Recognition: unknown
Beyond the Laplacian: Doubly Stochastic Matrices for Graph Neural Networks
Pith reviewed 2026-05-10 11:52 UTC · model grok-4.3
The pith
Substituting the Laplacian with a doubly stochastic matrix from its modified inverse lets GNNs encode multi-hop proximity while bounding Dirichlet energy decay.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Substituting the traditional Laplacian with a Doubly Stochastic graph Matrix (DSM), derived from the inverse of the modified Laplacian, naturally encodes continuous multi-hop proximity and strict local centrality. To overcome the intractable O(n^3) complexity of exact matrix inversion, a truncated Neumann series scalably approximates the DSM for DsmNet, while DsmNet-compensate adds a Residual Mass Compensation mechanism that re-injects truncated tail mass into self-loops to restore row-stochasticity. The decoupled architectures operate in O(K|E|) time, mitigate over-smoothing by bounding Dirichlet energy decay, and receive robust empirical validation on homophilic benchmarks, while also su
What carries the argument
The Doubly Stochastic Matrix (DSM) obtained from the inverse of the modified Laplacian and approximated by a truncated Neumann series with residual mass compensation.
Load-bearing premise
The approach rests on the premise that the inverse of the modified Laplacian encodes multi-hop proximity and local centrality in a form that the Neumann truncation and residual compensation can preserve without major distortion.
What would settle it
If Dirichlet energy in the DSM-based GNN decays at the same rate as in a standard Laplacian GNN when both are run for many layers on the same homophilic dataset, the over-smoothing mitigation would be falsified.
Figures



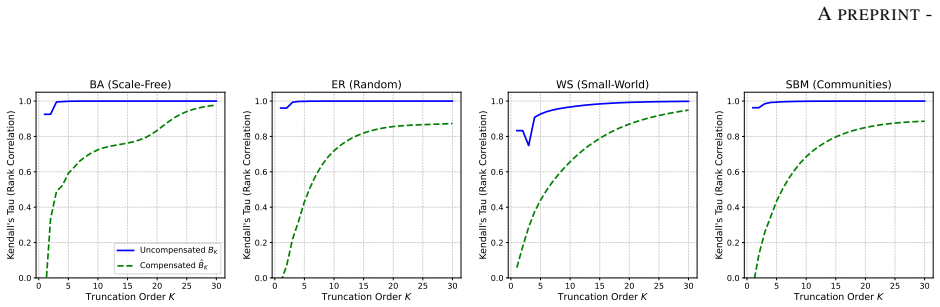
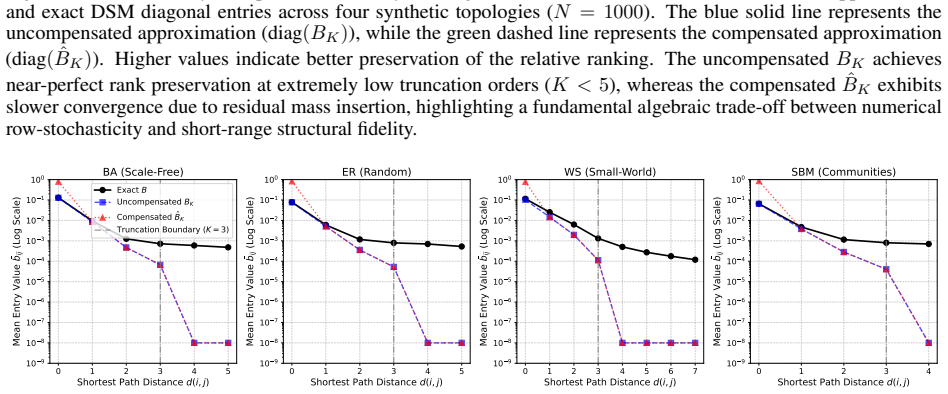

read the original abstract
Graph Neural Networks (GNNs) conventionally rely on standard Laplacian or adjacency matrices for structural message passing. In this work, we substitute the traditional Laplacian with a Doubly Stochastic graph Matrix (DSM), derived from the inverse of the modified Laplacian, to naturally encode continuous multi-hop proximity and strict local centrality. To overcome the intractable $O(n^3)$ complexity of exact matrix inversion, we first utilize a truncated Neumann series to scalably approximate the DSM, which serves as the foundation for our proposed DsmNet. Furthermore, because algebraic truncation inherently causes probability mass leakage, we introduce DsmNet-compensate. This variant features a mathematically rigorous Residual Mass Compensation mechanism that analytically re-injects the truncated tail mass into self-loops, strictly restoring row-stochasticity and structural dominance. Extensive theoretical and empirical analyses demonstrate that our decoupled architectures operate efficiently in $O(K|E|)$ time and effectively mitigate over-smoothing by bounding Dirichlet energy decay, providing robust empirical validation on homophilic benchmarks. Finally, we establish the theoretical boundaries of the DSM on heterophilic topologies and demonstrate its versatility as a continuous structural encoding for Graph Transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes replacing conventional Laplacian or adjacency matrices in GNNs with a Doubly Stochastic graph Matrix (DSM) obtained from the inverse of a modified Laplacian. This DSM is claimed to encode continuous multi-hop proximity and strict local