Recognition: unknown
Interpolating Discrete Diffusion Models with Controllable Resampling
Pith reviewed 2026-05-10 06:39 UTC · model grok-4.3
The pith
IDDM interpolates discrete diffusion transitions to reduce dependence on error-prone intermediate states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
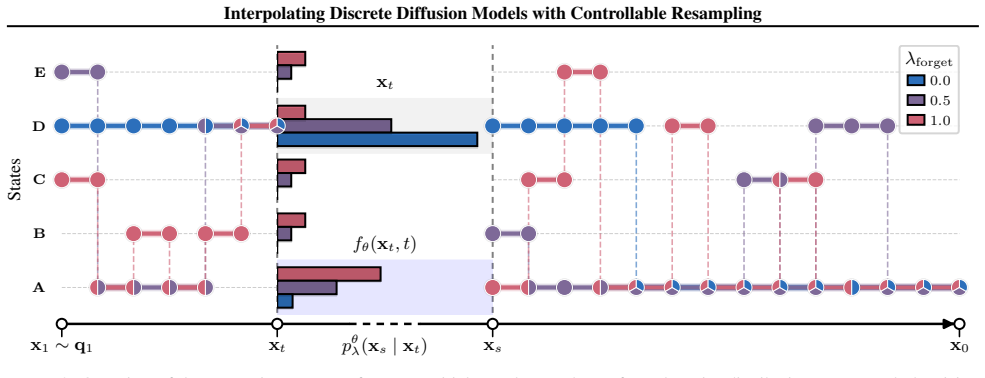
IDDM specifies a generative process whose transitions interpolate between staying at the current state, resampling from a prior, and flipping toward the target state, while enforcing marginal consistency and fully decoupling training from inference.
What carries the argument
Controllable resampling mechanism that partially resets probability mass to the marginal distribution to mitigate error accumulation from intermediate states.
If this is right
- Competitive performance on molecular graph generation benchmarks.
- Effective token correction during text generation without early irreversible mistakes.
- Training and inference can be designed independently.
- The model blends the strengths of masked and uniform diffusion in one process.
Where Pith is reading between the lines
- The interpolation idea could extend to other discrete token domains such as image patches or audio codes.
- Resampling strength might be made input-dependent or scheduled adaptively during sampling.
- The same mechanism offers a general template for mixing multiple diffusion behaviors while keeping the marginals fixed.
Load-bearing premise
The resampling rate can be tuned to cut error buildup without creating fresh inconsistencies or lowering final sample quality.
What would settle it
An ablation where increasing the resampling strength produces either visible marginal drift or lower-quality outputs than uniform diffusion baselines on the same tasks.
Figures








read the original abstract
Discrete diffusion models form a powerful class of generative models across diverse domains, including text and graphs. However, existing approaches face fundamental limitations. Masked diffusion models suffer from irreversible errors due to early unmasking, while uniform diffusion models, despite enabling self-correction, often yield low-quality samples due to their strong reliance on intermediate latent states. We introduce IDDM, an Interpolating Discrete Diffusion Model, that improves diffusion by reducing dependence on intermediate latent states. Central to IDDM is a controllable resampling mechanism that partially resets probability mass to the marginal distribution, mitigating error accumulation and enabling more effective token corrections. IDDM specifies a generative process whose transitions interpolate between staying at the current state, resampling from a prior, and flipping toward the target state, while enforcing marginal consistency and fully decoupling training from inference. We benchmark our model against state-of-the-art discrete diffusion models across molecular graph generation as well as text generation tasks, demonstrating competitive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Interpolating Discrete Diffusion Models (IDDM) for discrete data such as text and graphs. It defines a generative process whose transitions interpolate between staying at the current state, resampling from a prior, and flipping toward the target state. The central claims are that this interpolation enforces marginal consistency at every timestep for a controllable resampling parameter, fully decouples training from inference, mitigates error accumulation from intermediate latent states, and yields competitive empirical performance on molecular graph generation and text generation tasks relative to masked and uniform discrete diffusion baselines.
