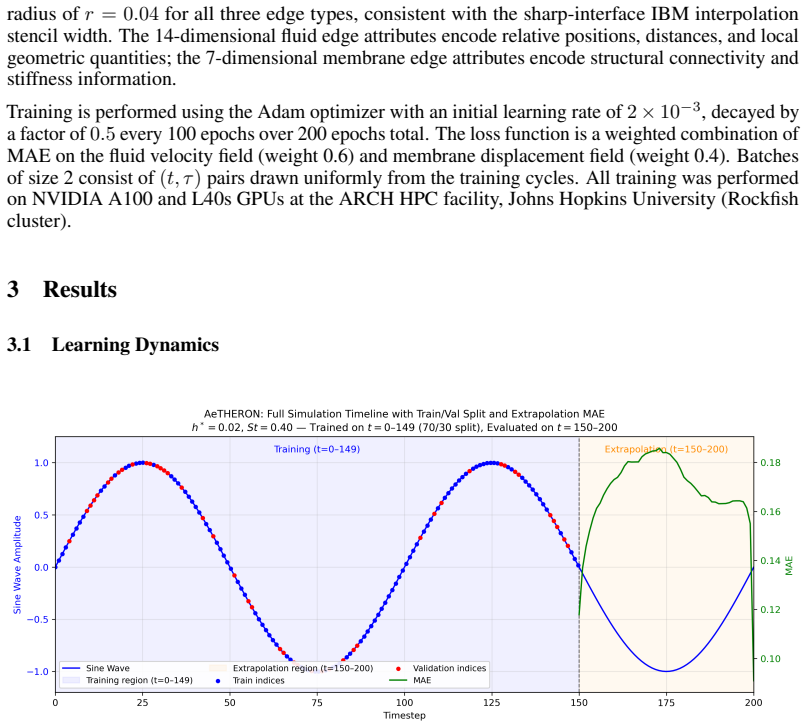
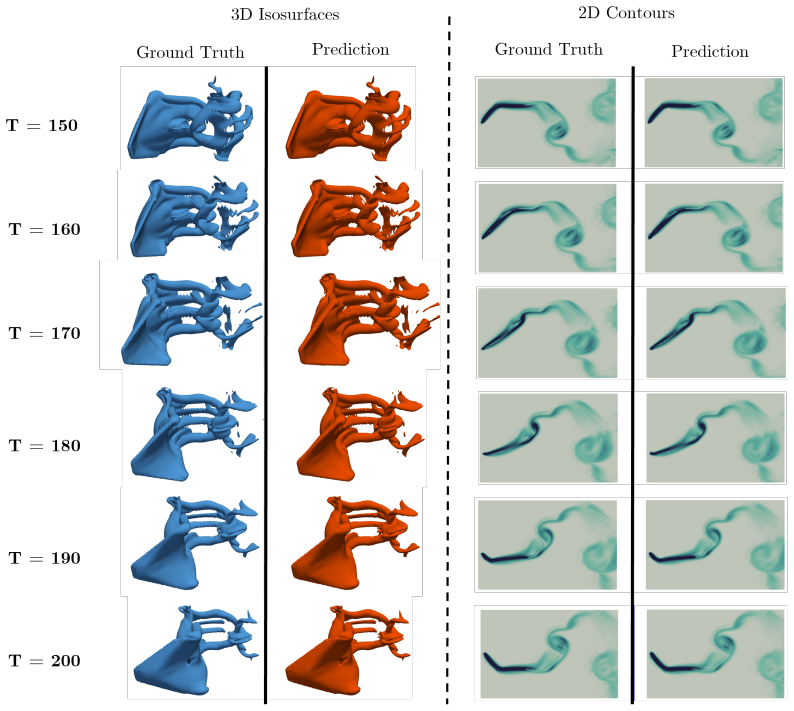
AeTHERON is a heterogeneous graph neural operator whose dual-graph representation separates fluid and structural domains and couples them through sparse cross-attention that directly reflects the compact support of immersed boundary method stencils, together with sinusoidal time embeddings, so that training on the first 150 timesteps of a flapping flexible caudal fin simulation allows autoregressive extrapolation to later times with a mean absolute error of 0.168 while preserving large-scale vortex topology and wake structure across a 4x5 grid of membrane thickness and Strouhal number.
What carries the argument
Dual-graph representation of fluid and structure coupled by sparse cross-attention that copies immersed boundary method stencil support, placed inside a shared latent space with continuous time embeddings.
If this is right
- The model produces millisecond-per-timestep inference on GPU while matching the qualitative vortex and wake features of full direct numerical simulation.
