Recognition: unknown
Adaptive Test-Time Compute Allocation for Reasoning LLMs via Constrained Policy Optimization
Pith reviewed 2026-05-10 11:54 UTC · model grok-4.3
The pith
A lightweight classifier learns to allocate extra test-time compute to difficult inputs by imitating Lagrangian oracles, improving accuracy under fixed budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize this as a constrained optimization problem (maximize expected accuracy subject to an average compute budget) and solve it with a two-stage Solve-then-Learn pipeline. In the solve stage, Lagrangian relaxation decomposes the global constraint into per-instance sub-problems, each admitting a closed-form oracle action that optimally prices accuracy against cost. We prove that the induced cost is monotone in the dual variable, enabling exact budget targeting via binary search. In the learn stage, a lightweight classifier is trained to predict oracle actions from cheap input features, amortizing the allocation rule for real-time deployment. We establish that the task-level regret of a
What carries the argument
Lagrangian relaxation that converts the global budget constraint into per-instance sub-problems whose optimal actions are monotone in the dual variable and can therefore be imitated by a classifier.
Where Pith is reading between the lines
- The same imitation approach could be applied to other inference constraints such as latency or memory by redefining the cost function inside the Lagrangian.
- If input features are enriched with cheap model-internal signals like entropy of the first token, imitation accuracy could rise further without retraining the base LLM.
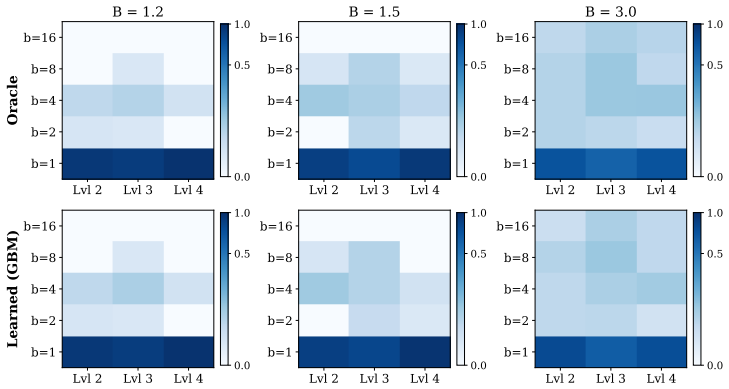
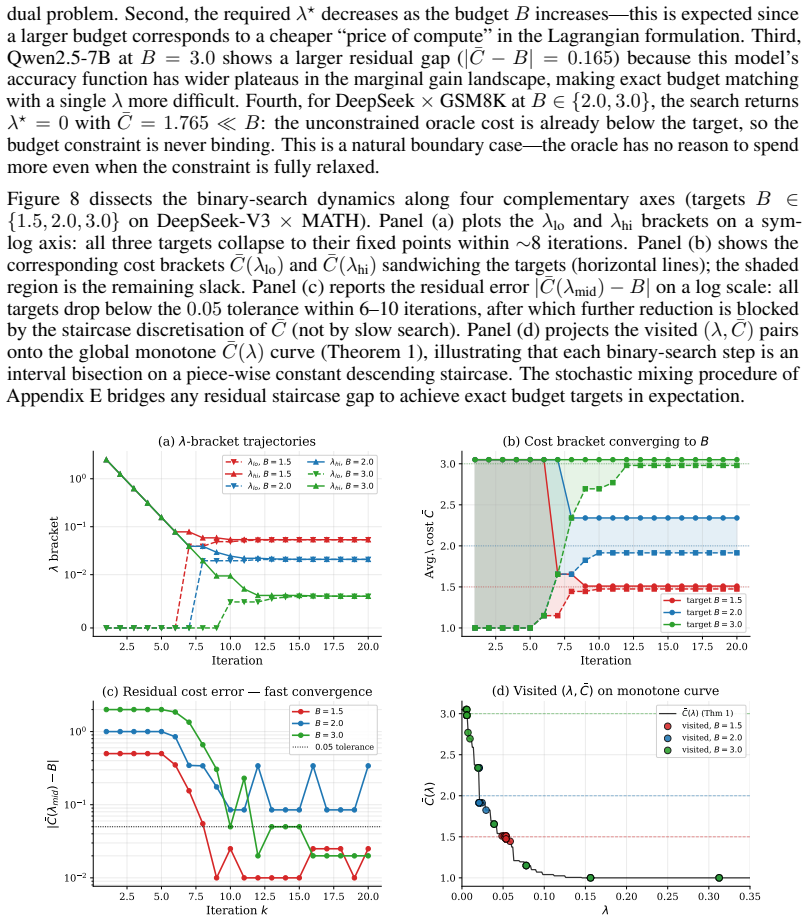
- The binary-search procedure for exact budget targeting assumes monotonicity; violating it on some model families would require a different search method or approximate dual optimization.
