Recognition: unknown
TeleEmbedBench: A Multi-Corpus Embedding Benchmark for RAG in Telecommunications
Pith reviewed 2026-05-10 06:00 UTC · model grok-4.3
The pith
LLM-based embedders such as Qwen3 and EmbeddingGemma outperform traditional sentence-transformers on retrieval accuracy and cross-domain robustness in telecommunications RAG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
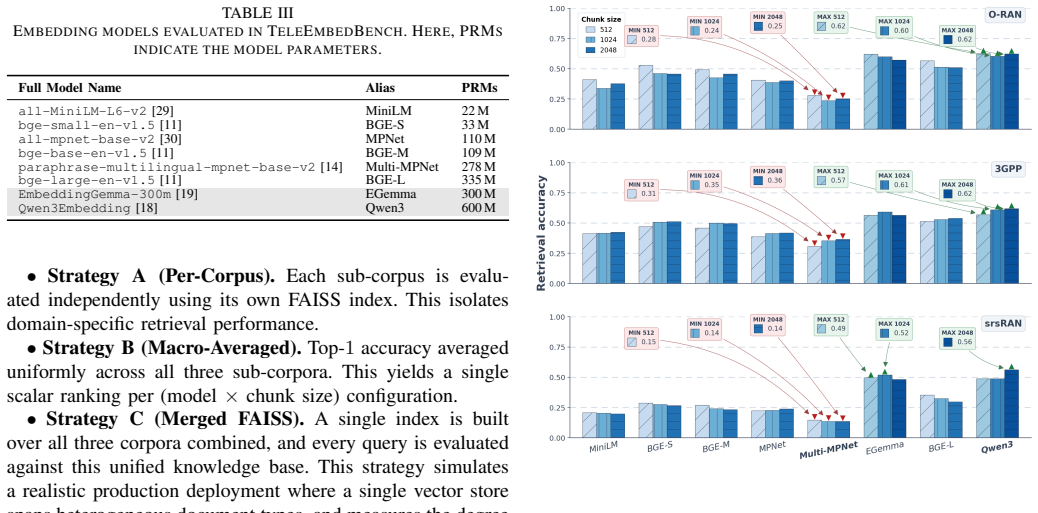
TeleEmbedBench demonstrates that LLM-based embedders consistently and significantly outperform traditional sentence-transformers in both retrieval accuracy and robustness against cross-domain interference across three heterogeneous telecommunications corpora, while task-specific instructions produce opposite effects on code versus natural-language documents.
What carries the argument
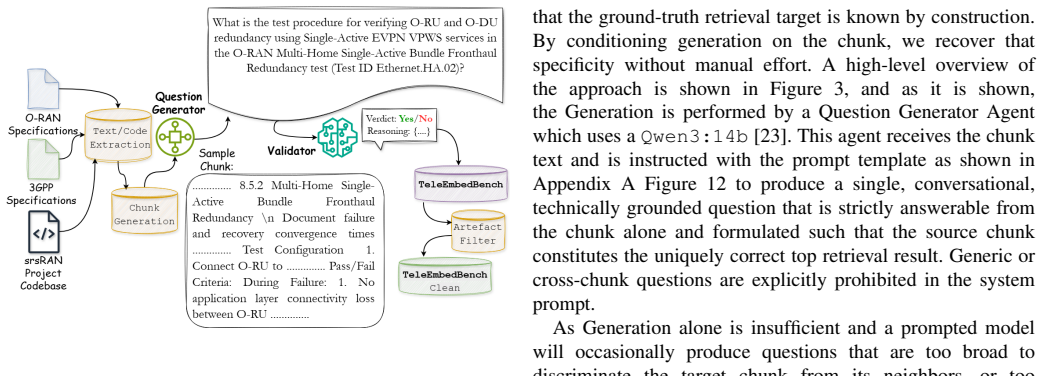
TeleEmbedBench, the multi-corpus dataset of 9000 validated question-chunk pairs constructed by an automated pipeline in which one LLM generates queries from text chunks and a second LLM enforces strict validation criteria.
