Recognition: unknown
AURORA: A High Performance DAQ Framework for Next-Generation Rare-Event Search Experiments
Pith reviewed 2026-05-10 05:53 UTC · model grok-4.3
The pith
The AURORA framework achieves over 3 GB/s throughput on aggregation nodes to meet the 1.6 GB/s data demands of experiments with more than 3,000 high-speed channels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AURORA is a high-performance, distributed data acquisition framework designed for scalability, low latency, and efficient resource utilization. Built on a modular architecture and leveraging modern I/O and networking technologies including multi-level buffering and deferred and asynchronous processing, AURORA achieves a projected throughput of over 3 GB/s on the aggregation node in benchmark tests while supporting the 1.6 GB/s sustained bandwidth required by PandaX-xT with over 3,000 channels at 500 MSa/s. While developed to support PandaX-xT, the framework is experiment-agnostic and readily adaptable to other large-scale particle and nuclear physics experiments.
What carries the argument
Modular architecture with multi-level buffering and deferred asynchronous processing that aggregates and manages high-volume data streams from many channels.
If this is right
- PandaX-xT can run at its full required data rate of 1.6 GB/s without loss from the more than 3,000 channels.
- The same framework can be adapted for other experiments that need similar high-channel-count, high-sampling-rate data handling.
- Future detectors with even larger numbers of channels or higher sampling rates become feasible without redesigning the core acquisition layer.
- Deferred and asynchronous processing reduces the hardware resources needed to maintain low-latency operation.
Where Pith is reading between the lines
- If the buffering approach scales, experiments could increase detector granularity without being limited by data throughput.
- Similar modular buffering patterns might apply to high-speed data collection in adjacent fields such as neutrino telescopes or medical imaging arrays.
- Integration testing across varied network topologies would clarify whether the reported headroom remains available in distributed real-time settings.
Load-bearing premise
The benchmark tests and modular architecture with multi-level buffering and deferred processing will translate directly to sustained performance under real experimental conditions without hidden bottlenecks or integration issues.
What would settle it
If actual deployment on PandaX-xT shows sustained bandwidth dropping below 1.6 GB/s or aggregation-node throughput falling below 3 GB/s under full channel load, the performance claims would not hold.
Figures




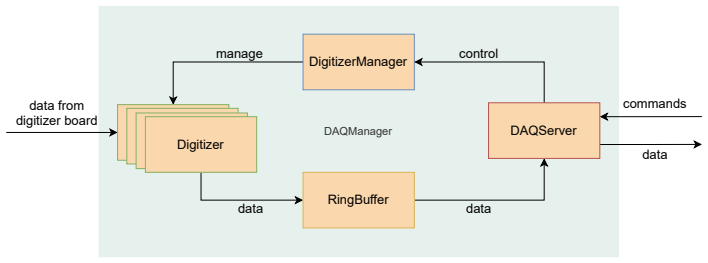
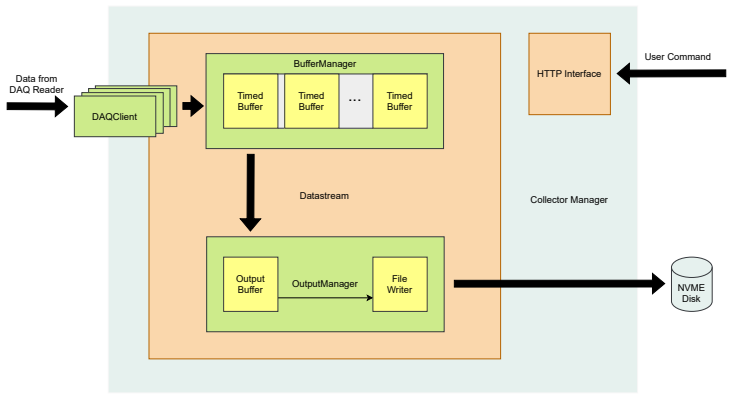
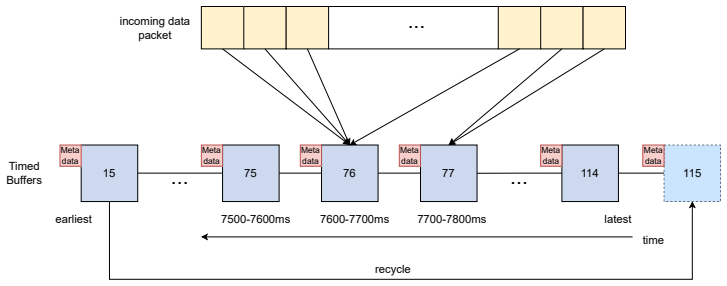
read the original abstract
The upcoming PandaX-xT experiment will deploy over 3,000 readout channels operating at a 500 MSa/s sampling rate, generating a sustained data bandwidth up to 1.6 GB/s. To meet this demanding requirement, we present AURORA, a high-performance, distributed data acquisition (DAQ) framework designed for scalability, low latency, and efficient resource utilization. Built on a modular architecture and leveraging modern I/O and networking technologies, including multi-level buffering, deferred and asynchronous processing, AURORA achieves a projected throughput of over 3 GB/s on the