Recognition: unknown
CAARL: In-Context Learning for Interpretable Co-Evolving Time Series Forecasting
Pith reviewed 2026-05-10 04:38 UTC · model grok-4.3
The pith
CAARL forecasts co-evolving time series interpretably by turning dependency graphs into narratives for LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAARL decomposes time series into autoregressive segments, constructs a temporal dependency graph, and serializes this graph into a narrative to allow processing by an LLM. This design yields a chain-of-thought-like reasoning path where intermediate steps capture contextual dynamics and guide forecasts in a transparent manner, enhancing interpretability while maintaining accuracy on real-world datasets.
What carries the argument
The temporal dependency graph serialized into a narrative text that the LLM uses for in-context learning and chain-of-thought reasoning.
If this is right
- Forecasts become linked to explicit reasoning traces that decode contextual dynamics.
- The method handles intricate dependencies and nonstationary dynamics through structured intermediate steps.
- It delivers accuracy competitive with state-of-the-art forecasting approaches.
- Predictions gain transparency by connecting directly to the serialized narrative of temporal relations.
Where Pith is reading between the lines
- The narrative format may allow users to inspect or edit specific reasoning steps before accepting a forecast.
- This graph-to-text step could be adapted to other sequential tasks such as anomaly detection where explanation of context matters.
- Incremental updates to the dependency graph might support online forecasting on streaming data without full re-serialization.
Load-bearing premise
That serializing the temporal dependency graph into narrative text allows the LLM to accurately decode and reason about intricate dependencies and nonstationary dynamics without losing critical information or introducing artifacts.
What would settle it
A controlled experiment on synthetic co-evolving series with known ground-truth dependencies where CAARL's forecast accuracy falls below a direct graph-input baseline or where the generated reasoning traces fail to recover the true dependency structure.
Figures

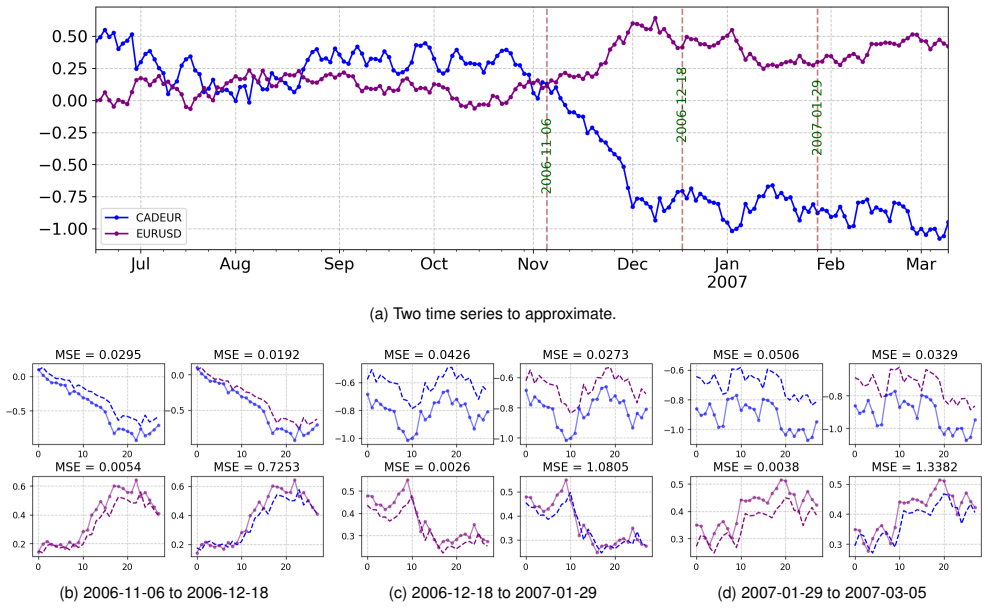


read the original abstract
In this paper we investigate forecasting coevolving time series that feature intricate dependencies and nonstationary dynamics by using an LLM Large Language Models approach We propose a novel modeling approach named ContextAware ARLLM CAARL that provides an interpretable framework to decode the contextual dynamics influencing changes in coevolving series CAARL decomposes time series into autoregressive segments constructs a temporal dependency graph and serializes this graph into a narrative to allow processing by LLM This design yields a chainofthoughtlike reasoning path where intermediate steps capture contextual dynamics and guide forecasts in a transparent manner By linking prediction to explicit reasoning traces CAARL enhances interpretability while maintaining accuracy Experiments on realworld datasets validate its effectiveness positioning CAARL as a competitive and interpretable alternative to stateoftheart forecasting methods
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CAARL (Context-Aware ARLLM), a framework for interpretable forecasting of co-evolving time series exhibiting intricate dependencies and nonstationary dynamics. It decomposes the series into autoregressive segments, constructs a temporal dependency graph capturing relationships among series, serializes the graph into narrative text, and feeds this to an LLM to produce forecasts via chain-of-thought-style reasoning that links predictions to explicit contextual traces. The abstract claims this yields both enhanced interpretability and competitive accuracy, validated on real-world datasets.
