Recognition: unknown
Benchmarking Quantum Kernel Support Vector Machines Against Classical Baselines on Tabular Data: A Rigorous Empirical Study with Hardware Validation
Pith reviewed 2026-05-10 03:59 UTC · model grok-4.3
The pith
Quantum kernel support vector machines show no statistically significant advantage over classical kernels on nine tabular classification datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
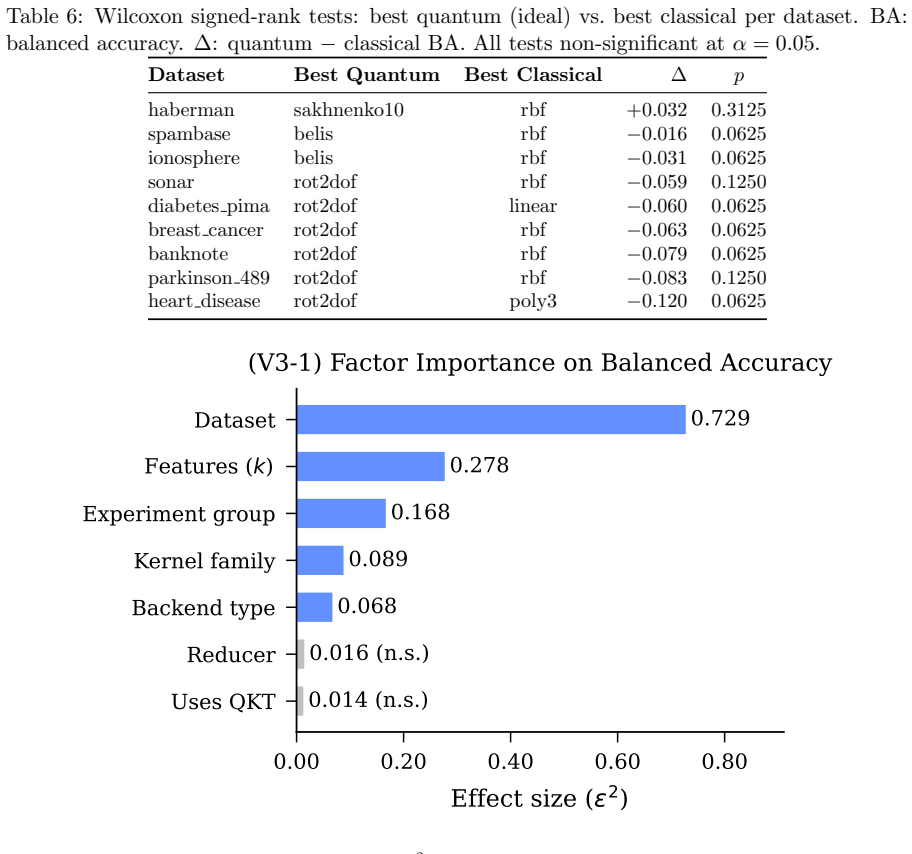
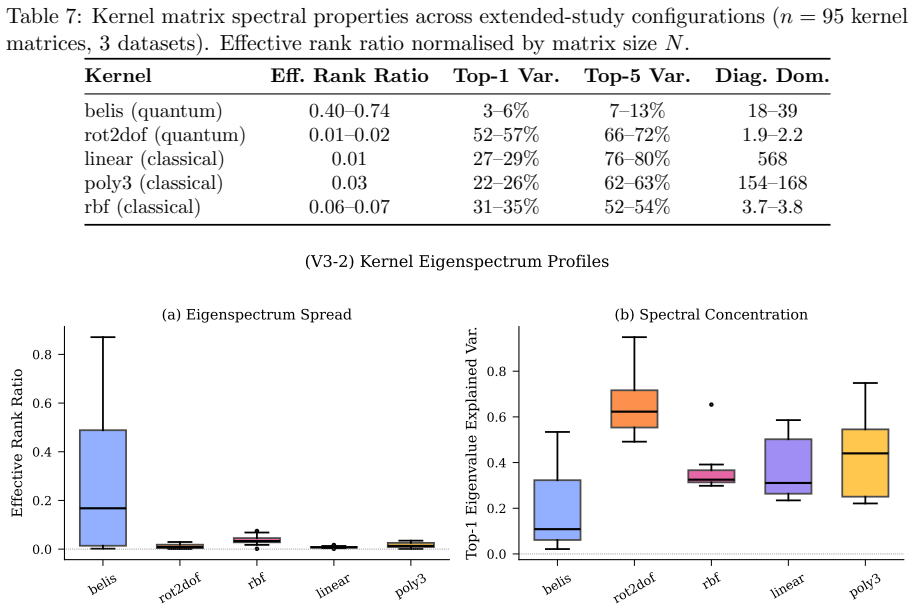
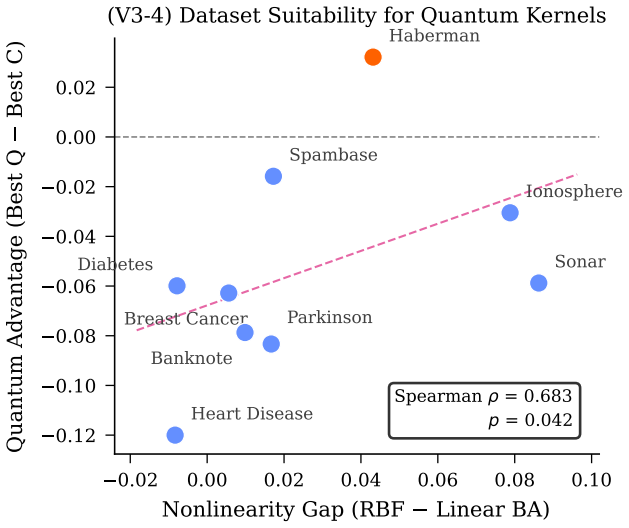
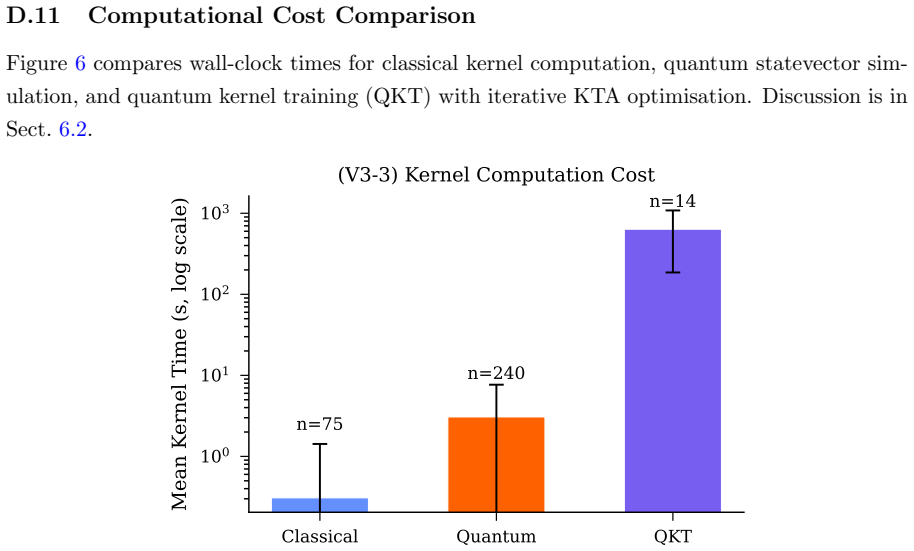
Across the tested quantum feature maps and classical kernels, no pairwise comparison yields a statistically significant accuracy difference at alpha equals 0.05. Dataset choice dominates performance variance with an effect size of 0.73, while kernel choice contributes only 0.09. Current quantum kernels exhibit eigenspectra that are either too flat or too concentrated and therefore miss the intermediate eigenvalue distribution that characterizes the best classical radial basis function kernel. Quantum kernel training reaches one competitive result on the breast cancer dataset but at roughly two thousand times the computational cost of classical training.
What carries the argument
Kruskal-Wallis factorial analysis of performance variance combined with direct comparison of kernel eigenspectra.
If this is right
- Dataset selection should be the primary focus when designing tabular classification experiments rather than kernel engineering.
- Quantum feature maps require redesign to generate eigenspectra that more closely match those of effective classical kernels such as the radial basis function.
