Recognition: unknown
A Scientific Human-Agent Reproduction Pipeline
Pith reviewed 2026-05-10 03:37 UTC · model grok-4.3
The pith
SHARP enables faithful reproduction of scientific analyses through structured human-AI collaboration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
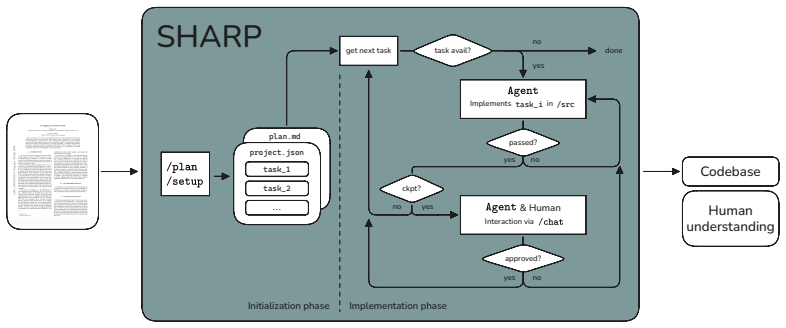
SHARP decomposes a reproduction task into discrete steps executed autonomously by AI subagents specialized in code generation, testing, and quality assurance. Human researchers review progress at defined checkpoints, provide feedback, and steer the analysis. When applied to reproducing a jet classification analysis in particle physics, the resulting code achieved performance comparable to the original publication, with high faithfulness to the described method.
What carries the argument
SHARP, the Scientific Human-Agent Reproduction Pipeline, which structures the task as autonomous agent steps with human review checkpoints.
Load-bearing premise
AI agents can autonomously produce correct analysis code from scientific descriptions when humans provide targeted feedback at checkpoints.
What would settle it
If the code produced by the SHARP pipeline for the jet classification task yields significantly different performance metrics or incorrect physics results compared to the original paper.
Figures
read the original abstract
Reproducing scientific analyses is essential for preserving knowledge, building extensible codebases, and deepening researcher understanding - yet the effort often outweighs its academic recognition. We argue that the reproduction of scientific data analyses is fundamentally a translation task: converting human-readable knowledge (papers, documentation) into machine-readable analysis code. This makes it uniquely well-suited for AI agents. We present SHARP (Scientific Human-Agent Reproduction Pipeline), a structured framework for reproducing scientific analyses through human-agent collaboration. SHARP decomposes a reproduction task into discrete steps, which an AI agent executes autonomously using specialized subagents for code generation, testing, and quality assurance. At defined checkpoints, the researcher reviews progress, provides feedback, and steers the analysis - keeping the human firmly in control of scientific judgment while the agent handles implementation. We demonstrate SHARP by reproducing a jet classification task in particle physics from a published paper. We evaluate the reproduction along three axes: analysis performance against the original results, code quality and faithfulness, and the nature of the human-agent conversation. The latter is evaluated with a novel framework for characterizing human-agent interactions. Our work highlights a practical model for AI-assisted scientific reproduction where the researcher's role shifts from writing code to understanding, evaluating, and directing - elevating human understanding rather than replacing it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SHARP, a structured framework for reproducing scientific analyses via human-AI agent collaboration. It decomposes reproduction tasks into discrete autonomous steps executed by specialized subagents for code generation, testing, and quality assurance, with defined human checkpoints for review, feedback, and steering. The framework is demonstrated by reproducing a jet classification task from a published particle physics paper and evaluated along three axes: analysis performance matching the original, code quality and faithfulness, and the nature of human-agent interactions (using a novel characterization framework).
Significance. If the demonstration holds, SHARP provides a practical model for AI-assisted reproduction that keeps the researcher in control of scientific judgment while automating implementation details. This could aid reproducibility and knowledge preservation in data-intensive fields. The novel framework for characterizing human-agent conversations is a clear strength and could be useful beyond this application.
major comments (3)
- [Abstract and demonstration section] Abstract and demonstration section: The paper reports a successful reproduction of the jet classification task but provides no quantitative metrics (e.g., accuracy, AUC, or side-by-side comparison tables to the original results), error analysis, or discussion of failure modes. This leaves the central claim of faithful reproduction only modestly supported, as performance matching could arise from compensatory mistakes rather than correct implementation.