Significance. If the graph-to-narrative serialization preserves sufficient quantitative structure (edge weights, lags, higher-order interactions) for the LLM to decode nonstationary co-evolving dynamics without material loss, the work could offer a useful bridge between graph-based time-series modeling and LLM reasoning, providing transparent intermediate steps that standard black-box forecasters lack. The design explicitly aims for falsifiable reasoning traces, which is a strength if demonstrated.
major comments (2)
- [Abstract] Abstract: the statement that 'experiments on real-world datasets validate its effectiveness' and position CAARL as 'competitive' provides no information on datasets, baselines, metrics, error analysis, or controls for nonstationarity. This absence makes it impossible to evaluate whether the data actually supports the central claims of accuracy and interpretability.
- [Abstract] Abstract (and Method description): the serialization of the temporal dependency graph into narrative text is described only at a high level, with no mechanism given for encoding numerical relations such as edge weights, temporal lags, or dependency strengths. If the encoding is coarse natural-language description, it risks introducing quantization artifacts or omitting higher-order interactions that matrix- or kernel-based models capture directly; this directly bears on whether the LLM can accurately reason about nonstationary dynamics.
minor comments (1)
- [Abstract] Abstract contains multiple typographical and spacing issues (e.g., 'chainofthoughtlike', 'realworld', 'coevolving', 'ARLLM' without consistent hyphenation or capitalization) that impair readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the presentation of our claims and methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'experiments on real-world datasets validate its effectiveness' and position CAARL as 'competitive' provides no information on datasets, baselines, metrics, error analysis, or controls for nonstationarity. This absence makes it impossible to evaluate whether the data actually supports the central claims of accuracy and interpretability.
Authors: We agree that the abstract is too high-level and does not provide sufficient concrete details to support the claims of effectiveness and competitiveness. The full experimental results, including datasets, baselines, metrics, and handling of nonstationarity via autoregressive decomposition, appear in Section 4, but the abstract should better preview them. In the revised version we will expand the abstract to explicitly reference the real-world datasets (e.g., traffic, energy consumption, and financial series), the compared baselines (ARIMA, VAR, GNN-based forecasters, and other LLM approaches), the metrics (MAE, RMSE, MAPE), and the controls for nonstationarity. This revision will make the abstract self-contained while remaining concise. revision: yes
-
Referee: [Abstract] Abstract (and Method description): the serialization of the temporal dependency graph into narrative text is described only at a high level, with no mechanism given for encoding numerical relations such as edge weights, temporal lags, or dependency strengths. If the encoding is coarse natural-language description, it risks introducing quantization artifacts or omitting higher-order interactions that matrix- or kernel-based models capture directly; this directly bears on whether the LLM can accurately reason about nonstationary dynamics.
