Recognition: unknown
Placing Puzzle Pieces Where They Matter: A Question Augmentation Framework for Reinforcement Learning
Pith reviewed 2026-05-10 08:24 UTC · model grok-4.3
The pith
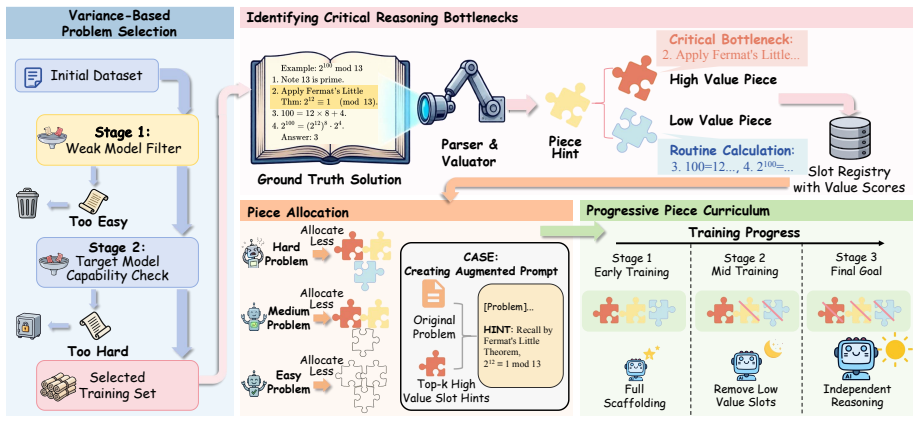
PieceHint strategically scores and injects critical reasoning hints in RL training to let a 1.5B model match 32B baselines on math benchmarks while preserving pass@k diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experiments on six mathematical reasoning benchmarks show that our 1.5B model achieves comparable average performance to 32B baselines while preserving pass@k diversity across all k values.
Load-bearing premise
That an importance-scoring procedure can reliably identify critical reasoning bottlenecks, that selective hint allocation based on difficulty avoids both redundancy and under-guidance, and that progressive hint withdrawal produces genuine independent reasoning rather than just masking overfitting.
Figures



read the original abstract
Reinforcement learning has become a powerful approach for enhancing large language model reasoning, but faces a fundamental dilemma: training on easy problems can cause overfitting and pass@k degradation, while training on hard problems often results in sparse rewards. Recent question augmentation methods address this by prepending partial solutions as hints. However, uniform hint provision may introduce redundant information while missing critical reasoning bottlenecks, and excessive hints can reduce reasoning diversity, causing pass@k degradation. We propose \textbf{PieceHint}, a hint injection framework that strategically identifies and provides critical reasoning steps during training. By scoring the importance of different reasoning steps, selectively allocating hints based on problem difficulty, and progressively withdrawing scaffolding, PieceHint enables models to transition from guided learning to independent reasoning. Experiments on six mathematical reasoning benchmarks show that our 1.5B model achieves comparable average performance to 32B baselines while preserving pass@k diversity across all $k$ values.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PieceHint, a question augmentation framework for RL-based LLM reasoning on mathematical tasks. It identifies critical reasoning steps via importance scoring, allocates hints selectively by problem difficulty, and progressively withdraws scaffolding to transition from guided to independent reasoning. The central claim, based on experiments with six benchmarks, is that a 1.5B model achieves average performance comparable to 32B baselines while preserving pass@k diversity across k values.
Significance. If substantiated, the approach could meaningfully advance efficient training of smaller models on complex reasoning by mitigating overfitting on easy problems and sparse rewards on hard ones, while maintaining output diversity. The progressive withdrawal mechanism offers a promising direction for adaptive scaffolding in RL for LLMs.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments: The headline claim of comparable average performance to 32B baselines and preserved pass@k diversity is stated without any details on the six benchmarks, exact metrics, baseline models and training regimes, scoring function, statistical tests, or pass@k measurement protocol. This absence makes the data-to-claim link impossible to evaluate and is load-bearing for the central result.
- [Method] Method: The importance-scoring procedure and difficulty-based allocation are described at a high level, yet the scoring function, thresholds, and any validation (human evaluation, error correlation, or ablation isolating it from uniform-hint or generic RL baselines) are not provided. Without these, it cannot be established that hints target genuine reasoning bottlenecks rather than artifacts.
- [Method and Experiments] Method and Experiments: No analysis or ablation demonstrates that progressive hint withdrawal produces genuine independent reasoning gains rather than the model exploiting residual patterns or that selective allocation avoids both redundancy and under-guidance. This directly affects the weakest assumption underlying the framework's claimed advantages.
minor comments (1)
- [Abstract] The phrase 'preserving pass@k diversity across all k values' should be accompanied by a precise definition or measurement formula to avoid ambiguity.
Circularity Check
No circularity: empirical method validated on external benchmarks
full rationale
The paper describes an empirical framework (importance scoring of reasoning steps, difficulty-based hint allocation, progressive withdrawal) whose effectiveness is measured via experiments on six independent mathematical reasoning benchmarks. No equations, fitted parameters, or derivations are presented that reduce the reported performance gains to a definition or self-referential construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on observable benchmark outcomes rather than tautological renaming or input-output equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- importance scoring function and thresholds
Reference graph
Works this paper leans on
-
[1]
Haonan Dong, Kehan Jiang, Haoran Ye, Wenhao Zhu, Zhaolu Kang, and Guojie Song
Prpo: Aligning process reward with out- come reward in policy optimization.arXiv preprint arXiv:2601.07182. Yangyi Fang, Jiaye Lin, Xiaoliang Fu, Cong Qin, Haolin Shi, Chaowen Hu, Lu Pan, Ke Zeng, and Xunliang Cai. 2026a. How to allocate, how to learn? dynamic rollout allocation and advantage modulation for pol- icy optimization.arXiv preprint arXiv:2602....
