Recognition: unknown
Similarity-Based Bike Station Expansion via Hybrid Denoising Autoencoders
Pith reviewed 2026-05-10 09:10 UTC · model grok-4.3
The pith
Hybrid denoising autoencoders identify promising bike station expansion sites by matching urban feature patterns of existing stations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
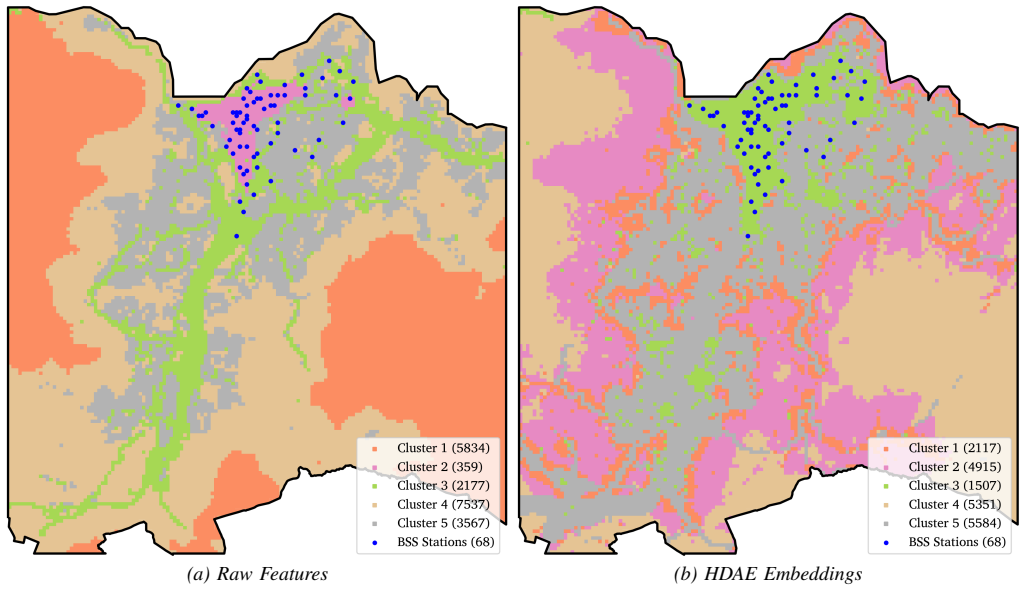
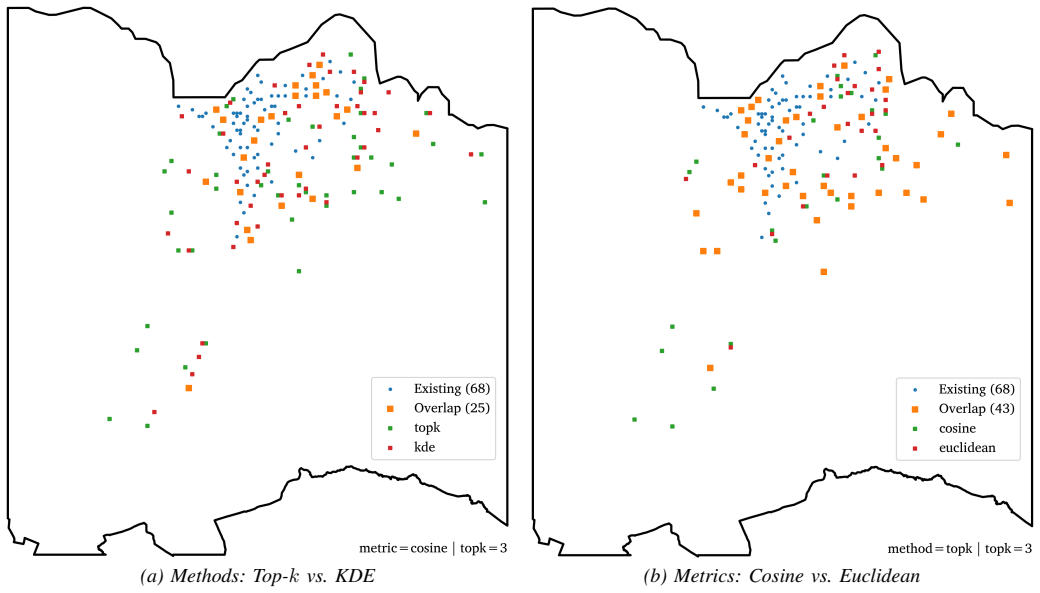
The paper claims that training a hybrid denoising autoencoder on grid-level socio-demographic, built environment, and transport features of desirable existing bike stations produces latent embeddings suitable for similarity-based expansion. When combined with greedy allocation under spatial constraints, these embeddings generate allocation patterns that are more spatially coherent than those from raw features. A consensus procedure across multiple model parametrisations isolates 32 high-confidence zones agreed upon by every parametrisation.
