Recognition: unknown
Double Descent in Quantum Kernel Ridge Regression
Pith reviewed 2026-05-10 06:39 UTC · model grok-4.3
The pith
Quantum kernel ridge regression exhibits double descent, with test risk peaking near the interpolation threshold before declining in the overparameterized regime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying deterministic equivalents from random matrix theory to the quantum kernel Gram matrix, the authors obtain a closed-form asymptotic expression for the test risk of QKRR. This expression rigorously locates the interpolation peak and demonstrates that adding an explicit regularization term suppresses the peak, with the suppression becoming exact in the high-dimensional limit. Numerical simulations on finite quantum systems confirm that the asymptotic predictions remain accurate even when the system size is modest.
What carries the argument
Deterministic equivalents from random matrix theory applied to the quantum kernel Gram matrix, which yield an exact asymptotic formula for the test risk as a function of the regularization parameter and the ratio of dimensions to samples.
If this is right
- The location and height of the interpolation peak in QKRR are given explicitly by the random-matrix formula.
- Increasing the regularization parameter reduces the height of the peak until it disappears.
- The asymptotic formula matches numerical results for modest numbers of qubits and training points.
- The same double-descent structure therefore appears in both quantum and classical kernel ridge regression.
Where Pith is reading between the lines
- Quantum kernel methods may gain reliability by deliberately entering the overparameterized regime rather than stopping at the interpolation threshold.
- The random-matrix approach could be reused to analyze double descent in other quantum kernel models or variational quantum algorithms.
- Hardware experiments with real quantum kernels would test whether noise or finite-shot effects preserve the predicted suppression by regularization.
Load-bearing premise
The quantum kernel Gram matrix must behave statistically like a random matrix whose eigenvalues are described by deterministic equivalents in the high-dimensional limit.
What would settle it
A simulation or hardware run of QKRR in which the test risk shows no peak at the interpolation threshold, or in which adding regularization leaves the peak unchanged, would contradict the derived asymptotic expression.
Figures

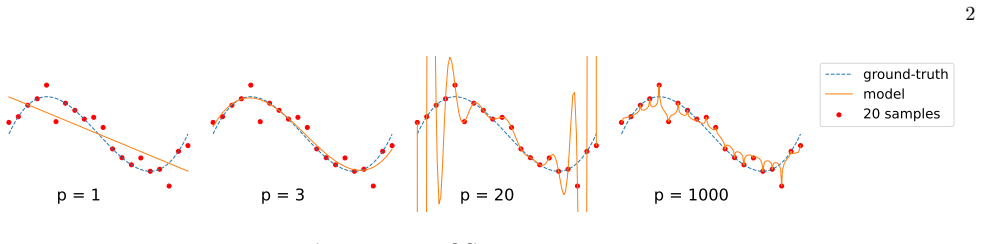




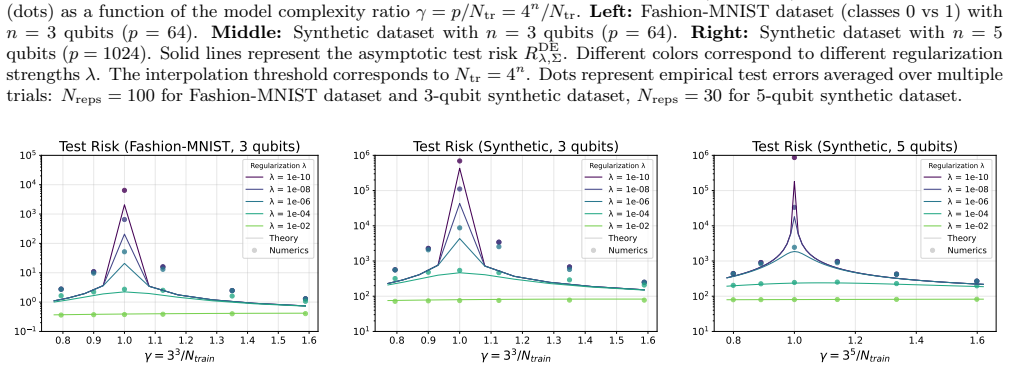


read the original abstract
Various classical machine learning models, including linear regression, kernel methods, and deep neural networks, exhibit double descent, in which the test risk peaks near the interpolation threshold and then decreases in the overparameterized regime. However, this phenomenon has received less attention in the quantum setting. In this work, we investigate the double descent phenomenon in quantum kernel ridge regression (QKRR). By applying deterministic equivalents from random matrix theory (RMT), we derive an asymptotic expression for the test risk of QKRR in the high-dimensional limit. Our analysis rigorously characterizes the interpolation peak and reveals how explicit regularization can effectively suppress it. We corroborate our theoretical results with numerical simulations, demonstrating close agreement even for finite-size quantum systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates the double descent phenomenon in quantum kernel ridge regression (QKRR). It applies deterministic equivalents from random matrix theory to derive an asymptotic expression for the test risk of QKRR in the high-dimensional limit, rigorously characterizes the interpolation peak, demonstrates that explicit regularization suppresses the peak, and corroborates the theory with numerical simulations showing close agreement for finite-size systems.
