Recognition: unknown
Scale-free adaptive planning for deterministic dynamics & discounted rewards
Pith reviewed 2026-05-10 04:35 UTC · model grok-4.3
The pith
Platypoos is a scale-free planning algorithm that adapts to unknown reward scales and smoothness while achieving sample complexity bounds that hold simultaneously across discount factors without prior knowledge of them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose Platypoos, a simple scale-free planning algorithm that adapts to the unknown scale and smoothness of the reward function. We provide a sample complexity analysis for Platypoos that improves upon prior work and holds simultaneously over a broad range of discount factors and reward scales, without the algorithm knowing them. We also establish a matching lower bound showing our analysis is optimal up to constants.
What carries the argument
Platypoos, the scale-free planning algorithm that adapts to the unknown scale and smoothness of the reward function by adjusting its behavior without explicit knowledge of those parameters.
Load-bearing premise
The environment has deterministic dynamics with stochastic rewards under discounting, and the optimal value function is unknown with possibly unbounded rewards.
What would settle it
Construct a simple deterministic MDP with stochastic rewards, run Platypoos for varying discount factors and reward scales chosen independently of the algorithm, and measure whether the observed sample count required to reach a given accuracy matches the claimed upper bound and is strictly lower than that of prior non-adaptive planners on the same instance.
Figures



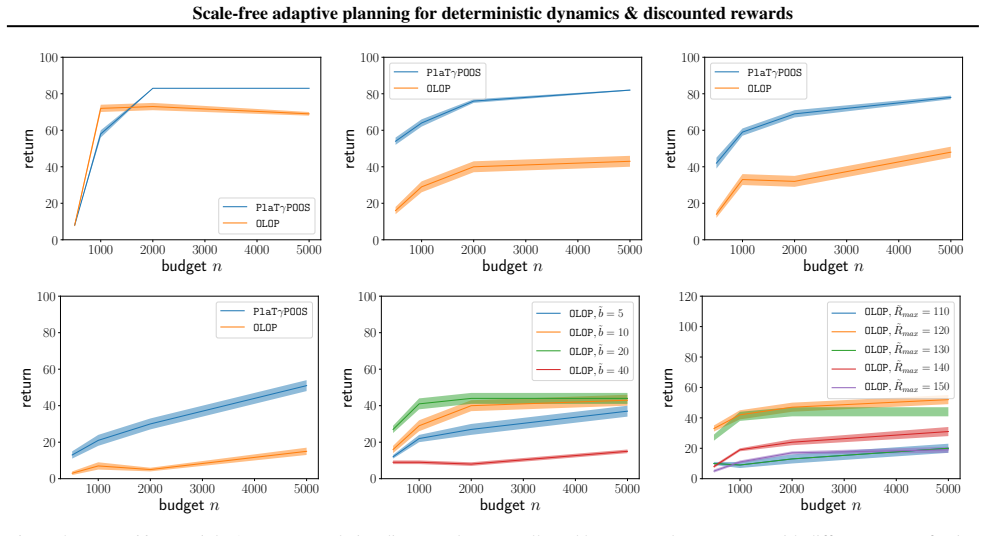

read the original abstract
We address the problem of planning in an environment with deterministic dynamics and stochastic rewards with discounted returns. The optimal value function is not known, nor are the rewards bounded. We propose Platypoos, a simple scale-free planning algorithm that adapts to the unknown scale and smoothness of the reward function. We provide a sample complexity analysis for Platypoos that improves upon prior work and holds simultaneously over a broad range of discount factors and reward scales, without the algorithm knowing them. We also establish a matching lower bound showing our analysis is optimal up to constants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Platypoos, a scale-free planning algorithm for MDPs with deterministic dynamics, stochastic (possibly unbounded) rewards, and discounted returns where the optimal value function is unknown. The algorithm adapts to the unknown scale and smoothness of the reward function without prior knowledge of these quantities or the discount factor. The central claims are an improved sample-complexity analysis that holds simultaneously over broad ranges of discount factors and reward scales, plus a matching lower bound establishing optimality up to constants.
Significance. If the analysis and lower bound hold, the result would be significant for adaptive planning under uncertainty: it removes the common requirement to know or tune for reward magnitude and discount factor while still delivering uniform guarantees. The deterministic-dynamics assumption enables exact forward simulation, which underpins the scale-free adaptation. The matching lower bound is a strength that would make the tightness claim falsifiable and useful for the literature.
minor comments (3)
- [Abstract] The abstract states that the analysis 'improves upon prior work' but does not name the specific prior results or quantify the improvement (e.g., dependence on smoothness or range of γ). Adding one sentence of comparison would help readers place the contribution.
