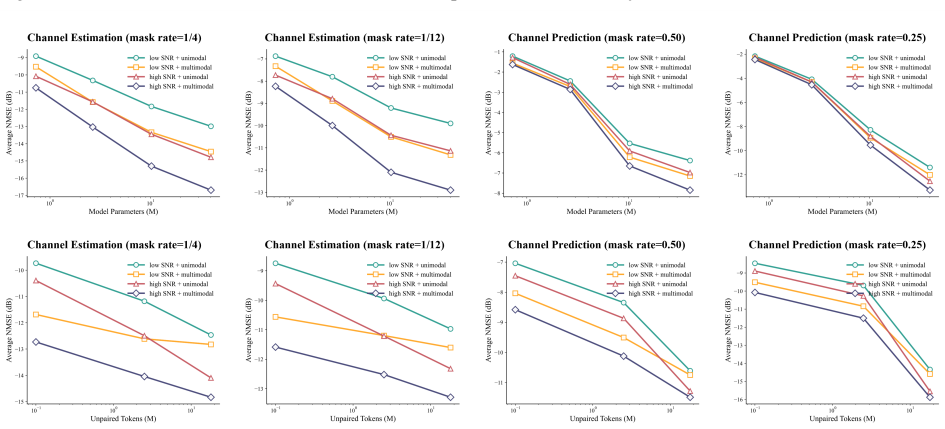
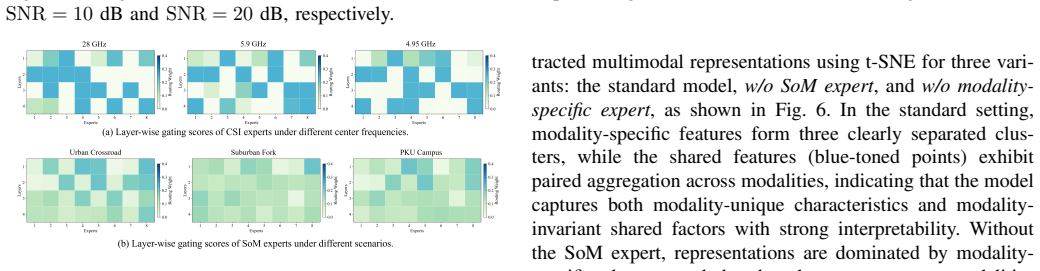
Recognition: unknown
WiFo-MiSAC: A Wireless Foundation Model for Multimodal Sensing and Communication Integration via Synesthesia of Machines (SoM)
Pith reviewed 2026-05-10 04:01 UTC · model grok-4.3
The pith
WiFo-MiSAC unifies wireless sensing and communication by tokenizing signals into a shared space for self-supervised learning with disentangled experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that a task-agnostic foundation model can integrate multimodal sensing and communication through signal tokenization into a unified space, followed by pre-training that combines masked reconstruction with contrastive alignment. The SS-DMoE architecture decouples shared and specific representations to allow beneficial interaction without cross-modal interference. This yields state-of-the-art performance on downstream tasks including beam prediction and channel estimation, robust few-shot adaptation, and the capacity to incorporate new modalities without difficulty.
What carries the argument
The shared-specific disentangled mixture-of-experts (SS-DMoE) architecture, which decouples modality-shared and modality-specific representations from tokenized heterogeneous signals.
If this is right
- State-of-the-art performance is achieved on beam prediction and channel estimation tasks.
- The model adapts effectively to new tasks using only a small number of examples.
- New modalities integrate seamlessly into the existing model.
- The approach provides a scalable backbone for integrated sensing and communication systems.
Where Pith is reading between the lines
- Joint processing of sensing and communication may allow wireless systems to operate more efficiently by sharing learned features.
- The tokenization method could be tested in other multimodal environments, such as combining radar with visual data.
- Few-shot capabilities suggest potential use in rapidly changing wireless conditions like mobile networks.
Load-bearing premise
That converting different wireless signals into tokens in a single space and applying the SS-DMoE architecture will separate shared and specific features without causing interference between modalities.