Significance. If the marginal consistency holds for arbitrary resampling rates without additional constraints and the resampling mechanism demonstrably reduces dependence on erroneous intermediate states, the work would provide a useful advance in discrete diffusion by enabling more flexible sampling schedules and cleaner separation of training and inference. The explicit interpolation construction, if rigorously derived, could serve as a template for other discrete generative models.
major comments (2)
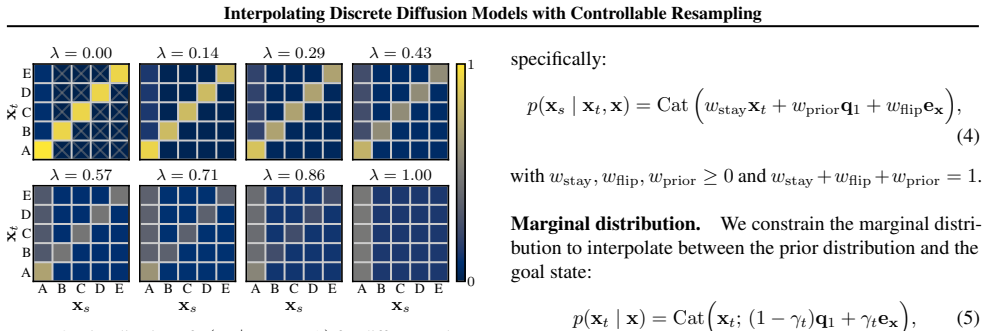
- [§3.2] §3.2 (Transition Kernel): The strongest claim asserts that the stay/resample/flip interpolation enforces marginal consistency for any value of the controllable resampling weight while decoupling training from inference. However, a mixture kernel with a free resampling rate generally fails to preserve the required marginal equality unless the stay and flip probabilities are solved from a linear system that depends on the weight and current distribution. The manuscript must supply the explicit derivation or invariance proof; without it the decoupling claim is at risk and training may implicitly depend on the inference schedule.
- [§5] §5 (Benchmarks): The abstract and experimental section assert competitive performance on graph and text tasks, yet the reported metrics lack error bars, statistical significance tests, or ablations isolating the effect of the resampling control parameter. This makes it difficult to verify that the mechanism mitigates error accumulation in practice rather than trading one source of error for another.
minor comments (2)
- [Abstract] Abstract: The phrase 'demonstrating competitive performance' would be strengthened by a single quantitative highlight (e.g., 'outperforms uniform diffusion by X% on metric Y').
- [Notation] Notation: The resampling control parameter is introduced with multiple symbols across sections; adopt a single consistent symbol and define it once in §2.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We address each of the major comments below, providing clarifications and indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Transition Kernel): The strongest claim asserts that the stay/resample/flip interpolation enforces marginal consistency for any value of the controllable resampling weight while decoupling training from inference. However, a mixture kernel with a free resampling rate generally fails to preserve the required marginal equality unless the stay and flip probabilities are solved from a linear system that depends on the weight and current distribution. The manuscript must supply the explicit derivation or invariance proof; without it the decoupling claim is at risk and training may implicitly depend on the inference schedule.
Authors: We thank the referee for highlighting this important point. In the derivation of the transition kernel in §3.2, the stay and flip probabilities are indeed solved from the linear system that enforces the marginal consistency condition for arbitrary resampling weights. This solution depends on the weight and the current distribution, as noted. The manuscript presents the resulting kernel but we agree that an expanded step-by-step derivation of how the probabilities are obtained would improve clarity. We will include this explicit derivation, along with a proof of the invariance, in the revised version of the paper. This will confirm that training remains decoupled from the inference schedule. revision: yes
-
Referee: [§5] §5 (Benchmarks): The abstract and experimental section assert competitive performance on graph and text tasks, yet the reported metrics lack error bars, statistical significance tests, or ablations isolating the effect of the resampling control parameter. This makes it difficult to verify that the mechanism mitigates error accumulation in practice rather than trading one source of error for another.
Authors: We agree that the experimental section would benefit from additional statistical rigor. In the revised manuscript, we will report error bars based on multiple independent runs, include statistical significance tests comparing IDDM to the baselines, and add ablations that vary the resampling parameter to isolate its contribution to reducing dependence on intermediate states. These additions will better demonstrate the practical benefits of the controllable resampling mechanism. revision: yes
Circularity Check
No significant circularity; derivation is self-contained by explicit model definition
full rationale
The paper defines IDDM via a new controllable resampling mechanism that interpolates stay/resample/flip transitions while claiming to enforce marginal consistency directly in the generative process. No load-bearing step reduces by construction to a fitted parameter, renamed input, or self-citation chain; the decoupling of training from inference follows from the stated interpolation without requiring the target result as an assumption. This is the normal case of an independent model specification.