- [Problem statement / Section 2] Definitions of 'scale' and 'smoothness' of the reward function appear only after the algorithm is introduced; moving a concise definition to the problem statement section would improve readability.
- [Lower bound section] The lower-bound construction should explicitly state the class of reward distributions and the range of γ over which the Ω(·) bound holds, to confirm it matches the upper bound's uniformity claim.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on Platypoos and for recommending minor revision. We appreciate the recognition that the simultaneous sample-complexity bounds across discount factors and reward scales, together with the matching lower bound, would be a useful contribution if the analysis holds. Since the report lists no specific major comments or requests for clarification, we have no points to address point-by-point at this stage. We are happy to incorporate any minor suggestions that may appear in the full review or during the revision process.
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on a proposed algorithm (Platypoos) whose sample-complexity bounds are derived from standard MDP assumptions under deterministic dynamics, stochastic rewards, and discounted returns. The analysis is stated to hold simultaneously over unknown discount factors and reward scales without the algorithm knowing them, and is supported by a matching lower bound. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the derivation remains independent of quantities defined from the same data or prior author-specific uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L., Gabillon, V., and Valko, M
Bartlett, P. L., Gabillon, V., and Valko, M. http://researchers.lille.inria.fr/ valko/hp/serve.php?what=publications/bartlett2019simple.pdf A simple parameter-free and adaptive approach to optimization under a minimal local smoothness assumption . In Algorithmic Learning Theory (ALT), 2019
2019
-
[2]
and Tsitsiklis, J
Bertsekas, D. and Tsitsiklis, J. https://books.google.co.uk/books/about/Neuro_dynamic_Programming.html?id=WxCCQgAACAAJ&source=kp_book_description&redir_esc=y Neuro-dynamic programming . Athena Scientific, Belmont, MA, 1996
1996
-
[3]
and Munos, R
Bubeck, S. and Munos, R. http://sbubeck.com/COLT10_BM.pdf Open-loop optimistic planning . In Conference on Learning Theory (COLT), 2010
2010
-
[4]
http://www.jmlr.org/papers/volume12/bubeck11a/bubeck11a.pdf X -armed bandits
Bubeck, S., Munos, R., Stoltz, G., and Szepesv \' a ri, C. http://www.jmlr.org/papers/volume12/bubeck11a/bubeck11a.pdf X -armed bandits . Journal of Machine Learning Research, 12: 0 1587--1627, 2011
2011
-
[5]
and Munos, R
Bu s oniu, L. and Munos, R. http://proceedings.mlr.press/v22/busoniu12/busoniu12.pdf Optimistic planning for Markov decision processes . In International Conference on Artificial Intelligence and Statistics (AISTATS), 2012
2012
-
[6]
and Locatelli, A
Carpentier, A. and Locatelli, A. Tight (lower) bounds for the fixed budget best-arm identification bandit problem http://proceedings.mlr.press/v49/carpentier16.pdf. In Conference on Learning Theory (COLT), 2016
2016
-
[7]
Coquelin, P.-A. and Munos, R. https://arxiv.org/pdf/1408.2028.pdf Bandit algorithms for tree search . In Conference on Uncertainty in Artificial Intelligence (UAI), 2007
-
[8]
https://hal.inria.fr/inria-00116992/document Efficient selectivity and backup operators in Monte-Carlo tree search
Coulom, R. https://hal.inria.fr/inria-00116992/document Efficient selectivity and backup operators in Monte-Carlo tree search . Computers and games, 4630: 0 72–83, 2007
2007
-
[9]
Feldman, Z. and Domshlak, C. http://dx.doi.org/10.1613/jair.4432 Simple regret optimization in online planning for Markov decision processes . Journal of Artificial Intelligence Research, 2014
-
[10]
https://hal.inria.fr/hal-00747005v1/document Best-arm identification: A unified approach to fixed budget and fixed confidence
Gabillon, V., Ghavamzadeh, M., and Lazaric, A. https://hal.inria.fr/hal-00747005v1/document Best-arm identification: A unified approach to fixed budget and fixed confidence . In Neural Information Processing Systems (NeurIPS), 2012
