Recognition: unknown
RL-ABC: Reinforcement Learning for Accelerator Beamline Control
Pith reviewed 2026-05-10 03:15 UTC · model grok-4.3
The pith
A Python framework converts Elegant beamline files into reinforcement learning environments, enabling agents to optimize particle transmission in accelerators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Beamline tuning can be cast as a Markov decision process by automatically inserting watch points before each tunable element in Elegant files, constructing states from beam statistics covariance and aperture data, and defining transmission-based rewards; a Deep Deterministic Policy Gradient agent trained in this environment achieves 70.3 percent particle transmission on a 37-parameter test beamline derived from the VEPP-5 injection complex, matching the performance of differential evolution.
What carries the argument
Automatic transformation of Elegant lattice files into Gym-compatible environments that insert diagnostic watch points, generate 57-dimensional states from beam moments and constraints, and expose configurable transmission rewards.
If this is right
- Beamline optimization tasks become directly usable by RL practitioners without writing custom environment code.
- Stage learning decomposes large tuning problems into sequential subproblems that train more efficiently.
- Stable-Baselines3 compatibility lets users swap in different RL algorithms for the same beamline setup.
- Performance on simulation matches established numerical optimizers such as differential evolution.
Where Pith is reading between the lines
- The same automatic conversion approach could be extended to other widely used beam-dynamics codes beyond Elegant.
- Successful simulation results raise the question of whether policies can be fine-tuned or transferred directly onto operating accelerators.
- Multi-objective reward functions could be explored to optimize not only transmission but also beam quality metrics simultaneously.
- Testing the framework on beamlines with different numbers of elements or lattice types would check how general the preprocessing method remains.
Load-bearing premise
Policies optimized inside the Elegant-based simulation will produce comparable transmission results when applied to real accelerator hardware.
What would settle it
Running the trained RL policy on the physical VEPP-5 injection complex and recording whether particle transmission reaches or falls short of the simulated 70.3 percent.
Figures


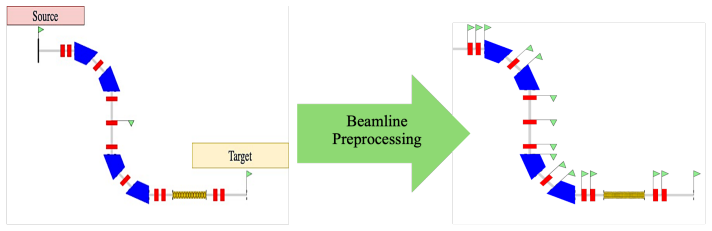






read the original abstract
Particle accelerator beamline optimization is a high-dimensional control problem traditionally requiring significant expert intervention. We present RLABC (Reinforcement Learning for Accelerator Beamline Control), an open-source Python framework that automatically transforms standard Elegant beamline configurations into reinforcement learning environments. RLABC integrates with the widely-used Elegant beam dynamics simulation code via SDDS-based interfaces, enabling researchers to apply modern RL algorithms to beamline optimization with minimal RL-specific development. The main contribution is a general methodology for formulating beamline tuning as a Markov decision process: RLABC automatically preprocesses lattice files to insert diagnostic watch points before each tunable element, constructs a 57-dimensional state representation from beam statistics, covariance information, and aperture constraints, and provides a configurable reward function for transmission optimization. The framework supports multiple RL algorithms through Stable-Baselines3 compatibility and implements stage learning strategies for improved training efficiency. Validation on a test beamline derived from the VEPP-5 injection complex (37 control parameters across 11 quadrupoles and 4 dipoles) demonstrates that the framework successfully enables RL-based optimization, with a Deep Deterministic Policy Gradient agent achieving 70.3\% particle transmission -- performance matching established methods such as differential evolution. The framework's stage learning capability allows decomposition of complex optimization problems into manageable subproblems, improving training efficiency. The complete framework, including configuration files and example notebooks, is available as open-source software to facilitate adoption and further research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RLABC, an open-source Python framework that automatically converts standard Elegant beamline lattice files into reinforcement learning environments for high-dimensional accelerator optimization. It describes a general MDP formulation that inserts diagnostic watch points before tunable elements, builds a 57-dimensional state from beam statistics, covariance matrices, and aperture constraints, and supplies a configurable reward focused on transmission. On a 37-parameter test beamline derived from the VEPP-5 injection complex, a DDPG agent (via Stable-Baselines3) reaches 70.3% particle transmission, reported to match differential evolution; stage-wise learning is introduced to improve training efficiency.