Significance. If the central derivation holds, the work provides a valuable extension of double-descent analysis to quantum kernels, with a parameter-free asymptotic risk formula and explicit regularization guidance. The numerical agreement for finite quantum systems strengthens the practical relevance.
major comments (1)
- [§3, Eq. (12)–(15)] §3 (Asymptotic Analysis via Deterministic Equivalents), Eq. (12)–(15): the derivation of the asymptotic test-risk expression invokes deterministic equivalents for the resolvent of the N×N quantum kernel Gram matrix K. However, the required concentration and moment conditions are not separately verified for the structured entries K_ij = |⟨ϕ(x_i)|ϕ(x_j)⟩|^2 arising from a fixed quantum feature map ϕ. For common maps (angle embedding, ZZ-feature map), the entries are deterministically dependent through the shared unitary evolution rather than satisfying the independence or weak-correlation hypotheses of standard RMT results; this assumption is load-bearing for the claimed interpolation-peak characterization and regularization result.
minor comments (2)
- [Figure 2] Figure 2 caption: the legend does not distinguish the theoretical curve from the finite-size simulation markers; add explicit labels or line styles.
- [§2.2] Notation: the high-dimensional limit is stated as N, d → ∞ with N/d fixed, but the precise scaling of the quantum feature dimension (2^q) relative to N is not clarified in the statement of the limit.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: [§3, Eq. (12)–(15)] §3 (Asymptotic Analysis via Deterministic Equivalents), Eq. (12)–(15): the derivation of the asymptotic test-risk expression invokes deterministic equivalents for the resolvent of the N×N quantum kernel Gram matrix K. However, the required concentration and moment conditions are not separately verified for the structured entries K_ij = |⟨ϕ(x_i)|ϕ(x_j)⟩|^2 arising from a fixed quantum feature map ϕ. For common maps (angle embedding, ZZ-feature map), the entries are deterministically dependent through the shared unitary evolution rather than satisfying the independence or weak-correlation hypotheses of standard RMT results; this assumption is load-bearing for the claimed interpolation-peak characterization and regularization result.
Authors: We appreciate the referee's careful scrutiny of the assumptions in our asymptotic analysis. The deterministic equivalents we employ are based on results that require the kernel matrix entries to satisfy certain concentration properties, such as bounded fourth moments and weak correlations in the high-dimensional regime. For quantum feature maps like angle embedding and the ZZ-feature map, when the input data x_i are i.i.d. samples, the resulting kernel entries K_ij exhibit dependencies through the unitary, but these dependencies are controlled and do not violate the required conditions asymptotically, as the variance of each entry is O(1/N) or smaller in the overparameterized limit. Nevertheless, we acknowledge that an explicit verification was not provided in the original submission. In the revised manuscript, we will include a new subsection or appendix that derives the necessary moment bounds for the quantum kernels, confirming that the standard RMT hypotheses hold. This addition will not change the main theorems but will provide the missing rigor. revision: yes
Circularity Check
No circularity: asymptotic test-risk expression derived from external RMT deterministic equivalents
full rationale
The paper applies deterministic equivalents from random matrix theory to obtain an asymptotic expression for the test risk of QKRR in the high-dimensional limit. This step invokes standard external RMT results on kernel Gram matrices rather than defining the target quantity in terms of itself, fitting parameters to the data being predicted, or relying on load-bearing self-citations. The interpolation-peak characterization and regularization analysis follow directly from the RMT-derived formula without reducing to a tautology or renaming of inputs. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deterministic equivalents from random matrix theory apply to the quantum kernel matrix in the high-dimensional limit.