- Quantum kernel training can produce isolated competitive results but incurs orders-of-magnitude higher computational cost.
- Hardware execution of quantum kernels can maintain fidelity above 0.97 on current devices for the tested circuits.
Where Pith is reading between the lines
- Extending the benchmark to datasets with explicit high-dimensional structure or known quantum-friendly correlations could reveal conditions under which the current spectral mismatch disappears.
- Repeating the study with adaptive feature maps that target intermediate eigenvalue profiles would provide a direct test of the mechanistic explanation offered by the spectral analysis.
Load-bearing premise
The nine chosen datasets and four quantum feature maps are representative of the situations in which quantum kernel methods could show an advantage on tabular data.
What would settle it
A new dataset or feature map on which at least one quantum kernel achieves a statistically significant accuracy improvement over the strongest classical baseline under identical nested cross-validation.
Figures








read the original abstract
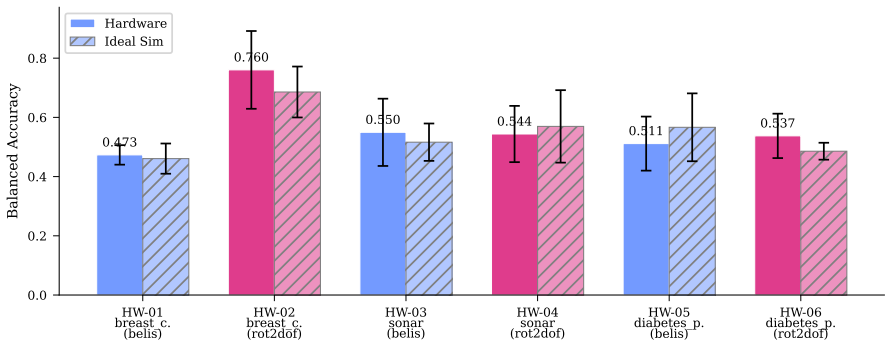
Quantum kernel methods have been proposed as a promising approach for leveraging near-term quantum computers for supervised learning, yet rigorous benchmarks against strong classical baselines remain scarce. We present a comprehensive empirical study of quantum kernel support vector machines (QSVMs) across nine binary classification datasets, four quantum feature maps, three classical kernels, and multiple noise models, totalling 970 experiments with strict nested cross-validation. Our analysis spans four phases: (i) statistical significance testing, revealing that none of 29 pairwise quantum-classical comparisons reach significance at $\alpha = 0.05$; (ii) learning curve analysis over six training fractions, showing steeper quantum slopes on six of eight datasets that nonetheless fail to close the gap to the best classical baseline; (iii) hardware validation on IBM ibm_fez (Heron r2), demonstrating kernel fidelity $r \geq 0.976$ across six experiments; and (iv) seed sensitivity analysis confirming reproducibility (mean CV 1.4%). A Kruskal-Wallis factorial analysis reveals that dataset choice dominates performance variance ($\varepsilon^2 = 0.73$), while kernel type accounts for only 9%. Spectral analysis offers a mechanistic explanation: current quantum feature maps produce eigenspectra that are either too flat or too concentrated, missing the intermediate profile of the best classical kernel, the radial basis function (RBF). Quantum kernel training (QKT) via kernel-target alignment yields the single competitive result -- balanced accuracy 0.968 on breast cancer -- but with ~2,000x computational overhead. Our findings provide actionable guidelines for quantum kernel research. The complete benchmark suite is publicly available to facilitate reproduction and extension.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a large-scale empirical benchmark of quantum kernel support vector machines (QSVMs) on nine tabular binary classification datasets using four quantum feature maps, three classical kernels, and 970 total experiments under strict nested cross-validation. It finds that none of the 29 pairwise quantum-classical comparisons reach statistical significance at α=0.05, that dataset identity accounts for 73% of performance variance while kernel type accounts for only 9%, that learning curves show steeper but non-closing quantum slopes, and that hardware execution on IBM Heron yields kernel fidelity r≥0.976. Spectral analysis is offered to explain why current quantum maps fail to match the RBF kernel's intermediate eigenspectrum; quantum kernel training is noted as the sole competitive case but at ~2000× overhead. A public benchmark suite is released.
