Recognition: unknown
STRIKE: Additive Feature-Group-Aware Stacking Framework for Credit Default Prediction
Pith reviewed 2026-05-10 06:07 UTC · model grok-4.3
The pith
Decomposing credit features into semantic groups and stacking their predictions improves default risk estimation over standard models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Rather than training a single model on the full feature set, the framework partitions features into semantically coherent groups, fits independent learners to each group, and aggregates the resulting predictions through a meta-learner. This additive approach yields superior AUC-ROC performance across corporate and consumer credit datasets compared to standard baselines. The improvement is shown to arise from the decomposition strategy itself rather than added model complexity.
What carries the argument
Feature-group-aware stacking, which isolates complementary signals from different feature groups before meta-aggregation.
If this is right
- Consistently higher AUC-ROC than tree-based baselines and conventional stacking on bankruptcy and lending data
- Performance gains trace to meaningful feature decomposition rather than increased model complexity
- Yields a stable, scalable, and interpretable framework for credit risk tasks
Where Pith is reading between the lines
- Similar grouping strategies could benefit prediction tasks in other domains with heterogeneous tabular features
- Inspecting the contribution of each group model may provide natural explanations for individual predictions
- Automated methods for discovering optimal feature groups could extend the framework beyond manual semantic partitioning
Load-bearing premise
Partitioning the feature space into semantically coherent groups yields independent learners that capture complementary evidence which a meta-learner can aggregate more effectively than a single monolithic model on high-dimensional, heterogeneous credit data.
What would settle it
If an experiment trains a single model with the same total parameters or base learners as the sum of the group models and finds equivalent or better AUC-ROC, the advantage of group partitioning would be called into question.
Figures


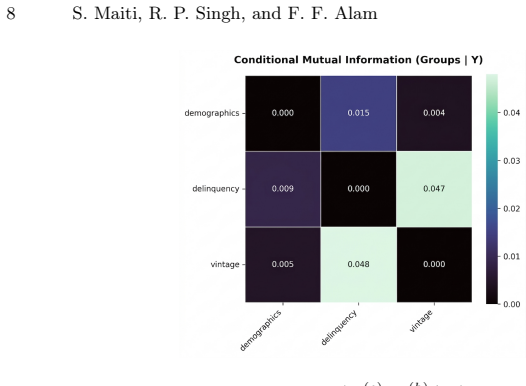
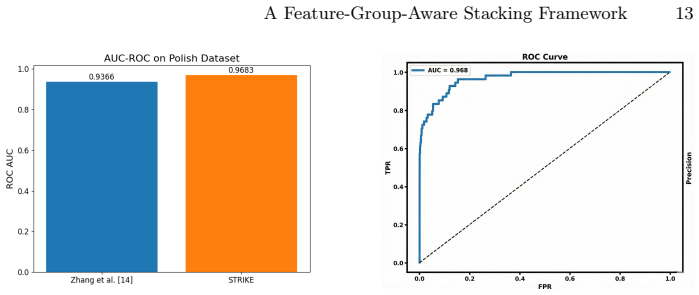
read the original abstract
Credit risk default prediction remains a cornerstone of risk management in the financial industry. The task involves estimating the likelihood that a borrower will fail to meet debt obligations, an objective critical for lending decisions, portfolio optimization, and regulatory compliance. Traditional machine learning models such as logistic regression and tree-based ensembles are widely adopted for their interpretability and strong empirical performance. However, modern credit datasets are high-dimensional, heterogeneous, and noisy, increasing overfitting risk in monolithic models and reducing robustness under distributional shift. We introduce STRIKE (Stacking via Targeted Representations of Isolated Knowledge Extractors), a feature-group-aware stacking framework for structured tabular credit risk data. Rather than training a single monolithic model on the complete dataset, STRIKE partitions the feature space into semantically coherent groups and trains independent learners within each group. This decomposition is motivated by an additive perspective on risk modeling, where distinct feature sources contribute complementary evidence that can be combined through a structured aggregation. The resulting group-specific predictions are integrated through a meta-learner that aggregates signals while maintaining robustness and modularity. We evaluate STRIKE on three real-world datasets spanning corporate bankruptcy and consumer lending scenarios. Across all settings, STRIKE consistently outperforms strong tree-based baselines and conventional stacking approaches in terms of AUC-ROC. Ablation studies confirm that performance gains stem from meaningful feature decomposition rather than increased model complexity. Our findings demonstrate that STRIKE is a stable, scalable, and interpretable framework for credit risk default prediction tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces STRIKE (Stacking via Targeted Representations of Isolated Knowledge Extractors), a feature-group-aware stacking framework for credit default prediction on tabular data. It partitions the feature space into semantically coherent groups, trains independent base learners on each group, and aggregates the resulting predictions with a meta-learner. The authors evaluate the method on three real-world datasets (corporate bankruptcy and consumer lending) and claim that STRIKE consistently outperforms strong tree-based baselines and conventional stacking approaches in AUC-ROC, with ablation studies attributing the gains to the feature decomposition rather than increased model complexity.