Load-bearing premise
That per-instance sub-problems admit closed-form oracle actions whose cost is monotone in the dual variable and that cheap input features can predict those actions with low enough imitation error for the regret bound to matter in practice.
What would settle it
Run the learned classifier on a held-out set and check whether measured task regret exceeds the product of its imitation error and the observed worst-case per-instance gap; if the excess is large and consistent, the bound and the practical utility of the reduction both fail.
Figures











read the original abstract
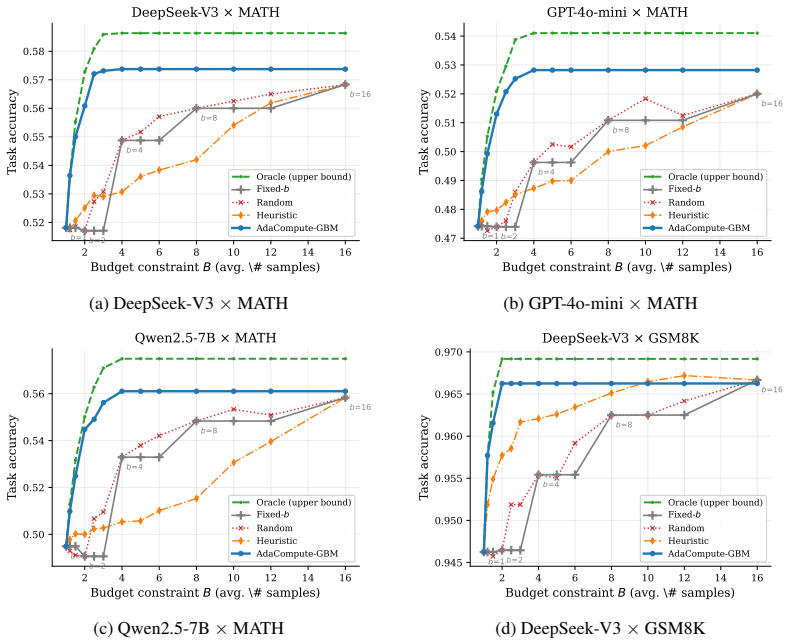
Test-time compute scaling, the practice of spending extra computation during inference via repeated sampling, search, or extended reasoning, has become a powerful lever for improving large language model performance. Yet deploying these techniques under finite inference budgets requires a decision that current systems largely ignore: which inputs deserve more compute, and which can be answered cheaply? We formalize this as a constrained optimization problem (maximize expected accuracy subject to an average compute budget) and solve it with a two-stage Solve-then-Learn pipeline. In the solve stage, Lagrangian relaxation decomposes the global constraint into per-instance sub-problems, each admitting a closed-form oracle action that optimally prices accuracy against cost. We prove that the induced cost is monotone in the dual variable, enabling exact budget targeting via binary search. In the learn stage, a lightweight classifier is trained to predict oracle actions from cheap input features, amortizing the allocation rule for real-time deployment. We establish that the task-level regret of the learned policy is bounded by its imitation error times the worst-case per-instance gap, yielding a clean reduction from constrained inference to supervised classification. Experiments on MATH and GSM8K with three LLMs (DeepSeek-V3, GPT-4o-mini, Qwen2.5-7B) show that our method consistently outperforms uniform and heuristic allocation baselines, achieving up to 12.8% relative accuracy improvement on MATH under matched budget constraints, while closely tracking the Lagrangian oracle upper bound with over 91% imitation accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes adaptive test-time compute allocation for reasoning LLMs as a constrained optimization problem (maximize expected accuracy subject to average compute budget) and solves it via a two-stage Solve-then-Learn pipeline. The solve stage applies Lagrangian relaxation to decompose into per-instance sub-problems with closed-form oracle actions, proves that the induced cost is monotone in the dual variable (enabling exact binary-search budget targeting), and the learn stage trains a lightweight classifier on cheap input features to imitate the oracle. A regret bound is established showing that task-level regret of the learned policy is at most its imitation error times the worst-case per-instance gap. Experiments on MATH and GSM8K with DeepSeek-V3, GPT-4o-mini, and Qwen2.5-7B report up to 12.8% relative accuracy gains under matched budgets and over 91% imitation accuracy while tracking the Lagrangian oracle.