What would settle it
If the model shows higher error rates than specialized models on beam prediction when modalities are combined in ways not seen during pre-training, this would challenge the claim of improved generalization without cross-modal interference.
Figures




read the original abstract
Current learning-based wireless methods struggle with generalization due to the fragmented processing of communication and sensing data. WiFo-MiSAC addresses this as a task-agnostic foundation model that tokenizes heterogeneous signals into a unified space for self-supervised pre-training. A shared-specific disentangled mixture-of-experts (SS-DMoE) architecture is employed to decouple modality-shared and modality-specific representations, facilitating interaction without cross-modal interference. By combining masked reconstruction with contrastive alignment, the model achieves state-of-the-art performance across downstream tasks, including beam prediction and channel estimation. Experimental results demonstrate robust few-shot adaptation and seamless integration of new modalities, positioning WiFo-MiSAC as a scalable backbone for future integrated sensing and communication systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WiFo-MiSAC, a task-agnostic foundation model for multimodal sensing and communication integration via Synesthesia of Machines. It tokenizes heterogeneous wireless signals (RF and sensing) into a unified space for self-supervised pre-training, employs a shared-specific disentangled mixture-of-experts (SS-DMoE) architecture to separate modality-shared and modality-specific representations, and combines masked reconstruction with contrastive alignment. The model claims state-of-the-art performance on downstream tasks including beam prediction and channel estimation, along with robust few-shot adaptation and seamless integration of new modalities.
Significance. If the experimental claims are substantiated, this work could advance integrated sensing and communication systems by offering a scalable, unified backbone that addresses generalization limitations of fragmented task-specific models. The self-supervised pre-training strategy and emphasis on disentangled multimodal representations represent a potentially valuable direction for handling heterogeneous wireless data with reduced reliance on labeled datasets.
major comments (2)
- [Abstract] Abstract: The abstract asserts state-of-the-art results on beam prediction and channel estimation but supplies no experimental details, baselines, error bars, or data-exclusion rules. Without these elements the numerical support for the central performance claims cannot be evaluated.
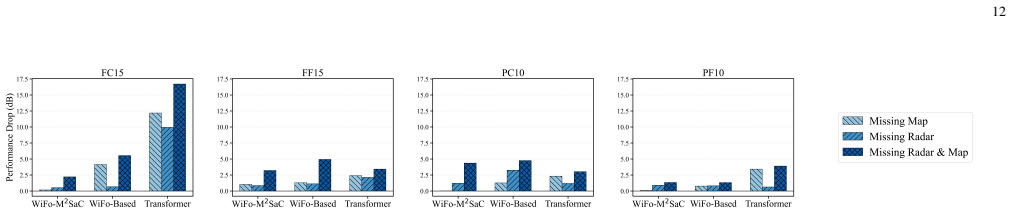
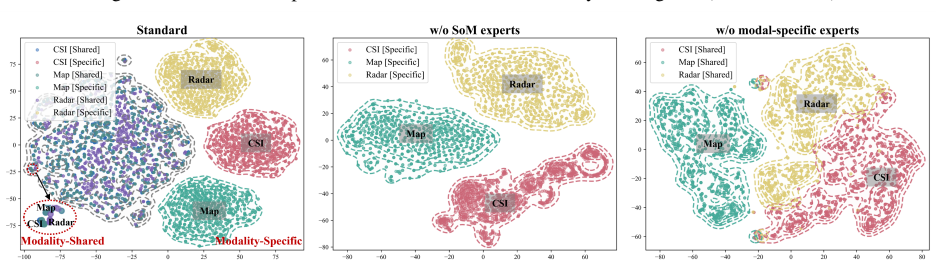
- [SS-DMoE Architecture] SS-DMoE Architecture: The claim that the SS-DMoE successfully decouples modality-shared and modality-specific representations without cross-modal interference is load-bearing for the generalization and few-shot adaptation results. Given that wireless modalities share physical-layer statistics such as multipath and Doppler, the manuscript requires explicit ablations or an interference metric to demonstrate that the mixture-of-experts routing and contrastive alignment prevent leakage and deliver gains over fragmented baselines.
minor comments (1)
- The abstract would benefit from a concise statement of the number of modalities and dataset sizes used in the pre-training and downstream evaluations to contextualize the reported robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment in detail below and indicate the revisions made to strengthen the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts state-of-the-art results on beam prediction and channel estimation but supplies no experimental details, baselines, error bars, or data-exclusion rules. Without these elements the numerical support for the central performance claims cannot be evaluated.