Significance. If the empirical result is shown to be robust, the framework would lower the barrier to applying modern RL methods to beamline tuning by automating environment construction from existing Elegant files and providing Stable-Baselines3 compatibility. The open-source release together with example notebooks and configuration files constitutes a concrete, reusable contribution that could accelerate experimentation in accelerator physics.
major comments (1)
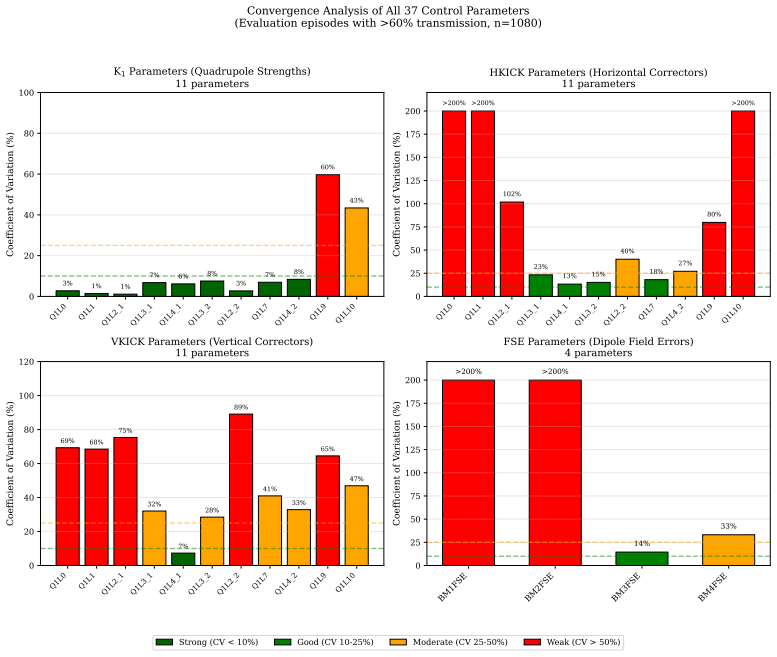
- [Validation section (VEPP-5 test beamline results)] Validation section (VEPP-5 test beamline results): the central performance claim of 70.3% transmission matching differential evolution is presented as a single scalar without reported training variance, number of independent random seeds, error bars, or any statistical test comparing the two methods. This single-run reporting is load-bearing for the assertion that the RL agent 'matches established methods.'
minor comments (2)
- [Methodology] The exact composition of the 57-dimensional state vector (breakdown of beam statistics, covariance elements, and aperture features) is described only at a high level; an explicit table or equation listing the 57 components would improve reproducibility.
- [Results / Experiments] Stage learning is mentioned in the abstract and introduction as improving efficiency, yet no quantitative comparison (e.g., episodes to convergence with vs. without staging) appears in the results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the framework's contributions. We address the single major comment below.
read point-by-point responses
-
Referee: Validation section (VEPP-5 test beamline results): the central performance claim of 70.3% transmission matching differential evolution is presented as a single scalar without reported training variance, number of independent random seeds, error bars, or any statistical test comparing the two methods. This single-run reporting is load-bearing for the assertion that the RL agent 'matches established methods.'
Authors: We agree that a single scalar value without variance, multiple seeds, error bars, or statistical comparison weakens the robustness of the claim that the DDPG agent matches differential evolution. The 70.3% figure originated from one representative training run in the current manuscript. In the revised version we will conduct at least five independent training runs with distinct random seeds, report the mean and standard deviation of the final transmission, add error bars to the relevant performance figure, and include a brief statistical comparison (e.g., a t-test) against the differential-evolution baseline. These additions will be placed in the validation section and will not alter the paper's primary focus on the RL-ABC framework. revision: yes
Circularity Check
No significant circularity in derivation or validation chain
full rationale
The paper's central contribution is an engineering framework that automatically converts Elegant lattice files into RL environments via preprocessing, watch-point insertion, 57-dimensional state construction from beam statistics, and a configurable reward. The reported 70.3% transmission is an empirical outcome obtained by running a trained DDPG policy inside the resulting simulation; it is not obtained by algebraic reduction, parameter fitting that is then renamed as prediction, or any self-referential equation. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling is present. The validation therefore stands as independent numerical evidence rather than a tautology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Elegant beam dynamics simulations provide a sufficiently accurate model for training RL policies that will transfer to real hardware.
