Recognition: unknown
NI Sampling: Accelerating Discrete Diffusion Sampling by Token Order Optimization
Pith reviewed 2026-05-10 05:53 UTC · model grok-4.3
The pith
A neural indicator picks correct tokens early to cut discrete diffusion sampling steps by an order of magnitude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
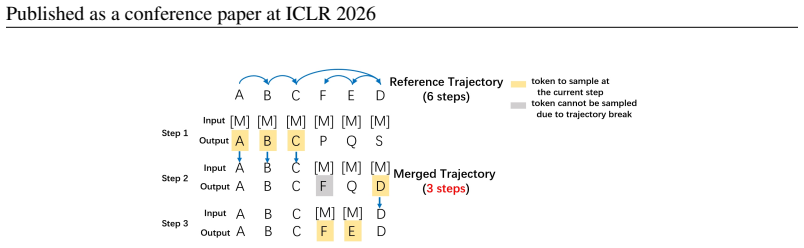
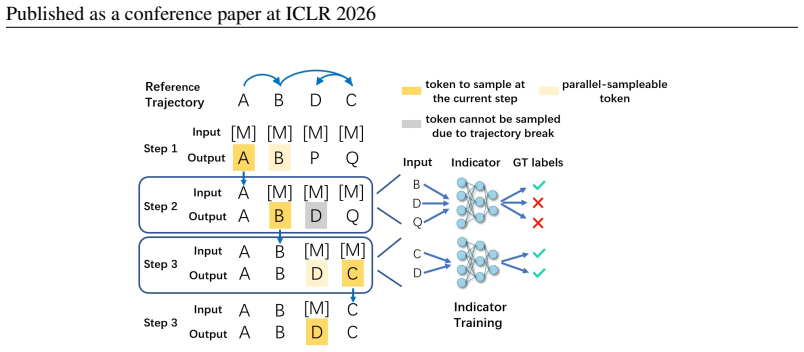
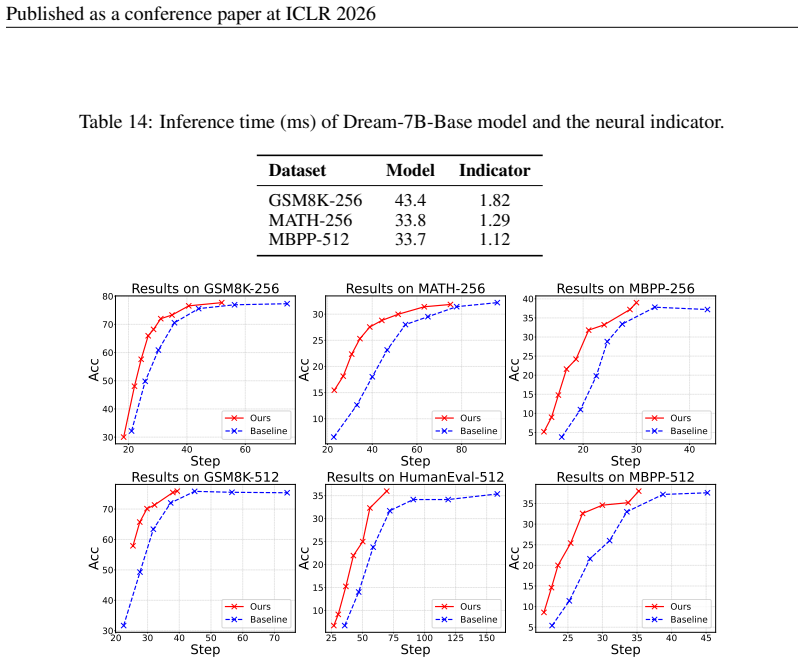
We find that fully leveraging correct predictions at each step can reduce the number of sampling iterations by an order of magnitude without compromising accuracy. Based on this observation, we propose Neural Indicator Sampling (NI Sampling), a general sampling order optimization framework that uses a neural indicator to decide which tokens should be sampled at each step, trained via a novel trajectory-preserving objective.
What carries the argument
Neural indicator trained with a trajectory-preserving objective to select which tokens to unmask early
Load-bearing premise
The neural indicator will identify correctly predicted tokens early enough to save steps without adding new errors or so much extra computation that the net speedup disappears.
What would settle it
Running NI Sampling on the same LLaDA or Dream benchmarks but observing either a noticeable accuracy drop or no reduction in required steps compared with full-step sampling.
