Recognition: unknown
When Flat Minima Fail: Characterizing INT4 Quantization Collapse After FP32 Convergence
Pith reviewed 2026-05-10 11:40 UTC · model grok-4.3
The pith
INT4 quantization error explodes after FP32 perplexity stops improving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
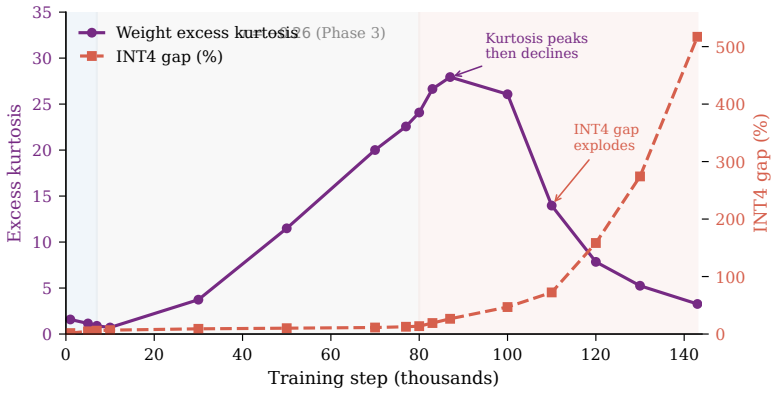
A calibration-free per-group INT4 probe applied to all 154 Pythia-160m checkpoints reveals a three-phase structure: rapid improvement while FP32 perplexity falls, a roughly 70,000-step meta-stable plateau, and an explosive divergence phase in which the INT4 gap grows from 11% to 517% exactly when FP32 perplexity converges, while INT8 remains stable and kurtosis measurements rule out outlier accumulation as the cause.
What carries the argument
The calibration-free per-group INT4 probe that measures the gap between FP32 and quantized perplexity at every training checkpoint without any calibration data or fine-tuning.
If this is right
- Post-convergence weight updates, not learning-rate decay itself, drive the growth in INT4 error.
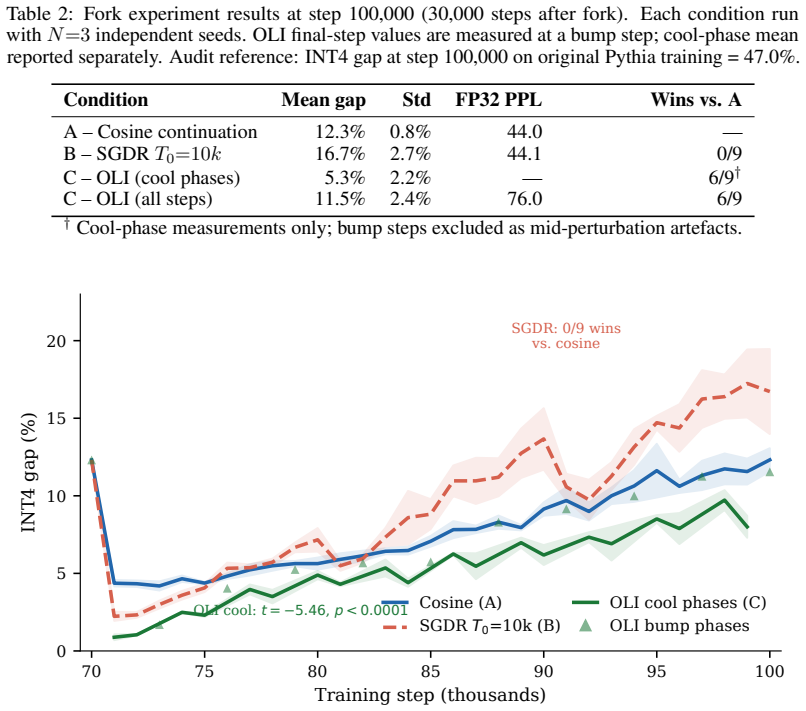
- Different learning-rate schedules after the plateau produce measurably different INT4 gaps, with SGDR accelerating collapse and certain oscillatory schedules reducing it.
- The failure is specific to the 16-level INT4 grid and does not occur under INT8 quantization.
Where Pith is reading between the lines
- Training recipes may need explicit monitoring of quantization readiness during the final stages rather than stopping at FP32 convergence.
- Schedule designs that keep the model in settled cool phases after convergence could preserve low-bit deployability without extra calibration.
- The same probe could be applied to other coarse quantization grids to test whether similar late-training instabilities exist.
Load-bearing premise
The three-phase divergence and its onset at FP32 convergence observed in Pythia-160m will appear in other model families, larger scales, and pipelines that include calibration or different grouping.
What would settle it
Running the identical per-group INT4 probe on the full checkpoint history of a different model family such as Llama and finding that the INT4 gap stays bounded after FP32 perplexity has converged.