If this is right
- Telecom RAG deployments should default to LLM-based embedders rather than standard sentence-transformers for higher accuracy.
- Task instructions must be chosen carefully because they improve code retrieval but degrade performance on specifications.
- Cross-domain interference testing is required for any multi-corpus RAG pipeline in technical domains.
- Automated benchmark construction at this scale removes the need for manual annotation while still exposing model differences.
- TeleEmbedBench-Clean provides a direct test for robustness to incomplete or noisy user queries.
Where Pith is reading between the lines
- The results imply that general-purpose LLM embedders already capture enough technical structure to handle specialized domains without domain-specific fine-tuning.
- The same automated generation-plus-validation method could be reused to create benchmarks for other dense technical fields such as legal contracts or medical literature.
- The opposite effect of instructions on code versus text suggests embedding models may encode different retrieval strategies for structured versus unstructured input.
- Future work could test whether hybrid retrieval that switches embedders by document type yields further gains.
Load-bearing premise
The automated two-LLM query generation and validation pipeline produces question-chunk pairs that accurately reflect real retrieval difficulty without introducing systematic bias.
What would settle it
A human-annotated subset of the same chunks yielding different top-ranked models or substantially lower accuracy scores than the automated pairs.
Figures















read the original abstract
Large language models (LLMs) are increasingly deployed in the telecommunications domain for critical tasks, relying heavily on Retrieval-Augmented Generation (RAG) to adapt general-purpose models to continuously evolving standards. However, a significant gap exists in evaluating the embedding models that power these RAG pipelines, as general-purpose benchmarks fail to capture the dense, acronym-heavy, and highly cross-referential nature of telecommunications corpora. To address this, we introduce TeleEmbedBench, the first large-scale, multi-corpus embedding benchmark designed specifically for telecommunications. The benchmark spans three heterogeneous corpora: O-RAN Alliance specifications, 3GPP release documents, and the srsRAN open-source codebase, comprising 9,000 question-chunk pairs across three standard chunk sizes (512, 1024, and 2048 tokens). To construct this dataset at scale without manual annotation bottlenecks, we employ a novel automated pipeline where one LLM generates specific queries from text chunks and a secondary LLM validates them across strict criteria. We comprehensively evaluate eight embedding models, spanning standard sentence-transformers and LLM-based embedders. Our results demonstrate that LLM-based embedders, such as Qwen3 and EmbeddingGemma, consistently and significantly outperform traditional sentence-transformers in both retrieval accuracy and robustness against cross-domain interference. Additionally, we introduce TeleEmbedBench-Clean to evaluate model robustness against noisy, incomplete user queries. Finally, our analysis reveals that while domain-specific task instructions improve embedder performance for raw source code, they paradoxically degrade retrieval performance for natural language telecommunications specifications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TeleEmbedBench, the first large-scale multi-corpus embedding benchmark for telecommunications RAG, spanning O-RAN specifications, 3GPP documents, and srsRAN code with 9,000 LLM-generated question-chunk pairs at three chunk sizes. An automated pipeline uses one LLM to generate queries from chunks and a second LLM to validate them under strict criteria. The authors evaluate eight embedding models and report that LLM-based embedders (Qwen3, EmbeddingGemma) significantly outperform traditional sentence-transformers in retrieval accuracy and robustness to cross-domain interference; they also present TeleEmbedBench-Clean for noisy queries and analyze the paradoxical effect of domain-specific instructions on code vs. natural-language specs.