-
[2]
RewardBench 2: Advancing Reward Model Evaluation
Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. Notion Blog. MAA. 2023. American mathematics competitions - amc. MAA. 2025. American invitational mathematics exami- nation - aime. Saumya Malik, Valentina Pyatkin, Sander Land, Ja- cob Morrison, Noah A. Smith, Hannaneh Ha- jishirzi, and Nathan Lambert. 2025. Rewardbench 2: Advancing rewar...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Optimizing test-time compute via meta reinforcement fine-tuning
Curriculum reinforcement learning from easy to hard tasks improves llm reasoning. Yuxiao Qu, Matthew Y . R. Yang, Amrith Setlur, Lewis Tunstall, Edward Emanuel Beeching, Ruslan Salakhutdinov, and Aviral Kumar. 2025. Optimizing test-time compute via meta reinforcement fine-tuning. Preprint, arXiv:2503.07572. John Schulman, Filip Wolski, Prafulla Dhariwal, ...
-
[4]
Spurious rewards: Rethinking training signals in RLVR.arXiv preprint arXiv:2506.10947,
Spurious rewards: Rethinking training signals in rlvr.arXiv preprint arXiv:2506.10947. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, and 1 others. 2024. Deepseek- math: Pushing the limits of mathematical reason- ing in open language models.arXiv preprint arXiv:2402.03300. Guangming Sheng...
-
[5]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Math-shepherd: Verify and reinforce llms step-by-step without human annotations.Preprint, arXiv:2312.08935. Tianyi Wang, Long Li, Hongcan Guo, Yibiao Chen, Yixia Li, Yong Wang, Yun Chen, and Guanhua Chen. 2026a. Anchored policy optimization: Mitigating exploration collapse via support-constrained rectifi- cation.Preprint, arXiv:2602.05717. Tianyi Wang, Yi...
work page internal anchor Pith review arXiv 2025
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Fengkai Yang, Zherui Chen, Xiaohan Wang, Xiaodong Lu, Jiajun Chai, Guojun Yin, Wei Lin, Shuai Ma, Fuzhen Zhuang, Deqing Wang, and 1 others. 2026. Your group-relative advantage is biased.arXiv preprint arXiv:2601.08521. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
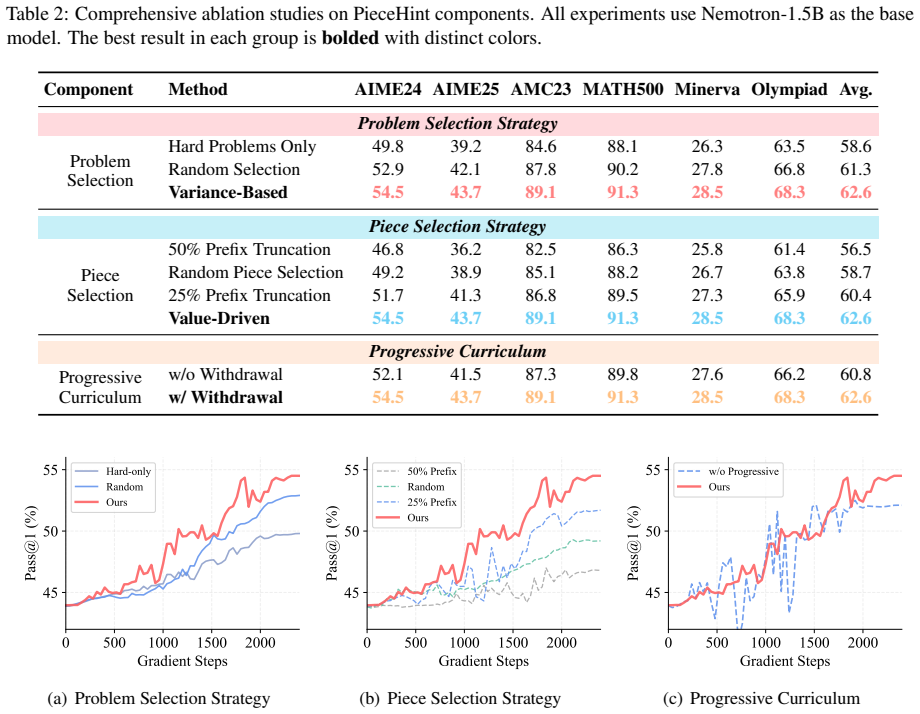
StepHint prepends the first 25% of ground- truth solution steps as positional prefix hints—the best-performing variant of StepHint as identified in our ablation studies (Table 2)
under identical experimental conditions: the same base model (Nemotron-1.5B), training dataset, hyperparameters, and computational bud- get. StepHint prepends the first 25% of ground- truth solution steps as positional prefix hints—the best-performing variant of StepHint as identified in our ablation studies (Table 2). Table 5 shows that PieceHint consist...
-
[8]
Score: 2
Restate condition in graph the- ory terms. Score: 2
-
[9]
Score: 2
Recognize this prevents com- plete graph. Score: 2
-
[10]
Score: 4
Hypothesize removing perfect matching. Score: 4
-
[11]
Score: 2
Calculate: 100 2 −50 = 4900 edges. Score: 2
-
[12]
Score: 5
Verify construction satisfies condition. Score: 5
-
[13]
same differ- ence
Conclude maximum is 4900.Score: 1 Normalized: Vmin = 1 , Vmax = 5⇒ D(pi): [0.25, 0.25, 0.75, 0.25, 1.00, 0.00] Step 5 receives the highest score as it criti- cally establishes correctness—without veri- fication, the construction remains unproven. J Case Study Problem Details This appendix provides complete details for the case study analyzed in the main t...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.