Significance. If the reported AUC-ROC gains and ablation results hold under proper statistical controls, the work would provide a practical, modular extension of stacking that exploits complementary signals from heterogeneous credit features. This could improve robustness on high-dimensional tabular data common in risk modeling. The additive perspective is a natural fit for credit data but overlaps with existing grouped-feature and ensemble techniques; the primary value would lie in the empirical demonstration on the three datasets rather than theoretical novelty.
major comments (3)
- [Abstract and §1] Abstract and §1: The central empirical claim ('consistently outperforms ... in terms of AUC-ROC' and 'performance gains stem from meaningful feature decomposition') is asserted without any reported AUC-ROC values, standard deviations, dataset sizes, number of features per group, or statistical significance tests. This absence makes the magnitude, reliability, and reproducibility of the claimed improvements impossible to assess from the manuscript text.
- [§4 (Experiments)] §4 (Experiments) and ablation description: The statement that ablations confirm gains arise from decomposition 'rather than increased model complexity' lacks controls for total parameter count, training time, or equivalent-capacity monolithic baselines. Without these, the attribution to feature grouping cannot be isolated from simple ensemble effects.
- [§3 (Methodology)] §3 (Methodology): The procedure for defining 'semantically coherent groups' is described only at a high level. No explicit algorithm, expert rules, or data-driven criterion is given, nor is sensitivity to group definition analyzed. This is load-bearing for the reproducibility of the reported outperformance.
minor comments (2)
- [Tables] The manuscript should include a table summarizing the three datasets (size, positive rate, feature count, train/test split) and a results table with AUC-ROC (and perhaps PR-AUC or Brier score) plus error bars or p-values against all baselines.
- [§2-3] Notation for the meta-learner and group-specific predictors is introduced but not formalized with equations; adding a concise mathematical description (e.g., in §2 or §3) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the manuscript's empirical reporting, experimental controls, and methodological transparency.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The central empirical claim ('consistently outperforms ... in terms of AUC-ROC' and 'performance gains stem from meaningful feature decomposition') is asserted without any reported AUC-ROC values, standard deviations, dataset sizes, number of features per group, or statistical significance tests. This absence makes the magnitude, reliability, and reproducibility of the claimed improvements impossible to assess from the manuscript text.
Authors: We agree that the abstract and introduction would benefit from explicit numerical support. In the revised manuscript we will insert a concise performance summary table (AUC-ROC means and standard deviations over 5-fold CV) together with dataset sizes, total feature counts, and per-group feature counts. We will also add paired statistical significance tests (e.g., Wilcoxon signed-rank) against the strongest baselines. These additions will make the magnitude and reliability of the reported gains directly verifiable. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments) and ablation description: The statement that ablations confirm gains arise from decomposition 'rather than increased model complexity' lacks controls for total parameter count, training time, or equivalent-capacity monolithic baselines. Without these, the attribution to feature grouping cannot be isolated from simple ensemble effects.
