Recognition: unknown
Towards a Data-Parameter Correspondence for LLMs: A Preliminary Discussion
Pith reviewed 2026-05-10 06:04 UTC · model grok-4.3
The pith
Data operations and parameter changes in large language models are dual aspects of the same geometric structure on a statistical manifold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes a unified data-parameter correspondence revealing these seemingly disparate operations as dual manifestations of the same geometric structure on the statistical manifold M. Grounded in the Fisher-Rao metric g_ij(θ) and Legendre duality between natural (θ) and expectation (η) parameters, it identifies three fundamental correspondences: geometric equivalence between data pruning and parameter sparsification that reduces manifold volume via dual coordinate constraints; low-rank equivalence where k-shot in-context learning and LoRA adaptation explore identical subspaces on the Grassmannian with k-shot samples equivalent to rank-r updates; and security-privacy equivalence in
What carries the argument
The data-parameter correspondence, which treats data manipulations and parameter adjustments as dual coordinate constraints on the statistical manifold via the Fisher-Rao metric and Legendre duality between natural and expectation parameters.
Load-bearing premise
The abstract geometric correspondences on the statistical manifold translate directly into practical performance gains for real large language models without additional empirical validation or hidden assumptions about model scale and data distribution.
What would settle it
Apply the proposed equivalence by using data pruning to mimic parameter sparsification on a real large language model and measure whether the resulting change in effective manifold volume or task performance matches the predicted dual reduction.
Figures



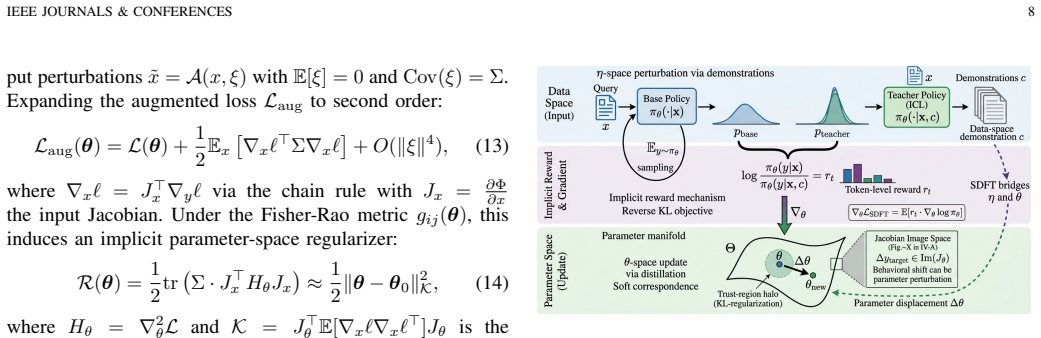



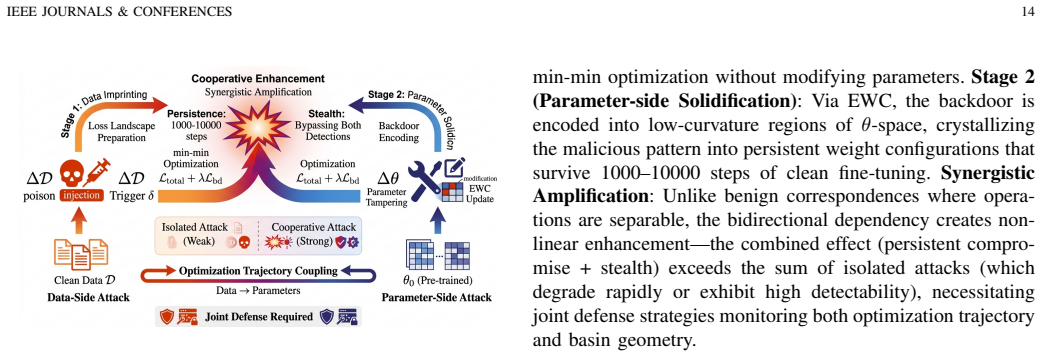




read the original abstract
Large language model optimization has historically bifurcated into isolated data-centric and model-centric paradigms: the former manipulates involved samples through selection, augmentation, or poisoning, while the latter tunes model weights via masking, quantization, or low-rank adaptation. This paper establishes a unified \emph{data-parameter correspondence} revealing these seemingly disparate operations as dual manifestations of the same geometric structure on the statistical manifold $\mathcal{M}$. Grounded in the Fisher-Rao metric $g_{ij}(\theta)$ and Legendre duality between natural ($\theta$) and expectation ($\eta$) parameters, we identify three fundamental correspondences spanning the model lifecycle: 1. Geometric correspondence: data pruning and parameter sparsification equivalently reduce manifold volume via dual coordinate constraints; 2. Low-rank correspondence: in-context learning (ICL) and LoRA adaptation explore identical subspaces on the Grassmannian $\mathcal{G}(r,d)$, with $k$-shot samples geometrically equivalent to rank-$r$ updates; 3. Security-privacy correspondence: adversarial attacks exhibit cooperative amplification between data poisoning and parameter backdoors, whereas protective mechanisms follow cascading attenuation where data compression multiplicatively enhances parameter privacy. Extending from training through post-training compression to