- [Evaluation section on human-agent conversation] Evaluation section on human-agent conversation: The manuscript does not report the number of iterations per checkpoint, specific error types encountered by the subagents, or an independent audit showing that performance-matched output implies faithful code rather than coincidental agreement. This directly bears on the load-bearing assumption that discrete human checkpoints plus feedback suffice to catch and correct scientific errors.
- [SHARP framework description] SHARP framework description: The claim that current AI agents can autonomously translate complex scientific descriptions into correct analysis code between human checkpoints is presented without testing beyond the single chosen example or discussion of potential limitations when the original analysis contains subtle physics choices.
minor comments (2)
- [Demonstration section] Ensure the original paper being reproduced is cited with full bibliographic details in the demonstration section for easy cross-reference.
- [Evaluation section] The novel interaction characterization framework is introduced but its precise criteria or scoring rubric could be clarified with an example from the jet task conversation.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the significance of SHARP and for the detailed, constructive comments. We address each major point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: The paper reports a successful reproduction of the jet classification task but provides no quantitative metrics (e.g., accuracy, AUC, or side-by-side comparison tables to the original results), error analysis, or discussion of failure modes. This leaves the central claim of faithful reproduction only modestly supported, as performance matching could arise from compensatory mistakes rather than correct implementation.
Authors: We agree that quantitative metrics are necessary to robustly support the claim of faithful reproduction. In the revised manuscript we will add a dedicated table comparing key performance metrics (accuracy, AUC, and any other relevant observables) between the original paper and the SHARP reproduction. We will also include an error analysis and explicit discussion of any failure modes observed during the process, thereby reducing the possibility that agreement arises from compensatory errors. revision: yes
-
Referee: The manuscript does not report the number of iterations per checkpoint, specific error types encountered by the subagents, or an independent audit showing that performance-matched output implies faithful code rather than coincidental agreement. This directly bears on the load-bearing assumption that discrete human checkpoints plus feedback suffice to catch and correct scientific errors.
Authors: We acknowledge that greater transparency on the interaction process would strengthen the evaluation. We will expand the relevant section to report the number of iterations at each checkpoint and to categorize the specific error types encountered by the subagents. Our existing code-quality assessment already includes manual inspection of generated code against the source description; we will elaborate on this procedure to address concerns about coincidental agreement. A fully independent external audit lies outside the scope of the current work but can be noted as a desirable future extension. revision: partial
-
Referee: The claim that current AI agents can autonomously translate complex scientific descriptions into correct analysis code between human checkpoints is presented without testing beyond the single chosen example or discussion of potential limitations when the original analysis contains subtle physics choices.
Authors: The demonstration is intentionally focused on a single, well-documented example to illustrate the framework. We will add a new limitations subsection that explicitly discusses challenges that may arise with subtle physics choices (e.g., specific variable definitions, kinematic selections, or approximations) and note that broader multi-analysis validation is planned for future work. This will clarify the current scope while preserving the general applicability of SHARP. revision: yes
Circularity Check
No circularity: SHARP framework defined independently and evaluated externally
full rationale