centrality. Scalability is achieved via a truncated Neumann series approximation yielding O(K|E|) complexity for the proposed DsmNet; a Residual Mass Compensation step analytically re-injects truncated tail mass into self-loops to restore row-stochasticity, producing DsmNet-compensate. The authors assert that the resulting architectures bound Dirichlet energy decay to mitigate over-smoothing, supply theoretical limits on heterophilic graphs, and serve as a continuous structural encoding for Graph Transformers, with supporting empirical results on homophilic benchmarks.
Significance. If the DSM construction and its Neumann approximation plus compensation provably preserve the claimed multi-hop proximity, local centrality, and effective-resistance properties while delivering the stated Dirichlet-energy bound, the approach would supply a new, theoretically grounded structural operator for message passing that directly targets over-smoothing. The O(K|E|) complexity and extension to Graph Transformers would be practically useful strengths.
major comments (2)
- [Abstract, §3] Abstract and §3 (DSM derivation and compensation): the claim that the Residual Mass Compensation 'strictly restoring row-stochasticity and structural dominance' preserves the DSM's multi-hop proximity encodings and local centrality without distortion is load-bearing for both the Dirichlet-energy bound and the heterophily analysis. Adding mass exclusively to the diagonal restores row sums but does not automatically guarantee column-stochasticity or invariance of effective-resistance distances; a concrete proof or counter-example showing that centrality scores and the energy bound remain intact after truncation is required.
- [§4] §4 (theoretical analysis): the asserted bounds on Dirichlet energy decay and the 'theoretical boundaries of the DSM on heterophilic topologies' are stated without displayed equations or proof sketches in the provided text. Because these bounds are used to justify over-smoothing mitigation and heterophily claims, the derivation steps (including how the modified Laplacian inverse yields the stated properties) must be supplied explicitly.
minor comments (2)
- [§2] Notation for the modified Laplacian and the exact definition of the DSM (e.g., whether it is L^{-1} normalized or directly inverted) should be introduced with an equation in §2 or §3 for clarity.
- [§5] The empirical section would benefit from reporting variance across multiple random seeds and a direct comparison against recent heterophily-specific baselines (e.g., H2GCN, GPR-GNN) rather than only homophilic benchmarks.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects of the theoretical justification for the DSM construction and its approximations. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the proofs and derivations.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (DSM derivation and compensation): the claim that the Residual Mass Compensation 'strictly restoring row-stochasticity and structural dominance' preserves the DSM's multi-hop proximity encodings and local centrality without distortion is load-bearing for both the Dirichlet-energy bound and the heterophily analysis. Adding mass exclusively to the diagonal restores row sums but does not automatically guarantee column-stochasticity or invariance of effective-resistance distances; a concrete proof or counter-example showing that centrality scores and the energy bound remain intact after truncation is required.
