Recognition: unknown
Constraint-based Pre-training: From Structured Constraints to Scalable Model Initialization
Pith reviewed 2026-05-10 12:03 UTC · model grok-4.3
The pith
Structured constraints during pre-training disentangle size-independent knowledge into reusable weight templates that initialize models at arbitrary depths and widths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Model parameters are expressed as compositions of weight templates formed by concatenation and weighted aggregation, with the connections between templates governed by lightweight weight scalers whose values are learned from limited downstream data. Kronecker-based constraints regularize the pre-training process so that the templates capture size-agnostic knowledge while the scalers absorb size-specific adaptation, turning variable-scale initialization into a multi-task adaptation problem.
What carries the argument
Kronecker-based constraints that enforce decomposition of parameters into reusable weight templates and lightweight size-specific scalers.
If this is right
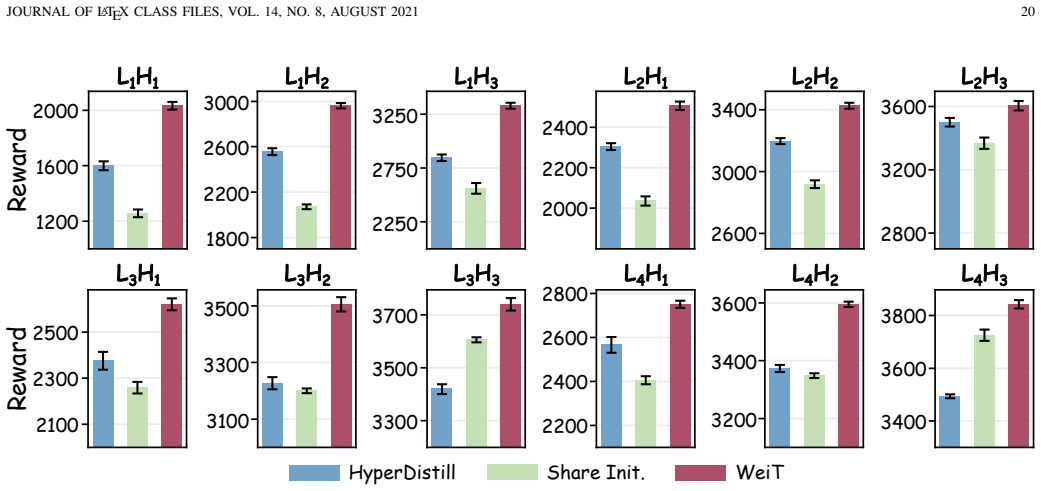
- A single pre-training run produces components that can be assembled into models of many different depths and widths.
- Initialized models reach higher final performance and converge faster than random initialization or simple resizing across image classification, generation, and embodied control tasks.
- The same template-based construction works for both Transformer and convolution architectures.
- Even when the downstream model is trained from scratch rather than fine-tuned, the constrained initialization still improves results.
Where Pith is reading between the lines
- A library of templates could be shared across many tasks or domains, with only the scalers retrained for each new setting.
- The decomposition might make it easier to prune or compress models after initialization because the templates already isolate reusable structure.
- One could test whether the templates remain effective when transferred to an entirely different architecture family not seen during pre-training.
Load-bearing premise
The constraints can separate size-independent knowledge into templates and size-dependent adjustments into scalers without lowering the final performance of the resulting models.
What would settle it
A model pre-trained under the constraints performs worse on a fixed-scale downstream task than a standard pre-trained model of the same size, or variable-scale models assembled from the templates converge more slowly or reach lower accuracy than models trained directly at those target sizes.