Authors: We acknowledge that the current description of the graph-to-narrative serialization is high-level in both the abstract and the method overview, without an explicit encoding template for numerical attributes. This is a valid concern regarding potential loss of quantitative fidelity. In the revised manuscript we will add a detailed description and illustrative example in Section 3.2 showing the precise serialization rules: nodes are rendered as textual autoregressive segment summaries, while edges are rendered as sentences that directly embed lag values, edge weights, and dependency strengths (e.g., “Series X depends on Series Y with lag 3 and strength 0.82”). We will also discuss how this textual encoding is intended to retain the information needed for chain-of-thought reasoning about nonstationary co-evolution, and we will note any limitations relative to matrix-based models. revision: yes
Circularity Check
No circularity in proposed pipeline
full rationale
The abstract and available description present CAARL as a novel pipeline that explicitly decomposes series into autoregressive segments, builds a temporal dependency graph, serializes it into narrative text, and feeds the result to an LLM for chain-of-thought-style forecasting. No equations, fitted parameters, or self-referential definitions appear in the provided text. The central claim rests on the design of these new components rather than any reduction of a prediction to its own inputs or to a self-citation chain. This is the most common honest outcome for a methods paper that introduces an explicit multi-stage architecture without claiming a first-principles derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Entropic dynamic time warping kernels for co-evolving financial time series analysis,
L. Bai, L. Cui, Z. Zhang, L. Xu, Y . Wang, and E. R. Hancock, “Entropic dynamic time warping kernels for co-evolving financial time series analysis,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 4, pp. 1808–1822, 2020
2020
-
[2]
Neucast: Seasonal neural forecast of power grid time series.,
P. Chen, S. Liu, C. Shi, B. Hooi, B. Wang, and X. Cheng, “Neucast: Seasonal neural forecast of power grid time series.,” inIJCAI, pp. 3315– 3321, 2018
2018
-
[3]
Attention based spatial- temporal graph convolutional networks for traffic flow forecasting,
S. Guo, Y . Lin, N. Feng, C. Song, and H. Wan, “Attention based spatial- temporal graph convolutional networks for traffic flow forecasting,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, pp. 922–929, 2019
2019
-
[4]
Lsgcn: Long short- term traffic prediction with graph convolutional networks.,
R. Huang, C. Huang, Y . Liu, G. Dai, and W. Kong, “Lsgcn: Long short- term traffic prediction with graph convolutional networks.,” inIJCAI, vol. 7, pp. 2355–2361, 2020
2020
-
[5]
High-dimensional multivariate forecasting with low-rank gaussian cop- ula processes,
D. Salinas, M. Bohlke-Schneider, L. Callot, R. Medico, and J. Gasthaus, “High-dimensional multivariate forecasting with low-rank gaussian cop- ula processes,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[6]
Coupling macro- sector-micro financial indicators for learning stock representations with less uncertainty,
G. Wang, L. Cao, H. Zhao, Q. Liu, and E. Chen, “Coupling macro- sector-micro financial indicators for learning stock representations with less uncertainty,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 4418–4426, 2021
2021
-
[7]
M. A. V osoughi and A. Wismuller, “Large-scale kernelized granger causality to infer topology of directed graphs with applications to brain networks,”arXiv preprint arXiv:2011.08261, 2020
-
[8]
Schizophrenia detection technique using multivariate iterative filtering and multichannel eeg signals,
K. Das and R. B. Pachori, “Schizophrenia detection technique using multivariate iterative filtering and multichannel eeg signals,”Biomedical Signal Processing and Control, vol. 67, p. 102525, 2021
2021
-
[9]
Think globally, act locally: A deep neural network approach to high-dimensional time series forecasting,
R. Sen, H.-F. Yu, and I. S. Dhillon, “Think globally, act locally: A deep neural network approach to high-dimensional time series forecasting,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[10]
Shape and time distortion loss for training deep time series forecasting models,
V . Le Guen and N. Thome, “Shape and time distortion loss for training deep time series forecasting models,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[11]
Explainable ai: A review of machine learning interpretability methods,