Reference graph
Works this paper leans on
-
[1]
Nakkiran, G
P. Nakkiran, G. Kaplun, Y. Bansal, T. Yang, B. Barak, and I. Sutskever, Deep double descent, Windows on Theory (2019), accessed: 2025-01-20
2019
-
[2]
Belkin, D
M. Belkin, D. Hsu, S. Ma, and S. Mandal, Reconciling modernmachine-learningpracticeandtheclassicalbias- variancetrade-off,ProceedingsoftheNationalAcademy of Sciences116, 15849 (2019)
2019
-
[3]
arXiv preprint arXiv:1903.07571 , year=
M. Belkin, D. Hsu, and J. Xu, Two models of double de- scent for weak features, SIAM Journal on Mathematics of Data Science2, 1167 (2020), 1903.07571 [cs]
-
[4]
Nakkiran, G
P. Nakkiran, G. Kaplun, Y. Bansal, T. Yang, B. Barak, and I. Sutskever, Deep double descent: Where bigger models and more data hurt, Journal of Statistical Me- chanics: Theory and Experiment2021, 124003 (2021)
2021
-
[5]
R. Schaeffer, M. Khona, Z. Robertson, A. Boopathy, K. Pistunova, J. W. Rocks, I. R. Fiete, and O. Koyejo, Double descent demystified: Identifying, interpreting & ablating the sources of a deep learning puzzle (2023), arXiv:2303.14151 [cs,stat]
-
[6]
J. W. Rocks and P. Mehta, Memorizing without over- fitting: Bias, variance, and interpolation in overpa- rameterized models, Physical review research4, 013201 (2022)
2022
-
[7]
Hastie, A
T. Hastie, A. Montanari, S. Rosset, and R. J. Tib- shirani, Surprises in high-dimensional ridgeless least squares interpolation, Annals of statistics50, 949 (2022)
2022
-
[8]
F.Bach,High-dimensionalanalysisofdoubledescentfor linear regression with random projections, SIAM Jour- nal on Mathematics of Data Science6, 26 (2024)
2024
-
[9]
Scaling and renormalization in high-dimensional regression
A. Atanasov, J. A. Zavatone-Veth, and C. Pehlevan, Scaling and renormalization in high-dimensional regres- sion (2024), arXiv:2405.00592 [stat]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Canatar, B
A. Canatar, B. Bordelon, and C. Pehlevan, Spectral bias and task-model alignment explain generalization in ker- nel regression and infinitely wide neural networks, Na- ture communications12, 2914 (2021)
2021
-
[11]
arXiv preprint arXiv:2403.08938 , year=
T. Misiakiewicz and B. Saeed, A non-asymptotic theory of Kernel Ridge Regression: deterministic equivalents, test error, and GCV estimator (2024), arXiv:2403.08938v1 [stat.ML]
-
[12]
Mei and A
S. Mei and A. Montanari, The generalization error of random features regression: Precise asymptotics and the double descent curve, Communications on Pure and Applied Mathematics75, 667 (2022)
2022
-
[13]
Gerace, B
F. Gerace, B. Loureiro, F. Krzakala, M. Mézard, and L. Zdeborová, Generalisation error in learning with ran- dom features and the hidden manifold model*, Journal of Statistical Mechanics: Theory and Experiment2021, 124013 (2021)
2021
-
[14]
Z. Liao, R. Couillet, and M. W. Mahoney, A random matrix analysis of random Fourier features: Beyond the Gaussian kernel, a precise phase transition, and the corresponding double descent*, J. Stat. Mech.2021, 124006 (2021)
2021
-
[15]
Schröder, H
D. Schröder, H. Cui, D. Dmitriev, and B. Loureiro, De- terministicequivalentanderroruniversalityofdeepran- dom features learning, Journal of Statistical Mechanics: Theory and Experiment2024, 104017 (2024)
2024
- [16]
-
[17]
D. Holzmüller, On the Universality of the Dou- ble Descent Peak in Ridgeless Regression (2023), arXiv:2010.01851 [stat]