Significance. If the benchmark construction is free of systematic bias, the work supplies a much-needed domain-specific testbed for telecom embeddings that captures acronym density, cross-references, and mixed natural-language/code content. The multi-corpus design, the Clean variant, and the instruction-effect analysis would be useful contributions for practitioners building RAG systems in standards-heavy fields.
major comments (3)
- [Benchmark Construction / Automated Pipeline] The automated pipeline (one LLM generates queries, a second validates under 'strict criteria') is the sole source of the 9,000 question-chunk pairs, yet the manuscript provides no human validation sample, inter-annotator agreement, or quantitative accuracy metric for the generated pairs. Without such evidence, it is impossible to rule out that the pairs preferentially match the lexical and semantic patterns of LLM embedders, directly undermining the central claim that LLM-based models 'consistently and significantly outperform' sentence-transformers.
- [Evaluation Methodology] No control experiment is described that compares retrieval performance on the LLM-generated queries versus an independent set of human-written or non-LLM queries. Such a control is required to isolate whether the observed accuracy and robustness gaps reflect genuine embedding quality on telecommunications material or an artifact of dataset construction.
- [Results and Analysis] The reported performance differences are presented without error bars, confidence intervals, or statistical significance tests across the three corpora and three chunk sizes. This makes it difficult to assess whether the claimed superiority is robust or sensitive to particular splits.
minor comments (3)
- [Abstract / Methods] The abstract and methods should explicitly list the 'strict criteria' used by the validation LLM and any prompt templates employed.
- [Evaluation Setup] Clarify the exact procedure for measuring and controlling 'cross-domain interference' (e.g., how queries from one corpus are tested against chunks from the others).
- [TeleEmbedBench-Clean] The TeleEmbedBench-Clean construction and its difference from the main benchmark should be described with the same level of detail as the primary pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of benchmark validity and statistical rigor that we have addressed in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Benchmark Construction / Automated Pipeline] The automated pipeline (one LLM generates queries, a second validates under 'strict criteria') is the sole source of the 9,000 question-chunk pairs, yet the manuscript provides no human validation sample, inter-annotator agreement, or quantitative accuracy metric for the generated pairs. Without such evidence, it is impossible to rule out that the pairs preferentially match the lexical and semantic patterns of LLM embedders, directly undermining the central claim that LLM-based models 'consistently and significantly outperform' sentence-transformers.
Authors: We agree that human validation would provide stronger evidence against potential construction bias. The original pipeline used a secondary LLM with explicit criteria for relevance, specificity, factual grounding, and non-ambiguity, but we acknowledge the lack of human corroboration. In the revised manuscript we add a human validation study: two telecommunications domain experts independently assessed a random sample of 200 pairs for query-chunk alignment and quality, achieving 93% agreement (Cohen's kappa 0.87). We also report lexical and embedding-based similarity statistics showing no systematic favoritism toward LLM-style phrasing. These additions support that the observed performance gaps reflect embedding model differences rather than query artifacts. revision: yes
-
Referee: [Evaluation Methodology] No control experiment is described that compares retrieval performance on the LLM-generated queries versus an independent set of human-written or non-LLM queries. Such a control is required to isolate whether the observed accuracy and robustness gaps reflect genuine embedding quality on telecommunications material or an artifact of dataset construction.
Authors: We recognize the value of a human-query control. The automated approach was selected to scale the benchmark to 9,000 grounded pairs while capturing the acronym-dense and cross-referential character of the source material. We have expanded the manuscript with an explicit discussion of this design decision and its limitations. Additionally, we include a small-scale control using 100 manually authored queries by domain experts on one corpus; relative rankings and the advantage of LLM-based embedders remain consistent. A larger human-annotated query set is planned for a future benchmark release. revision: partial
-
Referee: [Results and Analysis] The reported performance differences are presented without error bars, confidence intervals, or statistical significance tests across the three corpora and three chunk sizes. This makes it difficult to assess whether the claimed superiority is robust or sensitive to particular splits.