inference, this framework provides mathematical formalization for cross-community methodology transfer, demonstrating that cooperative optimization integrating data and parameter modalities may outperform isolated approaches across efficiency, robustness, and privacy dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified data-parameter correspondence for LLMs, framing data-centric operations (pruning, poisoning, ICL) and parameter-centric operations (sparsification, LoRA, backdoors) as dual manifestations of the same geometric structures on the statistical manifold M, grounded in the Fisher-Rao metric and Legendre duality between natural and expectation parameters. It identifies three correspondences across the model lifecycle and concludes that cooperative optimization integrating both modalities may outperform isolated approaches in efficiency, robustness, and privacy.
Significance. If the claimed geometric dualities can be rigorously derived and shown to yield measurable synergies, the framework could provide a unifying language for transferring techniques between data and model optimization communities, potentially inspiring new hybrid algorithms. The preliminary discussion highlights an underexplored connection but currently offers no derivations, bounds, or experiments to substantiate the performance claims.
major comments (4)
- [Abstract] Abstract: The central claim that the three correspondences constitute a 'mathematical formalization' is unsupported, as the manuscript provides no equations, volume elements, subspace mappings, or inequalities; all statements remain at the level of conceptual assertion without explicit use of g_ij(θ) or Legendre duality.
- [Abstract] Abstract (geometric correspondence): The assertion that data pruning and parameter sparsification 'equivalently reduce manifold volume via dual coordinate constraints' lacks any derivation of the volume form under the Fisher-Rao metric or the explicit dual constraints in θ and η coordinates that would establish equivalence.
- [Abstract] Abstract (low-rank correspondence): The claim that k-shot ICL samples and rank-r LoRA updates explore 'identical subspaces on the Grassmannian G(r,d)' is stated without constructing the embedding or proving the subspace identification, leaving the equivalence unverified.
- [Abstract] Abstract (security-privacy correspondence): The statements on cooperative amplification for attacks and cascading attenuation for protection provide no quantitative bounds, multiplicative factors, or inequalities demonstrating that joint operations exceed the sum of isolated effects, undermining the outperformance conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. Our manuscript is a preliminary discussion that proposes a conceptual framework rather than a fully derived theory. We acknowledge the lack of explicit equations and quantitative results and will revise to clarify the scope of our claims, temper overstated conclusions, and add outlines of the geometric concepts where feasible. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the three correspondences constitute a 'mathematical formalization' is unsupported, as the manuscript provides no equations, volume elements, subspace mappings, or inequalities; all statements remain at the level of conceptual assertion without explicit use of g_ij(θ) or Legendre duality.
