Recognition: unknown
Machine Learning Hamiltonian Dynamical Systems with Sparse and Noisy Data
Pith reviewed 2026-05-10 06:59 UTC · model grok-4.3
The pith
ASRNNs recover accurate long-term Hamiltonian dynamics and symbolic equations from only two noisy time points per trajectory
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adaptable Symplectic Recurrent Neural Networks (ASRNNs), which combine parameter-cognizant Hamiltonian learning with symplectic recurrent integration, enable accurate long-term prediction of nonlinear dynamics and subsequent symbolic discovery even when each training trajectory consists of only two irregularly spaced time points possibly corrupted by correlated noise.
What carries the argument
Adaptable Symplectic Recurrent Neural Networks (ASRNNs) that embed Hamiltonian structure and symplectic integration to train without derivative estimates and generate stable trajectories from minimal data.
If this is right
- Long-term dynamics can be predicted accurately under extreme data scarcity without dense sampling or derivative computation.
- Exact symbolic Hamiltonians can be recovered for polynomial systems by feeding ASRNN-generated trajectories into SINDy or PySR.
- Consistent polynomial approximations are obtained for non-polynomial Hamiltonians through the same pipeline.
- The method eliminates reliance on time-derivative estimation that usually fails under noise and irregularity.
Where Pith is reading between the lines
- The same structure-preserving generation step could support discovery tasks in other conservative systems beyond strict Hamiltonians.
- Experimental settings that record only initial and final states of a process become viable for model reconstruction.
- Internal generation of clean data may reduce propagation of measurement noise into the final symbolic equations.
Load-bearing premise
The underlying system must be Hamiltonian and the symplectic recurrent integration must remain stable and faithful when trained on only two noisy points per trajectory without derivative information.
What would settle it
Train an ASRNN on a known simple Hamiltonian such as the harmonic oscillator using only two noisy irregularly spaced points per trajectory and observe whether long-term predictions stay bounded and periodic or diverge from the true solution.
Figures








read the original abstract
Machine learning has become a powerful tool for discovering governing laws of dynamical systems from data. However, most existing approaches degrade severely when observations are sparse, noisy, or irregularly sampled. In this work, we address the problem of learning symbolic representations of nonlinear Hamiltonian dynamical systems under extreme data scarcity by explicitly incorporating physical structure into the learning architecture. We introduce Adaptable Symplectic Recurrent Neural Networks (ASRNNs), a parameter-cognizant, structure-preserving model that combines Hamiltonian learning with symplectic recurrent integration, avoiding time derivative estimation, and enabling stable learning under noise. We demonstrate that ASRNNs can accurately predict long-term dynamics even when each training trajectory consists of only two irregularly spaced time points, possibly corrupted by correlated noise. Leveraging ASRNNs as structure-preserving data generators, we further enable symbolic discovery using independent regression methods (SINDy and PySR), recovering exact symbolic equations for polynomial systems and consistent polynomial approximations for non-polynomial Hamiltonians. Our results show that such architectures can provide a robust pathway to interpretable discovery of Hamiltonian dynamics from sparse and noisy data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Adaptable Symplectic Recurrent Neural Networks (ASRNNs) that combine Hamiltonian neural networks with symplectic recurrent integration to learn governing equations of nonlinear Hamiltonian systems from extremely sparse data (only two irregularly spaced, possibly noisy points per trajectory) without requiring derivative estimates. The learned models are then used as structure-preserving data generators to enable symbolic regression via SINDy and PySR, with claims of recovering exact symbolic Hamiltonians for polynomial cases and consistent approximations otherwise, while achieving accurate long-term dynamical predictions.
