Recognition: no theorem link
CGCMA: Conditionally-Gated Cross-Modal Attention for Event-Conditioned Asynchronous Fusion
Pith reviewed 2026-05-13 22:32 UTC · model grok-4.3
The pith
A conditional gate in cross-modal attention achieves the highest Sharpe ratio by controlling fusion based on news freshness and agreement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
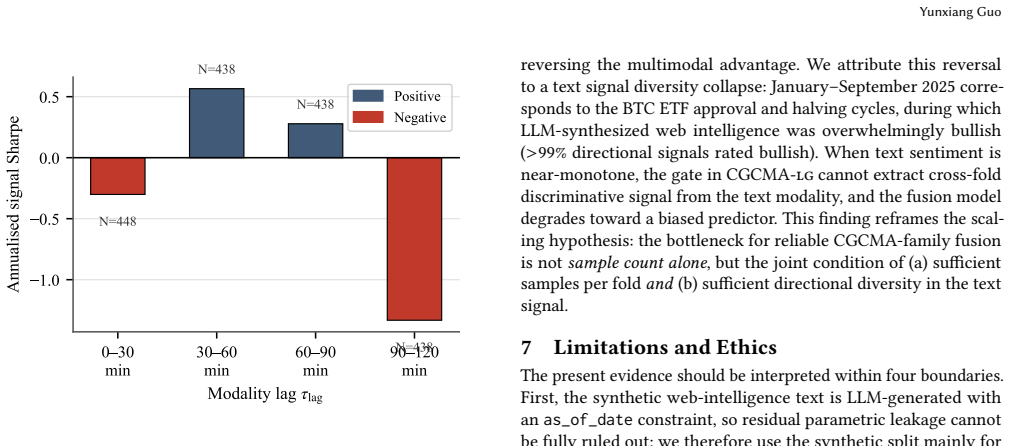
CGCMA separates text-conditioned grounding from lag-aware trust control. Text first attends over price sequences to identify event-relevant market states, after which a conditional gate uses modality agreement, web features, and lag to regulate residual injection and fall back toward unimodal prediction when external context is stale or contradictory. On the short real-news corpus this produces the highest mean downstream Sharpe ratio among baselines.
What carries the argument
The conditional gate, which regulates residual injection of attended text features into the price stream using modality agreement, web features, and lag τ_lag.
If this is right
- The model can default to unimodal price predictions when news is stale or contradictory.
- Gains on the corpus are not explained by web scalars alone and are not recovered by simple freshness rules.
- The approach provides evidence that explicit lag and agreement reasoning improves fusion in asynchronous settings.
- The design serves as a stress test for broader event-conditioned multimodal problems beyond finance.
Where Pith is reading between the lines
- The same separation of grounding and trust control could be tested on other sporadic-data domains such as sensor streams with occasional alerts.
- Extending the gate to learnable lag representations might further reduce reliance on explicit timestamps.
- The method suggests that attention-based fusion in general could benefit from an explicit trust stage after initial cross-attention.
Load-bearing premise
That performance gains on this high-frequency cryptocurrency corpus with limited real news are caused by the conditional gate rather than dataset particulars or unstated implementation choices.
What would settle it
An ablation that removes the conditional gate on the identical corpus and trading protocol, or a replication on a larger non-cryptocurrency asynchronous dataset, showing no improvement over simple freshness heuristics.