Figures









read the original abstract
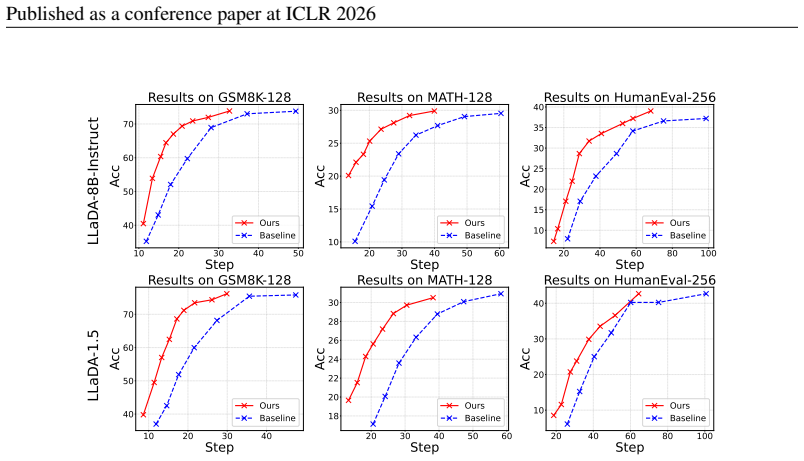
Discrete diffusion language models (dLLMs) have recently emerged as a promising alternative to traditional autoregressive approaches, offering the flexibility to generate tokens in arbitrary orders and the potential of parallel decoding. However, existing heuristic sampling strategies remain inefficient: they choose only a small part of tokens to sample at each step, leaving substantial room for improvement. In this work, we study the problem of token sampling order optimization and demonstrate its significant potential for acceleration. Specifically, we find that fully leveraging correct predictions at each step can reduce the number of sampling iterations by an order of magnitude without compromising accuracy. Based on this, we propose Neural Indicator Sampling (NI Sampling), a general sampling order optimization framework that utilize a neural indicator to decide which tokens should be sampled at each step. We further propose a novel trajectory-preserving objective to train the indicator. Experiments on LLaDA and Dream models across multiple benchmarks show that our method achieves up to 14.3$\times$ acceleration over full-step sampling with negligible performance drop, and consistently outperforms confidence threshold sampling in the accuracy-step trade-off. Code is available at https://github.com/imagination-research/NI-Sampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Neural Indicator Sampling (NI Sampling) for discrete diffusion language models (dLLMs). It claims that a neural network trained via a trajectory-preserving objective can optimize token sampling order by identifying correct tokens early, reducing sampling iterations by up to an order of magnitude. Experiments on LLaDA and Dream models report up to 14.3× acceleration over full-step sampling with negligible accuracy drop and better accuracy-step trade-offs than confidence-threshold baselines. Code is released.
Significance. If the net wall-clock and FLOPs speedups hold after accounting for indicator overhead, the work could meaningfully advance practical deployment of dLLMs by making parallel decoding far more efficient. The empirical focus on trajectory preservation and the public code release are positive for reproducibility.
major comments (2)
- [abstract and §4] The central speedup claim (abstract and §4) is reported in iteration count (up to 14.3× fewer steps) but provides no per-step FLOPs breakdown or wall-clock measurements that subtract the cost of the additional forward pass through the neural indicator. If the indicator is even 10-20% the size of the base dLLM, the net acceleration may be substantially lower than claimed; this is load-bearing for the practical contribution.
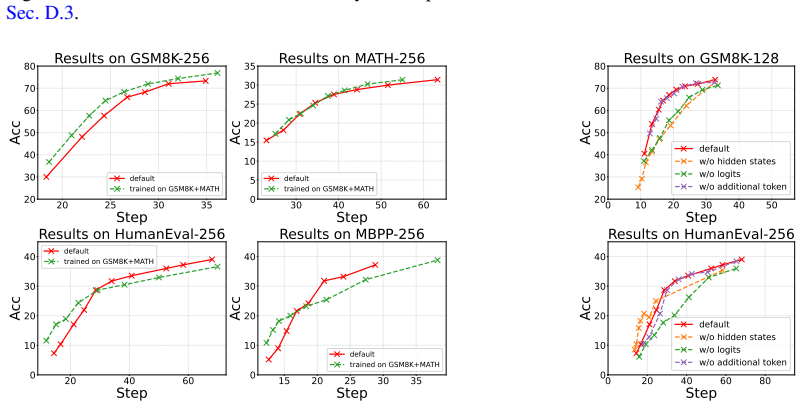
- [§3.2] §3.2 (trajectory-preserving objective): the training loss is defined on full trajectories, but it is not shown that the learned indicator avoids introducing new errors that propagate in the reduced-step regime. The weakest-assumption note in the review highlights this; an ablation on error rates when early sampling decisions are forced would be needed to support the 'negligible performance drop' claim.