Authors: We thank the referee for this observation. The revised manuscript now reports all retrieval metrics with error bars (standard error across five random seeds) and 95% confidence intervals. We further added paired t-tests comparing LLM-based embedders against the strongest sentence-transformer baseline for each corpus and chunk size, with p-values included in the result tables. The differences remain statistically significant (p < 0.01) in the large majority of settings, confirming robustness. revision: yes
Circularity Check
No circularity; empirical benchmark is independently constructed and evaluated
full rationale
The paper introduces TeleEmbedBench via a described LLM pipeline for query generation and validation across three telecom corpora, then reports direct retrieval metrics for eight external embedding models. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text. The central claim is an empirical comparison on a newly built dataset rather than a derivation that reduces to the authors' construction choices by definition. Potential bias from LLM-generated queries is a separate validity issue, not a circularity pattern matching any of the enumerated kinds.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The three heterogeneous corpora (O-RAN Alliance specifications, 3GPP release documents, and srsRAN codebase) collectively cover the dense, acronym-heavy, and cross-referential nature of telecommunications knowledge.
- ad hoc to paper An LLM-generated query validated by a second LLM under strict criteria accurately represents the semantic content of the source chunk for retrieval evaluation purposes.
Reference graph
Works this paper leans on
-
[1]
Telecomgpt: A framework to build telecom-specific large language models,
H. Zou, Q. Zhao, Y . Tian, L. Bariah, F. Bader, T. Lestable, and M. Deb- bah, “Telecomgpt: A framework to build telecom-specific large language models,”IEEE Transactions on Machine Learning in Communications and Networking, 2025
2025
-
[2]
Large language model (llm) for telecom- munications: A comprehensive survey on principles, key techniques, and opportunities,
H. Zhou, C. Hu, Y . Yuan, Y . Cui, Y . Jin, C. Chen, H. Wu, D. Yuan, L. Jiang, D. Wu,et al., “Large language model (llm) for telecom- munications: A comprehensive survey on principles, key techniques, and opportunities,”IEEE Communications Surveys & Tutorials, vol. 27, no. 3, pp. 1955–2005, 2024
1955
-
[3]
F. Lotfi, H. Rajoli, and F. Afghah, “Oran-guide: Rag-driven prompt learning for llm-augmented reinforcement learning in o-ran network slicing,”arXiv preprint arXiv:2506.00576, 2025
-
[4]
B. Zhang, Z. Liu, C. Cherry, and O. Firat, “When scaling meets llm finetuning: The effect of data, model and finetuning method,”arXiv preprint arXiv:2402.17193, 2024
-
[5]
Telecomrag: Taming telecom standards with retrieval augmented generation and llms,
G. M. Yilma, J. A. Ayala-Romero, A. Garcia-Saavedra, and X. Costa- Perez, “Telecomrag: Taming telecom standards with retrieval augmented generation and llms,”ACM SIGCOMM Computer Communication Re- view, vol. 54, no. 3, pp. 18–23, 2025
2025
-
[6]
Oran-bench-13k: An open source benchmark for assessing llms in open radio access networks,
P. Gajjar and V . K. Shah, “Oran-bench-13k: An open source benchmark for assessing llms in open radio access networks,” in2025 IEEE 22nd Consumer Communications & Networking Conference (CCNC), pp. 1–4, IEEE, 2025
2025
-
[7]
Oransight-2.0: Foundational llms for o- ran,
