Recognition: unknown
Efficient Mixture-of-Experts LLM Inference with Apple Silicon NPUs
Pith reviewed 2026-05-10 05:27 UTC · model grok-4.3
The pith
NPUMoE lets Mixture-of-Experts LLMs offload most work to Apple NPUs using offline expert calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
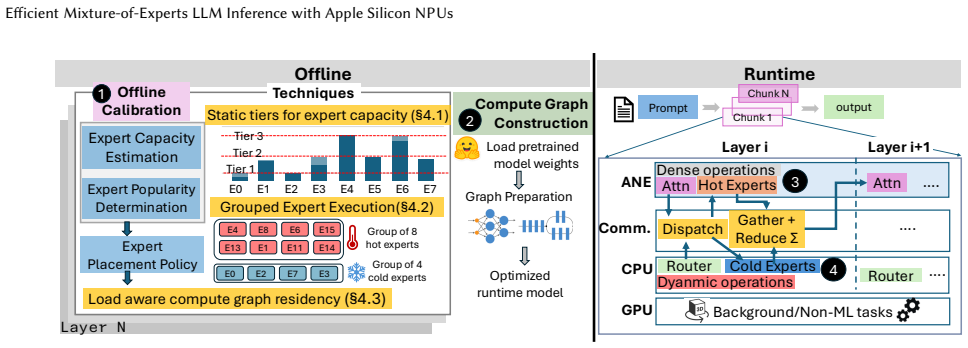
NPUMoE is a runtime inference engine that accelerates MoE execution on Apple Silicon by offloading dense, static computation to NPU, while preserving a CPU/GPU fallback path for dynamic operations. NPUMoE uses offline calibration to estimate expert capacity and popularity that drives three key techniques: (1) Static tiers for expert capacity to address dynamic expert routing (2) Grouped expert execution to mitigate NPU concurrency limits (3) Load-aware expert compute graph residency to reduce CPU-NPU synchronization overhead. Experiments on Apple M-series devices using three representative MoE LLMs and four long-context workloads show that NPUMoE consistently outperforms baselines, reducing
What carries the argument
Offline calibration that produces static expert capacity tiers and popularity estimates, which then drive grouped NPU execution and load-aware graph residency.
If this is right
- Most of the expert matrix multiplications in MoE models can be moved to the NPU even though routing is dynamic.
- Long-context prefills on Apple M-series devices become 1.32x to 5.55x faster.
- Energy used per token drops by 1.81x to 7.37x when the NPU handles the grouped static work.
- CPU cycles spent on inference fall by 1.78x to 5.54x, freeing the processor for other tasks.
- The same calibration and grouping approach works across different MoE models and workloads tested.
Where Pith is reading between the lines
- The same offline calibration pattern could be tried on other mobile NPUs if their shape and concurrency constraints are similar.
- Device makers might add more flexible support for scatter/gather and top-k inside future NPUs once software shows the payoff.
- On-device long-context applications such as document summarization could become practical on phones and laptops that already contain Apple Silicon.
- If calibration data is refreshed periodically from recent user sessions, the method might stay effective without full retraining.
Load-bearing premise
That offline calibration on representative data can produce static expert capacity tiers and popularity estimates that remain accurate enough at runtime to avoid frequent fallback or performance collapse on unseen long-context workloads.
What would settle it
Running the system on a long-context workload whose expert routing statistics differ sharply from the calibration data and checking whether latency, energy, and CPU gains disappear or reverse.
Figures














read the original abstract
Apple Neural Engine (ANE) is a dedicated neural processing unit (NPU) present in every Apple Silicon chip. Mixture-of-Experts (MoE) LLMs improve inference efficiency via sparse activation but are challenging for NPUs in three ways: expert routing is unpredictable and introduces dynamic tensor shapes that conflict with the shape-specific constraints of NPUs; several irregular operators, e.g., top-k, scatter/gather, etc., are not NPU-friendly; and launching many small expert kernels incurs substantial dispatch and synchronization overhead. NPUs are designed to offload AI compute from CPU and GPU; our goal is to enable such offloading for MoE inference, particularly during prefill, where long-context workloads consume substantial system resources. This paper presents NPUMoE, a runtime inference engine that accelerates MoE execution on Apple Silicon by offloading dense, static computation to NPU, while preserving a CPU/GPU fallback path for dynamic operations. NPUMoE uses offline calibration to estimate expert capacity and popularity that drives three key techniques: (1) Static tiers for expert capacity to address dynamic expert routing (2) Grouped expert execution to mitigate NPU concurrency limits (3) Load-aware expert compute graph residency to reduce CPU-NPU synchronization overhead. Experiments on Apple M-series devices using three representative MoE LLMs and four long-context workloads show that NPUMoE consistently outperforms baselines, reducing latency by 1.32x-5.55x, improving energy efficiency by 1.81x-7.37x, and reducing CPU-cycle usage by 1.78x-5.54x through effective NPU offloading.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NPUMoE, a runtime inference engine for Mixture-of-Experts LLMs on Apple Silicon NPUs. It addresses NPU limitations with MoE (unpredictable routing, irregular operators, dispatch overhead) by using offline calibration to derive static expert capacity tiers and popularity estimates. These drive three techniques: static capacity tiers, grouped expert execution, and load-aware compute graph residency, enabling NPU offloading of dense static computation with CPU/GPU fallback for dynamic parts. Experiments on M-series devices with three MoE LLMs and four long-context workloads report latency reductions of 1.32x-5.55x, energy efficiency gains of 1.81x-7.37x, and CPU-cycle reductions of 1.78x-5.54x.