Figures

read the original abstract
Post-training quantization (PTQ) assumes that a well-converged model is a quantization-ready model. We show this assumption fails in a structured, measurable, and previously uncharacterized way. Using a calibration-free per-group INT4 probe applied to all 154 publicly available Pythia-160m training checkpoints, we identify a three-phase divergence structure: a rapid-learning phase where both FP32 perplexity and quantization robustness improve together, a meta-stable plateau lasting roughly 70,000 steps where FP32 perplexity stagnates but INT4 gap remains bounded, and an explosive divergence phase where the INT4 gap compounds from 11% to 517% while FP32 perplexity barely moves. Critically, this divergence begins not when the learning rate starts decaying, but precisely when FP32 perplexity converges a finer-grained onset predictor that implies post-convergence weight updates, rather than decay magnitude alone, are the proximate cause. We further show that INT8 quantization is entirely immune throughout all three phases, constraining the mechanism to the coarseness of the 16-level INT4 grid specifically, and rule out weight outlier accumulation as the mechanism via direct kurtosis measurement. Finally, we conduct a controlled fork experiment from the pre-divergence checkpoint comparing three learning rate schedules (cosine continuation, SGDR warm restarts, and our proposed Oscillatory Lock-In) across nine independent runs. SGDR uniformly accelerates divergence (0/9 pairwise wins against cosine), while OLI's settled cool phases reduce the INT4 gap by 2.2 percentage points on average (t = -5.46, p < 0.0001), demonstrating that schedule amplitude calibration, not oscillation alone, determines whether perturbation helps or hurts. Our code, probe implementation, and all 154-checkpoint audit results are released publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the standard PTQ assumption—that a well-converged FP32 model is quantization-ready—fails for INT4 in a structured three-phase manner. Using a calibration-free per-group INT4 probe on all 154 public Pythia-160m checkpoints, it identifies a rapid-learning phase, a ~70k-step meta-stable plateau, and an explosive divergence phase where the INT4 gap grows from 11% to 517% precisely at FP32 perplexity convergence (not at LR decay onset). It shows the effect is INT4-specific (INT8 immune), not driven by weight outliers (via kurtosis), and that LR schedules matter: SGDR accelerates divergence while a proposed Oscillatory Lock-In schedule reduces the gap by 2.2 points on average (t=-5.46, p<0.0001) across 9 runs. Code, probe, and audit results are released.
Significance. If the three-phase structure and schedule sensitivity generalize, the work meaningfully challenges PTQ practice by providing a finer-grained onset predictor tied to post-convergence updates and demonstrating that training dynamics after FP32 convergence can be tuned to preserve quantization robustness. The public release of the 154-checkpoint audit, probe implementation, and reproducible fork experiments is a clear strength, enabling direct verification and extension.
major comments (2)
- [§3 and §5] §3 (Three-Phase Divergence) and §5 (Schedule Experiments): The central claim that post-convergence weight updates (rather than LR decay) drive INT4 collapse is supported by the checkpoint audit and fork results for Pythia-160m, but the manuscript tests only this single 160M model; without replication on at least one larger scale (>1B) or different family, the title's general characterization of INT4 collapse remains provisional.
- [§2] §2 (Quantization Probe): All reported INT4 gaps and phase timings derive from the calibration-free per-group probe; the paper does not benchmark this probe against standard calibrated PTQ pipelines (e.g., with calibration data or methods like GPTQ), leaving open whether the observed explosive divergence would appear under production quantization settings.
minor comments (3)
- [Methods] The definition of the INT4 gap metric (relative perplexity degradation) should be stated explicitly with its formula in the methods section for immediate clarity.
- [Figures] Figure captions for the phase plots and schedule comparisons should include exact step ranges and run counts to aid interpretation without cross-referencing the text.
- [Discussion] A brief discussion of why the meta-stable plateau lasts ~70k steps would strengthen the mechanistic interpretation even if speculative.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight key considerations around generalizability and alignment with production quantization practices. We address each major comment point by point below, with honest indications of planned revisions.
read point-by-point responses
-
Referee: [§3 and §5] §3 (Three-Phase Divergence) and §5 (Schedule Experiments): The central claim that post-convergence weight updates (rather than LR decay) drive INT4 collapse is supported by the checkpoint audit and fork results for Pythia-160m, but the manuscript tests only this single 160M model; without replication on at least one larger scale (>1B) or different family, the title's general characterization of INT4 collapse remains provisional.