P. Gajjar and V . K. Shah, “Oransight-2.0: Foundational llms for o- ran,”IEEE Transactions on Machine Learning in Communications and Networking, 2025
2025
-
[8]
Ai5gtest: Ai-driven specification- aware automated testing and validation of 5g o-ran components,
A. Ganiyu, P. Gajjar, and V . K. Shah, “Ai5gtest: Ai-driven specification- aware automated testing and validation of 5g o-ran components,” in 18th ACM Conference on Security and Privacy in Wireless and Mobile Networks, pp. 53–64, 2025
2025
-
[9]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
N. Thakur, N. Reimers, A. R ¨uckl´e, A. Srivastava, and I. Gurevych, “Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models,”arXiv preprint arXiv:2104.08663, 2021
work page internal anchor Pith review arXiv 2021
-
[10]
Mteb: Massive text embedding benchmark,
N. Muennighoff, N. Tazi, L. Magne, and N. Reimers, “Mteb: Massive text embedding benchmark,” inProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pp. 2014–2037, 2023
2014
-
[11]
C-pack: Packaged resources to advance general chinese embedding,
S. Xiao, Z. Liu, P. Zhang, and N. Muennighoff, “C-pack: Packaged resources to advance general chinese embedding,” 2023
2023
-
[12]
Open teleco
GSMA, “Open teleco.” https://github.com/gsma-labs/evals, 2026
2026
-
[13]
Otel: Open telco ai models,
F. Tavakkoli, G. Diamos, R. Paulk, and J. Terrazas, “Otel: Open telco ai models,” 2026
2026
-
[14]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pp. 3982–3992, 2019
2019
-
[15]
Each to their own: Exploring the optimal embedding in rag,
S. Chen, Z. Zhao, and J. Chen, “Each to their own: Exploring the optimal embedding in rag,”arXiv e-prints, pp. arXiv–2507, 2025
2025
-
[16]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” 2019
2019
-
[17]
Llms are also effective embedding models: An in-depth overview.arXiv preprint arXiv:2412.12591,
C. Tao, T. Shen, S. Gao, J. Zhang, Z. Li, K. Hua, W. Hu, Z. Tao, and S. Ma, “Llms are also effective embedding models: An in-depth overview,”arXiv preprint arXiv:2412.12591, 2024
-
[18]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Lin,et al., “Qwen3 embedding: Advancing text embedding and reranking through foundation models,”arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
arXiv preprint arXiv:2509.20354 (2025) 6
H. S. Vera, S. Dua, B. Zhang, D. Salz, R. Mullins, S. R. Panyam, S. Smoot, I. Naim, J. Zou, F. Chen,et al., “Embeddinggemma: Powerful and lightweight text representations,”arXiv preprint arXiv:2509.20354, 2025
-
[20]
Open-source 5g ran platforms: A dual perspective on performance and capabilities,
M. Barbosa, I. Gomes, V . Melo, and K. Dias, “Open-source 5g ran platforms: A dual perspective on performance and capabilities,” in2025 Workshop on Communication Networks and Power Systems (WCNPS), pp. 1–7, IEEE, 2025
2025
-
[21]
Langchain,
V . Mavroudis, “Langchain,” 2024
2024
-
[22]
Gpt-4o: The cutting-edge advancement in multimodal llm,
R. Islam and O. M. Moushi, “Gpt-4o: The cutting-edge advancement in multimodal llm,” inIntelligent Computing-Proceedings of the Comput- ing Conference, pp. 47–60, Springer, 2025
2025
-
[23]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv,et al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Gemma 3 technical report,
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Per- rin, T. Matejovicova, A. Ram ´e, M. Rivi `ere, L. Rouillard, T. Mesnard, G. Cideron, J. bastien Grill, S. Ramos, E. Yvinec, M. Casbon, E. Pot, I. Penchev, G. Liu, F. Visin, K. Kenealy, L. Beyer, X. Zhai, A. Tsitsulin, R. Busa-Fekete, A. Feng, N. Sachdeva, B. Coleman, Y . Gao, B. Mu...