Significance. If the empirical claims hold under scrutiny, this work would be significant for practical deployment of sparse MoE models on consumer NPUs, particularly for long-context prefill workloads that stress system resources. It offers concrete engineering solutions to make NPU offloading viable for dynamic routing patterns, which could improve accessibility and efficiency of large LLMs on Apple hardware. The paper credits its contributions through specific quantitative gains on representative models and workloads, though the absence of detailed validation limits immediate impact assessment.
major comments (2)
- [Offline calibration and techniques description] The offline calibration of static expert capacity tiers and popularity estimates (described as driving all three core techniques) is load-bearing for the claimed speedups, yet no ablation is provided on calibration-test distribution mismatch or measured fallback frequency to CPU/GPU paths when long-context inputs shift activation patterns from the calibration data. This directly affects whether the 1.32x-5.55x latency and 1.81x-7.37x energy gains generalize beyond the four evaluated workloads.
- [Experiments] The Experiments section (and abstract) reports specific performance numbers (latency, energy, CPU cycles) across three MoE LLMs and four workloads but supplies no baseline descriptions, workload definitions, error bars, hardware configurations, or statistical details, preventing verification of the central empirical claim that NPUMoE consistently outperforms via effective NPU offloading.
minor comments (1)
- [Introduction] The abstract and introduction could more clearly distinguish the NPU-specific constraints (shape-specific kernels, concurrency limits) from general MoE challenges to sharpen the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional analysis on calibration robustness and complete experimental details are needed to strengthen the paper. We will revise accordingly.
read point-by-point responses
-
Referee: [Offline calibration and techniques description] The offline calibration of static expert capacity tiers and popularity estimates (described as driving all three core techniques) is load-bearing for the claimed speedups, yet no ablation is provided on calibration-test distribution mismatch or measured fallback frequency to CPU/GPU paths when long-context inputs shift activation patterns from the calibration data. This directly affects whether the 1.32x-5.55x latency and 1.81x-7.37x energy gains generalize beyond the four evaluated workloads.
Authors: We agree that demonstrating robustness to distribution shift is important. In the revised manuscript we will add an ablation evaluating NPUMoE on additional long-context inputs drawn from distributions distinct from the calibration set (e.g., different prompt styles and context lengths). We will also report the observed fallback frequency to CPU/GPU paths on the four evaluated workloads, confirming that static tiers keep fallback low. revision: yes
-
Referee: [Experiments] The Experiments section (and abstract) reports specific performance numbers (latency, energy, CPU cycles) across three MoE LLMs and four workloads but supplies no baseline descriptions, workload definitions, error bars, hardware configurations, or statistical details, preventing verification of the central empirical claim that NPUMoE consistently outperforms via effective NPU offloading.