What carries the argument
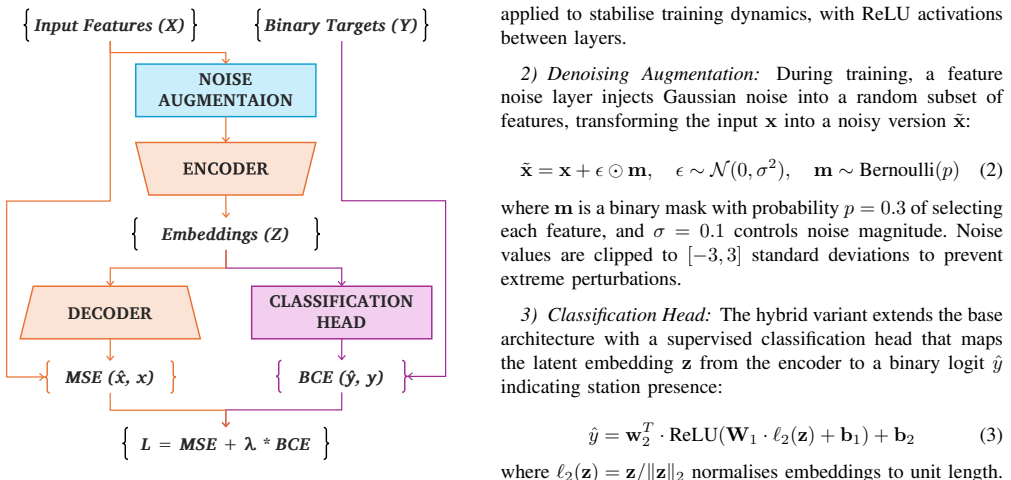
The hybrid denoising autoencoder (HDAE) with an added supervised classification head that structures the latent space so that similarity searches can select new stations resembling existing successful ones.
If this is right
- Expansion planning becomes possible using only data on current stations without explicit demand forecasting.
- Allocations respect spatial constraints while prioritizing feature similarity in the learned space.
- Multiple parametrisations can be run to find zones where recommendations converge, boosting reliability.
- The framework can be configured with different similarity measures and metrics while remaining robust.
- It applies to any location-allocation task that uses existing good examples to pick new ones.
Where Pith is reading between the lines
- Planners in cities with sparse data could apply this to bootstrap network growth using public geographic datasets.
- The same embedding approach might help site other urban facilities like parks or charging stations.
- Adding temporal usage data to the features could make the latent space reflect actual performance more directly.
- Testing the recommended zones in a pilot expansion would reveal if usage matches predictions from similarity alone.
Load-bearing premise
That the multi-source features around existing stations encode the key urban traits that make stations successful enough for similarity in the latent space to predict effective new locations.
What would settle it
Observing that stations placed at the recommended high-confidence zones have significantly lower ridership or higher maintenance costs than stations selected through traditional demand modeling after one year of operation.