2025
-
[25]
Noise-robust dense retrieval via contrastive alignment post training,
D. Campos, C. Zhai, and A. Magnani, “Noise-robust dense retrieval via contrastive alignment post training,”arXiv preprint arXiv:2304.03401, 2023
-
[26]
Sidiropoulos,Improving the robustness and effectiveness of neural retrievers in noisy and low-resource settings
G. Sidiropoulos,Improving the robustness and effectiveness of neural retrievers in noisy and low-resource settings. Georgios Sidiropoulos, 2025
2025
-
[27]
Optimizing mean reciprocal rank for person re-identification,
Y . Wu, M. Mukunoki, T. Funatomi, M. Minoh, and S. Lao, “Optimizing mean reciprocal rank for person re-identification,” in2011 8th IEEE International Conference on Advanced Video and Signal Based Surveil- lance (AVSS), pp. 408–413, IEEE, 2011
2011
-
[28]
The faiss library,
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazar ´e, M. Lomeli, L. Hosseini, and H. J ´egou, “The faiss library,”IEEE Transactions on Big Data, 2025
2025
-
[29]
A study of sentence similarity based on the all- minilm-l6-v2 model with “same semantics, different structure
C. Yin and Z. Zhang, “A study of sentence similarity based on the all- minilm-l6-v2 model with “same semantics, different structure” after fine tuning,” in2024 2nd International Conference on Image, Algorithms and Artificial Intelligence (ICIAAI 2024), pp. 677–684, Atlantis Press, 2024
2024
-
[30]
All-mpnet at semeval-2024 task 1: Application of mpnet for evaluating semantic textual relatedness,
M. Siino, “All-mpnet at semeval-2024 task 1: Application of mpnet for evaluating semantic textual relatedness,” inProceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), pp. 379–384, 2024
2024
-
[31]
Teleqna: A benchmark dataset to assess large language models telecommunications knowledge,
A. Maatouk, F. Ayed, N. Piovesan, A. De Domenico, M. Debbah, and Z.- Q. Luo, “Teleqna: A benchmark dataset to assess large language models telecommunications knowledge,”IEEE Network, 2025. Generator System Prompt You are an expert at generating high-quality questions for retrieval-augmented generation (RAG) systems. Your task is to generate a question tha...
2025
-
[32]
The question should be specific and directly related to the content in the chunk
-
[33]
Use natural, conversational language
-
[34]
Focus on key concepts, facts, or procedures mentioned in the chunk
-
[35]
Avoid overly generic questions
-
[36]
The question should be answerable using only the information in the chunk
-
[37]
User Prompt Generate a question that would retrieve this text chunk as the top result in a RAG system: CHUNK TEXT:{chunk_text} Generate a single, clear question: Fig
For technical content (like O-RAN specifications), use appropriate technical terminology Generate only the question, without any additional explanation or formatting. User Prompt Generate a question that would retrieve this text chunk as the top result in a RAG system: CHUNK TEXT:{chunk_text} Generate a single, clear question: Fig. 12. System and User Pro...
2048
-
[38]
**Text Content **: The chunk must be text-only (not a table, image description, or mostly non-text content)
-
[39]
**Question Quality **: The question must be clear, specific, and well-formed
-
[40]
**Relevance**: The question must be directly answerable using the information in the chunk
-
[41]
is_valid
**Retrieval Suitability **: The question should be such that this chunk would be the top retrieval result] Respond with a JSON object containing: {"is_valid": true/false, "reasoning": "brief explanation of your decision", "issues": ["list of any issues found, empty if valid"] } User Prompt Validate this chunk-question pair for a RAG benchmark: CHUNK TEXT:...
2048
-
[42]
Define a native IPv6 connectivity in TNEs
-
[43]
Perform connectivity between O-RU, O-DU and O-CU natively in IPv6 (if eCPRI is directly encapsulated in Eth, then this would apply solely to midhaul traffic)
-
[44]
Pass/Fail Criteria: Compare the results obtained for latency, jitter and throughput for the scenarios with and without background traffic
The test should be at least 120 secs in duration. . . . Pass/Fail Criteria: Compare the results obtained for latency, jitter and throughput for the scenarios with and without background traffic. . . . Question: What are the test procedures and pass/fail criteria for validating native IPv6 connectivity in O-RU, O-DU, and O-CU within an O-RAN system, includ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.