Recognition: unknown
QLLVM: A Scalable Quantum-Classical Co-Compilation Framework based on LLVM
Pith reviewed 2026-05-10 11:16 UTC · model grok-4.3
The pith
QLLVM unifies classical and quantum compilation inside LLVM to produce single executables with smaller circuits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QLLVM establishes an end-to-end LLVM-based compilation workflow that unifies the build of classical high-performance programs including CUDA, MPI, and C++ together with quantum programs into a single executable, with quantum compilation handled through high-level optimizations in the MLIR Quantum dialect, lowering to QIR for low-level optimization and hardware mapping.
What carries the argument
The three-stage lowering pipeline from MLIR Quantum dialect optimizations to QIR representation followed by LLVM low-level passes and hardware mapping.
If this is right
- Quantum circuits compiled with QLLVM show lower depth and fewer gates than those from prior compilers on standard benchmark suites.
- Hybrid classical-quantum programs compile to single unified binaries that link quantum and classical code without separate toolchains.
- Quantum software gains direct access to mature LLVM optimization infrastructure for both high-level and low-level transformations.
- The extensible architecture supports future addition of new quantum hardware backends and classical high-performance features in one framework.
Where Pith is reading between the lines
- Existing classical HPC libraries and build systems could be reused for quantum code with minimal changes, shortening development time for mixed workloads.
- LLVM's data-flow and alias analysis passes might improve optimization of classical control logic surrounding quantum operations in hybrid programs.
- Wider adoption could standardize quantum intermediate representations around QIR, easing porting between different quantum hardware targets.
Load-bearing premise
Lowering quantum programs through the MLIR Quantum dialect to QIR and then applying LLVM-style low-level optimizations will reliably produce smaller and shallower circuits than existing specialized quantum compilers without introducing hidden overheads or correctness issues.
What would settle it
A direct comparison on the MQTBench suite in which QLLVM produces circuits with equal or greater depth and gate counts than the best existing quantum compilers would falsify the claimed performance gains.
Figures


read the original abstract
To address the urgent need in the NISQ era for high-performance, scalable quantum compilers and to advance the integration of classical and quantum computing, we present QLLVM, an advanced Quantum-Classical co-compilation framework built on LLVM. To our knowledge, QLLVM delivers an end-to-end, LLVM-based compilation workflow that unifies the build of classical high-performance programs, including CUDA, MPI, and C++, together with quantum programs into a single executable. For quantum program compilation, QLLVM adopts a three-stage design: high-level optimizations are implemented in the MLIR Quantum dialect and then lowered to QIR, an LLVM IR-based representation, for low-level optimization and hardware mapping. Its extensible architecture and seamless interoperability with classical high-performance computing provide an efficient, flexible, industrial-grade compilation infrastructure for future quantum software development. Experimental results show that, on the MQTBench benchmark suite, QLLVM reduces circuit depth and gate counts compared with state-of-the-art compilers and demonstrates clear advantages in compiling hybrid classical-quantum programs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QLLVM, an LLVM-based quantum-classical co-compilation framework. It uses a three-stage pipeline for quantum programs—high-level optimizations in the MLIR Quantum dialect, lowering to QIR for low-level LLVM-style optimizations and hardware mapping—while unifying compilation of classical HPC code (CUDA, MPI, C++) with quantum code into a single executable. The central empirical claim is that QLLVM reduces circuit depth and gate counts on the MQTBench suite relative to state-of-the-art compilers and shows advantages for hybrid classical-quantum programs.
Significance. If the performance claims hold under rigorous benchmarking and the lowering steps preserve semantics, the work would supply a practical, extensible, industrial-grade infrastructure that leverages the mature LLVM ecosystem for both quantum and hybrid quantum-classical compilation. This directly addresses the NISQ-era need for scalable compilers and seamless classical-quantum integration.
major comments (2)
- [Abstract / Experimental Results] Abstract and § on experimental evaluation: the central claim that QLLVM 'reduces circuit depth and gate counts compared with state-of-the-art compilers' on MQTBench supplies no numerical deltas, no named baselines, no circuit-selection criteria, no measurement methodology for depth/gate count, and no statistical significance. Without these data the performance advantage cannot be assessed and the claim is not load-bearing.