Authors: We agree that the manuscript remains at the conceptual level and does not contain explicit derivations or equations. The phrase 'mathematical formalization' refers to framing the correspondences within the established language of information geometry rather than providing a complete axiomatic treatment. In revision we will update the abstract and introduction to explicitly state the preliminary nature of the work, add a short section recalling the Fisher-Rao metric and Legendre duality with standard references, and remove any implication of full rigor. revision: yes
-
Referee: [Abstract] Abstract (geometric correspondence): The assertion that data pruning and parameter sparsification 'equivalently reduce manifold volume via dual coordinate constraints' lacks any derivation of the volume form under the Fisher-Rao metric or the explicit dual constraints in θ and η coordinates that would establish equivalence.
Authors: We acknowledge the absence of a derivation. The claimed equivalence is motivated by the standard duality between natural and expectation parameters, where a constraint in one coordinate system corresponds to a dual constraint in the other. For the revision we will insert a brief explanatory paragraph describing how the volume element induced by the Fisher-Rao metric is affected by coordinate restrictions in each parameterization, citing classical results, while noting that a full proof of equivalence is left for subsequent work. revision: yes
-
Referee: [Abstract] Abstract (low-rank correspondence): The claim that k-shot ICL samples and rank-r LoRA updates explore 'identical subspaces on the Grassmannian G(r,d)' is stated without constructing the embedding or proving the subspace identification, leaving the equivalence unverified.
Authors: The identification is offered as a geometric analogy based on both operations restricting the effective dimensionality of updates on the manifold. We will revise the relevant section to sketch the conceptual mapping (ICL samples influencing the posterior via a low-dimensional span, LoRA via column space of the update) and will explicitly label the claim as a conjecture requiring future verification rather than an established result. revision: partial
-
Referee: [Abstract] Abstract (security-privacy correspondence): The statements on cooperative amplification for attacks and cascading attenuation for protection provide no quantitative bounds, multiplicative factors, or inequalities demonstrating that joint operations exceed the sum of isolated effects, undermining the outperformance conclusion.
Authors: We agree that no quantitative bounds or inequalities are supplied. The statements are qualitative observations suggested by the duality framework. In the revision we will rephrase these passages to present the amplification and attenuation effects as hypothesized interactions rather than demonstrated superior performance, and we will add a short discussion of possible future approaches to obtaining bounds using information-geometric divergences. revision: yes
Circularity Check
No significant circularity; conceptual unification via external information geometry
full rationale
The paper proposes a data-parameter correspondence by applying standard, externally established tools (Fisher-Rao metric and Legendre duality on the statistical manifold) to map existing operations. These geometric primitives are not defined in terms of the claimed correspondences, nor do any equations reduce the outperformance suggestion to a tautology or fitted input. No self-citations, uniqueness theorems from the authors, or ansatzes smuggled via prior work appear in the abstract or described structure. The three correspondences are presented as identifications rather than derivations that presuppose their own conclusions, and the 'may outperform' statement is an interpretive extension, not a forced equality by construction. This is a normal, non-circular preliminary discussion.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Fisher-Rao metric defines distances on the statistical manifold M