Authors: We agree that the empirical foundation is limited to Pythia-160m and its 154 publicly released checkpoints. This scale was selected specifically because the full training trajectory is available for exhaustive auditing, which would not be possible for most larger models. Replicating the complete checkpoint audit and fork experiments on a >1B-parameter model or different family is not feasible at present, as it would require either equivalent public checkpoints or the compute to generate them. The title frames the contribution as a characterization of the observed phenomenon rather than a universal claim across all scales. In the revised manuscript we will add explicit scope statements in the introduction, abstract, and a dedicated limitations paragraph, while noting that the released probe and data enable community extensions. This is a partial revision. revision: partial
-
Referee: [§2] §2 (Quantization Probe): All reported INT4 gaps and phase timings derive from the calibration-free per-group probe; the paper does not benchmark this probe against standard calibrated PTQ pipelines (e.g., with calibration data or methods like GPTQ), leaving open whether the observed explosive divergence would appear under production quantization settings.
Authors: The calibration-free per-group probe was deliberately designed to isolate the intrinsic effect of post-convergence weight updates on quantization error, free from calibration-data selection or optimization artifacts. This choice enables a controlled measurement across every checkpoint. We acknowledge that the magnitude of divergence could differ under calibrated production pipelines such as GPTQ. To address the concern, the revised manuscript will include a new discussion subsection with a limited comparison: we will apply a simple per-group scaling calibration (using a small held-out calibration set) to representative checkpoints from each phase and report the resulting INT4 gaps. Full benchmarking against GPTQ on all 154 checkpoints is beyond the scope of this revision due to computational cost but will be flagged as valuable future work. This is a partial revision. revision: partial
Circularity Check
No circularity; results are direct empirical measurements from checkpoints and experiments
full rationale
The paper's central claims rest on applying a calibration-free per-group INT4 probe to all 154 public Pythia-160m checkpoints, documenting three observed phases in quantization gap behavior, timing relative to FP32 convergence, immunity of INT8, kurtosis measurements ruling out outliers, and controlled fork experiments comparing learning rate schedules. No equations, derivations, or fitted parameters are present. No self-citations are load-bearing for any premise, no ansatzes are smuggled, and no results are renamed known patterns or self-defined by construction. All findings are falsifiable via the released code and checkpoint audits, making the work self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Pythia-160m architecture and its public training checkpoints are representative for characterizing INT4 quantization behavior during training.
- domain assumption The calibration-free per-group INT4 probe produces measurements that reflect practical post-training quantization outcomes.
Reference graph
Works this paper leans on
-
[1]
Biderman, H
S. Biderman, H. Schoelkopf, Q. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. InInternational Conference on Machine Learning, 2023
2023
-
[2]
Training dynamics impact post-training quantization robustness.arXiv preprint arXiv:2510.06213,
A. Catalan-Tatjer, N. Ajroldi, and J. Geiping. Training dynamics impact post-training quantiza- tion robustness, 2026. URLhttps://arxiv.org/abs/2510.06213
- [3]
-
[4]
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur. Sharpness-aware minimization for efficiently improving generalization, 2021. URLhttps://arxiv.org/abs/2010.01412
-
[5]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers, 2023. URL https://arxiv.org/abs/2210.17323
work page internal anchor Pith review arXiv 2023
-
[6]
L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review arXiv 2020
-
[7]
Gholami, S
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer. A survey of quantization methods for efficient neural network inference, 2021. URL https://arxiv.org/abs/2103. 13630
2021
-
[8]
S. Hochreiter and J. Schmidhuber. Flat minima.Neural Computation, 9(1):1–42, 01 1997. ISSN 0899-7667. doi: 10.1162/neco.1997.9.1.1. URL https://doi.org/10.1162/neco. 1997.9.1.1
-
[9]
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On large-batch training for deep learning: Generalization gap and sharp minima, 2017. URL https://arxiv. org/abs/1609.04836
work page internal anchor Pith review arXiv 2017
- [10]
-
[11]
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han. AWQ: Activation-aware weight quantization for on-device llm compression and acceleration. InProceedings of Machine Learning and Systems, 2024
2024
-
[12]
Loshchilov and F
I. Loshchilov and F. Hutter. SGDR: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations, 2017
2017
-
[13]
Nagel, M
M. Nagel, M. Fournarakis, R. A. Amjad, Y . Bondarenko, M. van Baalen, and T. Blankevoort. A white paper on neural network quantization, 2021. URL https://arxiv.org/abs/2106. 08295
2021
-
[14]
J. Park, T. Lee, C. Yoon, H. Hwang, and J. Kang. Outlier-safe pre-training for robust 4-bit quantization of large language models. 2025. 9
2025
-
[15]
J. Su, Y . Lu, S. Pan, B. Wen, and Y . Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021
work page internal anchor Pith review arXiv 2021
- [16]
-
[17]
how fixable is this model’s quantization error
H. Yang, X. Yang, N. Z. Gong, and Y . Chen. Hero: Hessian-enhanced robust optimization for unifying and improving generalization and quantization performance, 2021. URL https: //arxiv.org/abs/2111.11986. A Probe Implementation Details Calibration-free design rationale.We deliberately exclude calibration data from our quantization probe. Methods like GPTQ ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.