Authors: We agree that the abstract is currently high-level and does not provide the requested experimental specifics, which limits immediate evaluation of the claims. In the revised manuscript we expand the abstract to include the primary baselines (task-specific models and prior multimodal approaches), the reported performance gains with associated error bars from the main experiments, and a brief reference to the data processing protocol detailed in Section 4.1. The full experimental setup, including any exclusion criteria, remains in the body of the paper. revision: yes
-
Referee: [SS-DMoE Architecture] SS-DMoE Architecture: The claim that the SS-DMoE successfully decouples modality-shared and modality-specific representations without cross-modal interference is load-bearing for the generalization and few-shot adaptation results. Given that wireless modalities share physical-layer statistics such as multipath and Doppler, the manuscript requires explicit ablations or an interference metric to demonstrate that the mixture-of-experts routing and contrastive alignment prevent leakage and deliver gains over fragmented baselines.
Authors: The referee correctly notes that the decoupling property is central to our generalization and few-shot results and that shared physical-layer effects could induce leakage. While the manuscript already reports ablation studies comparing SS-DMoE against non-disentangled MoE variants and shows corresponding gains in downstream tasks, we acknowledge that a direct interference metric is not yet present. In the revision we add (i) an explicit ablation isolating the effect of the shared-specific routing and (ii) a quantitative interference metric (normalized mutual information between shared and modality-specific expert activations) together with routing visualizations. These additions directly quantify leakage under shared statistics such as multipath and Doppler and confirm the contribution of the contrastive alignment term. revision: yes
Circularity Check
No circularity: empirical self-supervised model with held-out evaluation
full rationale
The paper presents a foundation model trained via masked reconstruction and contrastive alignment on tokenized multimodal wireless signals, then evaluated on downstream tasks such as beam prediction and channel estimation. No equations, first-principles derivations, or predictions appear that reduce by construction to fitted inputs or self-citations. Performance claims rest on experimental results with few-shot adaptation and new-modality integration, which are falsifiable on held-out data. The SS-DMoE architecture and SoM framing are design choices justified by training objectives rather than tautological definitions or load-bearing self-citations that collapse the central result.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network weights and hyperparameters
axioms (1)
- domain assumption Heterogeneous wireless signals from different modalities can be tokenized into a shared latent space without prohibitive information loss.