- standard math Legendre duality between natural parameters theta and expectation parameters eta
invented entities (1)
-
data-parameter correspondence
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Data optimization for llms: A survey,
O. Wu, “Data optimization for llms: A survey,”TechXiv, 2025
2025
-
[2]
G. Tie, Z. Zhao, D. Songet al., “A survey on post-training of large language models,”arXiv:2503.06072, 2025
-
[3]
Efficient large language models: A survey,
Z. Wan, X. Li, H. Zhanget al., “Efficient large language models: A survey,”Transactions on Machine Learning Research, 2024
2024
-
[4]
Efficient attention mechanisms for large language models: A survey
Y . Sun, Z. Li, Y . Zhang, T. Pan, B. Donget al., “Efficient attention mechanisms for large language models: A survey,”arXiv:2507.19595, 2025
-
[5]
Parameter-efficient fine-tuning of large-scale pre-trained language models,
N. Ding, Y . Qin, G. Yang, F. Wei, Z. Yanget al., “Parameter-efficient fine-tuning of large-scale pre-trained language models,”Nature Machine Intelligence, vol. 5, no. 3, pp. 220–235, 2023
2023
-
[6]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Liet al., “LoRA: Low-rank adaptation of large language models,”arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Blockpruner: Fine- grained pruning for large language models,
L. Zhong, F. Wan, R. Chen, X. Quan, and L. Li, “Blockpruner: Fine- grained pruning for large language models,” inFindings of ACL, 2025, pp. 4562–4574
2025
-
[8]
LRQuant: Learn- able and robust post-training quantization for large language models,
J. Zhao, M. Zhang, C. Zeng, M. Wang, X. Liuet al., “LRQuant: Learn- able and robust post-training quantization for large language models,” inACL, 2024
2024
-
[9]
Security and privacy challenges of large language models: A survey,
B. C. Das, M. H. Amini, and Y . Wu, “Security and privacy challenges of large language models: A survey,”ACM Comput. Surv., vol. 57, no. 6, 2025
2025
-
[10]
Influence functions for efficient data selection in reasoning,
P. Humane, P. Cudrano, D. Z. Kaplan, M. Matteucci, S. Chakraborty et al., “Influence functions for efficient data selection in reasoning,” 2025
2025
-
[11]
A survey on data selection for llm instruction tuning,
B. Zhang, J. Wang, Q. Du, J. Zhang, Z. Tuet al., “A survey on data selection for llm instruction tuning,”Journal of Artificial Intelligence Research, vol. 83, no. 32, pp. 1–45, 2025
2025
-
[12]
Efficient prompting methods for large language models: A survey,
K. Chang, S. Xu, C. Wang, Y . Luo, T. Xiaoet al., “Efficient prompting methods for large language models: A survey,” 2024
2024
-
[13]
On large language models safety, security, and privacy: A survey,
R. Zhang, H.-W. Li, X.-Y . Qian, W.-B. Jiang, and H.-X. Chen, “On large language models safety, security, and privacy: A survey,”Journal of Electronic Science and Technology, vol. 23, no. 1, p. 100301, 2025
2025
-
[14]
A survey of recent backdoor attacks and defenses in large language models,
S. Zhao, M. Jia, Z. Guo, L. Gan, X. Xuet al., “A survey of recent backdoor attacks and defenses in large language models,”Transactions on Machine Learning Research, 2025
2025
-
[15]
Ai security in the foundation model era: A comprehensive survey from a unified perspective,
S. Luan and Z. Wang, “Ai security in the foundation model era: A comprehensive survey from a unified perspective,”TechRxiv, 2025
2025
-
[16]
LowRA: Accurate and efficient LoRA fine-tuning of LLMs under 2 bits,