Figures

read the original abstract
We study asynchronous alignment, a first-class multimodal learning setting in which a dense primary stream must be fused with sporadic external context whose value depends on when it arrives. Unlike standard multimodal benchmarks that assume structural synchrony, this setting requires models to reason explicitly about freshness and trust. We focus on the event-conditioned case in which continuous market states are paired with delayed web intelligence, and we use high-frequency cryptocurrency markets only as a timestamped, high-noise stress test for this broader problem. We propose CGCMA (Conditionally-Gated Cross-Modal Attention), whose central design principle is to separate text-conditioned grounding from lag-aware trust control. Text first attends over price sequences to identify event-relevant market states, after which a conditional gate uses modality agreement, web features, and lag $\tau_{\mathrm{lag}}$ to regulate residual injection and fall back toward unimodal prediction when external context is stale or contradictory. We introduce CMI (Crypto Market Intelligence), an asynchronous evaluation corpus with 27,914 real-news samples pairing high-frequency price sequences with lagged web intelligence. On the current short real-news corpus, CGCMA attains the highest mean downstream Sharpe ratio ($+0.449 \pm 0.257$) among the evaluated baselines under a shared zero-cost threshold-trading evaluation on news-available bars. Additional controls show that the gain is not explained by web scalars alone and is not recovered by simple freshness heuristics. The resulting evidence supports problem validity and a promising asynchronous multimodal gain on this stress-test setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CGCMA, a conditionally-gated cross-modal attention architecture for asynchronous multimodal fusion in the event-conditioned setting. Continuous primary streams (high-frequency price sequences) are paired with sporadic external context (lagged web intelligence). The model first performs text-conditioned grounding over price sequences, then applies a conditional gate that incorporates modality agreement, web features, and lag τ_lag to control residual injection and fall back to unimodal prediction when context is stale or contradictory. A new corpus CMI (27,914 real-news samples) is introduced as a stress test. On this corpus, CGCMA reports the highest mean downstream Sharpe ratio (+0.449 ± 0.257) under a shared zero-cost threshold-trading protocol on news-available bars, with controls indicating the gain is not explained by web scalars or simple freshness heuristics alone.
Significance. If the reported Sharpe improvement is statistically reliable and generalizes beyond the current short real-news corpus, the work would provide a concrete, high-noise benchmark for asynchronous multimodal methods and a design principle (separation of grounding from lag-aware trust) that could transfer to other timestamped multimodal domains. The explicit handling of freshness and trust via the conditional gate addresses a gap in standard attention-based fusion models. The provision of a reproducible corpus and shared evaluation protocol strengthens the contribution.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): The central empirical claim reports a mean Sharpe ratio of +0.449 ± 0.257 for CGCMA. The standard error is large relative to the mean (implying a t-statistic near 1.75 if ± denotes SE), yet no information is given on the number of independent events, test periods, or bars underlying the statistic, nor are any direct comparisons (paired t-test, bootstrap CI, or p-value) provided against the next-best baseline. This leaves open whether the observed ordering is consistent with sampling variability.
- [§3.2] §3.2 (Conditional Gate): The description of the gate that uses modality agreement, web features, and τ_lag to regulate residual injection is presented at a high level. It is unclear whether the gate parameters are learned jointly with the attention weights or held fixed, and whether the fallback to unimodal prediction is implemented as a hard switch or a soft residual scaling. This detail is load-bearing for the claim that the gain arises from the conditional mechanism rather than from the cross-modal attention alone.
minor comments (2)
- [Abstract] The abstract states “additional controls show that the gain is not explained by web scalars alone,” but the specific control experiments (e.g., which scalars were ablated and their resulting Sharpe values) are not enumerated in the provided text.
- [Notation] Notation for the lag variable is introduced as τ_lag in the abstract; ensure consistent use of the same symbol throughout the method and experimental sections.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commit to revisions that strengthen the statistical reporting and methodological transparency.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): The central empirical claim reports a mean Sharpe ratio of +0.449 ± 0.257 for CGCMA. The standard error is large relative to the mean (implying a t-statistic near 1.75 if ± denotes SE), yet no information is given on the number of independent events, test periods, or bars underlying the statistic, nor are any direct comparisons (paired t-test, bootstrap CI, or p-value) provided against the next-best baseline. This leaves open whether the observed ordering is consistent with sampling variability.
Authors: We agree that the current reporting leaves the statistical reliability of the Sharpe ordering under-specified. The ±0.257 reflects the standard deviation of per-sample Sharpe ratios across the 27,914 news events rather than the standard error of the mean; we will explicitly state this distinction and report the underlying number of independent test periods and total bars evaluated. In the revision we will add bootstrap confidence intervals for the mean Sharpe and a paired non-parametric test (Wilcoxon signed-rank) against the next-best baseline, together with the exact number of news-available bars per period. These additions will directly address whether the observed ranking is consistent with sampling variability. revision: yes
-
Referee: [§3.2] §3.2 (Conditional Gate): The description of the gate that uses modality agreement, web features, and τ_lag to regulate residual injection is presented at a high level. It is unclear whether the gate parameters are learned jointly with the attention weights or held fixed, and whether the fallback to unimodal prediction is implemented as a hard switch or a soft residual scaling. This detail is load-bearing for the claim that the gain arises from the conditional mechanism rather than from the cross-modal attention alone.