Significance. If the central claims hold under rigorous validation, this would represent a meaningful advance in physics-informed machine learning for data-scarce regimes, explicitly leveraging symplectic structure to stabilize learning and enable downstream interpretable discovery. The avoidance of derivative estimation and the two-point training regime address practical challenges in experimental data collection.
major comments (2)
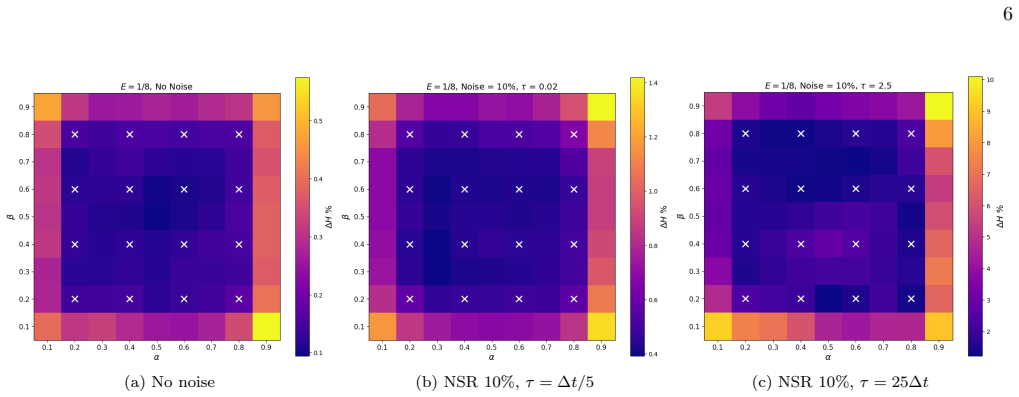
- [§3.2] §3.2, Eq. (7) (endpoint-matching loss): The loss minimizes discrepancy only between the observed second point and the symplectically integrated endpoint from the first point across irregular pairs. This does not automatically guarantee that the recovered vector field produces faithful long-term orbits or frequencies, as the symplectic property prevents energy drift but multiple nearby Hamiltonians can agree on short-time maps while diverging over longer horizons; the manuscript must include explicit long-term trajectory error metrics (e.g., phase-space distance or frequency spectra) against ground truth beyond the training interval, with ablations removing the symplectic constraint.
- [Results] Results, Table 2 and Figure 4: The reported long-term prediction accuracy for the two-point noisy regime lacks quantitative baselines (e.g., non-symplectic RNNs or standard HNNs), error bars over multiple noise realizations and initial conditions, and statistical tests; without these, the claim that ASRNNs 'accurately predict long-term dynamics' under correlated noise cannot be assessed as load-bearing evidence.
minor comments (2)
- [Abstract] Abstract: The phrase 'parameter-cognizant' is used without prior definition or reference; define it explicitly when first introduced in §2.
- [§5] §5: The transition from ASRNN-generated trajectories to SINDy/PySR regression should include a brief statement on how noise in the generated data is handled during symbolic fitting.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the validation requirements for our claims on long-term dynamics. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2, Eq. (7) (endpoint-matching loss): The loss minimizes discrepancy only between the observed second point and the symplectically integrated endpoint from the first point across irregular pairs. This does not automatically guarantee that the recovered vector field produces faithful long-term orbits or frequencies, as the symplectic property prevents energy drift but multiple nearby Hamiltonians can agree on short-time maps while diverging over longer horizons; the manuscript must include explicit long-term trajectory error metrics (e.g., phase-space distance or frequency spectra) against ground truth beyond the training interval, with ablations removing the symplectic constraint.
Authors: We agree that short-interval endpoint matching alone does not guarantee long-term fidelity, even under symplectic integration. While our architecture leverages symplecticity to stabilize learning and prevent energy drift, we will strengthen the manuscript by adding explicit long-term error metrics (phase-space distances and frequency spectra over horizons substantially longer than the training interval) and ablations that remove the symplectic constraint to isolate its contribution. revision: yes
-
Referee: [Results] Results, Table 2 and Figure 4: The reported long-term prediction accuracy for the two-point noisy regime lacks quantitative baselines (e.g., non-symplectic RNNs or standard HNNs), error bars over multiple noise realizations and initial conditions, and statistical tests; without these, the claim that ASRNNs 'accurately predict long-term dynamics' under correlated noise cannot be assessed as load-bearing evidence.