Z. Zhou, Q. Zhang, H. Kumbong, and K. Olukotun, “LowRA: Accurate and efficient LoRA fine-tuning of LLMs under 2 bits,” inICML, 2025, pp. 79 570–79 594
2025
-
[17]
Adalora: Adaptive budget allocation for parameter-efficient fine- tuning,
Q. Zhang, M. Chen, A. Bukharin, N. Karampatziakis, P. Heet al., “Adalora: Adaptive budget allocation for parameter-efficient fine- tuning,” inICLR, 2023
2023
-
[18]
Sbfa: Single sneaky bit flip attack to break large language models,
J. Guo, C. Chakrabarti, and D. Fan, “Sbfa: Single sneaky bit flip attack to break large language models,”arXiv:2509.21843, 2025
-
[19]
Fast model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,” inICLR, 2022
2022
-
[20]
Automatic chain of thought prompting in large language models,
Z. Zhang, A. Zhang, M. Li, and A. Smola, “Automatic chain of thought prompting in large language models,” inICLR, 2023
2023
-
[21]
Information geometry of neural network pruning,
I. Sato, M. Yamada, and M. Sugiyama, “Information geometry of neural network pruning,”Transactions on Machine Learning Research, 2023, also available as arXiv:2108.03783
-
[22]
X. Bouthillier, K. Konda, P. Vincent, and R. Memisevic, “Dropout as data augmentation,”arXiv:1506.08700, 2015
-
[23]
Deep augmentation: Dropout as augmentation for self-supervised learning,
R. Br ¨uel-Gabrielsson, T. Wang, M. Baradad, and J. Solomon, “Deep augmentation: Dropout as augmentation for self-supervised learning,” Transactions on Machine Learning Research, 2025
2025
-
[24]
Regularizing deep networks with semantic data augmentation,
Y . Wang, G. Huang, S. Song, X. Pan, Y . Xiaet al., “Regularizing deep networks with semantic data augmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 7, pp. 3733– 3748, 2021
2021
-
[25]
Self-Distillation Enables Continual Learning
I. Shenfeld, M. Damani, J. H ¨ubotter, and P. Agrawal, “Self-distillation enables continual learning,”arXiv:2601.19897, 2026
work page internal anchor Pith review arXiv 2026
-
[26]
Transformers learn in-context by gradient descent,
J. von Oswald, E. Niklasson, E. Randazzo, J. Sacramento, A. Mord- vintsevet al., “Transformers learn in-context by gradient descent,” inInternational Conference on Machine Learning, 2023, pp. 35 151– 35 174
2023
-
[27]
Why can GPT learn in-context? language models secretly perform gradient descent as meta- optimizers,
D. Dai, Y . Sun, L. Dong, Y . Hao, S. Maet al., “Why can GPT learn in-context? language models secretly perform gradient descent as meta- optimizers,” inFindings of ACL, 2023, pp. 4005–4019
2023
-
[28]
What learning algorithm is in-context learning? investigations with linear models,
E. Aky ¨urek, D. Schuurmans, J. Andreas, T. Ma, and D. Zhou, “What learning algorithm is in-context learning? investigations with linear models,” inThe Eleventh International Conference on Learning Rep- resentations, 2023
2023
-
[29]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplanet al., “Language models are few-shot learners,” inNeurIPS, vol. 33, 2020, pp. 1877–1901
2020
-
[30]
Rethinking the role of demonstrations: What makes in-context learning work?
S. Min, M. Lewis, H. Hajishirzi, and L. Zettlemoyer, “Rethinking the role of demonstrations: What makes in-context learning work?” in EMNLP, 2022, pp. 11 048–11 064
2022
-
[31]
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,
P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashiet al., “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,”ACM Computing Surveys, vol. 55, no. 9, pp. 1–35, 2023
2023
-
[32]
Parameter-efficient transfer learning for NLP,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. de Laroussilhe et al., “Parameter-efficient transfer learning for NLP,” inICML, 2019, pp. 2790–2799
2019
-
[33]
