Recognition: unknown
FlowForge: A Staged Local Rollout Engine for Flow-Field Prediction
Pith reviewed 2026-05-10 03:11 UTC · model grok-4.3
The pith
FlowForge predicts flow fields by compiling locality-preserving stages and running them with a shared lightweight local predictor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlowForge rewrites spatial sites stage by stage so that each update conditions only on bounded local context exposed by earlier stages. It compiles a locality-preserving update schedule from the spatial sites and executes that schedule with a shared lightweight local predictor. The resulting compile-execute design aligns inference with short-range physical dependence, keeps latency predictable, and limits error amplification from global mixing.
What carries the argument
The staged local rollout engine that compiles a locality-preserving update schedule and executes it with a shared lightweight local predictor.
Load-bearing premise
That updates based on bounded local context alone can be executed without losing global physical consistency or creating artifacts in complex multi-scale flows.
What would settle it
Long multi-step rollouts on a complex flow benchmark that show faster growth in pointwise error or visible physical violations compared with a strong global baseline.
Figures


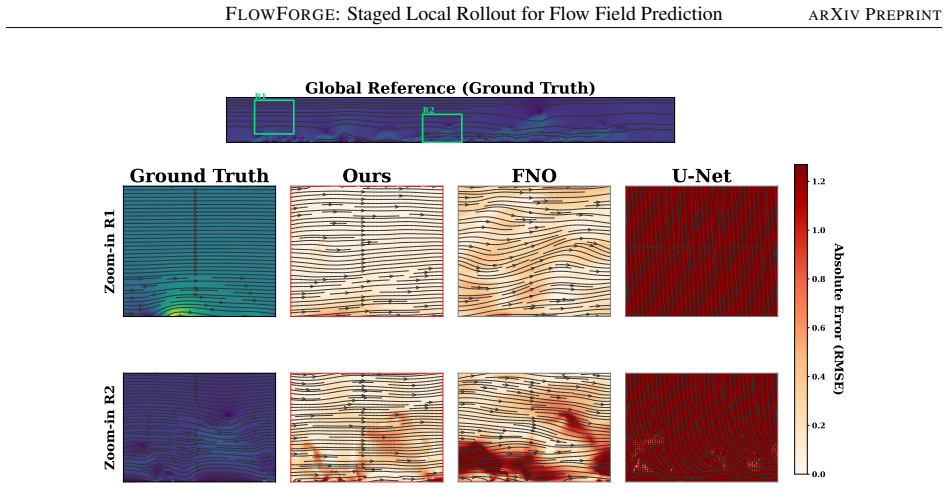

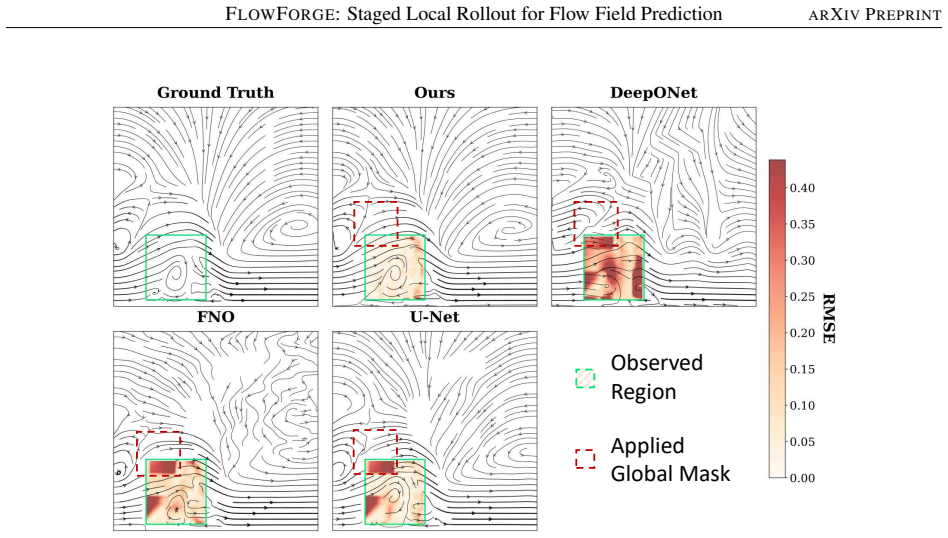
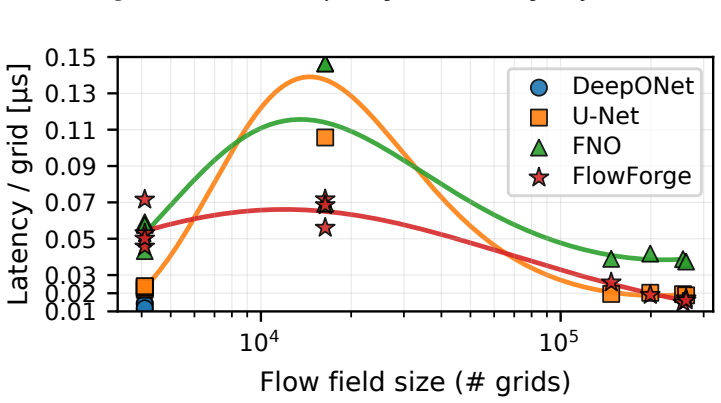







read the original abstract
Deep learning surrogates for CFD flow-field prediction often rely on large, complex models, which can be slow and fragile when data are noisy or incomplete. We introduce FlowForge, a staged local rollout engine that predicts future flow fields by compiling a locality-preserving update schedule and executing it with a shared lightweight local predictor. Rather than producing the next frame in a single global pass, FlowForge rewrites spatial sites stage by stage so that each update conditions only on bounded local context exposed by earlier stages. This compile-execute design aligns inference with short-range physical dependence, keeps latency predictable, and limits error amplification from global mixing. Across PDEBench, CFDBench, and BubbleML, FlowForge matches or improves upon strong baselines in pointwise accuracy, delivers consistently better robustness to noise and missing observations, and maintains stable multi-step rollout behavior while reducing per-step latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowForge, a staged local rollout engine for CFD flow-field prediction. It compiles a locality-preserving update schedule from spatial sites and executes it with a shared lightweight local predictor, so that each update conditions only on bounded local context from prior stages. The central claim is that this design matches or exceeds strong baselines on PDEBench, CFDBench, and BubbleML in pointwise accuracy, delivers better robustness to noise and missing observations, maintains stable multi-step rollouts, and reduces per-step latency.