Figures












read the original abstract
The pre-training and fine-tuning paradigm has become the dominant approach for model adaptation. However, conventional pre-training typically yields models at a fixed scale, whereas practical deployment often requires models of varying sizes, exposing its limitations when target model scales differ from those used during pre-training. To address this, we propose an innovative constraint-based pre-training paradigm that imposes structured constraints during pre-training to disentangle size-agnostic knowledge into reusable weight templates, while assigning size-specific adaptation to lightweight weight scalers, thereby reformulating variable-sized model initialization as a multi-task adaptation problem. Within this paradigm, we further introduce WeiT, which employs Kronecker-based constraints to regularize the pre-training process. Specifically, model parameters are represented as compositions of weight templates via concatenation and weighted aggregation, with adaptive connections governed by lightweight weight scalers whose parameters are learned from limited data. This design enables flexible and efficient construction of model weights across diverse downstream scales. Extensive experiments demonstrate the efficiency and effectiveness of WeiT, achieving state-of-the-art performance in initializing models with varying depths and widths across a broad range of perception and embodied learning tasks, including Image Classification, Image Generation, and Embodied Control. Moreover, its effectiveness generalizes to both Transformer-based and Convolution-based architectures, consistently enabling faster convergence and improved performance even under full training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a constraint-based pre-training paradigm called WeiT that imposes Kronecker-based structured constraints during pre-training. This is intended to disentangle size-agnostic knowledge into reusable weight templates (via concatenation and weighted aggregation) while isolating size-specific adaptations in lightweight weight scalers learned from limited data. The approach reformulates variable-sized model initialization as a multi-task adaptation problem and is claimed to generalize across Transformer and convolution architectures. Extensive experiments are asserted to show SOTA performance, faster convergence, and improved results on image classification, image generation, and embodied control tasks for models of varying depths and widths.
Significance. If the central claims hold, the work could meaningfully advance scalable model initialization by reducing the need for scale-specific pre-training. The idea of using structured constraints to separate reusable templates from lightweight adapters addresses a practical deployment gap. However, the absence of any experimental details, baselines, ablations, or analysis in the provided text makes it impossible to evaluate whether the Kronecker structure actually delivers the claimed disentanglement without expressivity loss.
major comments (2)
- [Abstract] Abstract: The central claim that Kronecker-based constraints produce reusable templates capturing size-agnostic knowledge (with all size variation isolated in lightweight scalers) is load-bearing, yet the text provides no ablation, theoretical argument, or analysis showing that the rigid block-repeated scaling pattern of the Kronecker product is sufficient rather than merely convenient. Without this, it is unclear whether the templates generalize or whether the scalers must compensate by becoming non-lightweight, violating the efficiency premise.
- [Abstract] Abstract: The assertion of 'extensive experiments' achieving SOTA performance across perception and embodied tasks provides no baselines, metrics, error bars, statistical tests, or comparison to standard pre-training/fine-tuning, making it impossible to verify support for the effectiveness and generalization claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major concerns point by point below, acknowledging where the current text falls short and outlining the revisions we will make to strengthen the support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Kronecker-based constraints produce reusable templates capturing size-agnostic knowledge (with all size variation isolated in lightweight scalers) is load-bearing, yet the text provides no ablation, theoretical argument, or analysis showing that the rigid block-repeated scaling pattern of the Kronecker product is sufficient rather than merely convenient. Without this, it is unclear whether the templates generalize or whether the scalers must compensate by becoming non-lightweight, violating the efficiency premise.
Authors: We agree that the abstract, as currently written, does not include the requested theoretical argument or ablations to substantiate the central claim. The provided manuscript text is limited to the abstract and therefore lacks these elements. In the revised version, we will add a dedicated subsection deriving the suitability of the Kronecker structure from its algebraic properties (specifically, how the block-repeated scaling isolates scale-specific factors without altering the core template patterns). We will also include ablations contrasting the Kronecker constraint against unstructured scaling and alternative factorizations, with measurements confirming that the weight scalers remain lightweight (parameter overhead independent of model size) while templates generalize across depths and widths. These additions will be summarized with a brief reference in the abstract. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'extensive experiments' achieving SOTA performance across perception and embodied tasks provides no baselines, metrics, error bars, statistical tests, or comparison to standard pre-training/fine-tuning, making it impossible to verify support for the effectiveness and generalization claims.