Figures





read the original abstract
Urban bike-sharing systems require strategic station expansion to meet growing demand. Traditional allocation approaches rely on explicit demand modelling that may not capture the urban characteristics distinguishing successful stations. This study addresses the need to exploit patterns from existing stations to inform expansion decisions, particularly in data-constrained environments. We present a data-driven framework leveraging existing stations deemed desirable by operational metrics. A hybrid denoising autoencoder (HDAE) learns compressed latent representations from multi-source grid-level features (socio-demographic, built environment, and transport network), with a supervised classification head regularising the embedding space structure. Expansion candidates are selected via greedy allocation with spatial constraints based on latent-space similarity to existing stations. Evaluation on Trondheim's bike-sharing network demonstrates that HDAE embeddings yield more spatially coherent clusters and allocation patterns than raw features. Sensitivity analyses across similarity methods and distance metrics confirm robustness. A consensus-based procedure across multiple parametrisations distils 32 high-confidence extension zones where all parametrisations agree. The results demonstrate how representation learning captures complex patterns that raw features miss, enabling evidence-based expansion planning without explicit demand modelling. The consensus procedure strengthens recommendations by requiring agreement across parametrisations, while framework configurability allows planners to incorporate operational knowledge. The methodology generalises to any location-allocation problem where existing desirable instances inform the selection of new candidates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid denoising autoencoder (HDAE) framework that learns compressed latent representations from multi-source grid-level features (socio-demographic, built environment, and transport network) of existing desirable bike stations, regularized by a supervised classification head on operational metrics. Expansion candidates are then selected via greedy allocation under spatial constraints using latent-space similarity to existing stations. On Trondheim data, the approach is claimed to produce more spatially coherent clusters and allocation patterns than raw features, with a consensus procedure across parametrizations yielding 32 high-confidence extension zones.
Significance. If the latent representations reliably generalize beyond the training distribution to identify sites with higher actual usage, the method could offer a useful alternative to explicit demand modeling for location-allocation tasks. The consensus procedure and configurability are positive features for practical deployment. However, the reported evidence is limited to spatial coherence and hyperparameter robustness, so the practical significance for improving network performance remains to be demonstrated.
major comments (3)
- [Evaluation] Evaluation section: The central claim that HDAE embeddings yield superior allocation patterns rests on qualitative descriptions of spatial coherence and a consensus set of 32 zones, but provides no quantitative metrics (e.g., silhouette scores, adjusted Rand index, or comparison against baselines such as raw-feature k-means or standard demand models), baseline comparisons, error bars, or details on data splits and evaluation criteria.
- [Methodology] Methodology (supervised head and similarity selection): The supervised classification head regularizes the embedding using the same operational labels that define desirable stations, yet no test (e.g., spatial cross-validation or correlation with held-out ridership data) is presented to show that latent similarity identifies new sites with higher usage rather than simply reproducing the training distribution of existing stations.
- [Results] Results (consensus procedure): The identification of 32 high-confidence zones is presented as strengthening recommendations, but without a predictive validation step measuring actual or simulated demand at those sites versus alternatives, it does not directly support the claim that the method improves expansion outcomes over raw features or other heuristics.
minor comments (1)
- [Abstract] Abstract: The statement that 'sensitivity analyses across similarity methods and distance metrics confirm robustness' would benefit from explicit mention of the parameter ranges tested and the quantitative criteria used for robustness.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript. We provide point-by-point responses to the major comments below and indicate the revisions we will make to address them.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The central claim that HDAE embeddings yield superior allocation patterns rests on qualitative descriptions of spatial coherence and a consensus set of 32 zones, but provides no quantitative metrics (e.g., silhouette scores, adjusted Rand index, or comparison against baselines such as raw-feature k-means or standard demand models), baseline comparisons, error bars, or details on data splits and evaluation criteria.
Authors: We concur that the evaluation would benefit from quantitative support. In the revised version, we will augment the Evaluation section with quantitative metrics including silhouette scores for assessing cluster quality in the latent space versus raw feature space, adjusted Rand index for allocation comparisons where ground truth clusters are available, and direct comparisons to baselines such as k-means on raw features and perhaps standard demand modeling approaches if data allows. Details on data splits, training procedures, and evaluation criteria will be explicitly stated. Error bars or variance measures will be included for the sensitivity analyses. These changes will provide a stronger, more objective foundation for our claims regarding superior spatial coherence. revision: yes
-
Referee: [Methodology] Methodology (supervised head and similarity selection): The supervised classification head regularizes the embedding using the same operational labels that define desirable stations, yet no test (e.g., spatial cross-validation or correlation with held-out ridership data) is presented to show that latent similarity identifies new sites with higher usage rather than simply reproducing the training distribution of existing stations.
Authors: The supervised head leverages operational metrics to shape the latent representations, aiming to capture characteristics of desirable stations. We recognize that without explicit tests like spatial cross-validation, it is difficult to fully rule out reproduction of the training distribution. We will add a discussion of this potential limitation in the revised manuscript. Additionally, we will attempt to implement a form of spatial cross-validation by partitioning the existing stations and evaluating the selection process on held-out stations, correlating with their known operational metrics. This will help demonstrate the method's ability to identify similar high-performing sites. revision: partial
-
Referee: [Results] Results (consensus procedure): The identification of 32 high-confidence zones is presented as strengthening recommendations, but without a predictive validation step measuring actual or simulated demand at those sites versus alternatives, it does not directly support the claim that the method improves expansion outcomes over raw features or other heuristics.