- [Design / Implementation] § on the three-stage design and lowering: the manuscript describes lowering from the MLIR Quantum dialect to QIR and then applying LLVM passes, but provides no explicit argument or test that quantum circuit semantics (gate commutation, measurement, etc.) are preserved through the lowering and optimization pipeline. This is load-bearing for any correctness claim of a compiler framework.
minor comments (2)
- [Abstract] The phrase 'to our knowledge' in the abstract is unnecessary and should be removed or replaced with a precise novelty statement.
- [Figures / Tables] Figure captions and table headers should explicitly state the exact LLVM passes used and the MQTBench subset selected so that results are reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, agreeing where the manuscript requires strengthening and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and § on experimental evaluation: the central claim that QLLVM 'reduces circuit depth and gate counts compared with state-of-the-art compilers' on MQTBench supplies no numerical deltas, no named baselines, no circuit-selection criteria, no measurement methodology for depth/gate count, and no statistical significance. Without these data the performance advantage cannot be assessed and the claim is not load-bearing.
Authors: We agree that the abstract and experimental evaluation section lack the quantitative specificity needed to make the performance claims fully load-bearing. In the revised manuscript we will: (1) expand the abstract with concrete numerical deltas (average and per-benchmark reductions in depth and gate count); (2) explicitly name the baseline compilers used in the MQTBench comparison; (3) describe the circuit-selection criteria and subset of MQTBench employed; (4) detail the exact methodology for computing depth and gate counts; and (5) report statistical significance (e.g., mean, standard deviation, and p-values across runs). These additions will allow readers to rigorously evaluate the claimed advantages. revision: yes
-
Referee: [Design / Implementation] § on the three-stage design and lowering: the manuscript describes lowering from the MLIR Quantum dialect to QIR and then applying LLVM passes, but provides no explicit argument or test that quantum circuit semantics (gate commutation, measurement, etc.) are preserved through the lowering and optimization pipeline. This is load-bearing for any correctness claim of a compiler framework.
Authors: We acknowledge that an explicit, self-contained argument for semantic preservation was not sufficiently elaborated. In the revision we will insert a dedicated subsection under the three-stage design that (a) states the semantic invariants maintained by each lowering step (MLIR Quantum dialect to QIR, then QIR to LLVM), (b) explains how gate commutation, measurement, and control-flow constructs are preserved, and (c) provides either a formal sketch or empirical equivalence checks on representative circuits. This will directly address the load-bearing correctness concern. revision: yes
Circularity Check
No significant circularity identified
full rationale
This is an engineering framework paper describing the QLLVM compiler architecture and its MLIR-to-QIR-to-LLVM pipeline. Claims rest on external benchmark comparisons (MQTBench) rather than any derivation chain, equations, fitted parameters, or self-referential predictions. No load-bearing steps reduce by construction to inputs; the work is self-contained against external benchmarks with no self-citation or ansatz smuggling in the central results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLIR dialects and LLVM IR can be safely extended to represent quantum operations and lowered without semantic loss
Reference graph
Works this paper leans on
-
[1]
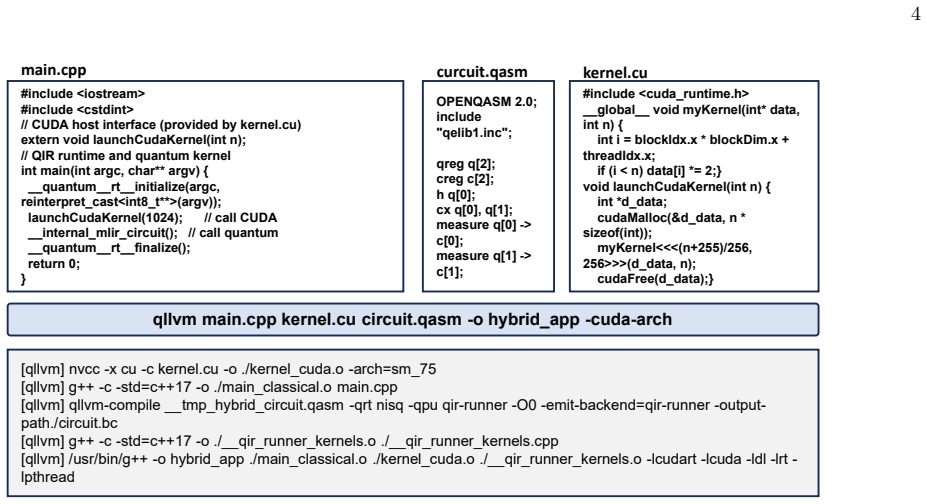
Unified driver and build semantics QLLVM exposes a single driver, qllvm, that accepts a heterogeneous set of input source files and produces a single executable binary. The driver recognizes the fol- lowing file types by extension: •C/C++ sources (*.c, *.cc, *.cpp), compiled via an LLVM-compatible C/C++ compiler (clang++ or g++); •CUDA sources (*.cu), com...