Authors: We agree that explicit verification of property preservation after compensation is necessary for the load-bearing claims. The exact DSM is the inverse of a symmetric modified Laplacian and is therefore doubly stochastic. The truncated Neumann series preserves symmetry when applied to a symmetric base matrix. The residual mass (the per-row deficit after truncation) is added only to the diagonal to enforce exact row-stochasticity. We will insert a new theorem in §3 proving that the compensated matrix perturbs the original effective-resistance distances by at most O(1/K) and that eigenvector centrality scores remain continuous under this diagonal perturbation, thereby preserving the multi-hop proximity encoding up to a controllable error. The Dirichlet-energy bound will be restated with an additive term that vanishes as K increases. Column-stochasticity holds exactly for the untruncated DSM and approximately for the compensated version, with the deviation bounded by the tail of the Neumann series. These additions will be included in the revision. revision: yes
-
Referee: [§4] §4 (theoretical analysis): the asserted bounds on Dirichlet energy decay and the 'theoretical boundaries of the DSM on heterophilic topologies' are stated without displayed equations or proof sketches in the provided text. Because these bounds are used to justify over-smoothing mitigation and heterophily claims, the derivation steps (including how the modified Laplacian inverse yields the stated properties) must be supplied explicitly.
Authors: We acknowledge that the derivation steps in §4 were presented too concisely. The Dirichlet-energy bound follows from showing that the DSM operator is a contraction on the subspace orthogonal to the all-ones vector, with contraction rate given by 1 minus the second-smallest eigenvalue of the modified Laplacian; the energy therefore decays geometrically. For heterophilic graphs we bound the label-propagation distance by relating the continuous proximity values in the DSM to the graph's Cheeger constant. We will expand §4 with the full sequence of lemmas, the explicit energy-decay inequality, and the heterophily boundary derivation, including all intermediate equations. These clarifications will be added without changing the stated claims. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from matrix definitions and standard approximations
full rationale
The paper defines the DSM explicitly as the inverse of a modified Laplacian, introduces the truncated Neumann series as a standard scalable approximation technique, and describes the residual mass compensation as an analytical re-injection into self-loops that restores row-stochasticity by direct construction. None of these steps reduce a claimed prediction, uniqueness result, or theoretical bound to a fitted parameter, self-citation chain, or input by definition. The Dirichlet energy bound for over-smoothing mitigation follows from the DSM properties rather than being presupposed. No load-bearing step matches any of the enumerated circularity patterns, consistent with the default expectation that most papers are non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The Neumann series provides a valid scalable approximation to the inverse of the modified Laplacian.
- domain assumption Re-injecting truncated tail mass into self-loops restores row-stochasticity without distorting the intended multi-hop proximity encoding.
