Recognition: unknown
Empowering NPC Dialogue with Environmental Context Using LLMs and Panoramic Images
Pith reviewed 2026-05-10 01:42 UTC · model grok-4.3
The pith
Panoramic images and semantic segmentation allow LLMs to equip NPCs with spatial awareness for dialogue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
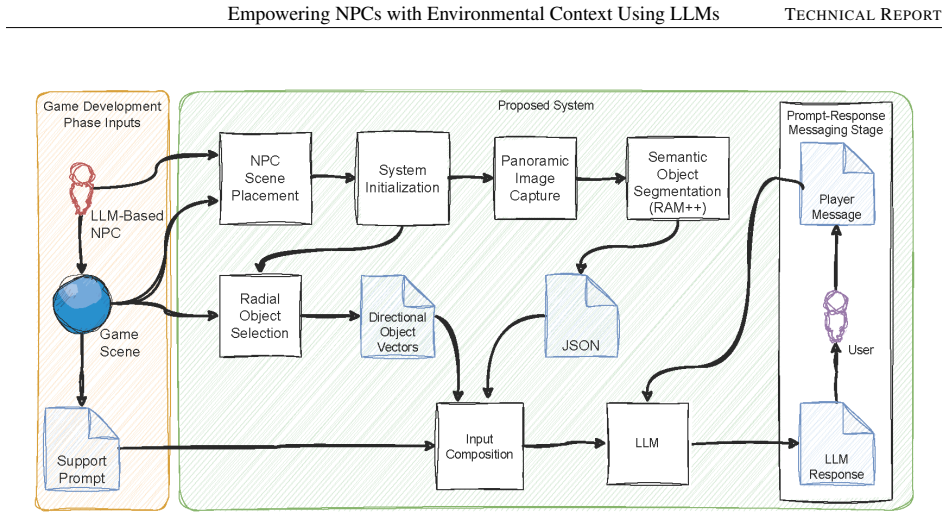
Our method captures panoramic images of an NPC's environment and applies semantic segmentation to identify objects and their spatial positions. The extracted information is used to generate a structured JSON representation of the environment, combining object locations derived from segmentation with additional scene graph data within the NPC's bounding sphere, encoded as directional vectors. This representation is provided as input to the LLM, enabling NPCs to incorporate spatial knowledge into player interactions.
What carries the argument
The structured JSON representation of the environment derived from panoramic image semantic segmentation combined with scene graph directional vectors, which is fed directly to the LLM.
If this is right
- NPCs can dynamically reference nearby objects, landmarks, and environmental features in their dialogue.
- This leads to more believable and engaging gameplay experiences.
- Participants in the user study preferred the context-aware NPCs over a non-context-aware baseline.
Where Pith is reading between the lines
- Such systems could extend to other interactive media like virtual reality where spatial context is critical.
- Integrating real-time updates to the JSON as the environment changes might further enhance responsiveness.
- Potential for combining with player position tracking to make references even more personalized.
Load-bearing premise
That the structured JSON from segmentation and scene graphs plus standard LLM prompting suffices to generate accurate and non-hallucinated references to the environment.
What would settle it
Observing whether NPCs mention objects that are not actually present in the panoramic view or fail to reference visible ones when prompted.
Figures




read the original abstract
We present an approach for enhancing non-playable characters (NPCs) in games by combining large language models (LLMs) with computer vision to provide contextual awareness of their surroundings. Conventional NPCs typically rely on pre-scripted dialogue and lack spatial understanding, which limits their responsiveness to player actions and reduces overall immersion. Our method addresses these limitations by capturing panoramic images of an NPC's environment and applying semantic segmentation to identify objects and their spatial positions. The extracted information is used to generate a structured JSON representation of the environment, combining object locations derived from segmentation with additional scene graph data within the NPC's bounding sphere, encoded as directional vectors. This representation is provided as input to the LLM, enabling NPCs to incorporate spatial knowledge into player interactions. As a result, NPCs can dynamically reference nearby objects, landmarks, and environmental features, leading to more believable and engaging gameplay. We describe the technical implementation of the system and evaluate it in two stages. First, an expert interview was conducted to gather feedback and identify areas for improvement. After integrating these refinements, a user study was performed, showing that participants preferred the context-aware NPCs over a non-context-aware baseline, confirming the effectiveness of the proposed approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a pipeline for context-aware NPC dialogue in games: panoramic images are captured around an NPC, semantic segmentation extracts objects and positions, a structured JSON is built combining these with scene-graph data and directional vectors within the NPC's bounding sphere, and the JSON is provided as input to an unmodified LLM to generate responses that reference the environment. Evaluation proceeds in two stages—an expert interview to refine the system followed by a user preference study showing participants favored the context-aware NPCs over a non-context baseline.
Significance. If the central claim holds, the work offers a practical engineering route to more immersive NPCs without heavy scripting or fine-tuning, potentially applicable to game development and interactive simulations. The two-stage evaluation supplies initial user feedback, but the absence of direct validation on whether the JSON encoding produces accurate, non-hallucinated spatial references limits how strongly the results can be interpreted as evidence for reliable environmental grounding.
major comments (1)
- [Evaluation] The user study (described after the expert interview) reports only subjective preference for context-aware NPCs versus a no-context baseline. No quantitative metrics are provided on dialogue fidelity, such as precision/recall of object mentions against the ground-truth JSON, frequency of directional errors, or hallucination rate of absent objects. This is load-bearing for the central claim because preference could arise from any added descriptive detail rather than from accurate use of the supplied spatial information.
minor comments (2)
- [Abstract] The abstract states that the approach 'confirm[s] the effectiveness' but supplies no numerical results, error rates, or prompting details; this should be expanded to include at least summary statistics from the user study.