Authors: We concur that the abstract provides no concrete experimental details, baselines, or quantitative results, rendering the effectiveness claims unverifiable from the current text alone. The manuscript as provided consists only of the abstract and therefore contains none of the requested information. In the revision, we will expand the paper with a full experimental section detailing the baselines (standard fixed-scale pre-training followed by adaptation, random initialization, and related scalable methods), the exact metrics used (top-1 accuracy, FID, task success rates), error bars from repeated runs, and statistical comparisons. We will also update the abstract with a concise statement of the main quantitative outcomes and generalization results across architectures. revision: yes
Circularity Check
No significant circularity; new constraint-based paradigm is self-contained
full rationale
The paper defines a novel pre-training approach (WeiT) that imposes Kronecker-based constraints to represent parameters as compositions of weight templates via concatenation and weighted aggregation, with size-specific adaptations handled by lightweight scalers. This is presented as an architectural and training choice rather than a derived prediction. Effectiveness is asserted via empirical results on image classification, generation, and control tasks for varying model scales, without any reduction of claims to quantities defined by the method's own fitted parameters or self-citations. The derivation chain consists of proposal followed by validation, remaining independent of the input data or prior fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Parameter-efficient fine-tuning of large-scale pre-trained language models,
N. Ding, Y . Qin, G. Yang, F. Wei, Z. Yang, Y . Su, S. Hu, Y . Chen, C.-M. Chanet al., “Parameter-efficient fine-tuning of large-scale pre-trained language models,”Nat. Mach. Intell., vol. 5, no. 3, pp. 220–235, 2023
2023
-
[2]
A survey on vision transformer,
K. Han, Y . Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y . Tang, A. Xiao, C. Xu, Y . Xuet al., “A survey on vision transformer,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 1, pp. 87–110, 2022
2022
-
[3]
Foundation models defining a new era in vision: a survey and outlook,
M. Awais, M. Naseer, S. Khan, R. M. Anwer, H. Cholakkal, M. Shah, M.-H. Yang, and F. S. Khan, “Foundation models defining a new era in vision: a survey and outlook,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 4, pp. 2245–2264, 2025
2025
-
[4]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInt. Conf. Learn. Represent. (ICLR’21), 2021, pp. 1–12
2021
-
[5]
Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” inInt. Conf. Learn. Represent. (ICLR’16), 2016
2016
-
[6]
Efficientnet: Rethinking model scaling for convo- lutional neural networks,
M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for convo- lutional neural networks,” inInt. Conf. Mach. Learn. (ICML’19), 2019, pp. 6105–6114
2019
-
[7]
Minivit: Compressing vision transformers with weight multiplexing,
J. Zhang, H. Peng, K. Wu, M. Liu, B. Xiao, J. Fu, and L. Yuan, “Minivit: Compressing vision transformers with weight multiplexing,” inIEEE Conf. Comput. Vis. Pattern Recog. (CVPR’22), 2022, pp. 12 145–12 154
2022
-
[8]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massaet al., “Training data-efficient image transformers & distillation through attention,” inInt. Conf. Mach. Learn. (ICML’21), 2021, pp. 10 347–10 357
2021
-
[9]
Learning to grow pretrained models for efficient transformer training,
P. Wang, R. Panda, L. T. Hennigen, P. Greengard, L. Karlinsky, R. Feris et al., “Learning to grow pretrained models for efficient transformer training,” inInt. Conf. Learn. Represent. (ICLR’23), 2023, pp. 1–13
2023
-
[10]
Initializing models with larger ones,
Z. Xu, Y . Chen, K. Vishniakov, Y . Yin, Z. Shen, T. Darrell, L. Liu, and Z. Liu, “Initializing models with larger ones,” inInt. Conf. Learn. Represent. (ICLR’23), 2024, pp. 1–13
2024
-
[11]
A unified framework for knowledge transfer in bidirectional model scaling,