The paper introduces SHARP as a human-agent collaboration framework for reproducing analyses, decomposed into discrete steps with human checkpoints. It is demonstrated and evaluated by direct comparison to an external published jet classification paper, with metrics on performance, code quality, and interaction nature. No equations, fitted parameters, predictions, or central claims reduce by construction to inputs defined within the paper. No self-citations are load-bearing for the framework definition or uniqueness. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AI agents can reliably translate human-readable scientific descriptions into correct machine-readable analysis code between human review checkpoints
invented entities (2)
-
SHARP framework
no independent evidence
-
specialized subagents for code generation, testing, and quality assurance
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Learning to Unscramble: Simplifying Symbolic Expressions via Self-Supervised Oracle Trajectories
David Shih. Learning to Unscramble: Simplifying Symbolic Expressions via Self-Supervised Oracle Trajectories, 2026. URLhttps://arxiv.org/abs/2603.11164
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Learning to Unscramble Feynman Loop Integrals with SAILIR
David Shih. Learning to Unscramble Feynman Loop Integrals with SAILIR, 2026. URL https://arxiv.org/abs/2604.05034
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, 2024. URL https: //arxiv.org/abs/2408.06292
work page internal anchor Pith review arXiv 2024
-
[5]
Automating High Energy Physics Data Analysis with LLM-Powered Agents,
Eli Gendreau-Distler, Joshua Ho, Dongwon Kim, Luc Tomas Le Pottier, Haichen Wang, and Chengxi Yang. Automating High Energy Physics Data Analysis with LLM-Powered Agents,
- [6]
-
[7]
karpathy/autoresearch, April 2026
Andrej Karpathy. karpathy/autoresearch, April 2026. URLhttps://github.com/karpathy/ autoresearch. original-date: 2026-03-06T22:00:43Z
2026
-
[8]
Anthony Badea, Yi Chen, Marcello Maggi, Yen-Jie Lee, and Electron-Positron Alliance. Agentic AI – Physicist Collaboration in Experimental Particle Physics: A Proof-of-Concept Measure- ment with LEP Open Data, 2026. URLhttps://arxiv.org/abs/2603.05735
-
[9]
PRBench: End-to-end Paper Reproduction in Physics Research, 2026
Shi Qiu et al. PRBench: End-to-end Paper Reproduction in Physics Research, 2026. URL https://arxiv.org/abs/2603.27646
-
[10]
Sascha Diefenbacher, Anna Hallin, Gregor Kasieczka, Michael Krämer, Anne Lauscher, and Tim Lukas. Agents of Discovery, 2026. URLhttps://arxiv.org/abs/2509.08535
- [11]
-
[12]
Ai agents can already autonomously perform experimental high energy physics,
Eric A. Moreno, Samuel Bright-Thonney, Andrzej Novak, Dolores Garcia, and Philip Harris. AI Agents Can Already Autonomously Perform Experimental High Energy Physics, 2026. URL https://arxiv.org/abs/2603.20179
-
[13]
software engineer
Geoffrey Huntley. Ralph Wiggum as a "software engineer", July 2025. URL https:// ghuntley.com/ralph/
2025
-
[14]
SHARP: Template to reproduce scientific analyses with a coding agent., April 2026
Dennis Noll and Joschka Birk. SHARP: Template to reproduce scientific analyses with a coding agent., April 2026. URLhttps://github.com/stanford-ai4physics/sharp
2026
-
[15]
Claude Code Docs, 2026
Anthropic. Claude Code Docs, 2026. URL https://code.claude.com/docs/en/ overview
2026
-
[16]
FlexCAST: Enabling Flexible Scientific Data Analyses, 7
Benjamin Nachman and Dennis Noll. FlexCAST: Enabling Flexible Scientific Data Analyses, 7
- [17]
-
[18]
Giordano et al., HEPScore: A new CPU benchmark for the WLCG , EPJ Web of Conf
Marcel Rieger. End-to-End Analysis Automation over Distributed Resources with Luigi Analysis Workflows.EPJ Web Conf., 295:05012, 2024. doi: 10.1051/epjconf/202429505012
-
[19]
Huilin Qu and Loukas Gouskos. ParticleNet: Jet Tagging via Particle Clouds.Phys. Rev. D, 101 (5):056019, 2020. doi: 10.1103/PhysRevD.101.056019
-
[20]
Gregor Kasieczka, Tilman Plehn, Jennifer Thompson, and Michael Russel. Top Quark Tagging Reference Dataset, March 2019. URLhttps://doi.org/10.5281/zenodo.2603256
-
[21]
Anja Butter et al. The Machine Learning landscape of top taggers.SciPost Phys., 7:014, 2019. doi: 10.21468/SciPostPhys.7.1.014
-
[22]
claude-hpc: Sandboxed Claude Code environment for HPC and local Docker, April 2026
Dennis Noll and Joschka Birk. claude-hpc: Sandboxed Claude Code environment for HPC and local Docker, April 2026. URLhttps://github.com/nollde/claude-hpc
2026
-
[23]
claude-parser: Display and Analyze Conversations with Claude, April 2026
Dennis Noll. claude-parser: Display and Analyze Conversations with Claude, April 2026. URL https://github.com/nollde/claude-parser. 6
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.