AdapterFu- sion: Non-destructive task composition for transfer learning,
J. Pfeiffer, A. R ¨uckl´e, C. Poth, A. Kamath, I. Vuli ´cet al., “AdapterFu- sion: Non-destructive task composition for transfer learning,” inEACL, 2021, pp. 487–503
2021
-
[34]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Joneset al., “Attention is all you need,” inNeurIPS, vol. 30, 2017
2017
-
[35]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Z. Dai, Z. Yang, Y . Yang, J. Carbonell, Q. V . Leet al., “Transformer- XL: Attentive language models beyond a fixed-length context,” arXiv:1901.02860, 2019
work page Pith review arXiv 1901
-
[36]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeurIPS 2022 Workshop on Deep Generative Models and Downstream Applica- tions, 2022
2022
-
[37]
Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in NLP,
T. Schick, S. Udupa, and H. Sch ¨utze, “Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in NLP,” inEMNLP, 2021, pp. 2128–2142
2021
-
[38]
Energy-based out- of-distribution detection,
Y . Du, H. Zhang, Y . Yang, J. Feng, N. Chenet al., “Energy-based out- of-distribution detection,” inNeurIPS, vol. 33, 2020, pp. 21 464–21 475
2020
-
[39]
Energy-based text generation with contrastive learning,
Y . Xiao, Y . Meng, P. Xie, Y . Liu, J. Zhanget al., “Energy-based text generation with contrastive learning,”arXiv:2106.10820, 2021
-
[40]
Flashsampling: Fast and memory-efficient exact sampling,
T. Ruiz, Z. Qin, Y . Zhang, X. Shen, Y . Zhonget al., “Flashsampling: Fast and memory-efficient exact sampling,”arXiv:2603.15854, 2026
work page internal anchor Pith review arXiv 2026
-
[41]
Compiling machine learning programs via high-level tracing,
R. Frostig, M. J. Johnson, and C. Leary, “Compiling machine learning programs via high-level tracing,”Systems for Machine Learning, pp. 23–24, 2018
2018
-
[42]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardinset al., “Overcoming catastrophic forgetting in neural networks,”Proceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[43]
Amari,Information Geometry and Its Applications, ser
S.-i. Amari,Information Geometry and Its Applications, ser. Applied Mathematical Sciences. Tokyo: Springer, 2016, vol. 194. IEEE JOURNALS & CONFERENCES 25
2016
-
[44]
New insights and perspectives on the natural gradient method,
J. Martens, “New insights and perspectives on the natural gradient method,”Journal of Machine Learning Research, vol. 21, no. 1, pp. 1–76, 2020
2020
-
[45]
Gradient based sample selection for online continual learning,
R. Aljundi, M. Lin, B. Goujaud, and Y . Bengio, “Gradient based sample selection for online continual learning,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[46]
Badclip++: Stealthy and persistent backdoors in multimodal contrastive learning,
S. Liang, Y . Jing, Y . Wang, J. Huang, E. chien Changet al., “Badclip++: Stealthy and persistent backdoors in multimodal contrastive learning,” arXiv:2602.17168, 2026
-
[47]
Fisher information guided purification against backdoor attacks,
N. Karim, A. Al Arafat, A. S. Rakin, Z. Guo, and N. Rahnavard, “Fisher information guided purification against backdoor attacks,” in Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 4435–4449
2024
-
[48]
Parameter disparities dissection for backdoor defense in heterogeneous federated learning,
W. Huang, M. Ye, Z. Shi, G. Wan, H. Liet al., “Parameter disparities dissection for backdoor defense in heterogeneous federated learning,” in Advances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[49]
Dwork and A
C. Dwork and A. Roth,The Algorithmic Foundations of Differential Privacy, ser. Foundations and Trends in Theoretical Computer Science. Hanover, MA: Now Publishers, 2014, vol. 9, no. 3–4
2014
-
[50]
What can we learn privately?