P. Linardatos, V . Papastefanopoulos, and S. Kotsiantis, “Explainable ai: A review of machine learning interpretability methods,”Entropy, vol. 23, no. 1, p. 18, 2020
2020
-
[12]
arXiv preprint arXiv:2310.01728 , year=
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y . Zhang, X. Shi, P.-Y . Chen, Y . Liang, Y .-F. Li, S. Pan,et al., “Time-llm: Time series fore- casting by reprogramming large language models,”arXiv preprint arXiv:2310.01728, 2023
-
[13]
C. Chang, W.-C. Peng, and T.-F. Chen, “Llm4ts: Two-stage fine- tuning for time-series forecasting with pre-trained llms,”arXiv preprint arXiv:2308.08469, 2023
-
[14]
Con- necting the dots: Multivariate time series forecasting with graph neural networks,
Z. Wu, S. Pan, G. Long, J. Jiang, X. Chang, and C. Zhang, “Con- necting the dots: Multivariate time series forecasting with graph neural networks,” inProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pp. 753–763, 2020
2020
-
[15]
Multivariate time series forecasting with dynamic graph neural odes,
M. Jin, Y . Zheng, Y .-F. Li, S. Chen, B. Yang, and S. Pan, “Multivariate time series forecasting with dynamic graph neural odes,”IEEE Trans- actions on Knowledge and Data Engineering, 2022
2022
-
[16]
Time series forecasting using ensemble learning methods for emergency prevention in hydroelectric power plants with dam,
S. F. Stefenon, M. H. D. M. Ribeiro, A. Nied, K.-C. Yow, V . C. Mariani, L. dos Santos Coelho, and L. O. Seman, “Time series forecasting using ensemble learning methods for emergency prevention in hydroelectric power plants with dam,”Electric Power Systems Research, vol. 202, p. 107584, 2022
2022
-
[17]
Bootstrap aggregating and random forest,
T.-H. Lee, A. Ullah, and R. Wang, “Bootstrap aggregating and random forest,”Macroeconomic forecasting in the era of big data: Theory and practice, pp. 389–429, 2020
2020
-
[18]
Extreme gradient boosting model based on improved jaya optimizer applied to forecasting energy consumption in residential buildings,
J. Sauer, V . C. Mariani, L. dos Santos Coelho, M. H. D. M. Ribeiro, and M. Rampazzo, “Extreme gradient boosting model based on improved jaya optimizer applied to forecasting energy consumption in residential buildings,”Evolving Systems, pp. 1–12, 2022
2022
-
[19]
Rethinking decomposition for time series forecasting: Learning from temporal pattern,
D. Ge, B. Liu, Y . Cheng, and Z. Zhu, “Rethinking decomposition for time series forecasting: Learning from temporal pattern,”Available at SSRN 5104377, 2025
2025
-
[20]
Graph deep learning for time series forecasting,
A. Cini, I. Marisca, D. Zambon, and C. Alippi, “Graph deep learning for time series forecasting,” 2023
2023
-
[21]
Everything is connected: Graph neural networks,
P. Veli ˇckovi´c, “Everything is connected: Graph neural networks,”Cur- rent Opinion in Structural Biology, vol. 79, p. 102538, 2023
2023
-
[22]
A gentle introduction to deep learning for graphs,
D. Bacciu, F. Errica, A. Micheli, and M. Podda, “A gentle introduction to deep learning for graphs,”Neural Networks, vol. 129, pp. 203–221, 2020
2020
-
[23]
Scalable causal graph learning through a deep neural network,
C. Xu, H. Huang, and S. Yoo, “Scalable causal graph learning through a deep neural network,” inProceedings of the 28th ACM international conference on information and knowledge management, pp. 1853–1862, 2019
2019
-
[24]
Fouriergnn: Rethinking multivariate time series forecast- ing from a pure graph perspective,
K. Yi, Q. Zhang, W. Fan, H. He, L. Hu, P. Wang, N. An, L. Cao, and Z. Niu, “Fouriergnn: Rethinking multivariate time series forecast- ing from a pure graph perspective,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[25]
Multivariate time-series forecasting with temporal polynomial graph neural networks,
Y . Liu, Q. Liu, J.-W. Zhang, H. Feng, Z. Wang, Z. Zhou, and W. Chen, “Multivariate time-series forecasting with temporal polynomial graph neural networks,”Advances in neural information processing systems, vol. 35, pp. 19414–19426, 2022
2022
-
[26]
Neural granger causality,
A. Tank, I. Covert, N. Foti, A. Shojaie, and E. B. Fox, “Neural granger causality,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 8, pp. 4267–4279, 2021
2021
-
[27]
Survey and evaluation of causal discovery methods for time series,
C. K. Assaad, E. Devijver, and E. Gaussier, “Survey and evaluation of causal discovery methods for time series,”Journal of Artificial Intelligence Research, vol. 73, pp. 767–819, 2022
2022
-
[28]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[29]
Large language models for time series: A survey,
X. Zhang, R. R. Chowdhury, R. K. Gupta, and J. Shang, “Large language models for time series: A survey,” 2024
2024
-
[30]
Can graph learning improve planning in llm-based agents?,