aggregation node in benchmark tests. While developed to support PandaX-xT, the framework is experiment-agnostic and readily adaptable to other large-scale particle and nuclear physics experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AURORA, a modular, distributed DAQ framework for next-generation rare-event searches. It targets the PandaX-xT experiment's requirements of >3000 readout channels at 500 MSa/s, producing up to 1.6 GB/s sustained bandwidth. The framework employs multi-level buffering, deferred/asynchronous processing, and modern I/O/networking technologies. Benchmark tests on the aggregation node are reported to project a throughput exceeding 3 GB/s, with the system described as scalable and experiment-agnostic for adaptation to other large-scale particle and nuclear physics experiments.
Significance. If the benchmark projections translate to sustained performance under full experimental load, AURORA would offer a practical, high-throughput DAQ solution that addresses a key bottleneck for upcoming ton-scale and multi-ton rare-event detectors. The modular design and emphasis on asynchronous processing could reduce development overhead for future experiments facing similar data-rate challenges.
major comments (3)
- [§4 (Performance Evaluation)] §4 (Performance Evaluation): The central claim that AURORA supports the 1.6 GB/s PandaX-xT requirement rests on benchmark results projecting >3 GB/s throughput, yet these tests provide no error bars, detailed test conditions, data exclusion criteria, or explicit comparison baselines, leaving the quantitative support for the projection thin.
- [§3 (Architecture) and §4] §3 (Architecture) and §4: The multi-level buffering and deferred/asynchronous processing are described as enabling scalability, but no quantitative scaling measurements or simulations are presented that inject realistic per-channel data volumes, packetization overhead, or timing jitter from >3000 front-end channels at 500 MSa/s; this leaves unverified whether contention is eliminated at full fan-in.
- [§4.1 (Benchmark Setup)] §4.1 (Benchmark Setup): The aggregation-node benchmarks do not report tests under the full 3000-channel load with realistic data patterns expected from the front-end electronics, so the assumption that the architecture sustains the required bandwidth without hidden bottlenecks remains untested.
minor comments (2)
- [Abstract and §1] The abstract and §1 state the 1.6 GB/s figure without an explicit derivation or reference to the per-channel bit depth and compression assumptions used to arrive at it.
- [Performance figures] Figure captions in the performance section could more clearly indicate whether the reported throughputs include or exclude overhead from packetization and network protocols.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript on the AURORA DAQ framework. We address each major comment point by point below, providing clarifications where possible and indicating planned revisions to improve the quantitative support and transparency of the results.
read point-by-point responses
-
Referee: §4 (Performance Evaluation): The central claim that AURORA supports the 1.6 GB/s PandaX-xT requirement rests on benchmark results projecting >3 GB/s throughput, yet these tests provide no error bars, detailed test conditions, data exclusion criteria, or explicit comparison baselines, leaving the quantitative support for the projection thin.