minor comments (1)
- [§3.1] Notation for the indicator network (e.g., how its output mask is combined with the diffusion model's logits) could be clarified with a small diagram or explicit equation in §3.1.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [abstract and §4] The central speedup claim (abstract and §4) is reported in iteration count (up to 14.3× fewer steps) but provides no per-step FLOPs breakdown or wall-clock measurements that subtract the cost of the additional forward pass through the neural indicator. If the indicator is even 10-20% the size of the base dLLM, the net acceleration may be substantially lower than claimed; this is load-bearing for the practical contribution.
Authors: We agree that iteration count alone does not fully capture practical acceleration and that a FLOPs/wall-clock analysis accounting for indicator overhead is necessary to substantiate the contribution. The manuscript emphasizes iteration reduction because it is the direct result of the token-order optimization, but we acknowledge the referee's point that net efficiency must be demonstrated. In the revised manuscript we will add a per-step FLOPs breakdown (base model vs. indicator) together with wall-clock timings on standard hardware, allowing readers to compute the true net speedup. revision: yes
-
Referee: [§3.2] §3.2 (trajectory-preserving objective): the training loss is defined on full trajectories, but it is not shown that the learned indicator avoids introducing new errors that propagate in the reduced-step regime. The weakest-assumption note in the review highlights this; an ablation on error rates when early sampling decisions are forced would be needed to support the 'negligible performance drop' claim.
Authors: The trajectory-preserving objective is explicitly constructed to align the indicator's decisions with the tokens that would have been correctly sampled under the full trajectory, thereby limiting deviation from the original path. The reported experiments already show that final accuracy remains essentially unchanged despite the large reduction in steps, which indirectly supports limited error propagation. Nevertheless, we accept that a direct ablation measuring error rates under forced early decisions would provide stronger evidence. We will add this ablation to the revised §3.2 and §4. revision: yes
Circularity Check
Empirical training and measurement; no circular derivation
full rationale
The paper's core contribution is an empirical framework: a neural indicator is trained on full trajectories using a proposed objective, then used at inference to select tokens for early sampling. Acceleration results (up to 14.3×) are obtained from direct benchmarks on LLaDA and Dream models rather than any closed-form derivation or parameter fit that is later renamed as a prediction. No equations reduce the indicator output or speedup claim to a quantity defined in terms of itself, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural indicator network hyperparameters
axioms (1)
- domain assumption A neural network can be trained to predict which tokens will be correctly generated at the current diffusion step.
invented entities (1)
-
Neural Indicator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Structured denoising diffusion models in discrete state-spaces , author=. Advances in neural information processing systems , volume=
-
[2]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete diffusion modeling by estimating the ratios of the data distribution , author=. arXiv preprint arXiv:2310.16834 , year=
work page internal anchor Pith review arXiv
-
[3]
Advances in Neural Information Processing Systems , volume=
Simple and effective masked diffusion language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Large Language Diffusion Models
Large language diffusion models , author=. arXiv preprint arXiv:2502.09992 , year=
work page internal anchor Pith review arXiv
-
[5]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models , author=. arXiv preprint arXiv:2508.15487 , year=
work page internal anchor Pith review arXiv
-
[6]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models , author=. arXiv preprint arXiv:2505.19223 , year=
work page internal anchor Pith review arXiv
-
[7]
Train for the worst, plan for the best: Understanding token ordering in masked diffusions , author=. arXiv preprint arXiv:2502.06768 , year=
-
[8]
Mercury: Ultra-fast language models based on diffusion, 2025
Mercury: Ultra-fast language models based on diffusion , author=. arXiv preprint arXiv:2506.17298 , year=
-
[9]
Seed diffusion: A large-scale diffusion language model with high-speed inference , author=. arXiv preprint arXiv:2508.02193 , year=
-
[10]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[11]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[12]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[13]
arXiv preprint arXiv:2412.17153 , year=
Distilled decoding 1: One-step sampling of image auto-regressive models with flow matching , author=. arXiv preprint arXiv:2412.17153 , year=
-
[14]
arXiv preprint arXiv:2510.21003 , year=