Authors: The referee correctly identifies a gap in our ablation design. While the current experiments compare STRIKE to monolithic trees and standard stacking, we did not report parameter counts or training times, nor did we include capacity-matched single-model baselines. We will add these controls in the revision: (i) a table of parameter counts and wall-clock training times for all methods, and (ii) additional monolithic baselines whose total capacity matches or exceeds that of STRIKE. These controls will allow readers to separate the contribution of feature grouping from mere increases in model capacity. revision: yes
-
Referee: [§3 (Methodology)] §3 (Methodology): The procedure for defining 'semantically coherent groups' is described only at a high level. No explicit algorithm, expert rules, or data-driven criterion is given, nor is sensitivity to group definition analyzed. This is load-bearing for the reproducibility of the reported outperformance.
Authors: We acknowledge that the current description of group construction is high-level. The groups were formed using domain expertise in credit-risk modeling (financial ratios, credit-history variables, behavioral features, etc.). In the revision we will expand Section 3 with an explicit listing of the grouping rules applied to each dataset, the exact features assigned to each group, and the rationale for each assignment. We will also add a sensitivity study that compares the original expert groupings against (a) random partitions of the same sizes and (b) k-means clustering on feature correlations, thereby quantifying robustness to alternative group definitions. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces STRIKE as an empirical stacking framework that partitions features into semantic groups, trains independent learners per group, and aggregates via a meta-learner. All central claims rest on AUC-ROC comparisons against baselines and ablation studies on three real-world datasets. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the described method; the approach is a standard additive construction whose performance gains are attributed to decomposition rather than any internal reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Expert Systems with Applications102, 213–234 (2018).https://doi.org/10
Alaka, H.A., Oyedele, L.O., Owolabi, H., Ajayi, S., Bilal, M., Akinade, O.O., Posh- dar, M.: Systematic literature review of credit scoring research in the last decade. Expert Systems with Applications102, 213–234 (2018).https://doi.org/10. 1016/j.eswa.2018.02.001
2018
-
[2]
Information Sciences503, 130–146 (2019).https://doi
Ali, B., Wei, Q., Liu, Y., Bie, R.: Group-based feature learning with sparsity for automatic credit scoring. Information Sciences503, 130–146 (2019).https://doi. org/10.1016/j.ins.2019.07.014
-
[3]
The journal of finance23(4), 589–609 (1968).https://doi.org/10
Altman,E.I.:Financialratios,discriminantanalysisandthepredictionofcorporate bankruptcy. The journal of finance23(4), 589–609 (1968).https://doi.org/10. 2307/2326758 16 S. Maiti, R. P. Singh, and F. F. Alam
1968
-
[4]
Bai, X., Feng, Y., Wu, Y., Wu, J.: A hierarchical learning framework for credit risk evaluation in peer-to-peer lending. Electronic Commerce Research and Appli- cations19, 1–10 (2016).https://doi.org/10.1016/j.elerap.2016.07.002
-
[5]
Basel Committee on Banking Supervision: International convergence of capital measurement and capital standards: A revised framework (comprehensive version) (2006),https://www.bis.org/publ/bcbs128.htm, accessed: 2025-05-05
2006
-
[6]
Basel Committee on Banking Supervision: Basel iii: A global regulatory framework for more resilient banks and banking systems (2011),https://www.bis.org/publ/ bcbs189.htm, accessed: 2025-05-05
2011
-
[7]
Breiman, L.: Random forests. Machine learning45, 5–32 (2001).https://doi. org/10.1023/A:1010933404324
-
[8]
ACM sigmod record29(2), 93–104 (2000).https://doi.org/10