Significance. If the performance and stability claims hold under detailed scrutiny, the compile-execute locality approach could offer a practical alternative to large global models for surrogate CFD, with advantages in predictable latency and reduced error amplification. The emphasis on aligning inference with short-range physical dependence is a clear conceptual strength.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): the central claim that a shared lightweight local predictor plus compile-time locality schedule produces stable multi-step rollouts requires that all relevant non-local dependencies (pressure projection in incompressible NS, long-range correlations in turbulence) are captured inside the bounded neighborhood at each stage. No description is given of how the predictor is trained (e.g., with PDE residuals, divergence penalties, or conservation constraints), so pointwise accuracy on clean data does not guarantee global consistency.
- [§4] §4 (Experiments): the reported improvements in robustness and multi-step stability across PDEBench, CFDBench, and BubbleML are stated without quantitative tables, ablation studies on neighborhood size, error accumulation plots, or analysis of invariant drift (e.g., divergence error over time). This absence makes it impossible to verify that local staged updates do not introduce artifacts invisible to pointwise MSE.
- [§3.2] §3.2 (Update schedule): the claim that the locality-preserving schedule limits error amplification is load-bearing for the latency and stability advantages, yet no formal argument or empirical test is supplied showing that the schedule preserves global physical consistency when the local predictor is applied repeatedly.
minor comments (2)
- [Abstract] Abstract: the phrase 'compile-execute design' is used without a one-sentence illustration of how the schedule is generated from spatial sites.
- [§3] Notation: the distinction between 'stage' and 'step' in the rollout description should be defined explicitly on first use to avoid ambiguity in multi-step experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for clarification and additional validation, which we will address through targeted revisions to strengthen the presentation of the method, experiments, and supporting analysis.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): the central claim that a shared lightweight local predictor plus compile-time locality schedule produces stable multi-step rollouts requires that all relevant non-local dependencies (pressure projection in incompressible NS, long-range correlations in turbulence) are captured inside the bounded neighborhood at each stage. No description is given of how the predictor is trained (e.g., with PDE residuals, divergence penalties, or conservation constraints), so pointwise accuracy on clean data does not guarantee global consistency.