Authors: We acknowledge that the benchmark results presented in Section 4 would benefit from greater statistical rigor and context. In the revised manuscript, we will add error bars calculated from multiple independent runs of the benchmarks, expand the description of test conditions (including specific hardware, network configuration, and data generation methodology), clarify any data exclusion criteria, and include explicit baseline comparisons to standard I/O benchmarks or prior DAQ implementations. These changes will provide stronger quantitative backing for the >3 GB/s projection. revision: yes
-
Referee: §3 (Architecture) and §4: The multi-level buffering and deferred/asynchronous processing are described as enabling scalability, but no quantitative scaling measurements or simulations are presented that inject realistic per-channel data volumes, packetization overhead, or timing jitter from >3000 front-end channels at 500 MSa/s; this leaves unverified whether contention is eliminated at full fan-in.
Authors: The current manuscript focuses on the core architectural mechanisms and node-level benchmarks to demonstrate scalability potential. We agree that explicit scaling measurements or simulations incorporating per-channel volumes, packetization, and jitter would strengthen the claims. In the revision, we will add modeling results or additional analysis in Sections 3 and 4 that simulate the full fan-in scenario based on the expected 500 MSa/s rates and data patterns, showing how the buffering and asynchronous design mitigates contention. This will be supported by calculations derived from the existing benchmark data. revision: partial
-
Referee: §4.1 (Benchmark Setup): The aggregation-node benchmarks do not report tests under the full 3000-channel load with realistic data patterns expected from the front-end electronics, so the assumption that the architecture sustains the required bandwidth without hidden bottlenecks remains untested.
Authors: The aggregation-node benchmarks were conducted at sustained rates exceeding the 1.6 GB/s target using synthetic workloads calibrated to match the expected aggregate bandwidth from 3000+ channels. We recognize that explicit full-scale tests with 3000-channel hardware and precise front-end data patterns are not yet reported. In the revised Section 4.1, we will provide more detailed justification of the data patterns used (including how they emulate per-channel 500 MSa/s streams), discuss potential bottlenecks, and note that complete 3000-channel integration tests will be performed as PandaX-xT hardware becomes available. The modular design and current results support the projection in the interim. revision: partial
Circularity Check
No circularity: throughput claims rest on external benchmark measurements, not self-referential derivation
full rationale
The paper describes a modular DAQ architecture with multi-level buffering and reports benchmark-derived throughput figures (>3 GB/s on aggregation node) that are compared against the PandaX-xT requirement (1.6 GB/s). No equations, fitted parameters, or derivation steps are present that reduce the performance projection to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central claims are engineering assertions backed by separate test results rather than circular redefinitions or renamings of known patterns. This is a standard non-circular case of an implementation paper whose quantitative results are tied to external measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark tests on the aggregation node accurately predict sustained performance under full experimental load.
Reference graph
Works this paper leans on
-
[1]
Cao, et al., PandaX: A Liquid Xenon Dark Matter Experiment at CJPL, Sci
X. Cao, et al., PandaX: A Liquid Xenon Dark Matter Experiment at CJPL, Sci. China Phys. Mech. Astron. 57 (2014) 1476–1494.arXiv:1405.2882,doi:10.1007/ s11433-014-5521-2
-
[2]
Refining radiative decay studies in singly heavy baryons.Phys