2012
-
[11]
https://hal.inria.fr/inria-00117266 Modification of UCT with patterns in Monte-Carlo Go
Gelly, S., Yizao, W., Munos, R., and Teytaud, O. https://hal.inria.fr/inria-00117266 Modification of UCT with patterns in Monte-Carlo Go . Technical report, Inria, 2006
2006
-
[12]
Grill, J.-B., Valko, M., and Munos, R. https://papers.nips.cc/paper/6253-blazing-the-trails-before-beating-the-path-sample-efficient-monte-carlo-planning Blazing the trails before beating the path: Sample-efficient Monte-Carlo planning . In Neural Information Processing Systems (NeurIPS), 2016
2016
-
[13]
and Hassani, M
Hoorfar, A. and Hassani, M. Inequalities on the lambert w function and hyperpower function https://www.emis.de/journals/JIPAM/images/107_07_JIPAM/107_07.pdf. Journal of Inequalities in Pure and Applied Mathematics, 9 0 (2): 0 5--9, 2008
2008
-
[14]
and Munos, R
Hren, J.-F. and Munos, R. https://hal.archives-ouvertes.fr/hal-00830182/document Optimistic planning of deterministic systems . In European Workshop on Reinforcement Learning, 2008
2008
-
[15]
Kaufmann, E. and Koolen, W. M. https://arxiv.org/pdf/1706.02986.pdf Monte-carlo tree search by best-arm identification . In Neural Information Processing Systems (NeurIPS), 2017
-
[16]
and Szepesv \' a ri, C
Kocsis, L. and Szepesv \' a ri, C. http://ggp.stanford.edu/readings/uct.pdf Bandit-based Monte-Carlo planning . In European Conference on Machine Learning (ECML), 2006
2006
-
[17]
Leurent, E. and Maillard, O.-A. https://arxiv.org/pdf/1904.04700.pdf Practical Open-Loop Optimistic Planning . arXiv preprint arXiv:1904.04700, 2019
-
[18]
Munos, R. https://papers.nips.cc/paper/4304-optimistic-optimization-of-a-deterministic-function-without-the-knowledge-of-its-smoothness.pdf Optimistic optimization of deterministic functions without the knowledge of its smoothness . In Neural Information Processing Systems (NeurIPS), 2011
2011
-
[19]
https://hal.archives-ouvertes.fr/hal-00747575v5/document From bandits to Monte-Carlo tree search: The optimistic principle applied to optimization and planning
Munos, R. https://hal.archives-ouvertes.fr/hal-00747575v5/document From bandits to Monte-Carlo tree search: The optimistic principle applied to optimization and planning . Foundations and Trends in Machine Learning, 7(1): 0 1--130, 2014
2014
-
[20]
Orabona, F. and P \' a l, D. http://dx.doi.org/10.1016/j.tcs.2017.11.021 Scale-free online learning . Theoretical Computer Science, 2018
-
[21]
and Tommasi, T
Orabona, F. and Tommasi, T. http://papers.neurips.cc/paper/6811-training-deep-networks-without-learning-rates-through-coin-betting.pdf Training deep networks without learning rates through coin betting . In Neural Information Processing Systems (NeurIPS), 2017
2017
- [22]
-
[23]
http://arxiv.org/abs/1305.6646 Normalized online learning
Ross, S., Mineiro, P., and Langford, J. http://arxiv.org/abs/1305.6646 Normalized online learning . In Conference on Uncertainty in Artificial Intelligence (UAI), 2013
-
[24]
Shah, D., Xie, Q., and Xu, Z. https://arxiv.org/pdf/1902.05213.pdf On reinforcement learning using Monte-Carlo tree search with supervised learning: Non-asymptotic analysis . arXiv preprint arXiv:1902.05213, 2019
-
[25]
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T., and Hassabis, D. http://www0.cs.ucl.ac.uk/staff/d.silver/web/Publications_files/u...
2016
-
[26]
Sz \" o r \' e nyi, B., Kedenburg, G., and Munos, R. https://papers.nips.cc/paper/5368-optimistic-planning-in-markov-decision-processes-using-a-generative-model.pdf Optimistic planning in Markov decision processes using a generative model . In Neural Information Processing Systems (NeurIPS), 2014
2014
-
[27]
http://proceedings.mlr.press/v28/valko13.pdf Stochastic simultaneous optimistic optimization
Valko, M., Carpentier, A., and Munos, R. http://proceedings.mlr.press/v28/valko13.pdf Stochastic simultaneous optimistic optimization . In International Conference on Machine Learning (ICML), 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.