Distilled decoding 2: One-step sampling of image auto-regressive models with conditional score distillation , author=. arXiv preprint arXiv:2510.21003 , year=
-
[15]
Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding , author=. arXiv preprint arXiv:2505.22618 , year=
-
[16]
Advances in Neural Information Processing Systems , volume=
A continuous time framework for discrete denoising models , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Advances in Neural Information Processing Systems , volume=
Concrete score matching: Generalized score matching for discrete data , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Maskgit: Masked generative image transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[19]
Block diffusion: Interpolating between autoregressive and diffusion language models , author=. arXiv preprint arXiv:2503.09573 , year=
-
[20]
Advances in neural information processing systems , volume=
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps , author=. Advances in neural information processing systems , volume=
-
[21]
Machine Intelligence Research , pages=
Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models , author=. Machine Intelligence Research , pages=. 2025 , publisher=
2025
-
[22]
Advances in Neural Information Processing Systems , volume=
Unipc: A unified predictor-corrector framework for fast sampling of diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2204.13902 , year=
Fast Sampling of Diffusion Models with Exponential Integrator , author=. arXiv preprint arXiv:2204.13902 , year=
-
[24]
dllm-cache: Accelerating diffusion large language models with adaptive caching , author=. arXiv preprint arXiv:2506.06295 , year=
-
[25]
The Twelfth International Conference on Learning Representations , year=
A unified sampling framework for solver searching of diffusion probabilistic models , author=. The Twelfth International Conference on Learning Representations , year=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Fast ode-based sampling for diffusion models in around 5 steps , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[28]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Medusa: Simple llm inference acceleration framework with multiple decoding heads , author=. arXiv preprint arXiv:2401.10774 , year=
work page internal anchor Pith review arXiv
-
[29]
Eagle: Speculative sampling requires rethinking feature uncertainty , author=. arXiv preprint arXiv:2401.15077 , year=
-
[30]
Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding , author=. arXiv preprint arXiv:2410.01699 , year=
-
[31]
Eagle-2: Faster inference of language models with dynamic draft trees , author=. arXiv preprint arXiv:2406.16858 , year=
-
[32]
Eagle-3: Scaling up inference acceleration of large language models via training-time test , author=. arXiv preprint arXiv:2503.01840 , year=
-
[33]
CITER: Collaborative Inference for Efficient Large Language Model Decoding with Token-Level Routing , author=. arXiv preprint arXiv:2502.01976 , year=
-
[34]
R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing , author=. arXiv preprint arXiv:2505.21600 , year=
-
[35]
Scaling up masked diffusion models on text.arXiv preprint arXiv:2410.18514,
Scaling up masked diffusion models on text , author=. arXiv preprint arXiv:2410.18514 , year=
-
[36]
Advances in neural information processing systems , volume=
Argmax flows and multinomial diffusion: Learning categorical distributions , author=. Advances in neural information processing systems , volume=
-
[37]
Hemmat, A., Torr, P., Chen, Y ., and Yu, J
Diffusionbert: Improving generative masked language models with diffusion models , author=. arXiv preprint arXiv:2211.15029 , year=
-
[38]
Diffuser: Discrete diffusion via edit-based reconstruction , author=. arXiv preprint arXiv:2210.16886 , year=
-
[39]
Score-based continuous-time discrete diffusion models
Score-based continuous-time discrete diffusion models , author=. arXiv preprint arXiv:2211.16750 , year=
-
[40]
Autoregressive Image Generation Without Vector Quantization
Autoregressive Image Generation without Vector Quantization , author=. arXiv preprint arXiv:2406.11838 , year=
-
[41]
European Conference on Computer Vision , pages=
Improved masked image generation with token-critic , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[42]
The Eleventh International Conference on Learning Representations , year=
Discrete predictor-corrector diffusion models for image synthesis , author=. The Eleventh International Conference on Learning Representations , year=
-
[43]
The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
Texygen: A benchmarking platform for text generation models , author=. The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
-
[44]
Advances in Neural Information Processing Systems , volume=
Mauve: Measuring the gap between neural text and human text using divergence frontiers , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Advances in neural information processing systems , volume=
Simplified and generalized masked diffusion for discrete data , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.