J. Shen, F. Feng, J. Xu, Y . Xie, J. Lv, and X. Geng, “A unified framework for knowledge transfer in bidirectional model scaling,” inIEEE Conf. Comput. Vis. Pattern Recog. (CVPR’26), 2026, pp. 1–9
2026
-
[12]
A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations,
H. Cheng, M. Zhanget al., “A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, pp. 10 558–10 578, 2024
2024
-
[13]
Isomorphic pruning for vision models,
G. Fang, X. Ma, M. B. Mi, and X. Wang, “Isomorphic pruning for vision models,” inEur. Conf. Comput. Vis. (ECCV’24), 2024, pp. 232–250
2024
-
[14]
Bk-sdm: A lightweight, fast, and cheap version of stable diffusion,
B.-K. Kim, H.-K. Song, T. Castells, and S. Choi, “Bk-sdm: A lightweight, fast, and cheap version of stable diffusion,” inEur. Conf. Comput. Vis. (ECCV’24), 2024, pp. 381–399
2024
-
[15]
Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,
L. Wang and K.-J. Yoon, “Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 6, pp. 3048–3068, 2021
2021
-
[16]
Knowledge distillation: A survey,
J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,”Int. J. Comput. Vis., vol. 129, no. 6, pp. 1789–1819, 2021
2021
-
[17]
Growing a brain: Fine-tuning by increasing model capacity,
Y .-X. Wang, D. Ramanan, and M. Hebert, “Growing a brain: Fine-tuning by increasing model capacity,” inIEEE Conf. Comput. Vis. Pattern Recog. (CVPR’17), 2017, pp. 2471–2480
2017
-
[18]
Measuring and improving consistency in pretrained language models,
Y . Elazar, N. Kassner, S. Ravfogel, A. Ravichander, E. Hovyet al., “Measuring and improving consistency in pretrained language models,” Trans. Assoc. Comput. Linguist., vol. 9, pp. 1012–1031, 2021
2021
-
[19]
Cs-bert: a pretrained model for customer service dialogues,
P. Wang, J. Fang, and J. Reinspach, “Cs-bert: a pretrained model for customer service dialogues,” in3rd Workshop on NLP for Conversational AI, 2021, pp. 130–142
2021
-
[20]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” in Int. Conf. Learn. Represent. (ICLR’22), 2022, pp. 1–13
2022
-
[21]
Learning a universal template for few-shot dataset generalization,
E. Triantafillou, H. Larochelle, R. Zemel, and V . Dumoulin, “Learning a universal template for few-shot dataset generalization,” inInt. Conf. Mach. Learn. (ICML’21), 2021, pp. 10 424–10 433
2021
-
[22]
G. H. Golubet al.,Matrix computations. JHU press, 2013
2013
-
[23]
Some mathematical notes on three-mode factor analysis,
L. R. Tucker, “Some mathematical notes on three-mode factor analysis,” Psychometrika, vol. 31, no. 3, pp. 279–311, 1966
1966
-
[24]
Kronecker products and matrix calculus in system theory,
J. Brewer, “Kronecker products and matrix calculus in system theory,” IEEE Trans. Circuits Syst., vol. 25, no. 9, pp. 772–781, 2003
2003
-
[25]
Wave: Weight template for adaptive initialization of variable-sized models,
F. Feng, Y . Xie, J. Wang, and X. Geng, “Wave: Weight template for adaptive initialization of variable-sized models,” inIEEE Conf. Comput. Vis. Pattern Recog. (CVPR’25), 2025, pp. 4819–4828
2025
-
[26]
Once-for-all: Train one network and specialize it for efficient deployment,
H. Cai, C. Gan, T. Wang, Z. Zhang, and S. Han, “Once-for-all: Train one network and specialize it for efficient deployment,” inInt. Conf. Learn. Represent. (ICLR’20), 2020. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
2020
-
[27]
A review on weight initialization strategies for neural networks,
M. V . Narkhede, P. P. Bartakke, and M. S. Sutaone, “A review on weight initialization strategies for neural networks,”Artif. Intell. Rev., vol. 55, no. 1, pp. 291–322, 2022
2022
-
[28]
How to initialize your network? robust initialization for weightnorm & resnets,
D. Arpit, V . Campos, and Y . Bengio, “How to initialize your network? robust initialization for weightnorm & resnets,”Adv. Neural Inform. Process. Syst. (NeurIPS’19), vol. 32, 2019
2019
-
[29]
Improving transformer optimization through better initialization,
X. S. Huang, F. Perez, J. Ba, and M. V olkovs, “Improving transformer optimization through better initialization,” inInt. Conf. Mach. Learn. (ICML’20), 2020, pp. 4475–4483