Authors: We acknowledge that the current results would be more robust with additional baselines and statistical support. In the revised version we will expand Table 2 and Figure 4 to include direct comparisons against non-symplectic RNNs and standard HNNs, report error bars across multiple noise realizations and initial conditions, and include statistical tests to substantiate the long-term prediction claims under correlated noise. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core architecture (ASRNNs) embeds external Hamiltonian and symplectic constraints from physics into the recurrent integration scheme, then trains via endpoint matching on sparse pairs; this does not reduce the long-term prediction claim to a definitional tautology or fitted-input renaming because the loss only enforces short-interval consistency while the symplectic property is an independent structural prior. Subsequent symbolic regression via SINDy/PySR operates on trajectories generated from the learned model and is not required for the primary claim. No self-citation chain, uniqueness theorem imported from the authors, or ansatz smuggling appears in the provided abstract or described workflow; the derivation remains self-contained against external physical principles rather than circularly re-expressing its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The dynamical system obeys Hamiltonian mechanics and can be integrated symplectically
Reference graph
Works this paper leans on
-
[1]
We propose ASRNNs (Adaptable Symplectic Recurrent Neural Networks) which combine parameter-cognizant Hamiltonian learning with symplectic recurrence
replace derivative-based losses with recurrent inte- gration using symplectic integrators, but are restricted to separable HamiltoniansH(q,p) =K(p) +V(q) where K,Vare kinetic and potential energy functions respec- tively. We propose ASRNNs (Adaptable Symplectic Recurrent Neural Networks) which combine parameter-cognizant Hamiltonian learning with symplect...
-
[2]
We trained an ensemble of 40 mod- els with independent random initialisations of both data slices and network weights
for 500 epochs. We trained an ensemble of 40 mod- els with independent random initialisations of both data slices and network weights. Typical training times were a few minutes per model on an Nvidia 4070Ti Super GPU with 16GB VRAM
-
[3]
Prediction After training, ASRNNs were evaluated on trajecto- ries generated at unseen parameter values and compared against ground truth Verlet integrations. To ascertain the quality of our predictions we considered both the gen- erated trajectories themselves as well as the kinetic and potential energies predicted by the networks, i.e.K θ1 and Vθ2 respe...
-
[4]
Long, regularly spaced trajectories are generated and passed to PySINDy
Symbolic Regression To enable interpretability, ASRNNs are used as data generators for symbolic regression. Long, regularly spaced trajectories are generated and passed to PySINDy
-
[5]
The former is specifically designed to identify nonlinear dynamical systems of the form˙ x= f(x) while PySR is more flexible and can learn symbolic forms of general functionsf(x)
and PySR [33]. The former is specifically designed to identify nonlinear dynamical systems of the form˙ x= f(x) while PySR is more flexible and can learn symbolic forms of general functionsf(x). PySINDy takes as input -0.5 -0.25 0 0.25 0.5 q1 0.50 0.25 0.00 0.25 0.50 q2 (a) Predicted trajectory -0.5 -0.25 0 0.25 0.5 q1 0.50 0.25 0.00 0.25 0.50 (b) True tr...
-
[6]
Mθ(z0) + X i η0i ∂Mθ ∂zi (z0) + 1 2 X i,j η0iη0j ∂Mθ ∂zi∂zj (z0) #T
Symbolic Regression As before, trained ASRNNs are used to generate regular trajectories for symbolic regression. Because PySINDy does not support exponential basis functions without prior specification, we apply PySR directly to the 0.30 0.34 0.38 0.42 0% 5% 10% 0.40 0.44 0.48 0.52 0.0 0.5 1.0 1.5 2.0 2.5 0.52 0.56 0.60 0.64 (a) 0.0 0.5 1.0 1.5 2.0 2.5 0....