Breunig, M.M., Kriegel, H.P., Ng, R.T., Sander, J.: Lof: Identifying density-based local outliers. ACM sigmod record29(2), 93–104 (2000).https://doi.org/10. 1145/335191.335388
-
[9]
Pattern Recognition Letters27(8), 861–874 (2006)
Fawcett, T.: An introduction to roc analysis. Pattern Recognition Letters27(8), 861–874 (2006)
2006
-
[10]
Financial Crisis Inquiry Commission: The financial crisis inquiry report (2011), https://www.govinfo.gov/features/financial-crisis-inquiry-report, accessed: 2025-05-05
2011
-
[11]
Friedman, J.H.: Greedy function approximation: A gradient boosting machine. In: Annals of statistics. vol. 29, pp. 1189–1232. Institute of Mathematical Statistics (2001).https://doi.org/10.1214/aos/1013203451
-
[12]
Advances in Neural Information Processing Systems35, 23272–23284 (2022)
Grinsztajn, L., Oyallon, E., Varoquaux, G.: Tree neural networks outperform deep learning on tabular data. Advances in Neural Information Processing Systems35, 23272–23284 (2022)
2022
-
[13]
Group, H.C.: Home credit default risk.https://www.kaggle.com/competitions/ home-credit-default-risk(2018)
2018
-
[14]
Com- putational Statistics & Data Analysis70, 152–168 (2014).https://doi.org/10
He, Z., Yu, W.: A statistical perspective on boosting for feature selection. Com- putational Statistics & Data Analysis70, 152–168 (2014).https://doi.org/10. 1016/j.csda.2013.09.004
2014
-
[15]
Artificial Intelligence Review43(3), 593–621 (2015).https://doi.org/10.1007/ s10462-013-9400-0
Kirkos, E.: Recent advances in credit risk prediction in the era of big data. Artificial Intelligence Review43(3), 593–621 (2015).https://doi.org/10.1007/ s10462-013-9400-0
2015
-
[16]
LendingClub: Lending club loan data.https://www.kaggle.com/datasets/ ethon0426/lending-club-20072020q1(2020)
2020
-
[17]
Topic Discovery for Short Texts Using Word Embeddings
Liu, F.T., Ting, K.M., Zhou, Z.H.: Isolation forest. 2008 Eighth IEEE International Conference on Data Mining pp. 413–422 (2008).https://doi.org/10.1109/ICDM. 2008.17
-
[18]
Jour- nalofaccountingresearchpp.109–131(1980).https://doi.org/10.2307/2490395
Ohlson, J.A.: Financial ratios and the probabilistic prediction of bankruptcy. Jour- nalofaccountingresearchpp.109–131(1980).https://doi.org/10.2307/2490395
-
[19]
Knowledge-Based Systems266, 110414 (2023)
Qian, H., Ma, P., Gao, S., Song, Y.: Soft reordering one-dimensional convolutional neural network for credit scoring. Knowledge-Based Systems266, 110414 (2023). https://doi.org/10.1016/j.knosys.2023.110414
-
[20]
ics.uci.edu/ml/datasets/Polish+companies+bankruptcy+data(2016)
Repository, U.I.M.L.: Polish companies bankruptcy data set.https://archive. ics.uci.edu/ml/datasets/Polish+companies+bankruptcy+data(2016)
2016
-
[21]
Journal of Information System Exploration and Research2(12 2023)
Rofik, R., Aulia, R., Musaadah, K., Ardyani, S., Hakim, A.: Optimization of credit scoring model using stacking ensemble learning and oversampling tech- niques. Journal of Information System Exploration and Research2(12 2023). https://doi.org/10.52465/joiser.v2i1.203 A Feature-Group-Aware Stacking Framework 17
-
[22]
Mathematics and Computers in Simulation162, 1–14 (2019).https://doi.org/10.1016/j.matcom.2019.01
Wei, J., Chen, D., Zhou, X., Zhao, H., Hu, X.: An adaptive ensemble approach for outlier detection and classification in credit scoring. Mathematics and Computers in Simulation162, 1–14 (2019).https://doi.org/10.1016/j.matcom.2019.01. 004
-
[23]
Wolpert, D.H.: Stacked generalization. In: Neural Networks. vol. 5, pp. 241–259. Elsevier (1992).https://doi.org/10.1016/S0893-6080(05)80023-1
-
[24]
Expert Systems with Applications165, 113872 (2021).https://doi.org/ 10.1016/j.eswa.2020.113872
Zhang, W., Yang, D., Zhang, S., Ablanedo-Rosas, J.H., Wu, X., Lou, Y.: A novel multi-stage ensemble model with enhanced outlier adaptation for credit scor- ing. Expert Systems with Applications165, 113872 (2021).https://doi.org/ 10.1016/j.eswa.2020.113872
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.