2020
-
[30]
Understanding the difficulty of training deep feedforward neural networks,
X. Glorot and Y . Bengio, “Understanding the difficulty of training deep feedforward neural networks,” inInt. Conf. Artif. Intell. Stat. (AISTATS’10), 2010, pp. 249–256
2010
-
[31]
An empirical study of training self- supervised vision transformers,
X. Chen, S. Xie, and K. He, “An empirical study of training self- supervised vision transformers,” inInt. Conf. Comput. Vis. (ICCV’21), 2021, pp. 9640–9649
2021
-
[32]
Rethinking pre-training and self-training,
B. Zoph, G. Ghiasi, T.-Y . Lin, Y . Cui, H. Liu, E. D. Cubuk, and Q. Le, “Rethinking pre-training and self-training,” inAdv. Neural Inform. Process. Syst. (NeurIPS’20), 2020, pp. 3833–3845
2020
-
[33]
Mimetic initialization of self-attention layers,
A. Trockman and J. Z. Kolter, “Mimetic initialization of self-attention layers,” inInt. Conf. Mach. Learn. (ICML’23), 2023, pp. 34 456–34 468
2023
-
[34]
Learngene: From open-world to your learning task,
Q. Wang, X. Geng, S. Lin, S.-Y . Xia, L. Qi, and N. Xu, “Learngene: From open-world to your learning task,” inAAAI Conf. Artif. Intell. (AAAI’22), 2022, pp. 8557–8565
2022
-
[35]
A theory for multiresolution signal decomposition: the wavelet representation,
S. G. Mallat, “A theory for multiresolution signal decomposition: the wavelet representation,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 11, no. 7, pp. 674–693, 2002
2002
-
[36]
Distilling morphology- conditioned hypernetworks for efficient universal morphology control,
Z. Xiong, R. Vuorio, J. Beck, M. Zimmeret al., “Distilling morphology- conditioned hypernetworks for efficient universal morphology control,” inInt. Conf. Mach. Learn. (ICML’24), 2024, pp. 54 777–54 791
2024
-
[37]
Al- bert: A lite bert for self-supervised learning of language representations,
Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “Al- bert: A lite bert for self-supervised learning of language representations,” inInt. Conf. Learn. Represent. (ICLR’20), 2020, pp. 1–14
2020
-
[38]
Transformer as linear expansion of learngene,
S. Xia, M. Zhanget al., “Transformer as linear expansion of learngene,” inAAAI Conf. Artif. Intell. (AAAI’24), 2024, pp. 16 014–16 022
2024
-
[39]
Exploring learngene via stage-wise weight sharing for initializing variable-sized models,
S.-Y . Xia, W. Zhu, X. Yang, and X. Geng, “Exploring learngene via stage-wise weight sharing for initializing variable-sized models,” inInt. Joint Conf. Artif. Intell. (IJCAI’24), 2024, pp. 5254–5262
2024
-
[40]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),”arXiv preprint arXiv:1606.08415, 2016
work page Pith review arXiv 2016
-
[41]
arXiv preprint arXiv:2305.02279 , year=
Q. Wang, X. Yang, S. Lin, and X. Geng, “Learngene: Inheriting condensed knowledge from the ancestry model to descendant models,”arXiv preprint arXiv:2305.02279, 2023
-
[42]
Convnext v2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “Convnext v2: Co-designing and scaling convnets with masked autoencoders,” inIEEE Conf. Comput. Vis. Pattern Recog. (CVPR’23), 2023, pp. 16 133–16 142
2023
-
[43]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inInt. Conf. Comput. Vis. (ICCV’09), 2009, pp. 248–255
2009
-
[44]
Automated flower classification over a large number of classes,
M.-E. Nilsback and A. Zisserman, “Automated flower classification over a large number of classes,” inIndian Conf. Comput. Vis. Graph. Image Process. (ICVGIP’08), 2008, pp. 722–729
2008
-
[45]
The caltech-ucsd birds-200-2011 dataset,
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-ucsd birds-200-2011 dataset,” California Institute of Technology, Tech. Rep. CNS-TR-2011-001, 2011
2011
-
[46]
Fine- grained car detection for visual census estimation,
T. Gebru, J. Krause, Y . Wang, D. Chen, J. Deng, and L. Fei-Fei, “Fine- grained car detection for visual census estimation,” inAAAI Conf. Artif. Intell. (AAAI’17), 2017, pp. 4502–4508
2017
-
[47]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,”Master’s thesis, Department of Computer Science, University of Toronto, 2009
