Recognition: unknown
Majority Voting for Code Generation
Pith reviewed 2026-05-10 09:17 UTC · model grok-4.3
The pith
Functional majority voting on execution signatures selects better code solutions from LLMs and improves benchmark performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
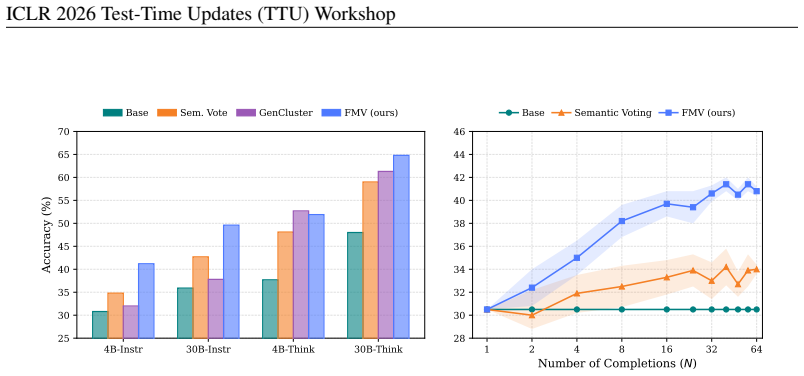
Functional Majority Voting identifies a representative solution from multiple LLM generations by matching their runtime execution signatures on test inputs. This approach substantially boosts performance on LiveCodeBench as a test-time inference strategy with modest compute cost. When applied as an aggregation strategy in label-free Test-Time Reinforcement Learning, it increases pass@1 on holdout tasks without showing self-improvement past the base model's performance ceiling.
What carries the argument
Functional Majority Voting (FMV), which aggregates generations by consensus on their execution behavior rather than syntax or probability.
If this is right
- Multiple generations can be turned into higher accuracy without retraining the model.
- Only a small number of test inputs are needed to compute the consensus.
- The method adds little overhead compared to the cost of generating the samples.
- Functional consensus can create pseudo-rewards for improving the model on unseen tasks.
- No automatic further gains beyond the model's inherent capability are observed.
Where Pith is reading between the lines
- If the test inputs fail to distinguish correct from plausible-wrong code, the vote may select incorrect solutions.
- This voting could be applied to other generative tasks where outputs can be executed or evaluated for equivalence.
- Combining FMV with other selection methods might yield further gains.
- Scalability to very complex code with long-running tests needs checking.
Load-bearing premise
That the test inputs are sufficient to make different code behaviors produce distinct signatures, so majority agreement indicates correctness.
What would settle it
A set of tasks where many incorrect code generations agree on passing the given test inputs but fail on additional hidden tests, while the correct code differs on the provided tests.
Figures

read the original abstract
We investigate Functional Majority Voting (FMV), a method based on functional consensus for code generation with Large Language Models, which identifies a representative solution from multiple generations using their runtime execution signatures on test inputs. We find that FMV is an effective test-time inference strategy, substantially boosting performance on LiveCodeBench without a large compute overhead. Furthermore, we extend the utility of functional consensus and apply it as an aggregation strategy for label-free Test-Time Reinforcement Learning. We demonstrate that this increases pass@1 on holdout tasks, but find no evidence of self-improvement beyond the base model's performance ceiling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Functional Majority Voting (FMV), a test-time inference method for LLM code generation that selects a representative solution from multiple generations based on consensus in their runtime execution signatures on test inputs. It claims FMV substantially boosts performance on LiveCodeBench with low compute overhead. The work further applies functional consensus as an aggregation strategy in label-free Test-Time Reinforcement Learning (TT-RL), reporting increased pass@1 on holdout tasks but no evidence of self-improvement beyond the base model's performance ceiling.
Significance. If the empirical claims hold under scrutiny, FMV offers a lightweight, label-free approach to improving code generation accuracy at inference time and enables practical aggregation for test-time RL without requiring ground-truth labels. The reported absence of self-improvement is a useful negative result that clarifies the method's limits. The core idea of using execution signatures for consensus could generalize to other program synthesis tasks if the underlying assumption about signature agreement proving correctness is validated.
major comments (2)
- [Abstract] Abstract: The abstract asserts that FMV 'substantially boosting performance on LiveCodeBench' and that functional consensus 'increases pass@1 on holdout tasks,' yet provides no quantitative numbers, error bars, ablation details, number of generations per problem, number of test inputs, or statistical significance. This absence prevents verification of the central performance claims and their magnitude.
- [Method / Experiments] Method and experimental sections: The central claim that FMV improves performance rests on the premise that agreement on execution signatures across generated programs reliably signals correctness rather than common incorrect behaviors. No analysis is provided to verify that the chosen test inputs provide sufficient coverage to distinguish correct implementations from frequent failure modes (e.g., off-by-one errors or missing edge cases that agree on the given inputs). This assumption is load-bearing for both the LiveCodeBench results and the TT-RL aggregation step.
minor comments (2)
- [Method] The description of how execution signatures are extracted, normalized, and compared (e.g., handling of non-deterministic outputs or floating-point precision) is not detailed enough for reproducibility.