Authors: We agree that the manuscript would benefit from expanded details on training and information propagation. The local predictor is trained via supervised regression on ground-truth local patches extracted from the simulation datasets using an MSE loss; no explicit PDE residuals or conservation penalties are included, as the approach is purely data-driven. The staged schedule propagates information across the domain by design, as each stage exposes updated values to neighboring sites in subsequent stages, allowing non-local effects (such as pressure influences) to be captured through sequential local conditioning. In the revision we will add a dedicated paragraph in §3 describing the training procedure, loss function, and data preparation, together with a short discussion and illustrative diagram showing how multi-stage updates enable effective long-range dependence without global mixing. revision: yes
-
Referee: [§4] §4 (Experiments): the reported improvements in robustness and multi-step stability across PDEBench, CFDBench, and BubbleML are stated without quantitative tables, ablation studies on neighborhood size, error accumulation plots, or analysis of invariant drift (e.g., divergence error over time). This absence makes it impossible to verify that local staged updates do not introduce artifacts invisible to pointwise MSE.
Authors: We acknowledge that the current experimental section would be strengthened by more granular quantitative evidence. While comparative pointwise results are presented, we will augment §4 with full numerical tables reporting all metrics, neighborhood-size ablations, multi-step error-accumulation curves, and invariant-drift analysis (divergence error for incompressible cases and mass conservation for BubbleML). These additions will directly address the concern about potential hidden artifacts and allow readers to assess robustness and stability beyond aggregate accuracy figures. revision: yes
-
Referee: [§3.2] §3.2 (Update schedule): the claim that the locality-preserving schedule limits error amplification is load-bearing for the latency and stability advantages, yet no formal argument or empirical test is supplied showing that the schedule preserves global physical consistency when the local predictor is applied repeatedly.
Authors: The schedule is constructed via a compile-time graph traversal that guarantees each local update depends only on a bounded, previously updated neighborhood; this structural property inherently restricts immediate error spread. A general formal proof of global consistency would require strong assumptions on predictor accuracy that do not hold for learned models, so we do not attempt one. Instead, we will add empirical validation in the revision by reporting global consistency metrics (divergence drift, total variation) over long rollouts and direct comparisons of error-amplification rates against global baselines. These tests will be placed in §4 alongside the existing stability results. revision: partial
Circularity Check
No circularity: FlowForge is introduced as an independent architectural design validated empirically on benchmarks.
full rationale
The paper presents FlowForge as a new staged local rollout engine that compiles a locality-preserving update schedule executed by a shared lightweight local predictor. Performance claims (matching or improving baselines on PDEBench, CFDBench, BubbleML in accuracy, robustness, and latency) rest on empirical comparisons rather than any derived quantity that reduces to fitted inputs or self-citations by construction. No equations, self-definitional steps, or load-bearing self-citations appear in the provided description; the central premise is a proposed engineering schedule whose correctness is tested externally against global baselines and physical datasets. This is the common case of a self-contained architectural contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Steven L. Brunton, Bernd R. Noack, and Petros Koumoutsakos. Machine learning for fluid mechanics.Annual Review of Fluid Mechanics, 52:477–508, 2020. doi:10.1146/annurev-fluid-010719-060214. URL https://www.annualreviews.org/doi/10.1146/annurev-fluid-010719-060214
-
[2]
Andrea Sciacchitano. Uncertainty quantification in particle image velocimetry.Measurement Science and Technology, 30(9):092001, 2019. doi:10.1088/1361-6501/ab1db8. URL https://iopscience.iop.org/article/10.1088/1361-6501/ab1db8
-
[3]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3:218–229, 2021. doi:10.1038/s42256-021-00302-5. URL https://www.nature.com/articles/s42256-021-00302-5
-
[4]
U -Net: Convolutional Networks for Biomedical Image Segmentation,
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing. URL https://link.springer.com/chapter/10.1007/978-3-319-24574-4_28. 11 FLOWFORGE: Staged Local Rollout...
-
[5]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=c8P9NQVtmnO
2021
-
[6]
M. Raissi, P. Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019. ISSN 0021-9991. doi:https://doi.org/10.1016/j.jcp.2018.10.045. URL https://www.sciencedirect.com/science...