2009
-
[48]
Food-101–mining discriminative components with random forests,
L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101–mining discriminative components with random forests,” inEur. Conf. Comput. Vis. (ECCV’14), 2014, pp. 446–461
2014
-
[49]
The Herbarium Challenge 2019 Dataset
K. C. Tan, Y . Liu, B. Ambrose, M. Tulig, and S. Belongie, “The herbarium challenge 2019 dataset,”arXiv preprint arXiv:1906.05372, 2019
work page Pith review arXiv 2019
-
[50]
arXiv preprint arXiv:2404.11098 (2024) 5
D. Zhang, S. Li, C. Chen, Q. Xie, and H. Lu, “Laptop-diff: Layer pruning and normalized distillation for compressing diffusion models,”arXiv preprint arXiv:2404.11098, 2024
-
[51]
Fine: Factorizing knowledge for initialization of variable-sized diffusion models,
Y . Xie, F. Feng, R. Shi, J. Wang, and X. Geng, “Fine: Factorizing knowledge for initialization of variable-sized diffusion models,” inIEEE Conf. Comput. Vis. Pattern Recog. (CVPR’26), 2026
2026
-
[52]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inInt. Conf. Comput. Vis. (ICCV’23), 2023, pp. 4195–4205
2023
-
[53]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthineret al., “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” inAdv. Neural Inform. Process. Syst. (NeurIPS’17), 2017, pp. 1–12
2017
-
[54]
Improved techniques for training gans,
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen, “Improved techniques for training gans,” inAdv. Neural Inform. Process. Syst. (NeurIPS’16), 2016
2016
-
[55]
Introvae: Introspective variational autoencoders for photographic image synthesis,
H. Huang, Z. Li, R. He, Z. Sun, and T. Tan, “Introvae: Introspective variational autoencoders for photographic image synthesis,” inAdv. Neural Inform. Process. Syst. (NeurIPS’18), 2018, pp. 1–12
2018
-
[56]
Knowledge guided disambiguation for large-scale scene classification with multi-resolution cnns,
L. Wang, S. Guo, W. Huang, Y . Xiong, and Y . Qiao, “Knowledge guided disambiguation for large-scale scene classification with multi-resolution cnns,”IEEE Trans. Image Process., vol. 26, no. 4, pp. 2055–2068, 2017
2055
-
[57]
Eco: Evolving core knowledge for efficient transfer,
F. Feng, Y . Xieet al., “Eco: Evolving core knowledge for efficient transfer,” inAdv. Neural Inform. Process. Syst. (NeurIPS’25), 2025
2025
-
[58]
Embodied intelligence via learning and evolution,
A. Gupta, S. Savarese, S. Ganguli, and L. Fei-Fei, “Embodied intelligence via learning and evolution,”Nat. Commun., vol. 12, no. 1, p. 5721, 2021
2021
-
[59]
Metamorph: Learning universal controllers with transformers,
A. Gupta, L. Fanet al., “Metamorph: Learning universal controllers with transformers,” inInt. Conf. Learn. Represent. (ICLR’22), 2022
2022
-
[60]
Learngene: Inheritable “genes
F. Feng, J. Wang, X. Yang, and X. Geng, “Learngene: Inheritable “genes” in intelligent agents,”Artif. Intell., p. 104421, 2025
2025
-
[61]
Principal component analysis,
M. Greenacre, P. J. Groenenet al., “Principal component analysis,”Nat. Rev. Methods Primers, vol. 2, no. 1, p. 100, 2022
2022
-
[62]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantamet al., “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inInt. Conf. Mach. Learn. (ICML’17), 2017, pp. 618–626
2017
-
[63]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” inInt. Conf. Comput. Vis. (ICCV’15), 2015, pp. 3730–3738
2015
-
[64]
Mujoco: A physics engine for model- based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model- based control,” inIEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS’21), 2012, pp. 5026–5033
2012
-
[65]
Knowledge diversion for efficient morphology control and policy transfer,
F. Feng, R. Shi, Y . Xie, J. Shen, J. Wang, and X. Geng, “Knowledge diversion for efficient morphology control and policy transfer,”arXiv preprint arXiv:2512.09796, 2025. VI. BIOGRAPHYSECTION Fu Fengreceived the B.Sc. (Hons.) degree in artificial intelligence from Chien-Shiung Wu College, Southeast University, Nanjing, China, in 2023. He is currently purs...