Significance. If the monotonicity proof and regret reduction hold, the work supplies a clean, principled reduction from constrained inference-time allocation to supervised classification, with explicit performance guarantees and practical amortization. The explicit regret bound, monotonicity result, and empirical tracking of the oracle (91% accuracy) are notable strengths that distinguish it from heuristic allocation methods. The reported gains over uniform and heuristic baselines on standard reasoning benchmarks indicate potential impact for efficient LLM deployment under finite budgets.
minor comments (3)
- Abstract: the claim of 'up to 12.8% relative accuracy improvement' would be strengthened by briefly indicating the specific budget levels (e.g., average tokens or forward passes) at which the gain is measured and the precise baselines (uniform, heuristic) used for comparison.
- Method section: while the input features for the classifier are described as 'cheap,' an explicit statement or table comparing their computational cost to a single LLM forward pass would clarify the practicality of the amortization step for real-time deployment.
- Experiments section: the 91% imitation accuracy and regret-bound utility would benefit from reporting the per-dataset breakdown of imitation error and the observed per-instance gap values to allow readers to assess how tight the bound is in practice.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the monotonicity proof, regret bound, and empirical results, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's pipeline begins with a standard constrained optimization formulation (maximize expected accuracy subject to average compute budget) solved via Lagrangian relaxation to obtain per-instance closed-form oracles, followed by a monotonicity proof on cost with respect to the dual variable (enabling binary search) and a regret bound reducing task-level regret to imitation error times per-instance gap. These steps rely on external optimization principles and standard imitation-learning analysis rather than self-referential definitions or fitted parameters to the final metric. The learn stage is explicitly reduced to supervised classification on input features to imitate the oracle, with no load-bearing self-citations or ansatzes imported from prior author work. The reported imitation accuracy and accuracy gains are presented as empirical validation of the bound, not as definitional inputs. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The per-instance cost induced by the Lagrangian relaxation is monotone in the dual variable
- domain assumption Per-instance sub-problems admit closed-form oracle actions that optimally price accuracy against cost
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu, and D. Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Hoffmann, S
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, et al. Training compute-optimal large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[3]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. H. Chi, Q. V . Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[4]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[5]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y . Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[6]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[7]
Learning to reason with LLMs, September 2024
OpenAI. Learning to reason with LLMs, September 2024. https://openai.com/index/ learning-to-reason-with-llms/
2024
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Kojima, S
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[10]
S. Hao, Y . Gu, H. Ma, J. J. Hong, Z. Wang, D. Z. Wang, and Z. Hu. Reasoning with language model is planning with world model. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[11]
D. Zhang, S. Zhoubian, Y . Yue, Y . Dong, and J. Tang. Accessing GPT-4 level mathemati- cal olympiad solutions via Monte Carlo tree self-refine with LLaMA-3 8B.arXiv preprint arXiv:2406.07394, 2024
-
[12]
Solving math word problems with process- and outcome-based feedback
J. Uesato, N. Kushman, R. Kumar, H. F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
B. Brown, J. Juravsky, R. Ehrlich, R. Clark, Q. V . Le, C. Ré, and A. Roelofs. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review arXiv 2024
-
[14]
Y . Li, Z. Lin, S. Zhang, Q. Fu, B. Chen, J.-G. Lou, and W. Chen. Making large language models better reasoners with step-aware verifier. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2023
2023
-
[15]
Snell, J
C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling LLM test-time compute optimally can be more ef- fective than scaling model parameters. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[16]
Y . Wu, Z. Sun, S. Li, S. Welleck, and Y . Yang. Inference scaling laws: An empirical analysis of compute-optimal inference for LLM problem-solving. InInternational Conference on Learning Representations (ICLR), 2025. 10