2000
-
[7]
Fθ(z0) + X i η0i ∂Fθ ∂zi (z0) + 1 2 X i,j η0iη0j ∂Fθ ∂zi∂zj (z0) #T
Expected loss gradient for AHNNs We can derive an analogue of Theorem 1 for an adapt- able AHNN to illustrate the bias-variance tradeoff of us- ing finite difference estimators for training AHNNs in noisy conditions. Theorem 2.Let ˆ˙z(θ;z) = (∂ pHθ(z;λ),−∂ qHθ(z;λ)) denote the AHNN vector field with model parameters θ. Let the initial (noiseless) observat...
-
[8]
Angelis, F
D. Angelis, F. Sofos, and T. E. Karakasidis, Artificial in- telligence in physical sciences: Symbolic regression trends and perspectives, Archives of Computational Methods in Engineering30, 3845 (2023)
2023
-
[9]
Makke and S
N. Makke and S. Chawla, Interpretable scientific discov- ery with symbolic regression: a review, Artificial Intelli- gence Review57, 2 (2024)
2024
-
[10]
H. Wang, T. Fu, Y. Du, W. Gao, K. Huang, Z. Liu, P. Chandak, S. Liu, P. Van Katwyk, A. Deac,et al., Scientific discovery in the age of artificial intelligence, Nature620, 47 (2023)
2023
-
[11]
Y. Xu, X. Liu, X. Cao, C. Huang, E. Liu, S. Qian, X. Liu, Y. Wu, F. Dong, C.-W. Qiu,et al., Artificial intelligence: A powerful paradigm for scientific research, The Innova- tion2(2021)
2021
-
[12]
Jumper, R
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Fig- urnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. ˇZ´ ıdek, A. Potapenko,et al., Highly accurate protein structure prediction with AlphaFold, Nature596, 583 (2021)
2021
-
[13]
Merchant, S
A. Merchant, S. Batzner, S. S. Schoenholz, M. Aykol, G. Cheon, and E. D. Cubuk, Scaling deep learning for materials discovery, Nature624, 80 (2023)
2023
-
[14]
F. E. Arhouni, M. A. S. Abdo, S. Ouakkas, M. L. Bouhssa, and A. Boukhair, Artificial intelligence-driven advances in nuclear technology: Exploring innovations, applications, and future prospects, Annals of Nuclear En- ergy213, 111151 (2025)
2025
-
[15]
Pavone, A
A. Pavone, A. Merlo, S. Kwak, and J. Svensson, Ma- chine learning and Bayesian inference in nuclear fusion research: an overview, Plasma Physics and Controlled Fusion65, 053001 (2023)
2023
-
[16]
Bracco, J
A. Bracco, J. Brajard, H. A. Dijkstra, P. Hassanzadeh, C. Lessig, and C. Monteleoni, Machine learning for the physics of climate, Nature Reviews Physics7, 6 (2025)
2025
-
[17]
Eyring, W
V. Eyring, W. D. Collins, P. Gentine, E. A. Barnes, M. Barreiro, T. Beucler, M. Bocquet, C. S. Bretherton, H. M. Christensen, K. Dagon,et al., Pushing the frontiers in climate modelling and analysis with machine learning, Nature Climate Change14, 916 (2024)
2024
-
[18]
C.-Y. Lai, P. Hassanzadeh, A. Sheshadri, M. Sonnewald, R. Ferrari, and V. Balaji, Machine learning for climate 12 physics and simulations, Annual Review of Condensed Matter Physics16, 343 (2024)
2024
-
[19]
R. Lam, A. Sanchez-Gonzalez, M. Willson, P. Wirns- berger, M. Fortunato, F. Alet, S. Ravuri, T. Ewalds, Z. Eaton-Rosen, W. Hu, A. Merose, S. Hoyer, G. Hol- land, O. Vinyals, J. Stott, A. Pritzel, S. Mohamed, and P. Battaglia, Learning skillful medium-range global weather forecasting, Science382, 1416 (2023)
2023
-
[20]
S. L. Brunton and J. N. Kutz, Promising directions of machine learning for partial differential equations, Na- ture Computational Science4, 483 (2024)