invented entities (2)
-
SS-DMoE architecture
no independent evidence
-
WiFo-MiSAC model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Integrated Sensing and Com- munications (ISAC) for Vehicular Communication Networks (VCN),
X. Cheng, D. Duan, S. Gao, and L. Yang, “Integrated Sensing and Com- munications (ISAC) for Vehicular Communication Networks (VCN),” IEEE Internet Things J., vol. 9, no. 23, pp. 23 441–23 451, Jul. 2022
2022
-
[2]
Integrated Sensing and Communications: Toward Dual- Functional Wireless Networks for 6G and Beyond,
F. Liuet al., “Integrated Sensing and Communications: Toward Dual- Functional Wireless Networks for 6G and Beyond,”IEEE J. Sel. Areas Commun., vol. 40, no. 6, pp. 1728–1767, Mar. 2022
2022
-
[3]
Integrated Sensing and Communication for Low Altitude Economy: Opportunities and Challenges,
Y . Jianget al., “Integrated Sensing and Communication for Low Altitude Economy: Opportunities and Challenges,”IEEE Commun. Mag., vol. 64, no. 12, pp. 72–78, Apr. 2025
2025
-
[4]
Intelligent Multi-Modal Sensing-Communication In- tegration: Synesthesia of Machines,
X. Chenget al., “Intelligent Multi-Modal Sensing-Communication In- tegration: Synesthesia of Machines,”IEEE Commun. Surv. Tutorials, vol. 26, no. 1, pp. 258–301, Firstquarter 2024
2024
-
[5]
Integrated sensing and communications toward proactive beamforming in mmWave V2I via multi-modal feature fusion (MMFF),
H. Zhang, S. Gao, X. Cheng, and L. Yang, “Integrated sensing and communications toward proactive beamforming in mmWave V2I via multi-modal feature fusion (MMFF),”IEEE Transactions on Wireless Communications, vol. 23, no. 11, pp. 15 721–15 735, Nov. 2024
2024
-
[6]
Deep Multimodal Learning: Merging Sensory Data for Massive MIMO Channel Predic- tion,
Y . Yang, F. Gao, C. Xing, J. An, and A. Alkhateeb, “Deep Multimodal Learning: Merging Sensory Data for Massive MIMO Channel Predic- tion,”IEEE J. Sel. Areas Commun., vol. 39, no. 7, pp. 1885–1898, Jul. 2020
2020
-
[7]
Sensing Aided Channel Estimation in Wideband Millimeter- Wave MIMO Systems,
R. Mundlamuri, R. Gangula, C. K. Thomas, F. Kaltenberger, and W. Saad, “Sensing Aided Channel Estimation in Wideband Millimeter- Wave MIMO Systems,” inIEEE Int. Conf. Commun. Workshops (ICC Workshops). Rome, Italy: IEEE, May 2023, pp. 1404–1409
2023
-
[8]
Radar Aided Proactive Blockage Prediction in Real-World Millimeter Wave Systems,
U. Demirhan and A. Alkhateeb, “Radar Aided Proactive Blockage Prediction in Real-World Millimeter Wave Systems,” inIEEE Int. Conf. Commun. (ICC). Seoul, South Korea: IEEE, May 2022, pp. 4547–4552
2022
-
[9]
LIDAR Data for Deep Learning-Based mmWave Beam-Selection,
A. Klautau, N. Gonz ´alez-Prelcic, and R. W. Heath, “LIDAR Data for Deep Learning-Based mmWave Beam-Selection,”IEEE Wireless Commun. Lett., vol. 8, no. 3, pp. 909–912, Feb. 2019
2019
-
[10]
Millimeter Wave Base Stations with Cameras: Vision-Aided Beam and Blockage Prediction,
M. Alrabeiah, A. Hredzak, and A. Alkhateeb, “Millimeter Wave Base Stations with Cameras: Vision-Aided Beam and Blockage Prediction,” inIEEE Proc. IEEE Veh. Technol. Conf. (VTC2020-Spring). Antwerp, Belgium: IEEE, May 2020, pp. 1–5
2020
-
[11]
Towards Real-World 6G Drone Communication: Position and Camera Aided Beam Prediction,
G. Charanet al., “Towards Real-World 6G Drone Communication: Position and Camera Aided Beam Prediction,” inIEEE Global Commun. Conf.(GLOBECOM). Rio de Janeiro, Brazil: IEEE, Dec. 2022, pp. 2951–2956
2022
-
[12]