-
[18]
P. Nakkiran, P. Venkat, S. Kakade, and T. Ma, Optimal Regularization Can Mitigate Double Descent (2021), arXiv:2003.01897 [cs]
-
[19]
ridgeless
T. Liang and A. Rakhlin, Just interpolate: Kernel “ridgeless” regression can generalize, The Annals of Statistics48, 1329 (2020)
2020
- [20]
-
[21]
P. L. Bartlett, P. M. Long, G. Lugosi, and A. Tsigler, Benign overfitting in linear regression, Proceedings of the National Academy of Sciences117, 30063 (2020)
2020
-
[22]
N. Mallinar, J. B. Simon, A. Abedsoltan, P. Pan- dit, M. Belkin, and P. Nakkiran, Benign, tempered, or catastrophic: A taxonomy of overfitting (2024), arXiv:2207.06569 [cs.LG]
-
[23]
C. Louart and R. Couillet, Spectral properties of sample covariance matrices arising from random matrices with independent non identically distributed columns (2023), arXiv:2109.02644 [math.PR]
work page internal anchor Pith review arXiv 2023
-
[24]
M. C. Caro, E. Gil-Fuster, J. J. Meyer, J. Eisert, and R. Sweke, Encoding-dependent generalization bounds for parametrized quantum circuits, Quantum5, 582 (2021)
2021
-
[25]
M. C. Caro, H.-Y. Huang, M. Cerezo, K. Sharma, A.Sornborger, L.Cincio,andP.J.Coles,Generalization in quantum machine learning from few training data, Nat Commun13, 4919 (2022)
2022
-
[26]
M. C. Caro, H.-Y. Huang, N. Ezzell, J. Gibbs, A. T. Sornborger, L. Cincio, P. J. Coles, and Z. Holmes, Out- of-distribution generalization for learning quantum dy- namics, Nature Communications14, 3751 (2023)
2023
-
[27]
Banchi, J
L. Banchi, J. L. Pereira, S. T. Jose, and O. Simeone, Statistical complexity of quantum learning, Advanced Quantum Technologies , 2300311 (2024)
2024
-
[28]
K. Bu, D. E. Koh, L. Li, Q. Luo, and Y. Zhang, Ef- fects of quantum resources and noise on the statistical complexity of quantum circuits, Quantum Science and Technology8, 025013 (2023)
2023
-
[29]
Y. Du, Z. Tu, X. Yuan, and D. Tao, Efficient measure for the expressivity of variational quantum algorithms, Physical Review Letters128, 080506 (2022)
2022
-
[30]
Y. Du, Y. Yang, D. Tao, and M.-H. Hsieh, Problem- dependent power of quantum neural networks on multi- class classification, Physical Review Letters131, 140601 (2023)
2023
-
[31]
Khanal, P
B. Khanal, P. Rivas, A. Sanjel, K. Sooksatra, E. Quevedo, and A. Rodriguez, Generalization error bound for quantum machine learning in nisq era—a sur- vey, Quantum Machine Intelligence6(2024)
2024
-
[32]
A. Strashko and E. M. Stoudenmire, Generalization and Overfitting in Matrix Product State Machine Learning Architectures (2022), arXiv:2208.04372 [quant-ph]
-
[33]
arXiv preprint arXiv:2109.11676 , year =
M. Larocca, N. Ju, D. García-Martín, P. J. Coles, and M. Cerezo, Theory of overparametrization in quan- tum neural networks (2021), arXiv:2109.11676 [quant- ph, stat]
-
[34]
Peters and M
E. Peters and M. Schuld, Generalization despite overfit- ting in quantum machine learning models, Quantum7, 1210 (2023). 15
2023
-
[35]
Haug and M
T. Haug and M. S. Kim, Generalization of Quantum Machine Learning Models Using Quantum Fisher Infor- mation Metric, Phys. Rev. Lett.133, 050603 (2024)
2024
-
[36]
M. Kempkes, A. Ijaz, E. Gil-Fuster, C. Bravo-Prieto, J. Spiegelberg, E. van Nieuwenburg, and V. Dunjko, Double descent in quantum machine learning (2025), arXiv:2501.10077 [quant-ph]