- Error remains bounded at 0.168 mean absolute value when extrapolating 50 timesteps beyond the training window without any retraining.
- Prediction error peaks at flapping half-cycle transitions, matching the physical times of fastest flow reorganization.
- Continuous sinusoidal time embeddings allow the same weights to handle arbitrary lead times after the initial 150 steps.
- The same trained weights work across the full 4x5 grid of membrane thickness and Strouhal number values.
Where Pith is reading between the lines
- The same stencil-mirroring cross-attention pattern could be reused for other multiphysics problems that involve immersed moving interfaces.
- Rapid parameter sweeps in bio-inspired propulsion design become feasible once a single short training segment is available.
- Hybrid schemes could combine this operator with occasional full simulations at the high-error transition points to maintain long-term accuracy.
- The approach suggests that embedding known numerical stencil geometry into graph attention layers may stabilize autoregressive predictions in other chaotic flow regimes.
Load-bearing premise
The dual-graph architecture with IBM-mirroring sparse cross-attention and sinusoidal time embeddings supplies enough inductive bias for reliable autoregressive rollout in chaotic unsteady flows past the short training window.
What would settle it
Running the trained model on a new flapping frequency or membrane thickness outside the 4x5 grid and observing rapid growth in wake error or loss of vortex topology within 20 timesteps would show the inductive bias is insufficient.
Figures





read the original abstract
Surrogate modeling of body-driven fluid flows where immersed moving boundaries couple structural dynamics to chaotic, unsteady fluid phenomena remains a fundamental challenge for both computational physics and machine learning. We present AeTHERON, a heterogeneous graph neural operator whose architecture directly mirrors the structure of the sharp-interface immersed boundary method (IBM): a dual-graph representation separating fluid and structural domains, coupled through sparse cross-attention that reflects the compact support of IBM interpolation stencils. This physics-informed inductive bias enables AeTHERON to learn nonlinear fluid-structure coupling in a shared high-dimensional latent space, with continuous sinusoidal time embeddings providing temporal generalization across lead times. We evaluate AeTHERON on direct numerical simulations of a flapping flexible caudal fin, a canonical FSI benchmark featuring leading-edge vortex formation, large membrane deformation, and chaotic wake shedding across a 4x5 parameter grid of membrane thickness (h* = 0.01-0.04) and Strouhal number (St = 0.30-0.50). As a proof-of-concept, we train on the first 150 timesteps of a representative case using a 70/30 train/validation split and evaluate on the fully unseen extrapolation window t=150-200. AeTHERON captures large-scale vortex topology and wake structure with qualitative fidelity, achieving a mean extrapolation MAE of 0.168 without retraining, with error peaking near flapping half-cycle transitions where flow reorganization is most rapid -- a physically interpretable pattern consistent with the nonlinear fluid-membrane coupling. Inference requires milliseconds per timestep on a single GPU versus hours for equivalent DNS computation. This is a continuously developing preprint; results and figures will be updated in subsequent versions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AeTHERON, a heterogeneous graph neural operator for surrogate modeling of fluid-structure interaction in flapping flexible caudal fin flows. Its architecture uses a dual-graph representation (fluid and structure domains) coupled by sparse cross-attention that mirrors immersed-boundary stencils, plus sinusoidal time embeddings for temporal generalization. Trained on the first 150 timesteps of one representative DNS case (70/30 split), it is evaluated autoregressively on the unseen window t=150-200 and claims to capture large-scale vortex topology with qualitative fidelity while achieving a mean extrapolation MAE of 0.168 without retraining across the full 4x5 (h*, St) benchmark grid.
Significance. A validated architecture that supplies sufficient inductive bias for stable, long-horizon extrapolation in chaotic unsteady FSI would be a useful contribution to physics-informed surrogate modeling, especially given the reported millisecond-per-timestep inference speed relative to DNS. The explicit mapping of the dual-graph and cross-attention to IBM stencils is a clear strength if it demonstrably improves generalization.
major comments (3)
- [Abstract] Abstract: the central claim that AeTHERON achieves the reported performance 'across a 4x5 parameter grid' without retraining is unsupported. The methods description states that training (70/30 split on first 150 timesteps) and evaluation (t=150-200 rollout) were performed exclusively on 'a representative case'; no per-parameter or aggregate quantitative results are shown for the remaining 19 combinations of h* and St.
- [Abstract] Abstract and Results: the single reported mean extrapolation MAE of 0.168 is given only for one case. In chaotic unsteady FSI, vortex topology and wake shedding vary sharply with h* and St; therefore the single-case metric does not establish that the dual-graph + sparse cross-attention + sinusoidal embedding inductive bias suffices for the full benchmark.