-
[7]
Dpot: auto-regressive denoising operator transformer for large-scale pde pre-training
Zhongkai Hao, Chang Su, Songming Liu, Julius Berner, Chengyang Ying, Hang Su, Anima Anandkumar, Jian Song, and Jun Zhu. Dpot: auto-regressive denoising operator transformer for large-scale pde pre-training. In Proceedings of the 41st International Conference on Machine Learning, ICML’24, 2024. doi:10.5555/3692070.3692773. URLhttps://dl.acm.org/doi/10.5555...
-
[8]
PDEformer: Towards a foundation model for one-dimensional partial differential equations
Zhanhong Ye, Xiang Huang, Leheng Chen, Hongsheng Liu, Zidong Wang, and Bin Dong. PDEformer: Towards a foundation model for one-dimensional partial differential equations. InICLR 2024 Workshop on AI4DifferentialEquations In Science, 2024. URLhttps://openreview.net/forum?id=GLDMCwdhTK
2024
-
[9]
Unisolver: PDE-conditional transformers are universal PDE solvers, 2025
Hang Zhou, Yuezhou Ma, Haixu Wu, Haowen Wang, and Mingsheng Long. Unisolver: PDE-conditional transformers are universal PDE solvers, 2025. URLhttps://openreview.net/forum?id=f3xXPDCh8Q
2025
-
[10]
David M. Knlgge, David R. Wessels, Riccardo Valperga, Samuele Papa, Jan-Jakob Sonke, Efstratios Gavves, and Erik J. Bekkers. Space-time continuous pde forecasting using equivariant neural fields. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, 2024. ISBN 9798331314385. doi:10.5555/3737916.3740354. URL...
-
[11]
Worrall, and Max Welling
Johannes Brandstetter, Daniel E. Worrall, and Max Welling. Message passing neural PDE solvers. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=vSix3HPYKSU
2022
-
[12]
Towards stability of autoregressive neural operators.Transactions on Machine Learning Research, 2023
Michael McCabe, Peter Harrington, Shashank Subramanian, and Jed Brown. Towards stability of autoregressive neural operators.Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=RFfUUtKYOG
2023
-
[13]
AmirPouya Hemmasian and Amir Barati Farimani. Multi-scale time-stepping of partial differential equations with transformers.Computer Methods in Applied Mechanics and Engineering, 426:116983, 2024. ISSN 0045-7825. doi:https://doi.org/10.1016/j.cma.2024.116983. URL https://www.sciencedirect.com/science/article/pii/S0045782524002391
-
[14]
On the benefits of memory for modeling time-dependent PDEs
Ricardo Buitrago, Tanya Marwah, Albert Gu, and Andrej Risteski. On the benefits of memory for modeling time-dependent PDEs. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=o9kqa5K3tB
2025
-
[15]
Waleed Diab and Mohammed Al Kobaisi. Temporal neural operator for modeling time-dependent physical phenomena.Scientific Reports, 15(1):32791, 2025. doi:10.1038/s41598-025-16922-5. URL https://doi.org/10.1038/s41598-025-16922-5
-
[16]
Multipole graph neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Multipole graph neural operator for parametric partial differential equations. InProceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, 2020. URL https://dl.acm.org/doi/10.5555/3495724.3496291
-
[17]
Fourier neural operator with learned deformations for pdes on general geometries.J
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier neural operator with learned deformations for pdes on general geometries.J. Mach. Learn. Res., January 2023. URL https://dl.acm.org/doi/10.5555/3648699.3649087
-
[18]
Geometry-informed neural operator for large-scale 3d pdes
Zongyi Li, Nikola Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Mohammad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, and Animashree Anandkumar. Geometry-informed neural operator for large-scale 3d pdes. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information...
2023
-
[19]
Convolutional neural operators for robust and accurate learning of PDEs
Bogdan Raonic, Roberto Molinaro, Tim De Ryck, Tobias Rohner, Francesca Bartolucci, Rima Alaifari, Siddhartha Mishra, and Emmanuel de Bezenac. Convolutional neural operators for robust and accurate learning of PDEs. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=MtekhXRP4h. 12 FLOWFORGE: Stag...