- [Experiments] The manuscript would benefit from explicit discussion of the number of test inputs used per problem and any sensitivity analysis to the choice or coverage of those inputs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, agreeing where revisions are warranted and providing clarifications on the manuscript's existing content and planned updates.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that FMV 'substantially boosting performance on LiveCodeBench' and that functional consensus 'increases pass@1 on holdout tasks,' yet provides no quantitative numbers, error bars, ablation details, number of generations per problem, number of test inputs, or statistical significance. This absence prevents verification of the central performance claims and their magnitude.
Authors: We agree that the abstract would be strengthened by including key quantitative details to make the claims more verifiable at a glance. The full results, including performance deltas, generation counts, and test input details, are reported in the experimental sections with tables and figures. In the revised version, we will expand the abstract to incorporate specific numbers (e.g., absolute and relative gains on LiveCodeBench), the number of generations per problem, the number of test inputs used for signature comparison, and any available statistical measures such as standard deviations. This change will keep the abstract concise while improving transparency. revision: yes
-
Referee: [Method / Experiments] Method and experimental sections: The central claim that FMV improves performance rests on the premise that agreement on execution signatures across generated programs reliably signals correctness rather than common incorrect behaviors. No analysis is provided to verify that the chosen test inputs provide sufficient coverage to distinguish correct implementations from frequent failure modes (e.g., off-by-one errors or missing edge cases that agree on the given inputs). This assumption is load-bearing for both the LiveCodeBench results and the TT-RL aggregation step.
Authors: This is a substantive concern about the discriminative power of the test inputs. The inputs are those supplied by the LiveCodeBench benchmark itself, which are designed to assess functional correctness across a range of cases. We acknowledge that the manuscript does not include an explicit analysis of cases where incorrect programs might share execution signatures on these inputs. To address this, we will add a dedicated paragraph or short subsection discussing this assumption, including an empirical examination of instances where the majority vote selects an incorrect solution (i.e., agreement on wrong behavior) and any observed common failure modes. We will also note the number of test inputs per problem and their role in the TT-RL aggregation. This addition will clarify the limits of the approach without requiring new experiments. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations or self-referential reductions
full rationale
The paper contains no equations, derivations, fitted parameters, or mathematical predictions. Its central claims rest on experimental observations of pass@1 improvements from Functional Majority Voting on LiveCodeBench and holdout tasks, which are directly falsifiable against external benchmarks and code execution. No load-bearing step reduces a result to its own inputs by construction, self-citation chains, or ansatz smuggling. The method is defined descriptively from runtime signatures and evaluated empirically, remaining self-contained against independent test suites.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
a is b" fail to learn
Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. The reversal curse: Llms trained on "a is b" fail to learn "b is a". In ICLR, 2024
2024
-
[2]
Codet: Code generation with generated tests
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. Codet: Code generation with generated tests. In ICLR, 2023
2023
-
[3]
Divide-and-conquer meets consensus: Unleashing the power of functions in code generation
Jingchang Chen, Hongxuan Tang, Zheng Chu, Qianglong Chen, Zekun Wang, Ming Liu, and Bing Qin. Divide-and-conquer meets consensus: Unleashing the power of functions in code generation. In NeurIPS, 2024
2024
-
[4]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. In ICLR, 2025
2025
-
[5]
Semantic voting: A self-evaluation-free approach for efficient llm self-improvement on unverifiable open-ended tasks
Chunyang Jiang, Yonggang Zhang, Yiyang Cai, Chi-Min Chan, Yulong Liu, Mingming Chen, Wei Xue, and Yike Guo. Semantic voting: A self-evaluation-free approach for efficient llm self-improvement on unverifiable open-ended tasks. In ICLR, 2026
2026
-
[6]
Gonzalez, and Ion Stoica
Dacheng Li, Shiyi Cao, Chengkun Cao, Xiuyu Li, Shangyin Tan, Kurt Keutzer, Jiarong Xing, Joseph E. Gonzalez, and Ion Stoica. S*: Test time scaling for code generation. In EMNLP, 2025
2025
-
[7]
Competition-level code generation with alphacode
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R \'e mi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. Science, 378 0 (6624): 0 1092--1097, 2022
2022
-
[8]
A Theoretical Analysis of Test-Driven Code Generation
Nicolas Menet, Michael Hersche, Andreas Krause, and Abbas Rahimi. A theoretical analysis of test-driven llm code generation. arXiv preprint arXiv:2602.06098, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Marianna Nezhurina, Lucia Cipolina-Kun, Mehdi Cherti, and Jenia Jitsev. Alice in wonderland: Simple tasks showing complete reasoning breakdown in state-of-the-art large language models. arXiv preprint arXiv:2406.02061, 2024
-
[10]
Scaling Test-Time Compute to Achieve IOI Gold Medal with Open-Weight Models
Mehrzad Samadi, Aleksander Ficek, Sean Narenthiran, Siddhartha Jain, Wasi Uddin Ahmad, Somshubra Majumdar, Vahid Noroozi, and Boris Ginsburg. Scaling test-time compute to achieve ioi gold medal with open-weight models. arXiv preprint arXiv:2510.14232, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Freda Shi, Daniel Fried, Marjan Ghazvininejad, Luke Zettlemoyer, and Sida I. Wang. Natural language to code translation with execution. In EMNLP, 2022
2022
-
[12]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In ICLR, 2023
2023
-
[13]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Ttrl: Test-time reinforcement learning
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, et al. Ttrl: Test-time reinforcement learning. In NeurIPS, 2025
2025
-
[15]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[16]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[17]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[18]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.