A. Tan, et al., Dark Matter Search Results from the Commissioning Run of PandaX-II, Phys. Rev. D 93 (12) (2016) 122009.arXiv:1602.06563,doi:10.1103/PhysRevD. 93.122009
-
[3]
Zhang, et al., Dark matter direct search sensitivity of the PandaX-4T experiment, Sci
H. Zhang, et al., Dark matter direct search sensitivity of the PandaX-4T experiment, Sci. China Phys. Mech. Astron. 62 (3) (2019) 31011.arXiv:1806.02229,doi:10.1007/ s11433-018-9259-0
-
[4]
E. Aprile, T. Doke, Liquid Xenon Detectors for Particle Physics and Astrophysics, Rev. Mod. Phys. 82 (2010) 2053–2097.arXiv:0910.4956,doi:10.1103/RevModPhys.82. 2053
-
[5]
Dark Matter Search Re- sults from the PandaX-4T Commissioning Run,
Y . Meng, et al., Dark Matter Search Results from the PandaX-4T Commissioning Run, Phys. Rev. Lett. 127 (26) (2021) 261802.arXiv:2107.13438,doi:10.1103/ PhysRevLett.127.261802
-
[6]
L. Si, et al., Determination of Double Beta Decay Half-Life of 136Xe with the PandaX- 4T Natural Xenon Detector, Research 2022 (2022) 9798721.arXiv:2205.12809,doi: 10.34133/2022/9798721
-
[7]
W. Ma, et al., Search for Solar B8 Neutrinos in the PandaX-4T Experiment Using Neutrino- Nucleus Coherent Scattering, Phys. Rev. Lett. 130 (2) (2023) 021802.arXiv:2207. 04883,doi:10.1103/PhysRevLett.130.021802. 14
-
[8]
X. Ning, et al., Limits on the luminance of dark matter from xenon recoil data, Nature 618 (7963) (2023) 47–50.doi:10.1038/s41586-023-05982-0
-
[9]
Z. Bo, et al., First Indication of Solar B8 Neutrinos through Coherent Elastic Neutrino- Nucleus Scattering in PandaX-4T, Phys. Rev. Lett. 133 (19) (2024) 191001.arXiv:2407. 10892,doi:10.1103/PhysRevLett.133.191001
-
[10]
Boet al.(PandaX), Dark Matter Search Results from 1.54 Tonne·Year Exposure of PandaX-4T, Phys
Z. Bo, et al., Dark Matter Search Results from 1.54 Tonne·Year Exposure of PandaX- 4T, Phys. Rev. Lett. 134 (1) (2025) 011805.arXiv:2408.00664,doi:10.1103/ PhysRevLett.134.011805
-
[11]
Abdukerim, et al., PandaX-xT—A deep underground multi-ten-tonne liquid xenon ob- servatory, Sci
A. Abdukerim, et al., PandaX-xT—A deep underground multi-ten-tonne liquid xenon ob- servatory, Sci. China Phys. Mech. Astron. 68 (2) (2025) 221011.arXiv:2402.03596, doi:10.1007/s11433-024-2539-y
-
[12]
J. Yang, et al., Readout electronics and data acquisition system of PandaX-4T experiment, JINST 17 (02) (2022) T02004.arXiv:2108.03433,doi:10.1088/1748-0221/17/02/ T02004
-
[13]
C. He, et al., A 500 MS/s waveform digitizer for PandaX dark matter experiments, JINST 16 (12) (2021) T12015.arXiv:2108.11804,doi:10.1088/1748-0221/16/12/ T12015
-
[14]
T. Uchida, Hardware-based tcp processor for gigabit ethernet, IEEE Transactions on Nu- clear Science 55 (3) (2008) 1631–1637.doi:10.1109/TNS.2008.920264
-
[15]
URLhttps://docs.influxdata.com
InfluxData, InfluxDB: Open Source Time Series Database. URLhttps://docs.influxdata.com
-
[16]
URLhttps://www.postgresql.org
The PostgreSQL Global Development Group, Postgresql documentation. URLhttps://www.postgresql.org
-
[17]
Kreps, Kafka : a distributed messaging system for log processing, 2011
J. Kreps, Kafka : a distributed messaging system for log processing, 2011. URLhttps://api.semanticscholar.org/CorpusID:18534081
2011
-
[18]
M. J. Sax, Apache Kafka, Springer International Publishing, Cham, 2018, pp. 1–8.doi: 10.1007/978-3-319-63962-8_196-1. URLhttps://doi.org/10.1007/978-3-319-63962-8_196-1 [19]https://kafka.apache.org/
-
[19]
C. M. Kohlhoff, Boost.Asio Documentation, Boost.org. URLhttps://www.boost.org/doc/libs/latest/doc/html/boost_asio.html
-
[20]
R. T. Fielding, Architectural styles and the design of network-based software architectures, Ph.D. thesis, University of California, Irvine (2000). URLhttps://www.ics.uci.edu
2000
-
[21]
Y . Hirose. [link]. URLhttps://github.com/yhirose/cpp-httplib
-
[22]
URLhttps://github.com/google/benchmark 15
[link]. URLhttps://github.com/google/benchmark 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.