Authors: We acknowledge the omission of these details. The revised Experiments section will include: explicit descriptions of all baselines, precise definitions and input characteristics of the four workloads, hardware specifications for the M-series devices, error bars with standard deviations from repeated runs, and any relevant statistical information. revision: yes
Circularity Check
No circularity: empirical systems paper with measured results
full rationale
The manuscript describes an engineering runtime system (NPUMoE) that uses offline calibration to set static expert tiers and popularity estimates, then applies three techniques (static capacity tiers, grouped execution, load-aware graph residency) and reports measured speedups on four workloads against baselines. No equations, first-principles derivations, or fitted predictions are presented as outputs that reduce to the calibration inputs by construction. No self-citation chains or uniqueness theorems are invoked to justify core claims. The contribution is therefore self-contained empirical evaluation rather than a closed derivation loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. 2024. Phi-4 technical report. arXiv preprint arXiv:2412.08905 (2024)
work page internal anchor Pith review arXiv 2024
- [2]
- [3]
-
[4]
Yash Akhauri, Ahmed F AbouElhamayed, Jordan Dotzel, Zhiru Zhang, Alexander M Rush, Safeen Huda, and Mohamed S Abdelfattah. 2024. Shadowllm: Predictor-based contextual sparsity for large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 19154–19167
2024
-
[5]
ANEMLL Contributors. 2026. ANEMLL: Artificial Neural Engine Machine Learning Library.https://github.com/Anemll/AnemllGitHub repository, version 0.3.5 beta, accessed 2026-04-07
2026
-
[6]
antmikinka. 2024. Optimization Guidelines for the Apple Neural Engine (ANE).https://gist.github.com/antmikinka/ 715499ae63630575065b22e5cb6ad8dd. GitHub Gist. Accessed: 2026-04-15
2024
-
[7]
Apple Inc. 2023. Apple Reports First Quarter Results. Corporate Report. Apple Inc.https://www.apple.com/newsroom/2023/02/apple- reports-first-quarter-results/
2023
-
[8]
Apple Machine Learning Research. 2024. Deploying Attention- Based Vision Transformers to Apple Neural Engine. Apple Machine Learning Research (5 Jan 2024).https://machinelearning.apple.com/ research/vision-transformers
2024
-
[9]
Shiyi Cao, Shu Liu, Tyler Griggs, Peter Schafhalter, Xiaoxuan Liu, Ying Sheng, Joseph E Gonzalez, Matei Zaharia, and Ion Stoica. 2025. Moe- lightning: High-throughput moe inference on memory-constrained gpus. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 715–730
2025
-
[10]
Le Chen, Dahu Feng, Erhu Feng, Yingrui Wang, Rong Zhao, Yubin Xia, Pinjie Xu, and Haibo Chen. 2025. Characterizing mobile soc for accelerating heterogeneous llm inference. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 359–374
2025
-
[11]
Le Chen, Dahu Feng, Erhu Feng, Rong Zhao, Yingrui Wang, Yubin Xia, Haibo Chen, and Pinjie Xu. 2025. Heterollm: Accelerating large language model inference on mobile socs platform with heterogeneous ai accelerators. arXiv e-prints (2025), arXiv–2501
2025
- [12]
-
[13]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short pap...
2019
- [14]
-
[15]
Kuntai Du, Bowen Wang, Chen Zhang, Yiming Cheng, Qing Lan, Hejian Sang, Yihua Cheng, Jiayi Yao, Xiaoxuan Liu, Yifan Qiao, et al
-
[16]
In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles
Prefillonly: An inference engine for prefill-only workloads in large language model applications. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 399–414
-
[17]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch trans- formers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research 23, 120 (2022), 1–39
2022
-
[18]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. 2024. The L...
- [19]
-
[20]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. RULER: What’s the real context size of your long-context language models? arXiv preprint arXiv:2404.06654 (2024)
work page internal anchor Pith review arXiv 2024
-
[21]
Paul Hübner, Andong Hu, Ivy Peng, and Stefano Markidis. 2025. Ap- ple vs. oranges: Evaluating the apple silicon m-series socs for hpc performance and efficiency. In 2025 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 45– 54
2025
-
[22]
Apple Inc. 2026. Core ML.https://developer.apple.com/machine- learning/core-ml/Accessed: 2026-03-02
2026
-
[23]
Apple Inc. 2026. Core ML Models.https://developer.apple.com/ machine-learning/models/Accessed: 2026-03-02
2026
-
[24]
Apple Inc. 2026. Deploying Transformers on the Apple Neural En- gine.https://machinelearning.apple.com/research/neural-engine- transformersAccessed: 2026-03-02
2026
-
[25]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xu- fang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al. 2024. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention. Advances in Neural Information Processing Systems 37 (2024), 52481–52515
2024
-
[26]