2023
-
[20]
Factorized fourier neural operators
Alasdair Tran, Alexander Mathews, Lexing Xie, and Cheng Soon Ong. Factorized fourier neural operators. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=tmIiMPl4IPa
2023
-
[21]
U-NO: U-shaped neural operators
Md Ashiqur Rahman, Zachary E Ross, and Kamyar Azizzadenesheli. U-NO: U-shaped neural operators. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=j3oQF9coJd
2023
-
[22]
Gnot: a general neural operator transformer for operator learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. Gnot: a general neural operator transformer for operator learning. InProceedings of the 40th International Conference on Machine Learning, ICML’23, 2023. URL https://dl.acm.org/doi/10.5555/3618408.3618917
-
[23]
Improved operator learning by orthogonal attention, 2024
Zipeng Xiao, Zhongkai Hao, Bokai Lin, Zhijie Deng, and Hang Su. Improved operator learning by orthogonal attention, 2024. URLhttps://openreview.net/forum?id=mt5NPvTp5a
2024
-
[24]
HT-net: Hierarchical transformer based operator learning model for multiscale PDEs, 2023
Xinliang Liu, Bo Xu, and Lei Zhang. HT-net: Hierarchical transformer based operator learning model for multiscale PDEs, 2023. URLhttps://openreview.net/forum?id=UY5zS0OsK2e
2023
-
[25]
Transolver: a fast transformer solver for pdes on general geometries
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: a fast transformer solver for pdes on general geometries. InProceedings of the 41st International Conference on Machine Learning, ICML’24, 2024. URLhttps://dl.acm.org/doi/10.5555/3692070.3694270
-
[26]
Hamlet: graph transformer neural operator for partial differential equations
Andrey Bryutkin, Jiahao Huang, Zhongying Deng, Guang Yang, Carola-Bibiane Schönlieb, and Angelica Aviles-Rivero. Hamlet: graph transformer neural operator for partial differential equations. InProceedings of the 41st International Conference on Machine Learning, ICML’24, 2024. URL https://dl.acm.org/doi/10.5555/3692070.3692256
-
[27]
Poseidon: Efficient foundation models for PDEs
Maximilian Herde, Bogdan Raonic, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Emmanuel de Bezenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for PDEs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=JC1VKK3UXk
2024
-
[28]
Operator learning with neural fields: Tackling PDEs on general geometries
Louis Serrano, Lise Le Boudec, Armand Kassaï Koupaï, Thomas X Wang, Yuan Yin, Jean-Noël Vittaut, and patrick gallinari. Operator learning with neural fields: Tackling PDEs on general geometries. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=4jEjq5nhg1
2023
-
[29]
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Dan MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. PDEBench Datasets, 2022. URLhttps://doi.org/10.18419/darus-2986
-
[30]
Towards multi-spatiotemporal-scale generalized PDE modeling
Jayesh K Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized PDE modeling. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=dPSTDbGtBY
2023
-
[31]
Luo Yining, Chen Yingfa, and Zhang Zhen. Cfdbench: A large-scale benchmark for machine learning methods in fluid dynamics. 2023. URLhttps://arxiv.org/abs/2310.05963
-
[32]
BubbleML: A multi-physics dataset and benchmarks for machine learning
Sheikh Md Shakeel Hassan, Arthur Feeney, Akash Dhruv, Jihoon Kim, Youngjoon Suh, Jaiyoung Ryu, Yoonjin Won, and Aparna Chandramowlishwaran. BubbleML: A multi-physics dataset and benchmarks for machine learning. InAdvances in Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=0Wmglu8zak
2023
-
[33]
APEBench: A benchmark for autoregressive neural emulators of PDEs
Felix Koehler, Simon Niedermayr, rüdiger westermann, and Nils Thuerey. APEBench: A benchmark for autoregressive neural emulators of PDEs. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/forum?id=iWc0qE116u. 13 FLOWFORGE: Staged Local Rollout for Flow Field PredictionARXI...
2024
-
[34]
Warm-up Phase (t <30 ):In the initial steps, locality-preserving orders (Outward Spiral, Raster Scan, Hilbert Curve) maintain a consistent dt = 1 (adjacent pixels), whereas Random ordering exhibits high variance and larger average distances (dt >1), as early points are scattered sparsely across the grid
-
[35]
Consequently, the dt for Random ordering rapidly decays and converges to the same baseline (dt ≈1 ), providing similar context vectors as the locality-preserving orders
Stable Phase (t≥30 ):As the grid becomes populated, the probability of a randomly selected target location falling within the immediate neighborhood of an existing point increases distinctly. Consequently, the dt for Random ordering rapidly decays and converges to the same baseline (dt ≈1 ), providing similar context vectors as the locality-preserving ord...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.