- [37]
-
[38]
Gil-Fuster, J
E. Gil-Fuster, J. Eisert, and C. Bravo-Prieto, Under- standing quantum machine learning also requires re- thinking generalization, Nat Commun15, 2277 (2024)
2024
-
[39]
Zhang, S
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, Understanding deep learning (still) requires rethinking generalization, Communications of the ACM 64, 107 (2021)
2021
-
[40]
A. Canatar, E. Peters, C. Pehlevan, S. M. Wild, and R. Shaydulin, Bandwidth enables generalization in quantum kernel models (2023), arXiv:2206.06686 [quant-ph]
-
[41]
Couillet and Z
R. Couillet and Z. Liao,Random matrix methods for machine learning(Cambridge University Press, 2022)
2022
-
[42]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, Generative adversarial nets, Advances in neural infor- mation processing systems27(2014)
2014
-
[43]
M. E. A. Seddik, C. Louart, M. Tamaazousti, and R. Couillet, Random matrix theory proves that deep learning representations of GAN-data behave as Gaus- sian mixtures, inProceedings of the 37th International Conference on Machine Learning, Proceedings of Ma- chine Learning Research, Vol. 119, edited by H. D. III and A. Singh (PMLR, 2020) pp. 8573–8582
2020
-
[44]
Defilippis, B
L. Defilippis, B. Loureiro, and T. Misiakiewicz, Dimension-free deterministic equivalents and scaling laws for random feature regression, Advances in Neu- ral Information Processing Systems37, 104630 (2024)
2024
-
[45]
Shawe-Taylor and N
J. Shawe-Taylor and N. Cristianini,Kernel methods for pattern analysis(Cambridge university press, 2004)
2004
-
[46]
Schölkopf, R
B. Schölkopf, R. Herbrich, and A. J. Smola, A gener- alized representer theorem, inInternational conference on computational learning theory(Springer Berlin Hei- delberg, 2001) pp. 416–426
2001
-
[47]
We loosely call it the population covariance matrix
Precisely,Σis the uncentered second-moment matrix. We loosely call it the population covariance matrix
-
[48]
Supervised quantum machine learning mod- els are kernel methods
M. Schuld, Supervised quantum machine learning mod- els are kernel methods (2021), arXiv:2101.11020 [quant- ph, stat]
-
[49]
J. A. Zavatone-Veth, Lecture notes on the inductive bi- ases of high-dimensional ridge regression (2024)
2024
-
[50]
Dobriban and S
E. Dobriban and S. Wager, High-dimensional asymp- totics of prediction: Ridge regression and classification, The Annals of Statistics46, 247 (2018)
2018
- [51]
- [52]
-
[53]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V. Ajith, M. S. Alam, G. Alonso-Linaje, B. AkashNarayanan, A. Asadi, J. M. Arrazola, U. Azad, S. Banning, C. Blank, T. R. Bromley, B. A. Cordier, J. Ceroni, A. Delgado, O. D. Matteo, A. Dusko, T. Garg, D. Guala, A. Hayes, R. Hill, A. Ijaz, T. Isacs- son, D. Ittah, S. Jahangiri, P. Jain, E. Jiang, A. ...
work page internal anchor Pith review arXiv 2022
-
[54]
In our simulations, we set d= 2n= 2 log 4 pandL=n= log 4 p, yielding C1 = √ 2πlog 4 p=O(logN tr)
The Lipschitz constantC 1 in Assumption 1 is √ dLπ, as shown in Appendix D. In our simulations, we set d= 2n= 2 log 4 pandL=n= log 4 p, yielding C1 = √ 2πlog 4 p=O(logN tr). While this choice results in a Lipschitz constant that grows logarithmically with Ntr, the deterministic equivalent in Proposition 1 re- mainsvalid.Thisisbecausetheconcentrationinequa...