2024
-
[21]
Kochkov, J
D. Kochkov, J. A. Smith, A. Alieva, Q. Wang, M. P. Brenner, and S. Hoyer, Machine learning–accelerated computational fluid dynamics, Proceedings of the Na- tional Academy of Sciences118, e2101784118 (2021)
2021
-
[22]
Praˇ snikar, M
E. Praˇ snikar, M. Ljubiˇ c, A. Perdih, and J. Boriˇ sek, Ma- chine learning heralding a new development phase in molecular dynamics simulations, Artificial intelligence re- view57, 102 (2024)
2024
-
[23]
Vinuesa and S
R. Vinuesa and S. L. Brunton, Enhancing computational fluid dynamics with machine learning, Nature Computa- tional Science2, 358 (2022)
2022
-
[24]
Karniadakis, Y
G. Karniadakis, Y. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, Physics-informed machine learn- ing, Nature Reviews Physics3, 422 (2021)
2021
-
[25]
J. D. Toscano, V. Oommen, A. J. Varghese, Z. Zou, N. Ahmadi Daryakenari, C. Wu, and G. E. Karniadakis, From PINNs to PIKANs: Recent advances in physics- informed machine learning, Machine Learning for Com- putational Science and Engineering1, 15 (2025)
2025
-
[26]
Goldstein, C
H. Goldstein, C. P. Poole, and J. L. Safko,Classical Me- chanics, 3rd ed. (Addison Wesley, San Francisco, CA, USA, 2002)
2002
-
[27]
Greydanus, M
S. Greydanus, M. Dzamba, and J. Yosinski, Hamiltonian neural networks, inAdvances in Neural Information Pro- cessing Systems, Vol. 32 (2019)
2019
-
[28]
Choudhary, J
A. Choudhary, J. F. Lindner, E. G. Holliday, S. T. Miller, S. Sinha, and W. L. Ditto, Physics-enhanced neural net- works learn order and chaos, Physical Review E101, 062207 (2020)
2020
-
[29]
C.-D. Han, B. Glaz, M. Haile, and Y.-C. Lai, Adaptable Hamiltonian neural networks, Physical Review Research 3, 023156 (2021)
2021
-
[30]
Z. Chen, J. Zhang, M. Arjovsky, and L. Bottou, Sym- plectic recurrent neural networks, inInternational Con- ference on Learning Representations(2020)
2020
-
[31]
Xiong, Y
S. Xiong, Y. Tong, X. He, S. Yang, C. Yang, and B. Zhu, Nonseparable symplectic neural networks, inInterna- tional Conference on Learning Representations(2021)
2021
-
[32]
Cranmer, S
M. Cranmer, S. Greydanus, S. Hoyer, P. Battaglia, D. Spergel, and S. Ho, Lagrangian neural networks, in ICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations(2020)
2020
-
[33]
Choudhary, J
A. Choudhary, J. F. Lindner, E. G. Holliday, S. T. Miller, S. Sinha, and W. L. Ditto, Forecasting Hamiltonian dy- namics without canonical coordinates, Nonlinear Dynam- ics103, 1553 (2021)
2021
-
[34]
Finzi, K
M. Finzi, K. A. Wang, and A. G. Wilson, Simplifying Hamiltonian and Lagrangian neural networks via explicit constraints, inAdvances in Neural Information Process- ing Systems, Vol. 33 (2020)
2020
-
[35]
A. Sosanya and S. Greydanus, Dissipative Hamiltonian neural networks: Learning dissipative and conservative dynamics separately, arXiv preprint arXiv:2201.10085 (2022)
-
[36]
P. Jin, Z. Zhang, A. Zhu, Y. Tang, and G. E. Karniadakis, SympNets: Intrinsic structure-preserving symplectic net- works for identifying Hamiltonian systems, Neural Net- works132, 166 (2020)
2020
-
[37]