SAM-Med3D: A Vision Foundation Model for General- Purpose Segmentation on V olumetric Medical Images,
H. Wanget al., “SAM-Med3D: A Vision Foundation Model for General- Purpose Segmentation on V olumetric Medical Images,”IEEE Trans. Neural Networks Learn. Syst., vol. 36, pp. 17 599–17 612, Oct. 2025
2025
-
[13]
DMAE-EEG: A Pretraining Framework for EEG Spatiotemporal Representation Learning,
Y . Zhanget al., “DMAE-EEG: A Pretraining Framework for EEG Spatiotemporal Representation Learning,”IEEE Trans. Neural Networks Learn. Syst., vol. 36, pp. 17 664–17 678, Oct. 2025
2025
-
[14]
Foundation Model Em- powered Synesthesia of Machines (SoM): AI-Native Intelligent Multi- Modal Sensing-Communication Integration,
X. Cheng, B. Liu, X. Liu, E. Liu, and Z. Huang, “Foundation Model Em- powered Synesthesia of Machines (SoM): AI-Native Intelligent Multi- Modal Sensing-Communication Integration,”IEEE Trans. Network Sci. Eng., vol. 13, pp. 762–782, 2026
2026
-
[15]
Large Wireless Foundation Models: Stronger over Bigger,
X. Cheng, B. Liu, X. Liu, and X. Cai, “Large Wireless Foundation Models: Stronger over Bigger,”arXiv preprint arXiv:2601.10963, 2026
-
[16]
Large wireless model (LWM): A foundation model for wireless channels,
S. Alikhani, G. Charan, and A. Alkhateeb, “Large Wireless Model (LWM): A Foundation Model for Wireless Channels,”arXiv preprint arXiv:2411.08872, 2024
-
[17]
WiFo: Wireless Foundation Model for Channel Prediction,
B. Liu, S. Gao, X. Liu, X. Cheng, and L. Yang, “WiFo: Wireless Foundation Model for Channel Prediction,”Sci. China Inf. Sci., vol. 68, no. 8, p. 162302, May 2025
2025
-
[18]
WiFo-CF: Wireless foundation model for CSI feedback,
X. Liu, S. Gao, B. Liu, X. Cheng, and L. Yang, “WiFo-CF: Wireless foundation model for CSI feedback,”arXiv preprint arXiv:2508.04068, 2025
-
[19]
WiFo-2: a generalist foundation model unifies heterogeneous wireless system design
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “Foundation Model for Intelligent Wireless Communications,”arXiv preprint arXiv:2511.22222, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
IQFM–A Wireless Foundation Model for I/Q Streams in AI-Native 6G,
O. Mashaal and H. Abou-Zeid, “IQFM–A Wireless Foundation Model for I/Q Streams in AI-Native 6G,”IEEE Open J. Commun. Soc., vol. 7, pp. 1426–1441, Feb. 2026
2026
-
[21]
H. Zhang, S. Gao, and X. Cheng, “WiFo-M 2: Plug-and-Play Multi- Modal Sensing via Foundation Model to Empower Wireless Communi- cations,”arXiv preprint arXiv:2601.09179, 2026
-
[22]
M. Farzanullah, H. Zhang, A. B. Sediq, A. Afana, and M. Erol-Kantarci, “Wireless Multimodal Foundation Model (WMFM): Integrating Vision and Communication Modalities for 6G ISAC Systems,”arXiv preprint arXiv:2512.23897, 2025
-
[23]
FRCL-MNER: A Finer Grained Rank-Based Contrastive Learning Framework for Multimodal NER,
T. Yanet al., “FRCL-MNER: A Finer Grained Rank-Based Contrastive Learning Framework for Multimodal NER,”IEEE Trans. Neural Net- works Learn. Syst., vol. 36, pp. 10 779–10 793, Jun. 2025
2025
-
[24]
A Multi-Modal Foundational Model for Wireless Communication and Sensing,
V . Yazdnian and Y . Ghasempour, “A Multi-Modal Foundational Model for Wireless Communication and Sensing,”arXiv preprint arXiv:2602.04016, 2026
-
[25]
Radar Aided 6G Beam Prediction: Deep Learning Algorithms and Real-World Demonstration,
U. Demirhan and A. Alkhateeb, “Radar Aided 6G Beam Prediction: Deep Learning Algorithms and Real-World Demonstration,” inIEEE Wireless Commun. Netw. Conf. (WCNC). Austin, USA: IEEE, Apr. 2022, pp. 2655–2660