- domain assumption The automatically generated 57-dimensional state vector (beam statistics, covariance, aperture constraints) is Markovian and adequate for the control task.
Reference graph
Works this paper leans on
-
[1]
Borland, Elegant: A flexible sdds-compliant code for accelerator sim- ulation, Tech
M. Borland, Elegant: A flexible sdds-compliant code for accelerator sim- ulation, Tech. rep., Argonne National Lab., IL (US) (2000)
2000
-
[2]
Lee, Accelerator physics, World Scientific Publishing Company, 2018
S.-Y. Lee, Accelerator physics, World Scientific Publishing Company, 2018
2018
-
[3]
Wiedemann, Particle accelerator physics, Springer Nature, 2015
H. Wiedemann, Particle accelerator physics, Springer Nature, 2015. 30
2015
-
[4]
A. W. Chao, K. H. Mess, M. Tigner, F. Zimmermann (Eds.), Handbook of accelerator physics and engineering: 2nd Edition, 2nd Edition, World Scientific, Hackensack, USA, 2013. doi:10.1142/8543
-
[5]
Wolski, Beam dynamics in high energy particle accelerators, World Scientific, 2014
A. Wolski, Beam dynamics in high energy particle accelerators, World Scientific, 2014
2014
-
[6]
J. A. Nelder, R. Mead, A simplex method for function minimization, The computer journal 7 (4) (1965) 308–313
1965
-
[7]
Pelikan, Bayesian optimization algorithm, in: Hierarchical Bayesian optimization algorithm: toward a new generation of evolutionary algo- rithms, Springer, 2005, pp
M. Pelikan, Bayesian optimization algorithm, in: Hierarchical Bayesian optimization algorithm: toward a new generation of evolutionary algo- rithms, Springer, 2005, pp. 31–48
2005
-
[8]
R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, A Bradford Book, Cambridge, MA, USA, 2018
2018
-
[9]
Kober, J
J. Kober, J. A. Bagnell, J. Peters, Reinforcement learning in robotics: A survey, The International Journal of Robotics Research 32 (11) (2013) 1238–1274
2013
-
[10]
C. Tang, B. Abbatematteo, J. Hu, R. Chandra, R. Martín-Martín, P. Stone, Deep reinforcement learning for robotics: A survey of real- world successes, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39, 2025, pp. 28694–28698
2025
-
[11]
Kendall, J
A. Kendall, J. Hawke, D. Janz, P. Mazur, D. Reda, J.-M. Allen, V.-D. Lam, A. Bewley, A. Shah, Learning to drive in a day, in: 2019 interna- tional conference on robotics and automation (ICRA), IEEE, 2019, pp. 8248–8254
2019
-
[12]
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, D. Hassabis, Human-level control through deep reinforcement learning, Nature 518 (7540) (2015) 529–533
2015
-
[13]
Nambiar, S
M. Nambiar, S. Ghosh, P. Ong, Y. E. Chan, Y. M. Bee, P. Krish- naswamy, Deep offline reinforcement learning for real-world treatment optimization applications, in: Proceedings of the 29th ACM SIGKDD 31 conference on knowledge discovery and data mining, 2023, pp. 4673– 4684
2023
-
[14]
Y. Bai, Y. Gao, R. Wan, S. Zhang, R. Song, A review of reinforcement learning in financial applications, Annual Review of Statistics and Its Application 12 (1) (2025) 209–232
2025
-
[15]
F. A. Emanov, K. V. Astrelina, V. V. Balakin, O. V. Belikov, D. E. Berkaev, Y. M. Boimelshtain, D. Y. Bolkhovityanov, A. R. Frolov, G. V. Karpov, A. S. Kasaev, A. A. Kondakov, G. Y. Kurkin, R. M. Lapik, N. N. Lebedev, A. E. Levichev, Y. I. Maltseva, A. A. Murasev, S. L. Samoylov, S. V. Vasiliev, A. Y. Martinovsky, C. V. Motygin, A. M. Pilan, A. G. Tribend...
-
[16]
R. Roussel, A. L. Edelen, T. Boltz, D. Kennedy, Z. Zhang, F. Ji, X. Huang, D. Ratner, A. Santamaria Garcia, C. Xu, et al., Bayesian optimization algorithms for accelerator physics, Physical Review Accelerators and Beams 27 (8) (2024) 084801, review of Bayesian optimization methods in accelerator physics. doi:10.1103/PhysRevAccelBeams.27.084801
-
[17]
Y. Morita, T. Washio, Y. Nakashima, Accelerator tuning method us- ing autoencoder and bayesian optimization, Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment 1057 (2023) 168730, autoencoder- assisted Bayesian optimization for high-dimensional accelerator tuning. doi:10.1016/j.ni...