X. Wu, Y . Shen, C. Shan, K. Song, S. Wang, B. Zhang, J. Feng, H. Cheng, W. Chen, Y . Xiong,et al., “Can graph learning improve planning in llm-based agents?,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[31]
Position: What can large language models tell us about time series analysis,
M. Jin, Y . Zhang, W. Chen, K. Zhang, Y . Liang, B. Yang, J. Wang, S. Pan, and Q. Wen, “Position: What can large language models tell us about time series analysis,” inForty-first International Conference on Machine Learning, 2024
2024
-
[32]
Llm-abba: Understanding time series via symbolic approximation,
E. Carson, X. Chen, and C. Kang, “Llm-abba: Understanding time series via symbolic approximation,” 2024
2024
-
[33]
Promptcast: A new prompt-based learning paradigm for time series forecasting,
H. Xue and F. D. Salim, “Promptcast: A new prompt-based learning paradigm for time series forecasting,”IEEE Transactions on Knowledge and Data Engineering, 2023
2023
-
[34]
Causalbench: A comprehensive benchmark for causal learning capability of large language models,
Y . Zhou, X. Wu, B. Huang, J. Wu, L. Feng, and K. C. Tan, “Causalbench: A comprehensive benchmark for causal learning capability of large language models,”arXiv preprint arXiv:2404.06349, 2024
-
[35]
Unitime: A language-empowered unified model for cross-domain time series forecasting,
X. Liu, J. Hu, Y . Li, S. Diao, Y . Liang, B. Hooi, and R. Zimmermann, “Unitime: A language-empowered unified model for cross-domain time series forecasting,” inProceedings of the ACM on Web Conference 2024, pp. 4095–4106, 2024
2024
-
[36]
One fits all: Power general time series analysis by pretrained lm,
T. Zhou, P. Niu, L. Sun, R. Jin,et al., “One fits all: Power general time series analysis by pretrained lm,”Advances in neural information processing systems, vol. 36, pp. 43322–43355, 2023
2023
-
[37]
Chattime: A unified multimodal time series foundation model bridging numerical and textual data,
C. Wang, Q. Qi, J. Wang, H. Sun, Z. Zhuang, J. Wu, L. Zhang, and J. Liao, “Chattime: A unified multimodal time series foundation model bridging numerical and textual data,”arXiv preprint arXiv:2412.11376, 2024
-
[38]
S. Jaitly, T. Shah, A. Shugani, and R. S. Grewal, “Towards better serialization of tabular data for few-shot classification,”arXiv preprint arXiv:2312.12464, 2023
-
[39]
Tabllm: Few-shot classification of tabular data with large language models,
S. Hegselmann, A. Buendia, H. Lang, M. Agrawal, X. Jiang, and D. Sontag, “Tabllm: Few-shot classification of tabular data with large language models,” inInternational Conference on Artificial Intelligence and Statistics, pp. 5549–5581, PMLR, 2023
2023
-
[40]
A comprehensive capability analysis of gpt-3 and gpt- 3.5 series models,
J. Ye, X. Chen, N. Xu, C. Zu, Z. Shao, S. Liu, Y . Cui, Z. Zhou, C. Gong, Y . Shen,et al., “A comprehensive capability analysis of gpt-3 and gpt- 3.5 series models,”arXiv preprint arXiv:2303.10420, 2023
-
[41]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat,et al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Evaluating text quality of gpt engine davinci-003 and gpt engine davinci generation using bleu score,
Y . Heryanto and A. Triayudi, “Evaluating text quality of gpt engine davinci-003 and gpt engine davinci generation using bleu score,”SAGA: Journal of Technology and Information System, vol. 1, no. 4, pp. 121– 129, 2023
2023
-
[43]
Structured sequence modeling with graph convolutional recurrent networks,
Y . Seo and al, “Structured sequence modeling with graph convolutional recurrent networks,” inICONIP, pp. 362–373, Springer, 2018
2018
-
[44]
Y . Li and al, “Diffusion convolutional recurrent neural network: Data- driven traffic forecasting,”arXiv preprint arXiv:1707.01926, 2017
-
[45]
T-gcn: A temporal graph convolutional network for traffic prediction,
L. Zhao and al, “T-gcn: A temporal graph convolutional network for traffic prediction,”IEEE TITS, vol. 21, no. 9, pp. 3848–3858, 2019
2019
-
[46]
Temporal fusion trans- formers for interpretable multi-horizon time series forecasting,
B. Lim, S. O. Arik, N. Loeff, and T. Pfister, “Temporal fusion trans- formers for interpretable multi-horizon time series forecasting,” 2020
2020
-
[47]
Are transformers effective for time series forecasting?,
A. Zeng, M. Chen, L. Zhang, and Q. Xu, “Are transformers effective for time series forecasting?,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, pp. 11121–11128, 2023
2023
-
[48]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,”arXiv preprint arXiv:2211.14730, 2022
work page internal anchor Pith review arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.