2025
- [17]
-
[18]
A. Agarwal, A. Sengupta, and T. Chakraborty. The art of scaling test-time compute for large language models.arXiv preprint arXiv:2512.02008, 2025
-
[19]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Q. Zhang, F. Lyu, Z. Sun, L. Wang, W. Zhang, Z. Guo, Y . Wang, N. Muennighoff, I. King, X. Liu, and C. Ma. What, how, where, and how well? A survey on test-time scaling in large language models.arXiv preprint arXiv:2503.24235, 2025
work page internal anchor Pith review arXiv 2025
- [20]
-
[21]
A. Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review arXiv 2016
-
[22]
Teerapittayanon, B
S. Teerapittayanon, B. McDanel, and H.-T. Kung. BranchyNet: Fast inference via early exiting from deep neural networks. InInternational Conference on Pattern Recognition (ICPR), 2016
2016
-
[23]
Huang, D
G. Huang, D. Chen, T. Li, F. Wu, L. van der Maaten, and K. Q. Weinberger. Multi-scale dense networks for resource efficient image classification. InInternational Conference on Learning Representations (ICLR), 2018
2018
-
[24]
Y . Han, G. Huang, S. Song, L. Yang, H. Wang, and Y . Wang. Dynamic neural networks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(11):7436–7456, 2021
2021
-
[25]
Shazeer, A
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[26]
Fedus, B
W. Fedus, B. Zoph, and N. Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[27]
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts. Neural Computation, 3(1):79–87, 1991
1991
-
[28]
E. Bengio, P.-L. Bacon, J. Pineau, and D. Precup. Conditional computation in neural networks for faster models.arXiv preprint arXiv:1511.06297, 2016
-
[29]
Leviathan, M
Y . Leviathan, M. Kalman, and Y . Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[30]
I. Ong, A. Almahairi, V . Wu, W.-L. Chiang, T. Wu, J. E. Gonzalez, M. W. Kadous, and I. Stoica. RouteLLM: Learning to route LLMs with preference data.arXiv preprint arXiv:2406.18665, 2024
work page internal anchor Pith review arXiv 2024
-
[31]
Pan, H., Tennenholtz, G., Mannor, S., Chi, C.-W., Brekel- mans, R., Shah, P., and Tewari, A
P. Panda, R. Magazine, C. Devaguptapu, S. Takemori, and V . Sharma. Adaptive LLM routing under budget constraints.arXiv preprint arXiv:2508.21141, 2025
- [32]
- [33]
-
[34]
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning
P. Aggarwal and S. Welleck. SelfBudgeter: Adaptive token allocation for efficient LLM reason- ing.arXiv preprint arXiv:2505.11274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [35]
-
[36]
Damani, I
M. Damani, I. Shenfeld, H. Peng, A. Agrawal, and J. Andreas. Learning how hard to think: Input-adaptive allocation of LM computation. InInternational Conference on Learning Repre- sentations (ICLR), 2025
2025
-
[37]
The larger the better? improved llm code-generation via budget reallocation, 2024
M. Hassid, T. Remez, J. Gehring, R. Schwartz, and Y . Adi. The larger the better? Improved LLM code-generation via budget reallocation.arXiv preprint arXiv:2404.00725, 2024
-
[38]
L. Chen, M. Zaharia, and J. Zou. FrugalGPT: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review arXiv 2023
-
[39]
Madaan, N
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prab- humoye, Y . Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[40]
Trapeznikov and V
K. Trapeznikov and V . Saligrama. Supervised sequential classification under budget constraints. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2013
2013
-
[41]
Geifman and R
Y . Geifman and R. El-Yaniv. Selective classification for deep neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[42]
Badanidiyuru, R
A. Badanidiyuru, R. Kleinberg, and A. Slivkins. Bandits with knapsacks.Journal of the ACM, 65(3):1–55, 2018
2018
-
[43]
Agrawal and N
S. Agrawal and N. R. Devanur. Linear contextual bandits with knapsacks. InAdvances in Neural Information Processing Systems (NeurIPS), 2016
2016
-
[44]
Boyd and L
S. Boyd and L. Vandenberghe.Convex Optimization. Cambridge University Press, 2004
2004
-
[45]
D. P. Bertsekas.Convex Optimization Algorithms. Athena Scientific, 2015
2015
-
[46]
Hendrycks, C
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[47]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Prafulla, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
A. Yang, B. Zhang, B. Hui, B. Gao, B. Yu, C. Li, D. Liu, J. Tu, J. Zhou, J. Lin, et al. Qwen2.5- Math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review arXiv 2024
-
[51]
Chen and C
T. Chen and C. Guestrin. XGBoost: A scalable tree boosting system. InACM SIGKDD Interna- tional Conference on Knowledge Discovery and Data Mining, 2016
2016
-
[52]
responsive
S. Zhou, Y . Ao, Y . Xuan, X. Wang, T. Fan, and H. Wang. Inference scaling law for retrieval aug- mented generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 16522–16530, 2026. 12 A Related Work Test-time scaling for LLMs.A growing body of work demonstrates that inference-time computa- tion can significantly improv...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.