Authors: We appreciate the referee pointing out this ambiguity in the gate description. The gate parameters are learned jointly with the attention weights via end-to-end gradient descent; no parameters are held fixed. The fallback is realized as soft residual scaling: a sigmoid-activated scalar (conditioned on modality agreement, web features, and τ_lag) multiplicatively gates the cross-modal residual before it is added to the unimodal price prediction. We will revise §3.2 to include the exact equations, the joint-training statement, and a short pseudocode block that makes the soft scaling explicit, thereby clarifying that the performance gain is attributable to the conditional mechanism. revision: yes
Circularity Check
No circularity: empirical claim rests on independent evaluation of a standard attention variant
full rationale
The manuscript proposes CGCMA as an attention architecture that first performs text-conditioned grounding over price sequences and then applies a conditional gate driven by modality agreement, web features, and lag τ_lag to control residual injection. No equations are supplied that define any quantity in terms of itself or that rename a fitted parameter as a prediction. The central result is an empirical Sharpe-ratio ordering on the newly introduced CMI corpus under a fixed zero-cost threshold-trading protocol; the ordering is presented as an observation on real data rather than a mathematical identity. No self-citation is invoked to establish uniqueness or to forbid alternatives. Because the derivation chain consists of an architectural design choice followed by direct measurement against external baselines, the result does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard attention mechanisms can identify event-relevant states in price sequences
invented entities (1)
-
Conditionally-gated cross-modal attention module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jethin Abraham, Daniel Higdon, John Nelson, and Juan Ibarra. 2018. Cryptocur- rency Price Prediction Using Tweet Volumes and Sentiment Analysis.SMU Data CGCMA: Conditionally-Gated Cross-Modal Attention for Event-Conditioned Asynchronous Fusion Science Review1, 3 (2018), 1–12
work page 2018
- [2]
-
[3]
Gated Multimodal Units for Information Fusion
Gated Multimodal Units for Information Fusion. arXiv:1702.01992
-
[4]
Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. 2019. Multi- modal Machine Learning: A Survey and Taxonomy.IEEE Transactions on Pattern Analysis and Machine Intelligence41, 2 (2019), 423–443
work page 2019
-
[5]
Kai Chen, Yi Zhou, and Fangyan Dai. 2021. Exploring the Attention Mechanism in LSTM-based Hong Kong Stock Price Movement Prediction.Quantitative Finance21, 9 (2021), 1507–1520
work page 2021
-
[6]
CryptoCompare. 2025. CryptoCompare News API. https://min-api. cryptocompare.com/documentation. Accessed March 2026
work page 2025
-
[7]
Shib Sankar Dasgupta, Swayambhatta Ray, and Partha Talukdar. 2018. HyTE: Hyperplane-based Temporally Aware Knowledge Graph Embedding. InProceed- ings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Brussels, Belgium, 2001– 2011
work page 2018
-
[8]
Xiao Ding, Yue Zhang, Ting Liu, and Junwen Duan. 2015. Deep Learning for Event-Driven Stock Prediction. InProceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI). AAAI Press, Buenos Aires, Argentina, 2327–2333
work page 2015
-
[9]
Fuli Feng, Huimin Chen, Xiangnan He, Ji Ding, Maosong Sun, and Tat-Seng Chua
-
[10]
Temporal Relational Ranking for Stock Prediction.ACM Transactions on Information Systems37, 2 (2019), 1–30
work page 2019
- [11]
-
[12]
Vincent Gurgul, Stefan Lessmann, and Wolfgang Karl Härdle. 2025. Deep Learn- ing and NLP in Cryptocurrency Forecasting: Integrating Financial, Blockchain, and Social Media Data.International Journal of Forecasting41, 4 (2025), 1666–1695. doi:10.1016/j.ijforecast.2025.02.007
-
[13]
Devamanyu Hazarika, Roger Zimmermann, and Soujanya Poria. 2020. MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis. InProceedings of the 28th ACM International Conference on Multimedia (ACM MM). ACM, New York, NY, 1122–1131
work page 2020
-
[14]
Arthur E. Hoerl and Robert W. Kennard. 1970. Ridge Regression: Biased Estima- tion for Nonorthogonal Problems.Technometrics12, 1 (1970), 55–67