-
[66]
Given an input image x∈R H×W×3 , the network extracts multi-scale representations acrossSstages
Preliminaries on ConvNeXt-v2:ConvNeXt-v2 [42] is a modern hierarchical Convolution-based architecture with a stage-wise design, where feature maps are progressively downsampled. Given an input image x∈R H×W×3 , the network extracts multi-scale representations acrossSstages. Formally, ConvNeXt-v2 can be viewed as a composition of stage-wise transformations...
2021
-
[67]
Specifically, for each stage s, the depthwise convolution weight is denoted as W dw s ∈R Cs×1×k×k
Constraint-based Pre-training Paradigm on Convolution-based Architectures:To extend constraint-based pre-training to ConvNeXt-v2, we first reparameterize all depthwise convolution kernels across different stages into a unified representation. Specifically, for each stage s, the depthwise convolution weight is denoted as W dw s ∈R Cs×1×k×k. We then aggrega...
-
[68]
Table IX summarizes the details of these seven datasets, organized in ascending order of dataset size
Downstream Datasets in Image Classification:Additional downstream datasets for IMAGECLASSIFICATIONinclude Oxford Flowers [44], CUB-200-2011 [45], Stanford Cars [46], CIFAR-10 [47], CIFAR-100 [47], Food-101 [48], and iNaturalist-2019 [49]. Table IX summarizes the details of these seven datasets, organized in ascending order of dataset size
2011
-
[69]
Downstream Datasets in Image Generation:Additional downstream datasets for IMAGEGENERATIONinclude CelebA- HQ [55], LSUN-Bedroom [56], LSUN-Church [56], Hubble, MRI, and Pokemon. LSUN-Bedroom and LSUN-Church are subsets of the Large-Scale Scene Understanding (LSUN) dataset [56], consisting of scene images of bedrooms and churches, respectively, at a resolu...
2021
-
[70]
All tasks are constructed in the MuJoCo physics simulator [64] and are designed to comprehensively evaluate the agent’s capabilities across multiple dimensions
Downstream Datasets in Embodied Control:We conduct the main experiments for EMBODIEDCONTROLon the Flat Terrain, while additional downstream tasks include Variable Terrain, Incline, Obstacle, and Patrol. All tasks are constructed in the MuJoCo physics simulator [64] and are designed to comprehensively evaluate the agent’s capabilities across multiple dimen...
2021
-
[71]
Extending them to more heterogeneous or structured operations, e.g., depth-wise convolutions, requires careful redesign to preserve their specific inductive biases
Limitations:First, the current Kronecker-based constraints in WeiT are primarily designed for standard dense operators, such as linear projections and regular convolutions. Extending them to more heterogeneous or structured operations, e.g., depth-wise convolutions, requires careful redesign to preserve their specific inductive biases. JOURNAL OF LATEX CL...
2021
-
[72]
In this setting, only lightweight modality-specific scalers need to be adapted, leading to more general and parameter-efficient models
Future Work:Based on these observations, we highlight two directions for future research: • Cross-Modal Templates.Extending WeiT to learn shared templates across modalities, e.g., vision and text, is a promising direction. In this setting, only lightweight modality-specific scalers need to be adapted, leading to more general and parameter-efficient models...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.