- [Abstract] Abstract: no baseline comparisons (standard GNN operators, PINNs, or other FSI surrogates), error bars, or quantitative results across the parameter grid are provided, and details on training procedure, loss, stability, or hyper-parameters are absent, preventing assessment of whether the claimed inductive bias is responsible for the observed behavior.
minor comments (1)
- [Abstract] Abstract: the statement that this is a 'continuously developing preprint; results and figures will be updated' is atypical for a submitted manuscript and should be removed or clarified.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important clarifications needed in this early-stage preprint. We agree that the abstract overstates the current scope of results and will revise it to accurately reflect the proof-of-concept nature of the work on a single representative case. The core architectural contributions remain as described, but we will improve transparency regarding limitations and planned extensions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that AeTHERON achieves the reported performance 'across a 4x5 parameter grid' without retraining is unsupported. The methods description states that training (70/30 split on first 150 timesteps) and evaluation (t=150-200 rollout) were performed exclusively on 'a representative case'; no per-parameter or aggregate quantitative results are shown for the remaining 19 combinations of h* and St.
Authors: We agree that the abstract phrasing is ambiguous and can be read as claiming quantitative performance across the full grid. The 4x5 grid is the benchmark from which the DNS data were drawn, but the reported training, autoregressive evaluation, MAE of 0.168, and qualitative vortex capture are strictly for one representative case. The phrase 'without retraining' refers to temporal extrapolation on unseen timesteps within that case. We will revise the abstract to explicitly state the single-case scope and note that full-grid evaluation is planned for future versions. This is a textual clarification only. revision: yes
-
Referee: [Abstract] Abstract and Results: the single reported mean extrapolation MAE of 0.168 is given only for one case. In chaotic unsteady FSI, vortex topology and wake shedding vary sharply with h* and St; therefore the single-case metric does not establish that the dual-graph + sparse cross-attention + sinusoidal embedding inductive bias suffices for the full benchmark.
Authors: We concur that a single-case result cannot demonstrate parameter-space generalization, given the known sensitivity of vortex dynamics to h* and St. The manuscript presents these results as an initial proof-of-concept for stable long-horizon rollout in a representative chaotic FSI problem, with error patterns that align with physical expectations (peaking at half-cycle transitions). We will revise the abstract and results to clearly delimit the scope and state that quantitative multi-parameter validation is ongoing work. We do not claim the inductive bias has been proven sufficient for the full grid at this stage. revision: yes
-
Referee: [Abstract] Abstract: no baseline comparisons (standard GNN operators, PINNs, or other FSI surrogates), error bars, or quantitative results across the parameter grid are provided, and details on training procedure, loss, stability, or hyper-parameters are absent, preventing assessment of whether the claimed inductive bias is responsible for the observed behavior.
Authors: The full manuscript contains a methods section with training details (70/30 split, MAE loss on velocity/pressure fields, sinusoidal embeddings, autoregressive rollout procedure, and stability observations). However, we agree these should be summarized more prominently. We will add a concise training description to the abstract and include error bars or run-to-run variance for the reported case. Baseline comparisons and full-grid quantitative results are not present in the current version; we will incorporate them in the revision where feasible through additional experiments. This addresses the assessment concern without altering the presented proof-of-concept. revision: partial
Circularity Check
No circularity: model trained on external DNS data with held-out temporal extrapolation
full rationale
The paper trains AeTHERON on DNS simulation data using a 70/30 split of the first 150 timesteps and evaluates autoregressive rollout on unseen later timesteps (t=150-200). No equations, parameters, or self-citations reduce the reported MAE or vortex-capture claim to a fitted input by construction. The architecture (dual-graph IBM mirroring, sparse cross-attention, sinusoidal embeddings) is presented as an inductive bias choice rather than a tautological redefinition of the target quantities. The single-case proof-of-concept evaluation does not collapse into the training data itself, and no load-bearing uniqueness theorem or ansatz is imported from prior self-work. This is a standard data-driven surrogate setup with external ground truth.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural operator: Graph kernel network for partial differential equations
Anima Anandkumar, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Nikola Kovachki, Zongyi Li, Burigede Liu, and Andrew Stuart. Neural operator: Graph kernel network for partial differential equations. InICLR 2020 workshop on integration of deep neural models and differential equations,
2020
-
[2]
Multiscale MeshGraphNets.arXiv preprint arXiv:2210.00612,
Meire Fortunato, Tobias Pfaff, Peter Wirnsberger, Alexander Pritzel, and Peter Battaglia. Multiscale meshgraphnets.arXiv preprint arXiv:2210.00612,
-
[3]
Nicola Rares Franco, Stefania Fresca, Federico Tombari, and Andrea Manzoni. Deep learning-based surrogate models for parametrized pdes: Handling geometric variability through graph neural networks.arXiv preprint arXiv:2308.01602,
-
[4]
Rui Gao, Zijie Cheng, and Rajeev K Jaiman. Data-driven modeling of fluid flow around rotating structures with graph neural networks.arXiv preprint arXiv:2503.22252,
-
[5]
Flow-induced dorso-ventral deformation enhances propulsive efficiency in flexible caudal fins.Bioinspiration & Biomimetics, 21(1):016027, 2026a
Sushrut Kumar, Matthew J McHenry, Jung-Hee Seo, and Rajat Mittal. Flow-induced dorso-ventral deformation enhances propulsive efficiency in flexible caudal fins.Bioinspiration & Biomimetics, 21(1):016027, 2026a. Sushrut Kumar, Joshua Romero, Jung-Hee Seo, Massimiliano Fatica, and Rajat Mittal. A gpu- accelerated sharp interface immersed boundary solver for...