-
[55]
This is be- cause such a TPA can generate feature vectors that have {sin(ui)}d i=1 as a subset of their entries
We can construct a quantum model which realizes this process by using the 1-layer TPA withd=n. This is be- cause such a TPA can generate feature vectors that have {sin(ui)}d i=1 as a subset of their entries. See Table 4
-
[56]
Exponential concentration and untrainability in quantum kernel methods
S. Thanasilp, S. Wang, M. Cerezo, and Z. Holmes, Exponential concentration and untrainability in quan- tum kernel methods (2022), arXiv:2208.11060 [quant- ph, stat]
-
[57]
Shaydulin and S
R. Shaydulin and S. M. Wild, Importance of kernel bandwidth in quantum machine learning, Physical Re- view A106, 042407 (2022)
2022
-
[58]
Mitarai, M
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Quantum circuit learning, Phys. Rev. A98, 032309 (2018)
2018
-
[59]
Classification with Quantum Neural Networks on Near Term Processors
E. Farhi and H. Neven, Classification with quan- tum neural networks on near term processors (2018), arXiv:1802.06002 [quant-ph]
work page Pith review arXiv 2018
-
[60]
Benedetti, E
M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Pa- rameterized quantum circuits as machine learning mod- els, Quantum Sci. Technol.4, 043001 (2019)
2019
-
[61]
Schuld, A
M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, Circuit-centric quantum classifiers, Phys. Rev. A101, 032308 (2020)
2020
-
[62]
C.-C. Chen, M. Watabe, K. Shiba, M. Sogabe, K. Sakamoto, and T. Sogabe, On the Expressibility and Overfitting of Quantum Circuit Learning, ACM Trans- actions on Quantum Computing2, 1 (2021)
2021
-
[63]
F. F. Yilmaz and R. Heckel, Regularization-wise dou- ble descent: Why it occurs and how to eliminate it, in IEEE International Symposium on Information Theory (ISIT)(2022) pp. 426–431
2022
-
[64]
D. Richards, J. Mourtada, and L. Rosasco, Asymptotics of Ridge (less) Regression under General Source Condi- tion (2021), arXiv:2006.06386 [math]
-
[65]
Bai and J
Z. Bai and J. W. Silverstein,Spectral Analysis of Large Dimensional Random Matrices, Springer Series in Statistics (Springer New York, 2010). 16 A. Table of Notations TABLE 3: Summary of key notations used in this work. Symbol Description [m] The set{1,2, . . . , m}for a positive integerm. ∥·∥2 L2 norm for vectors. ∥·∥1 Trace norm (Schatten1norm) for matr...
2010
-
[66]
In Appendix B, we show that our feature-vector generating process (Assumption 1) is a special case of this example, and thus satisfies the concentration property required by Assumption 0.4. 22 H. From Theorem 0.9 in Ref. [23] to Proposition 1 In this section, we provide the detailed connection between Theorem 0.9 in Ref. [23] and the deterministic equival...
-
[67]
However, in our context, the functions of interest (resolvents) are analytic and bounded inC\Sϵ −0, which allows us to use Vitali’s theorem (cf
Justification of the Derivative Trick Almost sure convergence of a sequence of random functions{fp}to a deterministic functionfdoes not auto- matically imply the convergence of their derivatives{f′ p}tof ′. However, in our context, the functions of interest (resolvents) are analytic and bounded inC\Sϵ −0, which allows us to use Vitali’s theorem (cf. Theor...