-
[18]
A. Awal, J. Hetzel, R. Gebel, J. Pretz, Injection optimization at particle accelerators via reinforcement learning: From simulation to real-world application, Physical Review Accelerators and Beams 28 (3) (2025) 034601, rL framework for optimizing the injection process with SAC and live evaluation. doi:10.1103/PhysRevAccelBeams.28.034601
-
[19]
J. Kaiser, C. Xu, A. Eichler, A. Santamaria Garcia, et al., Reinforce- ment learning-trained optimisers and bayesian optimisation for online 32 particle accelerator tuning, Scientific Reports 14 (2024) 15733, com- parative study of RL and Bayesian optimization for online tuning. doi:10.1038/s41598-024-66263-y
-
[20]
J. Kaiser, C. Xu, A. Eichler, A. Santamaria Garcia, Bridging the gap be- tween machine learning and particle accelerator physics with high-speed, differentiable simulations, Physical Review Accelerators and Beams 27 (5) (2024) 054601. doi:10.1103/PhysRevAccelBeams.27.054601. URLhttps://doi.org/10.1103/PhysRevAccelBeams.27.054601
-
[21]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Sil- ver, D. Wierstra, Continuous control with deep reinforcement learning, arXiv preprint arXiv:1509.02971Presented at ICLR 2016 (2015)
work page internal anchor Pith review arXiv 2016
-
[22]
Silver, G
D. Silver, G. Lever, N. Heess, T. Degris, D. Wierstra, M. Riedmiller, Deterministic Policy Gradient Algorithms, in: ICML, Beijing, China, 2014, pp. 387–395. URLhttps://inria.hal.science/hal-00938992
2014
-
[23]
Grote, F
H. Grote, F. Schmidt, MAD-X: An upgrade from MAD8, in: Proceed- ings of the 2003 Particle Accelerator Conference, PAC 2003, IEEE, Port- land, OR, USA, 2003, pp. 3497–3499, cERN-AB-2003-024-ABP
2003
-
[24]
Floettmann, ASTRA: A Space Charge Tracking Algorithm, User’s Manual, DESY, Hamburg, Germany, version 3.2 Edition, dESY, Notkestr
K. Floettmann, ASTRA: A Space Charge Tracking Algorithm, User’s Manual, DESY, Hamburg, Germany, version 3.2 Edition, dESY, Notkestr. 85, 22603 Hamburg, Germany (March 2017). URLhttps://www.desy.de/~mpyflo/
2017
-
[25]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. D. Cola, T. Deleu, M. Goulão, A. Kallinteris, M. Krimmel, A. KG, R. Perez-Vicente, A. Pierré, S. Schulhoff, J. J. Tai, H. Tan, O. G. Younis, Gymnasium: A standard interface for reinforcement learning environments (2025). arXiv:2407.17032. URLhttps://arxiv.org/abs/2407.17032
work page internal anchor Pith review arXiv 2025
-
[26]
A. Ibrahim, A. Petrenko, M. Kaledin, E. Suleiman, F. Ratnikov, D. Derkach, Reinforcement learning for accelerator beamline control: a simulation-based approach, International Journal of Modern Physics E (2026) 2641027ArXiv:2510.26805. doi:10.1142/S0218301326410272. 33
-
[27]
Raffin, A
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, N. Dor- mann, Stable-baselines3: Reliable reinforcement learning implementa- tions, Journal of machine learning research 22 (268) (2021) 1–8
2021
-
[28]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, in: J. Dy, A. Krause (Eds.), Proceedings of the 35th International Con- ference on Machine Learning, Vol. 80 of Proceedings of Machine Learn- ing Research, PMLR, 2018, pp. 1861–1870. URLhttps://proceedings.mlr.pres...
2018
-
[29]
Storn, K
R. Storn, K. Price, Differential evolution – a simple and efficient heuris- tic for global optimization over continuous spaces, Journal of Global Optimization 11 (4) (1997) 341–359
1997
-
[30]
P. Virtanen, R. Gommers, T. E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S. J. van der Walt, M. Brett, J. Wilson, K. J. Millman, N. Mayorov, A. R. J. Nelson, E. Jones, R. Kern, E. Larson, C. J. Carey, İ. Polat, Y. Feng, E. W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.