2026
-
[6]
Freeman scholar lecture (2021)—sharp-interface immersed boundary methods in fluid dynamics.Journal of Fluids Engineering, 147(3):030801,
Rajat Mittal, Jung-Hee Seo, Jacob Turner, Sushrut Kumar, Suryansh Prakhar, and Ji Zhou. Freeman scholar lecture (2021)—sharp-interface immersed boundary methods in fluid dynamics.Journal of Fluids Engineering, 147(3):030801,
2021
-
[7]
Sepehr Mousavi, Shizheng Wen, Levi Lingsch, Maximilian Herde, Bogdan Raoni´c, and Siddhartha Mishra. Rigno: A graph-based framework for robust and accurate operator learning for pdes on arbitrary domains.arXiv preprint arXiv:2501.19205,
-
[8]
Mohammad Amin Nabian and Sanjay Choudhry. A mixture of experts gating network for enhanced surrogate modeling in external aerodynamics.arXiv preprint arXiv:2508.21249,
-
[9]
Data-efficient time-dependent pde surrogates: Graph neural simulators vs
Dibyajyoti Nayak, Qingwen Zhang, Tamer A Yousif, Liang Zhang, and Peyman Givi. Data-efficient time-dependent pde surrogates: Graph neural simulators vs. neural operators.arXiv preprint arXiv:2509.06154,
-
[10]
State space neural operator.arXiv preprint arXiv:2507.23428,
Levi Nguyen, Matthew Wellborn, and Benjamin Peherstorfer. State space neural operator.arXiv preprint arXiv:2507.23428,
-
[11]
Rishikesh Ranade, Mohammad Amin Nabian, Kaustubh Tangsali, Alexey Kamenev, Oliver Hennigh, Ram Cherukuri, and Sanjay Choudhry. Domino: A decomposable multi-scale iterative neural operator for modeling large scale engineering simulations.arXiv preprint arXiv:2501.13350,
-
[12]
Gpu accelerated digital twins of the human heart open new routes for cardiovascular research.Scientific reports, 13 (1):8230, 2023a
Francesco Viola, Giulio Del Corso, Ruggero De Paulis, and Roberto Verzicco. Gpu accelerated digital twins of the human heart open new routes for cardiovascular research.Scientific reports, 13 (1):8230, 2023a. Francesco Viola, Giulio Del Corso, and Roberto Verzicco. High-fidelity model of the human heart: an immersed boundary implementation.Physical Review...
2022
-
[13]
Equivariant graph neural operator for modeling 3d dynamics.arXiv preprint arXiv:2401.11037,
Minkai Xu, Jiaqi Han, Aaron Lou, Jean Kossaifi, Arvind Ramanathan, Kamyar Azizzadenesheli, Jure Leskovec, Stefano Ermon, and Anima Anandkumar. Equivariant graph neural operator for modeling 3d dynamics.arXiv preprint arXiv:2401.11037,
-
[14]
URLhttps://doi.org/10.1088/1748-3190/ad3a4e
doi: 10.1088/ 1748-3190/ad3a4e. URLhttps://doi.org/10.1088/1748-3190/ad3a4e. Ji Zhou, Jung-Hee Seo, and Rajat Mittal. Effect of hydrodynamic wakes in dynamical models of large-scale fish schools.Physics of Fluids, 37(1), 2025a. Ji Zhou, Jung-Hee Seo, and Rajat Mittal. Hydrodynamically beneficial school configurations in carangiform swimmers: insights from...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.