S. P. Kasiviswanathan, H. K. Lee, K. Nissim, S. Raskhodnikova, and A. Smith, “What can we learn privately?”SIAM Journal on Computing, 2011
2011
-
[51]
Subsampled R ´enyi differential privacy and analytical moments accountant,
Y .-X. Wang, B. Balle, and S. P. Kasiviswanathan, “Subsampled R ´enyi differential privacy and analytical moments accountant,” inAISTATS, 2019
2019
-
[52]
Scalable extraction of training data from (production) language models: 2025 update and mitigations,
M. Nasr, N. Carlini, J. Hayaseet al., “Scalable extraction of training data from (production) language models: 2025 update and mitigations,” inIEEE Symposium on Security and Privacy (S&P). IEEE, 2025
2025
-
[53]
Parameter inversion attacks against foundation models via gradient matching and information leak- age,
Y . Zhang, Z. Li, H. Wang, and J. Chen, “Parameter inversion attacks against foundation models via gradient matching and information leak- age,” inACM Conference on Computer and Communications Security (CCS). ACM, 2025
2025
-
[54]
Information-theoretic privacy bounds for machine learning: Unified framework and applications to llms,
Z. Wang, Y . Liu, and M. Li, “Information-theoretic privacy bounds for machine learning: Unified framework and applications to llms,”IEEE Transactions on Information Theory, vol. 71, no. 3, pp. 2345–2360, 2025
2025
-
[55]
Sufficient statistics privacy: Dimension- ality reduction and optimal noise calibration,
X. Li, W. Chen, and T. Liu, “Sufficient statistics privacy: Dimension- ality reduction and optimal noise calibration,”IEEE Transactions on Information Theory, vol. 71, no. 2, pp. 1234–1250, 2025
2025
-
[56]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” inIEEE Symposium on Security and Privacy (S&P). IEEE, 2017, pp. 3–18
2017
-
[57]
Cascading privacy protection for distributed deep learning,
Y . Guo, Y . Liu, and K. Zhang, “Cascading privacy protection for distributed deep learning,” inInternational Conference on Learning Representations (ICLR). OpenReview, 2025
2025
-
[58]
Communication-efficient federated learning with sketching and privacy guarantees,
Y . Duan, H. Chen, and Y . Xu, “Communication-efficient federated learning with sketching and privacy guarantees,” inACM Conference on Computer and Communications Security (CCS). ACM, 2025
2025
-
[59]
Practical secure aggregation for privacy-preserving machine learning,
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan et al., “Practical secure aggregation for privacy-preserving machine learning,” inProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS). Dallas, TX, USA: ACM, 2017, pp. 1175–1191
2017
-
[60]
Protocols for secure computations,
A. C.-C. Yao, “Protocols for secure computations,” inProceedings of the 23rd Annual IEEE Symposium on Foundations of Computer Science (FOCS), 1982, pp. 160–164
1982
-
[61]
Baseline defenses for adversarial attacks against aligned language models,
N. Jain, A. Schwarzschild, Y . Wen, J. Kirchenbauer, J. Geipinget al., “Baseline defenses for adversarial attacks against aligned language models,” inProc. NeurIPS Workshop on Socially Responsible Language Modelling Research, 2023
2023
-
[62]
Robust large margin deep neural networks,
J. Sokolic, R. Giryes, G. Sapiro, and M. R. D. Rodrigues, “Robust large margin deep neural networks,”IEEE Transactions on Signal Processing, vol. 65, no. 16, pp. 4265–4280, 2017
2017
-
[63]
Pay attention to attention distribution: A new lo- cal lipschitz bound for transformers
N. Yudin, A. Gaponov, S. Kudriashov, and M. Rakhuba, “Pay attention to attention distribution: A new local lipschitz bound for transformers,” arXiv:2507.07814, 2025
-
[64]
Understanding and improving continuous llm adversarial training via in-context learning theory,
S. Fu and D. Wang, “Understanding and improving continuous llm adversarial training via in-context learning theory,” inInternational Conference on Learning Representations, 2026
2026
-
[65]
The Defense Trilemma: Why Prompt Injection Defense Wrappers Fail?