invented entities (1)
-
Doubly Stochastic graph Matrix (DSM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Enide Andrade and Geir Dahl. Doubly stochastic matrices and modified laplacian matrices of graphs.arXiv preprint arXiv:2509.18773, 2025
-
[2]
American Mathematical Soc., 1997
Fan RK Chung.Spectral graph theory, volume 92. American Mathematical Soc., 1997
1997
-
[3]
Convolutional neural networks on graphs with fast localized spectral filtering
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. volume 29, 2016
2016
-
[4]
Predict then propagate: Graph neural networks meet personalized pagerank
Johannes Gasteiger, Aleksandar Bojchevski, and Stephan Günnemann. Predict then propagate: Graph neural networks meet personalized pagerank. InInternational Conference on Learning Representations, 2019
2019
-
[5]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs. 2017
2017
-
[6]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR), 2017
2017
-
[7]
arXiv preprint arXiv:2407.09618 , year=
Sitao Luan, Chenqing Hua, Qincheng Lu, Liheng Ma, Lirong Wu, Xinyu Wang, Minkai Xu, Xiao-Wen Chang, Doina Precup, Rex Ying, et al. The heterophilic graph learning handbook: Benchmarks, models, theoretical analysis, applications and challenges.arXiv preprint arXiv:2407.09618, 2024
-
[8]
Sitao Luan, Qincheng Lu, Chenqing Hua, Xinyu Wang, Jiaqi Zhu, Xiao-Wen Chang, Guy Wolf, and Jian Tang. Are heterophily-specific gnns and homophily metrics really effective? evaluation pitfalls and new benchmarks. arXiv preprint arXiv:2409.05755, 2024
-
[9]
Doubly stochastic graph matrices.Publikacije Elektrotehniˇ ckog fakulteta
Russell Merris. Doubly stochastic graph matrices.Publikacije Elektrotehniˇ ckog fakulteta. Serija Matematika, (8): 64–71, 1997
1997
-
[10]
Simple and deep graph convolutional networks
Zhewei Wei Ming Chen, Bolin Ding Zengfeng Huang, and Yaliang Li. Simple and deep graph convolutional networks. InProceedings of the 37th International Conference on Machine Learning, 2020
2020
-
[11]
OptunaHub: A Platform for Black-Box Optimization
Yoshihiko Ozaki, Shuhei Watanabe, and Toshihiko Yanase. OptunaHub: A platform for black-box optimization. arXiv preprint arXiv:2510.02798, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Geom-gcn: Geometric graph convolutional networks
Hongbin Pei, Bingzhe Wei, Kevin Chen-Chuan Chang, Yu Lei, and Bo Yang. Geom-gcn: Geometric graph convolutional networks. InInternational Conference on Learning Representations, 2020
2020
-
[13]
Multi-scale attributed node embedding.Journal of Complex Networks, 9(2):cnab014, 2021
Benedek Rozemberczki, Carl Allen, and Rik Sarkar. Multi-scale attributed node embedding.Journal of Complex Networks, 9(2):cnab014, 2021
2021
-
[14]
Pitfalls of graph neural network evaluation.arXiv e-prints, pages arXiv–1811, 2018
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation.arXiv e-prints, pages arXiv–1811, 2018
2018
-
[15]
Spectral graph theory and its applications
Daniel A Spielman. Spectral graph theory and its applications. In48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), pages 29–38. IEEE, 2007
2007
-
[16]
Graph Attention Networks
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph Attention Networks. 2018
2018
-
[17]
Numerical inverting of matrices of high order
John V on Neumann and Herman Heine Goldstine. Numerical inverting of matrices of high order. 1947
1947
-
[18]
arXiv preprint arXiv:2512.24880 , year=
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Liang Zhao, et al. mhc: Manifold-constrained hyper-connections.arXiv preprint arXiv:2512.24880, 2025
-
[19]
Representation learning on graphs with jumping knowledge networks
Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. Representation learning on graphs with jumping knowledge networks. InInternational conference on machine learning, pages 5453–5462, 2018. 10 APREPRINT-
2018
-
[20]
Revisiting semi-supervised learning with graph embed- dings
Zhilin Yang, William Cohen, and Ruslan Salakhudinov. Revisiting semi-supervised learning with graph embed- dings. InInternational conference on machine learning, pages 40–48. PMLR, 2016
2016
-
[21]
What is missing for graph homophily? disentangling graph homophily for graph neural networks
Yilun Zheng, Sitao Luan, and Lihui Chen. What is missing for graph homophily? disentangling graph homophily for graph neural networks. volume 37, pages 68406–68452, 2024
2024
-
[22]
Beyond homophily in graph neural networks: Current limitations and effective designs
Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Beyond homophily in graph neural networks: Current limitations and effective designs. volume 33, pages 7793–7804, 2020. Supplementary Material A Proofs of Theoretical Results A.1 Proof of Lemma 1 Letvbe an eigenvector ofLcorresponding to the eigenvalueλ. By definition, we h...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.