P. Horn, V. Saz Ulibarrena, B. Koren, and S. Portegies Zwart, A generalized framework of neural networks for Hamiltonian systems, Journal of Computational Physics 521, 113536 (2025)
2025
-
[38]
G. I. Allen, L. Gan, and L. Zheng, Interpretable machine learning for discovery: Statistical challenges and oppor- tunities, Annual Review of Statistics and its Application 11, 97 (2023)
2023
-
[39]
S. L. Brunton, J. L. Proctor, and J. N. Kutz, Discover- ing governing equations from data by sparse identifica- tion of nonlinear dynamical systems, Proceedings of the National Academy of Sciences113, 3932 (2016)
2016
-
[40]
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl
M. Cranmer, Interpretable machine learning for science with PySR and SymbolicRegression.jl, arXiv preprint arXiv:2305.01582 (2023)
work page internal anchor Pith review arXiv 2023
-
[41]
DiPietro, S
D. DiPietro, S. Xiong, and B. Zhu, Sparse symplectically integrated neural networks, inAdvances in Neural Infor- mation Processing Systems, Vol. 33 (2020)
2020
-
[42]
T.-T. Gao, B. Barzel, and G. Yan, Learning interpretable dynamics of stochastic complex systems from experimen- tal data, Nature Communications15, 6029 (2024)
2024
-
[43]
Guimer` a, I
R. Guimer` a, I. Reichardt, A. Aguilar-Mogas, F. A. Mas- succi, M. Miranda, J. Pallar` es, and M. Sales-Pardo, A Bayesian machine scientist to aid in the solution of chal- lenging scientific problems, Science Advances6, eaav6971 (2020)
2020
-
[44]
R. Iten, T. Metger, H. Wilming, L. del Rio, and R. Ren- ner, Discovering physical concepts with neural networks, Physical Review Letters124, 010508 (2020)
2020
-
[45]
Udrescu and M
S.-M. Udrescu and M. Tegmark, AI Feynman: A physics- inspired method for symbolic regression, Science Ad- vances6, eaay2631 (2020)
2020
-
[46]
Liu and M
Z. Liu and M. Tegmark, Machine learning conserva- tion laws from trajectories, Physical Review Letters126, 180604 (2021)
2021
-
[47]
Lemos, N
P. Lemos, N. Jeffrey, M. Cranmer, S. Ho, and P. Battaglia, Rediscovering orbital mechanics with ma- chine learning, Machine Learning: Science and Technol- ogy4, 045002 (2023)
2023
-
[48]
J. Hsin, S. Agarwal, A. Thorpe, L. Sentis, and D. Fridovich-Keil, Symbolic regression on sparse and noisy data with Gaussian processes, in2025 American Control Conference (ACC)(2025)
2025
-
[49]
G. E. Uhlenbeck and L. S. Ornstein, On the theory of the Brownian motion, Physical Review36, 823 (1930)
1930
-
[50]
More complex architectures were tested but did not im- prove performance under extreme sparsity
-
[51]
D. C. Liu and J. Nocedal, On the limited memory BFGS method for large scale optimization, Mathematical pro- gramming45, 503 (1989)
1989
-
[52]
This is not due to weaker predictions from the ASRNN but rather due to performance of the symbolic regres- sion algorithms themselves, to confirm this we also at- tempted the symbolic regression with ‘ground truth’ data and found the same results
-
[53]
See Supplementary material for exact expressions
-
[54]
K. Xu, M. Zhang, J. Li, S. S. Du, K.-I. Kawarabayashi, and S. Jegelka, How neural networks extrapolate: From feedforward to graph neural networks, inInternational 13 Conference on Learning Representations(2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.