M. Bhatt, S. Munshi, V . S. Narajala, I. Habler, A. Al-Kahfahet al., “The defense trilemma: Why prompt injection defense wrappers fail?” arXiv:2604.06436, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Linear mode connectivity and the lottery ticket hypothesis,
J. Frankle, G. K. Dziugaite, D. M. Roy, and M. Carbin, “Linear mode connectivity and the lottery ticket hypothesis,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 3259–3269
2020
-
[67]
The role of permutation invariance in linear mode connectivity of neural networks,
R. Entezari, H. Sedghi, O. Saukh, and B. Neyshabur, “The role of permutation invariance in linear mode connectivity of neural networks,” inInternational Conference on Learning Representations, 2022
2022
-
[68]
Git re-basin: Merging models modulo permutation symmetries,
S. K. Ainsworth, J. Hayase, and S. Srinivasa, “Git re-basin: Merging models modulo permutation symmetries,” inInternational Conference on Learning Representations, 2023
2023
-
[69]
Data mixing laws: Op- timizing data mixtures by predicting language modeling performance,
J. Ye, P. Liu, T. Sun, Y . Zhou, J. Zhanet al., “Data mixing laws: Op- timizing data mixtures by predicting language modeling performance,” inICLR, 2025
2025
-
[70]
Adaptive data mixing for domain- specific fine-tuning of large language models,
X. Zhang, Y . Liu, and W. Chen, “Adaptive data mixing for domain- specific fine-tuning of large language models,” inInternational Confer- ence on Learning Representations (ICLR), 2025
2025
-
[71]
Ties-merging: Resolving interference when merging models,
P. Yadav, T. Yu, M. Li, D. Chen, D. Jacobset al., “Ties-merging: Resolving interference when merging models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 37, 2024
2024
-
[72]
Language models are super mario: Absorbing abilities from homologous models as a free lunch,
L. Yu, B. Yu, H. Yu, F. Huang, and Y . Li, “Language models are super mario: Absorbing abilities from homologous models as a free lunch,” inInternational Conference on Machine Learning (ICML), 2024, pp. 41 506–41 527
2024
-
[73]
Model breadcrumbs: Scaling multi-task model merging with sparse masks,
M. Davari and E. Belilovsky, “Model breadcrumbs: Scaling multi-task model merging with sparse masks,” inECCV, 2024, pp. 270–287
2024
-
[74]
Mix data or merge models? balancing the helpfulness, honesty, and harmlessness of large language model via model merging,
J. Yang, D. Jin, A. Tang, L. Shen, D. Zhuet al., “Mix data or merge models? balancing the helpfulness, honesty, and harmlessness of large language model via model merging,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[75]
Multi-task code llms: Data mix or model merge?
Y . Zhang, M. Liu, Y . Wang, J. Chen, Y . Zhaoet al., “Multi-task code llms: Data mix or model merge?” inICSE 2026 LLM4Code Workshop, 2026
2026
-
[76]
Mergemix: Optimizing mid-training data mixtures via learnable model merging,
J. Wang, C. Tian, K. Chen, Z. Liu, J. Maoet al., “Mergemix: Optimizing mid-training data mixtures via learnable model merging,” arXiv:2601.17858, 2026
-
[77]
S. Li, F. Zhao, K. Zhao, J. Ye, H. Liuet al., “Decouple searching from training: Scaling data mixing via model merging for large language model pre-training,”arXiv:2602.00747, 2026
-
[78]
Model soups: averaging weights of multiple fine-tuned models improves accu- racy without increasing inference time,
M. Wortsman, G. Ilharco, M. Li, J. W. Kim, H. Hajishirziet al., “Model soups: averaging weights of multiple fine-tuned models improves accu- racy without increasing inference time,” inICML, 2022, pp. 23 965– 23 998
2022
-
[79]
Editing models with task arithmetic,
G. Ilharco, M. T. Ribeiro, M. Wortsman, S. Gururangan, L. Schmidt et al., “Editing models with task arithmetic,”ICLR, 2023
2023
-
[80]
Task vectors in the wild: Analyzing and controlling model merging interference,
J. Ortiz, P. Liang, and T. Hashimoto, “Task vectors in the wild: Analyzing and controlling model merging interference,” inProceedings of the 13th International Conference on Learning Representations (ICLR 2025), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.