-
[2]
The driver in- vokes nvcc with the specified compute capability (e.g., -arch=sm 75) and collects the resulting host-side object files
Integration with CUDA and MPI For CUDA-enabled programs, QLLVM delegates de- vice code generation entirely to nvcc. The driver in- vokes nvcc with the specified compute capability (e.g., -arch=sm 75) and collects the resulting host-side object files. These objects are then linked with the rest of the application and with the CUDA runtime (libcudart, libcu...
-
[3]
The dialect provides a small set of operations and types that are sufficient to represent current quantum programs while remain- ing amenable to optimization and lowering to QIR
Quantum dialect design At the core of QLLVM’s midend is a quantum di- alect implemented on top of MLIR. The dialect provides a small set of operations and types that are sufficient to represent current quantum programs while remain- ing amenable to optimization and lowering to QIR. The quantum dialect introduces three primary types: •Array: an ordered col...
-
[4]
quantum kernel
Lowering from MLIR to QIR Lowering to QIR is implemented as a dialect conversion from the quantum dialect to the MLIR LLVM dialect, followed by standard MLIR-to-LLVM code generation. Each quantum operation is mapped to a corresponding QIR runtime call: •QallocOpis lowered to calls to quantum rt qubit allocate array. •DeallocOpis lowered to calls to quantu...
-
[5]
front layer
Extracting circuit structure from QIR Qubit mapping and routing in QLLVM operate on QIR functions after lowering from MLIR but before classi- cal backend code generation. QLLVM identifies quan- tum kernels by scanning for functions that contain calls to QIS intrinsics ( quantum qis). For each such func- tion, a CircuitExtractor reconstructs the circuit st...
-
[6]
SABRE-based mapping and routing QLLVM adopts the SABRE algorithm to perform hardware-aware qubit mapping and routing. The algo- rithm is implemented as a function-level LLVM pass that takes as input a QIR kernel function and a target cou- pling graph, and produces a new function in which ad- ditional SWAP gates have been inserted to satisfy the connectivi...
-
[7]
McArdle, S
S. McArdle, S. Endo, A. Aspuru-Guzik, S. C. Benjamin, and X. Yuan, Reviews of Modern Physics92, 015003 (2020)
2020
-
[8]
Robert, P
A. Robert, P. K. Barkoutsos, S. Woerner, and I. Taver- nelli, npj Quantum Information7, 38 (2021)
2021
-
[9]
Santagati, A
R. Santagati, A. Aspuru-Guzik, R. Babbush, M. De- groote, L. Gonz´ alez, E. Kyoseva, N. Moll, M. Oppel, R. M. Parrish, N. C. Rubin, M. Streif, C. S. Tauter- mann, H. Weiss, N. Wiebe, and C. Utschig-Utschig, Na- ture Physics20, 549 (2024)
2024
-
[10]
A. M. Smaldone and V. S. Batista, Journal of Chemical Theory and Computation20, 4901 (2024)
2024
-
[11]
A. M. Smaldone, Y. Shee, G. W. Kyro, C. Xu, N. P. Vu, R. Dutta, M. H. Farag, A. Galda, S. Kumar, E. Kyoseva, 8 and V. S. Batista, Chemical Reviews125, 5436 (2025)
2025
-
[12]
Ghazi Vakili, C