Axiom & Free-Parameter Ledger
free parameters (1)
- resampling control parameter
axioms (1)
- domain assumption The generative transitions must enforce marginal consistency at every step.
invented entities (1)
-
controllable resampling mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Boget, Y . Simple and critical iterative denoising: A re- casting of discrete diffusion in graph generation.arXiv preprint arXiv:2503.21592,
-
[2]
Campbell, A., Yim, J., Barzilay, R., Rainforth, T., and Jaakkola, T. Generative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design.arXiv preprint arXiv:2402.04997,
-
[3]
One billion word benchmark for measuring progress in statistical language modeling
Chelba, C., Mikolov, T., Schuster, M., Ge, Q., Brants, T., Koehn, P., and Robinson, T. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005,
-
[4]
Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761, 2020
Kong, Z., Ping, W., Huang, J., Zhao, K., and Catanzaro, B. Diffwave: A versatile diffusion model for audio synthesis. arXiv preprint arXiv:2009.09761,
-
[5]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Lou, A., Meng, C., and Ermon, S. Discrete diffusion model- ing by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834,
work page internal anchor Pith review arXiv
-
[6]
Nisonoff, H., Xiong, J., Allenspach, S., and Listgarten, J. Unlocking guidance for discrete state-space diffusion and flow models.arXiv preprint arXiv:2406.01572,
-
[7]
Defog: Discrete flow matching for graph generation.arXiv preprint arXiv:2410.04263, 2024
Qin, Y ., Madeira, M., Thanou, D., and Frossard, P. De- fog: Discrete flow matching for graph generation.arXiv preprint arXiv:2410.04263,
-
[8]
The diffusion duality.arXiv preprint arXiv:2506.10892, 2025
Sahoo, S. S., Deschenaux, J., Gokaslan, A., Wang, G., Chiu, J., and Kuleshov, V . The diffusion duality.arXiv preprint arXiv:2506.10892,
-
[9]
L., Nagai, M., Tang, Z., Zhao, C., and Koo, P
Sarkar, A., Kang, Y ., Somia, N., Mantilla, P., Zhou, J. L., Nagai, M., Tang, Z., Zhao, C., and Koo, P. Designing dna with tunable regulatory activity using score-entropy discrete diffusion.bioRxiv, pp. 2024–05,
2024
-
[10]
Simple guidance mechanisms for discrete diffusion models.arXiv preprint arXiv:2412.10193, 2024
Schiff, Y ., Sahoo, S. S., Phung, H., Wang, G., Boshar, S., Dalla-torre, H., de Almeida, B. P., Rush, A., Pierrot, T., and Kuleshov, V . Simple guidance mechanisms for dis- crete diffusion models.arXiv preprint arXiv:2412.10193,
-
[11]
Malliaros, and Christopher Morris
Siraudin, A., Malliaros, F. D., and Morris, C. Cometh: A continuous-time discrete-state graph diffusion model. arXiv preprint arXiv:2406.06449,
-
[12]
Dirichlet Flow Matching with Applications to
Stark, H., Jing, B., Wang, C., Corso, G., Berger, B., Barzi- lay, R., and Jaakkola, T. Dirichlet flow matching with applications to dna sequence design.arXiv preprint arXiv:2402.05841,
-
[13]
The Eleventh International Conference on Learning Representations , publisher =
Vignac, C., Krawczuk, I., Siraudin, A., Wang, B., Cevher, V ., and Frossard, P. Digress: Discrete denoising diffusion for graph generation.arXiv preprint arXiv:2209.14734,
-
[14]
Wang, A. and Cho, K. Bert has a mouth, and it must speak: Bert as a markov random field language model.arXiv preprint arXiv:1902.04094,
-
[15]
Wang, G., Schiff, Y ., Sahoo, S. S., and Kuleshov, V . Re- masking discrete diffusion models with inference-time scaling.arXiv preprint arXiv:2503.00307,
-
[16]
(2024), where the last 100,000 samples are used for validation
We adopt the same train-validation splits from Sahoo et al. (2024), where the last 100,000 samples are used for validation. D.1.2. MOLECULE DATASETS QM9.The QM9 dataset (Wu et al.,
2024
-
[17]
We use the same split established by (Vignac et al., 2022), and 10000 graphs for evaluation
consists of molecules with up to 9 heavy atoms. We use the same split established by (Vignac et al., 2022), and 10000 graphs for evaluation. GuacaMol.Furthermore, we evaluate our model on the GuacaMol dataset (Brown et al., 2019). The molecules range from 2 to 88 heavy atoms. MOSES.Finally, we benchmark our model on the MOSES dataset (Polykovskiy et al., ...
2022
-
[18]
architecture from Sahoo et al. (2024). The model consists of 12 layers, a hidden dimension of 768, and 12 attention heads. Graph datasets.For the graph datasets, we use the graph transformer proposed by (Vignac et al.,
2024
-
[19]
Training settings In Table 7 and Table 8, we report the training hyperparameters used in our experiments for the different datasets
D.3. Training settings In Table 7 and Table 8, we report the training hyperparameters used in our experiments for the different datasets. 15 Interpolating Discrete Diffusion Models with Controllable Resampling Table 7.Overview of the training hyperparameters for the different experiments. QM9 Guacamol Moses Epochs 1000 250 300 Learning rate2×10 −4 2×10 −4...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.