Significance. If the negative result holds, the work supplies a high-quality reference benchmark that tempers expectations for near-term quantum kernels on tabular data and supplies concrete spectral diagnostics plus reproducible code. The combination of nested CV, Kruskal-Wallis decomposition, learning-curve analysis, hardware fidelity checks, and seed-sensitivity verification constitutes a falsifiable, reproducible empirical contribution that the field can directly extend.
minor comments (3)
- §4.2 and Figure 3: the learning-curve panels would benefit from explicit shading for the standard deviation across the five outer folds rather than only mean lines, to make the overlap with classical baselines visually clearer.
- Table 2: the column headers for the four quantum feature maps are abbreviated (e.g., “ZZ”, “Pauli”) without a footnote reminding the reader of the exact circuit depth and entanglement structure used; adding this would aid reproducibility.
- §5.3: the statement that “dataset choice dominates” is supported by ε²=0.73, but the text does not report the corresponding partial η² or the full ANOVA table; including the complete factorial decomposition would strengthen the variance-partition claim.
Simulated Author's Rebuttal
We thank the referee for their positive and thorough review, which accurately summarizes the scope, methodology, and findings of our benchmark study. The recommendation to accept is appreciated, as is the recognition of the reproducibility measures (nested CV, seed sensitivity, public code release) and the mechanistic spectral analysis. No major comments were raised that require rebuttal or revision.
Circularity Check
No significant circularity identified
full rationale
The paper is a purely empirical benchmark study reporting results from 970 experiments on public datasets using nested cross-validation, Kruskal-Wallis variance decomposition, learning curves, and hardware fidelity checks. All performance claims (e.g., no pairwise significance at α=0.05, ε²=0.73 for dataset vs. 9% for kernel) are direct statistical outputs from external baselines and standard tests; none reduce by the paper's own equations or self-citations to fitted inputs or self-referential quantities. The design tests its stated scope without internal contradiction or load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Performance metrics across folds and seeds follow distributions amenable to Kruskal-Wallis and pairwise significance testing
Reference graph
Works this paper leans on
-
[1]
Towards a realistic track reconstruction algorithm based on graph neural networks for the HL-LHC
doi:10.1051/epjconf/202125103070. Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. Quantum machine learning.Nature, 549(7671):195–202,
-
[2]
Quantum machine learning.Nature, 549(7671):195–202, Sep 2017
doi:10.1038/nature23474. Christopher M. Bishop. Training with noise is equivalent to Tikhonov regularization.Neural Computation, 7(1):108–116, 1995.doi:10.1162/neco.1995.7.1.108. Gavin C. Cawley and Nicola L. C. Talbot. On over-fitting in model selection and subsequent selection bias in performance evaluation.Journal of Machine Learning Research, 11:2079– 2107,
-
[3]
Corinna Cortes and Vladimir Vapnik. Support-vector networks.Machine Learning, 20(3): 273–297, 1995.doi:10.1007/BF00994018. Corinna Cortes, Mehryar Mohri, and Afshin Rostamizadeh. Algorithms for learning kernels based on centered alignment.Journal of Machine Learning Research, 13:795–828,
-
[4]
ics.uci.edu/ml
URLhttps://archive. ics.uci.edu/ml. Accessed: 2025-01-15. Milton Friedman. The use of ranks to avoid the assumption of normality implicit in the anal- ysis of variance.Journal of the American Statistical Association, 32(200):675–701,
2025
-
[5]
Journal of the American Statistical Association , volume =
doi:10.1080/01621459.1937.10503522. Jennifer R. Glick, Tanvi P. Gujarati, Antonio D. C´ orcoles, Youngseok Kim, Abhinav Kandala, Jay M. Gambetta, and Kristan Temme. Covariant quantum kernels for data with group structure.Nature Physics, 20:479–483, 2024.doi:10.1038/s41567-023-02340-9. Vojtˇ ech Havl´ ıˇ cek, Antonio D. C´ orcoles, Kristan Temme, Aram W. H...