Authors: We agree that predictive validation on actual demand would provide the strongest evidence, but this is inherently limited in a prospective planning study as the proposed sites do not yet have stations. The consensus procedure is designed to identify zones where multiple model configurations agree, thereby increasing robustness. In the revision, we will revise the language in the Results and Conclusion to more carefully frame the contributions as providing a data-driven, similarity-based approach for candidate selection in data-scarce settings, rather than claiming direct improvement in outcomes. We will also include a forward-looking discussion on the importance of monitoring actual usage post-expansion to validate the recommendations. revision: partial
- Providing direct predictive validation or correlation with held-out ridership data for the proposed new sites, since these are future expansion locations without existing usage data.
Circularity Check
Standard representation-learning pipeline with no self-referential reductions
full rationale
The manuscript presents a hybrid denoising autoencoder trained on grid-level features with an auxiliary supervised classification head, followed by latent-space nearest-neighbor selection and post-hoc evaluation on cluster coherence and cross-parametrisation consensus. No equation, derivation step, or self-citation reduces the reported spatial-coherence or consensus outcomes to a fitted parameter or input label by construction. The workflow is a conventional empirical ML pipeline whose performance claims rest on held-out spatial patterns rather than tautological re-use of the same quantities.
Axiom & Free-Parameter Ledger
free parameters (1)
- autoencoder hyperparameters
axioms (1)
- domain assumption Multi-source grid features around existing stations encode the characteristics that make stations operationally desirable.
Reference graph
Works this paper leans on
-
[1]
J. Malczewski, “On the Use of Weighted Linear Com- bination Method in GIS: Common and Best Practice Approaches,” Transactions in GIS , vol. 4, no. 1, pp. 5– 22, 2000, eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/1467- 9671.00035. [Online]. Available: https://onlinelibrary.wiley.com/doi/abs/ 10.1111/1467-9671.00035
-
[2]
The Maximal Covering Location Problem,
R. Church and C. R. Velle, “The Maximal Covering Location Problem,” Papers in Regional Science , vol. 32, no. 1, pp. 101–118, Jan
-
[3]
Available: https://www.sciencedirect.com/science/article/ pii/S1056819023021395
[Online]. Available: https://www.sciencedirect.com/science/article/ pii/S1056819023021395
-
[4]
Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion,
P. Vincent, H. Larochelle, I. Lajoie, Y . Bengio, and P.-A. Manzagol, “Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion,” Journal of Machine Learning Research , vol. 11, no. 110, pp. 3371–3408, 2010. [Online]. Available: http://jmlr.org/papers/v11/vincent10a.html
2010
-
[5]
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
K. He, X. Zhang, S. Ren, and J. Sun, “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification,” Feb. 2015, arXiv:1502.01852 [cs]. [Online]. Available: http://arxiv.org/abs/ 1502.01852
work page Pith review arXiv 2015
-
[6]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer Normalization,” Jul. 2016, arXiv:1607.06450 [stat]. [Online]. Available: http://arxiv.org/abs/ 1607.06450
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” Jan. 2017, arXiv:1412.6980 [cs]. [Online]. Available: http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
S. M. Lundberg and S.-I. Lee, “A Unified Approach to Interpreting Model Predictions,” in Proceedings of the 31st International Conference on Neural Information Processing Systems , ser. NIPS’17. Red Hook, NY , USA: Curran Associates Inc., Dec. 2017, pp. 4768–4777. [Online]. Available: https://dl.acm.org/doi/10.5555/3295222.3295230
-
[9]
A Density-Based Algo- rithm for Discovering Clusters in Large Spatial Databases with Noise,
M. Ester, H.-P. Kriegel, J. Sander, and X. Xu, “A Density-Based Algo- rithm for Discovering Clusters in Large Spatial Databases with Noise,” in Proceedings of the Second International Conference on Knowledge Discovery and Data Mining , ser. KDD’96. Portland, Oregon: AAAI Press, Aug. 1996, pp. 226–231
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.