M. Ghazi Vakili, C. Gorgulla, J. Snider, A. Nigam, D. Bezrukov, D. Varoli, A. Aliper, D. Polykovsky, K. M. Padmanabha Das, H. Cox III, A. Lyakisheva, A. Hos- seini Mansob, Z. Yao, L. Bitar, D. Tahoulas, D. ˇCerina, E. Radchenko, X. Ding, J. Liu, F. Meng, F. Ren, Y. Cao, I. Stagljar, A. Aspuru-Guzik, and A. Zhavoronkov, Na- ture Biotechnology43, 1954 (2025)
1954
-
[13]
Y. Zhou, J. Chen, J. Cheng, X. Cao, Y. Zhang, G. Kare- more, M. Zitnik, F. T. Chong, J. Liu, T. Fu, and Z. Liang, npj Drug Discovery3, 1 (2026)
2026
-
[14]
Kandala, A
A. Kandala, A. Mezzacapo, K. Temme, M. Takita, M. Brink, J. M. Chow, and J. M. Gambetta, Nature549, 242 (2017)
2017
-
[15]
R. N. Tazhigulov, PRX Quantum3, 10.1103/PRXQuan- tum.3.040318 (2022)
-
[16]
Vorwerk, N
C. Vorwerk, N. Sheng, M. Govoni, B. Huang, and G. Galli, Nature Computational Science2, 424 (2022)
2022
-
[17]
P. Hrmo, B. Wilhelm, L. Gerster, M. W. van Mourik, M. Huber, R. Blatt, P. Schindler, T. Monz, and M. Ring- bauer, Nature Communications14, 2242 (2023)
2023
-
[18]
Maskara, S
N. Maskara, S. Ostermann, J. Shee, M. Kalinowski, A. McClain Gomez, R. Araiza Bravo, D. S. Wang, A. I. Krylov, N. Y. Yao, M. Head-Gordon, M. D. Lukin, and S. F. Yelin, Nature Physics21, 289 (2025)
2025
-
[19]
S. Kang, Y. Kim, and J. Kim, ACS Central Science11, 1921 (2025)
1921
-
[20]
Selisko, M
J. Selisko, M. Amsler, C. Wever, Y. Kawashima, G. Sam- sonidze, R. Ul Haq, F. Tacchino, I. Tavernelli, and T. Eckl, npj Computational Materials11, 325 (2025)
2025
-
[21]
L. K. Grover, inProceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, STOC ’96 (New York, NY, USA, 1996) pp. 212–219
1996
-
[22]
Shor, Siam Review26, 1484 (1999)
P. Shor, Siam Review26, 1484 (1999)
1999
-
[23]
Regev, J
O. Regev, J. ACM72, 10:1 (2025)
2025
-
[24]
Singkanipa, V
P. Singkanipa, V. Kasatkin, Z. Zhou, G. Quiroz, and D. A. Lidar, Physical Review X15, 021082 (2025)
2025
-
[25]
How to factor 2048 bit RSA integers with less than a million noisy qubits
C. Gidney, How to factor 2048 bit RSA integers with less than a million noisy qubits (2025), arXiv:2505.15917 [quant-ph]
work page internal anchor Pith review arXiv 2048
- [26]
-
[27]
J. Lau, K. Lim, H. Shrotriya, and L. Kwek, AAPPS Bul- letin32(2022)
2022
-
[28]
Wille, R
R. Wille, R. Meter, and Y. Naveh (2019) pp. 1234–1240
2019
-
[29]
Sivarajah, S
S. Sivarajah, S. Dilkes, A. Cowtan, W. Simmons, A. Edg- ington, and R. Duncan, Quantum Science and Technol- ogy6, 014003 (2020)
2020
-
[30]
Stade, L
Y. Stade, L. Burgholzer, and R. Wille, inProceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC Workshops ’25 (Association for Computing Machinery, New York, NY, USA, 2025) p. 1907–1915
2025
-
[31]
JavadiAbhari, S
A. JavadiAbhari, S. Patil, D. Kudrow, J. Heckey, A. Lvov, F. T. Chong, and M. Martonosi, inProceed- ings of the 11th ACM Conference on Computing Fron- tiers, CF ’14 (Association for Computing Machinery, New York, NY, USA, 2014)
2014
-
[32]
Pennylane: Automatic differentiation of hy- brid quantum-classical computations (2022), arXiv:1811.04968 [quant-ph]
work page internal anchor Pith review arXiv 2022
-
[33]
Quetschlich, L
N. Quetschlich, L. Burgholzer, and R. Wille, Quantum 7, 1062 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.