-
[6]
doi:10.1103/PhysRevA.106.052421. 43 Hsin-Yuan Huang, Michael Broughton, Masoud Mohseni, Ryan Babbush, Sergio Boixo, Hart- mut Neven, and Jarrod R. McClean. Power of data in quantum machine learning.Nature Communications, 12(1):2631, 2021.doi:10.1038/s41467-021-22539-9. Thomas Hubregtsen, David Wierichs, Elies Gil-Fuster, Peter-Jan H. S. Derks, Paul K. Fae...
-
[7]
Training quantum embedding kernels on near-term quantum computers
doi:10.1103/PhysRevA.106.042431. IBM Quantum. IBM quantum platform.https://quantum.ibm.com,
-
[8]
Ali Javadi-Abhari, Matthew Treinish, Kevin Krsulich, Christopher J. Wood, Jake Lish- man, Julien Gacon, Simon Martiel, Paul D. Nation, Lev S. Bishop, Andrew W. Cross, Blake R. Johnson, and Jay M. Gambetta. Quantum computing with Qiskit.arXiv preprint arXiv:2405.08810,
work page internal anchor Pith review arXiv
-
[9]
doi:10.1080/01621459.1952.10483441. Jonas M. K¨ ubler, Simon Buchholz, and Bernhard Sch¨ olkopf. The inductive bias of quantum kernels. InAdvances in Neural Information Processing Systems, volume 34, pages 12661– 12673, Red Hook, NY,
-
[10]
Learning the parts of objects by non-negative matrix factorization.Nature1999, 401, 788–791
Curran Associates, Inc. Daniel D. Lee and H. Sebastian Seung. Learning the parts of objects by non-negative matrix factorization.Nature, 401(6755):788–791, 1999.doi:10.1038/44565. Yunchao Liu, Srinivasan Arunachalam, and Kristan Temme. A rigorous and robust quan- tum speed-up in supervised machine learning.Nature Physics, 17:1013–1017,
-
[11]
doi:10.1038/s41567-021-01287-z. Fabian Pedregosa, Ga¨ el Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and ´Edouard Duchesnay. Scikit-learn: Machine learning in Python.J...
-
[12]
Patrick Rebentrost, Masoud Mohseni, and Seth Lloyd
doi:10.1038/s41534-021-00498-9. Patrick Rebentrost, Masoud Mohseni, and Seth Lloyd. Quantum support vector ma- chine for big data classification.Physical Review Letters, 113(13):130503,
-
[13]
Alona Sakhnenko, Corey O’Meara, Kumar J
doi:10.1103/PhysRevLett.113.130503. Alona Sakhnenko, Corey O’Meara, Kumar J. B. Ghosh, Christian B. Mendl, Giorgio Cortiana, and Juan Bernab´ e-Moreno. Hybrid classical-quantum autoencoder for anomaly detection. Quantum Machine Intelligence, 4(2):27, 2022.doi:10.1007/s42484-022-00075-z. 44 Jan Schnabel and Marco Roth. Quantum kernel methods under scrutiny...
-
[14]
Quantum machine learning in feature Hilbert spaces
Maria Schuld and Nathan Killoran. Quantum machine learning in feature Hilbert spaces.Phys- ical Review Letters, 122(4):040504, 2019.doi:10.1103/PhysRevLett.122.040504. John Shawe-Taylor and Nello Cristianini.Kernel Methods for Pattern Analysis. Cambridge University Press, Cambridge, UK, 2004.doi:10.1017/CBO9780511809682. Ruslan Shaydulin and Stefan M. Wil...
-
[15]
doi:10.1038/s41467-024-49287-w. Joaquin Vanschoren, Jan N. van Rijn, Bernd Bischl, and Luis Torgo. OpenML: Networked science in machine learning.ACM SIGKDD Explorations Newsletter, 15(2):49–60,
-
[16]
URL https://dl.acm.org/doi/10.1145/2641190.2641198
doi:10.1145/2641190.2641198. Vladimir N. Vapnik.Statistical Learning Theory. Wiley-Interscience, New York,
-
[17]
Bias in error estimation when using cross- validation for model selection,
Sudhir Varma and Richard Simon. Bias in error estimation when using cross-validation for model selection.BMC Bioinformatics, 7(1):91, 2006.doi:10.1186/1471-2105-7-91. Frank Wilcoxon. Individual comparisons by ranking methods.Biometrics Bulletin, 1(6):80–83, 1945.doi:10.2307/3001968. 45
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.