2022
-
[26]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,
A. Dosovitskiyet al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” inInt. Conf. Learn. Representations (ICLR), Vienna, Austria, May 2021, pp. 1–22
2021
-
[27]
Root mean square layer normalization,
B. Zhang and R. Sennrich, “Root mean square layer normalization,” Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 32, Dec. 2019
2019
-
[28]
S. Baiet al., “Qwen3-vl Technical Report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhinet al., “Gshard: Scaling giant models with conditional computation and automatic sharding,”arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review arXiv 2006
-
[30]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity,”J. Mach. Learn. Res., vol. 23, no. 120, pp. 1–39, Jan. 2022
2022
-
[31]
M 3SC: A Generic Dataset for Mixed Multi-Modal (MMM) Sensing and Communication Integration,
X. Chenget al., “M 3SC: A Generic Dataset for Mixed Multi-Modal (MMM) Sensing and Communication Integration,”China Commun., vol. 20, no. 11, pp. 13–29, Nov. 2023
2023
-
[32]
SynthSoM: A Synthetic Intelligent Multi-Modal Sensing-Communication Dataset for Synesthesia of Machines (SoM),
X. Chenget al., “SynthSoM: A Synthetic Intelligent Multi-Modal Sensing-Communication Dataset for Synesthesia of Machines (SoM),” Sci. Data, vol. 12, no. 819, May 2025
2025
-
[33]
DeepSense 6G: A Large-Scale Real-World Multi- Modal Sensing and Communication Dataset,
A. Alkhateebet al., “DeepSense 6G: A Large-Scale Real-World Multi- Modal Sensing and Communication Dataset,”IEEE Commun. Mag., vol. 61, no. 9, pp. 122–128, Sep. 2023
2023
-
[34]
LLM4CP: Adapting Large Language Models for Channel Prediction,
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “LLM4CP: Adapting Large Language Models for Channel Prediction,”J. Commun. Inf. Networks, vol. 9, no. 2, pp. 113–125, Jun. 2024
2024
-
[35]
LLM4WM: Adapting LLM for Wireless Multi-Tasking,
X. Liu, S. Gao, B. Liu, X. Cheng, and L. Yang, “LLM4WM: Adapting LLM for Wireless Multi-Tasking,”IEEE Trans. Mach. Learn. Commun. Networking, vol. 3, pp. 835–847, Jul. 2025
2025
-
[36]
Accurate Channel Prediction Based on Transformer: Making Mobility Negligible,
H. Jiang, M. Cui, D. W. K. Ng, and L. Dai, “Accurate Channel Prediction Based on Transformer: Making Mobility Negligible,”IEEE J. Sel. Areas Commun., vol. 40, no. 9, pp. 2717–2732, July 2022
2022
-
[37]
Channelformer: Attention Based Neural Solution for Wireless Channel Estimation and Effective Online Train- ing,
D. Luan and J. S. Thompson, “Channelformer: Attention Based Neural Solution for Wireless Channel Estimation and Effective Online Train- ing,”IEEE Trans. Wireless Commun., vol. 22, no. 10, pp. 6562–6577, Oct. 2023
2023
-
[38]
Deep Learning for mmWave Beam and Blockage Prediction Using Sub-6 GHz Channels,
M. Alrabeiah and A. Alkhateeb, “Deep Learning for mmWave Beam and Blockage Prediction Using Sub-6 GHz Channels,”IEEE Trans. Commun., vol. 68, no. 9, pp. 5504–5518, Sep. 2020
2020
-
[39]
Attention Aided CSI Wireless Lo- calization,
A. Salihu, S. Schwarz, and M. Rupp, “Attention Aided CSI Wireless Lo- calization,” inIEEE Workshop Signal Process. Adv. Wireless Commun. (SPAWC), Oulu, Finland, Jul. 2022, pp. 1–5
2022
-
[40]
Multi-Modal Variable-Rate CSI Reconstruction for FDD Massive MIMO Systems,
Y . Nam and J. Choi, “Multi-Modal Variable-Rate CSI Reconstruction for FDD Massive MIMO Systems,”arXiv preprint arXiv:2501.11926, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.