Jaehoon Jung, Jinpyo Kim, and Jaejin Lee. 2023. Deepum: Tensor migration and prefetching in unified memory. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume2. 207–221
2023
-
[27]
Keisuke Kamahori, Tian Tang, Yile Gu, Kan Zhu, and Baris Kasikci
-
[28]
In The Thirteenth International Conference on Learning Representations (ICLR)
Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture- of-Experts Models. In The Thirteenth International Conference on Learning Representations (ICLR). 12 Efficient Mixture-of-Experts LLM Inference with Apple Silicon NPUs
-
[29]
Rui Kong, Yuanchun Li, Qingtian Feng, Weijun Wang, Xiaozhou Ye, Ye Ouyang, Linghe Kong, and Yunxin Liu. 2024. SwapMoE: Serv- ing Off-the-shelf MoE-based Large Language Models with Tunable Memory Budget. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[30]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668 (2020)
work page internal anchor Pith review arXiv 2020
-
[31]
Minchong Li, Feng Zhou, and Xiaohui Song. 2025. Bild: Bi-directional logits difference loss for large language model distillation. In Proceedings of the 31st International Conference on Computational Linguistics. 1168–1182
2025
-
[32]
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. 2024. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434 (2024)
work page internal anchor Pith review arXiv 2024
-
[33]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al . 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. 2023. Deja vu: Contextual sparsity for efficient llms at infer- ence time. In International Conference on Machine Learning. PMLR, 22137–22176
2023
-
[35]
Microsoft. 2024. Phi-3.5-MoE-instruct.https://huggingface.co/ microsoft/Phi-3.5-MoE-instructHugging Face model card. Accessed: 2026-04-09
2024
-
[36]
Microsoft. 2025. Phi-tiny-MoE-instruct.https://huggingface.co/ microsoft/Phi-tiny-MoE-instructHugging Face model card. Accessed: 2026-04-09
2025
-
[37]
Seungjae Moon, Junseo Cha, Hyunjun Park, and Joo-Young Kim
-
[38]
In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA)
Hybe: GPU-NPU Hybrid System for Efficient LLM Inference with Million-Token Context Window. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA). 808–820
-
[39]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Manjeet Singh. 2026. Inside the M4 Apple Neural Engine.https: //maderix.substack.com/p/inside-the-m4-apple-neural-engine-615. maderix’s Substack
2026
-
[41]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al
-
[42]
Kimi-vl technical report. arXiv preprint arXiv:2504.07491 (2025)
work page internal anchor Pith review arXiv 2025
-
[43]
The ML-Energy Initiative. 2025. zeus-apple-silicon: Zeus device support for Apple Silicon.https://github.com/ml-energy/zeus-apple- siliconGitHub repository
2025
- [44]
-
[45]
Wikipedia contributors. 2026. Apple Neural Engine.https://en. wikipedia.org/wiki/Neural_EngineAccessed: 2026-03-02
2026
- [46]
-
[47]
Daliang Xu, Hao Zhang, Liming Yang, Ruiqi Liu, Gang Huang, Meng- wei Xu, and Xuanzhe Liu. 2025. Fast on-device llm inference with npus. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 445–462
2025
- [48]
-
[49]
Yuqi Xue, Yiqi Liu, Lifeng Nai, and Jian Huang. 2023. V10: Hardware- assisted npu multi-tenancy for improved resource utilization and fairness. In Proceedings of the 50th Annual International Symposium on Computer Architecture. 1–15
2023
-
[50]
Yuqi Xue, Yiqi Liu, Lifeng Nai, and Jian Huang. 2024. Hardware- assisted virtualization of neural processing units for cloud plat- forms. In 2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 1–16
2024
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [52]
-
[53]
Juheon Yi and Youngki Lee. 2020. Heimdall: mobile GPU coordina- tion platform for augmented reality applications. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking. 1–14
2020
-
[54]
Wangsong Yin, Daliang Xu, Mengwei Xu, Gang Huang, and Xuanzhe Liu. 2025. Dynamic sparse attention on mobile socs. arXiv preprint arXiv:2508.16703 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Enda Yu, Zhaoning Zhang, Dezun Dong, Yongwei Wu, and Xi- angke Liao. 2025. PreScope: Unleashing the Power of Prefetch- ing for Resource-Constrained MoE Inference. arXiv preprint arXiv:2509.23638 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence?. In Proceedings of the 57th annual meeting of the association for computational linguistics. 4791–4800
2019
- [57]
-
[58]
Yuxin Zhou, Zheng Li, Jun Zhang, Jue Wang, Yiping Wang, Zhongle Xie, Ke Chen, and Lidan Shou. 2025. FloE: On-the-Fly MoE Inference on Memory-constrained GPU. In Proceedings of the International Conference on Machine Learning (ICML)
2025
-
[59]
Pengfei Zuo, Huimin Lin, Junbo Deng, Nan Zou, Xingkun Yang, Yingyu Diao, Weifeng Gao, Ke Xu, Zhangyu Chen, Shirui Lu, et al . 2025. Serving large language models on huawei cloudmatrix384. arXiv preprint arXiv:2506.12708 (2025). 13 Afsara Benazir and Felix Xiaozhu Lin A Appendix A.1 Phimoe-tiny 11.776 18.528 11.328 6.304 0 10 20 Prefill 5.6064 6.464 5.824 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.