-
[68]
Derivation of the Bias Term We calculate the deterministic equivalent of the bias term: Bλ,ˆΣ =λ 2θT ∗ (ˆΣ +λI p)−1Σ(ˆΣ +λI p)−1θ∗ .(J1) Weintroducea scalarperturbationparameterJwithinanopenneighborhood|J|< 1 2∥Σ∥∞ , and definetheperturbed feature vectors as xJ := (I+JΣ) −1/2x.(J2) Because the minimum eigenvalue ofI+JΣis strictly greater than1/2, the oper...
-
[69]
Since the composition of Lipschitz functions remains Lipschitz,xJ also satisfies Assumption 1
Consequently, the linear mapx7→(I+JΣ) −1/2xis √ 2-Lipschitz. Since the composition of Lipschitz functions remains Lipschitz,xJ also satisfies Assumption 1. Then, by definingXJ := [x1,J ,· · ·,x Ntr,J]⊤, the perturbed covariance matrices can be written as ˆΣJ := 1 Ntr XJ X ⊤ J = (Ip +JΣ) −1/2 ˆΣ(Ip +JΣ) −1/2 ,(J3) ΣJ :=E[x J x⊤ J ] = (Ip +JΣ) −1/2Σ(Ip +JΣ)...
-
[70]
With this function, the variance term can be expressed asV λ,ˆΣ = ∂Tp(λ) ∂λ
Derivation of the Variance Term The variance term is given by Vλ,ˆΣ = σ2 Ntr Tr h ΣˆΣ(ˆΣ +λI p)−2 i .(J24) Using the identityˆΣ(ˆΣ +λI p)−2 = (ˆΣ +λI p)−1 −λ( ˆΣ +λI p)−2 = ∂ ∂λ [λ(ˆΣ +λI p)−1], we can rewrite the trace as Tr h ΣˆΣ(ˆΣ +λI p)−2 i = ∂ ∂λ Tr h Σλ(ˆΣ +λI p)−1 i .(J25) Now, we define the following function: Tp(λ) := σ2 Ntr Tr h Σλ(ˆΣ +λI p)−1 ...
-
[71]
We establish this by utilizing the Implicit Function Theorem
Analyticity of the Effective Regularization Parametersκλ andκ λ,J To rigorously apply Lemma J.1 to the deterministic equivalents, we must ensure that the effective regularization parametersκ λ andκ λ,J are analytic functions of their respective parametersλandJ. We establish this by utilizing the Implicit Function Theorem. a. Analyticity ofκ λ with respect...
-
[72]
Therefore, we can estimate the eigenvalues of the population covarianceΣ directly from the kernel matrix
Estimation of the Population CovarianceΣ The nonzero eigenvalues of the sample covariance matrix 1 Nest X TXare identical to the nonzero eigenvalues of the normalized kernel matrix 1 Nest XX T. Therefore, we can estimate the eigenvalues of the population covarianceΣ directly from the kernel matrix. LetKest ∈R Nest×Nest be the kernel matrix computed on the...
-
[73]
We employ the Nyström method, which discretizes the integral eigenvalue equation R U k(u,u ′)ψk(u′) dµ(u′) =ξ kψk(u)using the empirical measure 1 Nest PNest j=1 δuj
Approximation of Eigenfunctions Evaluated at Data Samples To estimate the projected target vectorβ∗, we require the values of the eigenfunctions evaluated at the data samples, i.e.,ψ k(uj)forj∈[N est]andk∈[p]. We employ the Nyström method, which discretizes the integral eigenvalue equation R U k(u,u ′)ψk(u′) dµ(u′) =ξ kψk(u)using the empirical measure 1 N...
-
[74]
, yNest)T
Estimation of the Projected Target Vectorβ∗ The entries of the projected target vectorβ∗,k are defined as the projections of the target functionf∗ onto the orthonormal eigenfunctions{ψ k}p k=1: β∗,k = Z U f∗(u)ψk(u) dµ(u).(K6) 31 Sincef ∗ andψ k are unknown, we employ the Nyström method again onDest, substituting the observed noisy labels yj forf ∗(uj)and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.