work page 1970
-
[15]
Young Bin Kim, Jun Gi Kim, Wook Kim, Jae Ho Im, Tae Hyeong Kim, Shin Jin Kang, and Chang Hun Kim. 2016. Predicting Fluctuations in Cryptocurrency Transactions Based on User Comments and Replies.PLOS ONE11, 8 (2016), 1–17
work page 2016
-
[16]
Dániel Kondor, Márton Pósfai, István Csabai, and Gábor Vattay. 2014. Do the Rich Get Richer? An Empirical Analysis of the Bitcoin Transaction Network. PLOS ONE9, 2 (2014), e86197
work page 2014
- [17]
- [18]
-
[19]
Arik, Nicolas Loeff, and Tomas Pfister
Bryan Lim, Sercan O. Arik, Nicolas Loeff, and Tomas Pfister. 2021. Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. International Journal of Forecasting37, 4 (2021), 1748–1764
work page 2021
-
[20]
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. 2024. iTransformer: Inverted Transformers Are Effective for Time Series Forecasting. InThe Twelfth International Conference on Learning Representations (ICLR). OpenReview.net, Vienna, Austria. Paper ID JePfAI8fah
work page 2024
-
[21]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2023. A Time Series Is Worth 64 Words: Long-term Forecasting with Transformers. InThe Eleventh International Conference on Learning Representations (ICLR). OpenReview.net, Kigali, Rwanda. Paper ID r8sQPpGCv0
work page 2023
-
[22]
Yu Qin and Yi Yang. 2019. What You Say and How You Say It Matters: Predicting Stock Volatility Using Verbal and Vocal Cues. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, Florence, Italy, 390–401
work page 2019
-
[23]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Hong Kong, China, 3982–3992
work page 2019
-
[24]
Gerard Salton and Christopher Buckley. 1988. Term-Weighting Approaches in Automatic Text Retrieval.Information Processing & Management24, 5 (1988), 513–523
work page 1988
-
[25]
Ramit Sawhney, Shivam Agarwal, Arnav Wadhwa, and Rajiv Ratn Shah. 2020. Multimodal Multi-Task Financial Risk Forecasting. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Asso- ciation for Computational Linguistics, Online, 5656–5665
work page 2020
-
[26]
Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J. Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2019. Multimodal Transformer for Un- aligned Multimodal Language Sequences. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, Florence, Italy, 6558–6569
work page 2019
-
[27]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 30. Curran Associates, Red Hook, NY, 5998–6008
work page 2017
-
[28]
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. 2021. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Fore- casting. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 34. Curran Associates, Red Hook, NY, 22419–22430
work page 2021
-
[29]
Haixu Wu, Jianmin Xu, Jianmin Wang, and Mingsheng Long. 2023. Times- Net: Temporal 2D-Variation Modeling for General Time Series Analysis. InThe Eleventh International Conference on Learning Representations (ICLR). OpenRe- view.net, Kigali, Rwanda. Paper ID ju_Uqw384Oq
work page 2023
-
[30]
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023. BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564
work page internal anchor Pith review arXiv 2023
-
[31]
Yumo Xu and Shay B. Cohen. 2018. Stock Movement Prediction from Tweets and Historical Prices. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, Melbourne, Australia, 1970–1979
work page 2018
- [32]
- [33]
-
[34]
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Copenhagen, Denmark, 1103–1114
work page 2017
-
[35]
Amir Zadeh, Paul Pu Liang, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2018. Memory Fusion Network for Multi-view Sequential Learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI). AAAI Press, Palo Alto, CA, 5634–5641
work page 2018
-
[36]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. InProceedings of the 35th AAAI Conference on Artificial Intelligence. AAAI Press, Palo Alto, CA, 11106–11115
work page 2021
-
[37]
Yanzhao Zou and Dorien Herremans. 2023. PreBit – A Multimodal Model with Twitter FinBERT Embeddings for Extreme Price Movement Prediction of Bitcoin. Expert Systems with Applications233 (2023), 120838. doi:10.1016/j.eswa.2023. 120838
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.