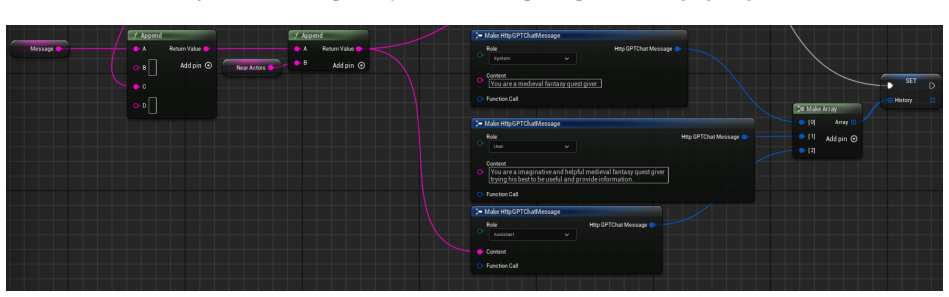
- [Technical Implementation] The description of JSON construction (object locations plus directional vectors) would benefit from an explicit example of the JSON schema and a sample LLM prompt to clarify how spatial relations are encoded for the model.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the evaluation concern point by point below, providing the strongest honest defense of our methodology while acknowledging where the manuscript can be clarified.
read point-by-point responses
-
Referee: [Evaluation] The user study (described after the expert interview) reports only subjective preference for context-aware NPCs versus a no-context baseline. No quantitative metrics are provided on dialogue fidelity, such as precision/recall of object mentions against the ground-truth JSON, frequency of directional errors, or hallucination rate of absent objects. This is load-bearing for the central claim because preference could arise from any added descriptive detail rather than from accurate use of the supplied spatial information.
Authors: We appreciate this point and agree that quantitative metrics on dialogue fidelity would offer additional validation. Our two-stage evaluation was intentionally focused on practical impact: the expert interview refined the JSON construction and prompting to ensure spatial references are grounded, while the user study measures the resulting improvement in player preference and immersion—the core claim of the work. Because the LLM receives only the structured JSON (with no other scene knowledge), the design inherently constrains outputs to the provided data, reducing the scope for ungrounded references. Full precision/recall or hallucination-rate analysis would require extensive manual annotation of open-ended dialogues, which falls outside the paper's engineering and user-experience focus. We will not add these metrics but will revise the evaluation section to include a brief discussion of this limitation and the mitigating role of the structured input. revision: partial
Circularity Check
No circularity: descriptive engineering pipeline validated by external user study
full rationale
The paper presents a system pipeline (panoramic capture, semantic segmentation, JSON scene-graph construction with directional vectors, LLM prompting) whose claims rest on an expert interview followed by a comparative user study measuring subjective preference against a no-context baseline. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the derivation chain. The evaluation is external and falsifiable via participant responses rather than reducing to internal definitions or tautological consistency. This is the expected non-finding for an applied systems paper without mathematical derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Semantic segmentation reliably extracts object identities and approximate spatial positions from panoramic images in game environments
- domain assumption Providing a JSON scene description to an LLM is sufficient for it to generate contextually appropriate and non-hallucinated dialogue references
Reference graph
Works this paper leans on
-
[1]
2022 , publisher=
Better game characters by design: A psychological approach , author=. 2022 , publisher=
2022
-
[2]
Human-level
Laird, John and VanLent, Michael , journal=. Human-level
-
[3]
Poetics , volume=
Story understanding as problem-solving , author=. Poetics , volume=. 1980 , publisher=
1980
-
[4]
Game Developers Conference , year=
Façade: An Experiment in Building a Fully-Realized Interactive Drama , author=. Game Developers Conference , year=
-
[5]
Expert Systems with Applications , volume=
Towards autonomous behavior learning of non-player characters in games , author=. Expert Systems with Applications , volume=. 2016 , publisher=
2016
-
[6]
2014 , school=
Computational techniques for modeling non-player characters in games , author=. 2014 , school=
2014
-
[7]
2022 , school=
Dynamic theme-based narrative systems , author=. 2022 , school=
2022
-
[8]
It Knows What You’re Going To Do: Adding Anticipation to a
Laird, John E , journal=. It Knows What You’re Going To Do: Adding Anticipation to a
-
[9]
IEEE Transactions on Affective Computing , volume=
Experience-driven procedural content generation , author=. IEEE Transactions on Affective Computing , volume=. 2011 , publisher=
2011
-
[10]
Applications of Evolutionary Computation:
Search-based procedural content generation , author=. Applications of Evolutionary Computation:. 2010 , organization=
2010
-
[11]
The effect of context-aware
Csepregi, Lajos Matyas , journal=. The effect of context-aware
-
[12]
Generative
Vidrih, Marko and Mayahi, Shiva , eprint=. Generative
-
[13]
Stanley: The robot that won the
Thrun, Sebastian and Montemerlo, Mike and Dahlkamp, Hendrik and Stavens, David and Aron, Andrei and Diebel, James and Fong, Philip and Gale, John and Halpenny, Morgan and Hoffmann, Gabriel and others , journal=. Stanley: The robot that won the. 2006 , publisher=
2006
-
[14]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Fully convolutional networks for semantic segmentation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[15]
Proceedings of the
Panoptic segmentation , author=. Proceedings of the
-
[16]
Teaching Agents how to Map: Spatial Reasoning for Multi-Object Navigation , year=
Marza, Pierre and Matignon, Laetitia and Simonin, Olivier and Wolf, Christian , booktitle=. Teaching Agents how to Map: Spatial Reasoning for Multi-Object Navigation , year=
-
[17]
1994 first workshop on mobile computing systems and applications , pages=
Context-aware computing applications , author=. 1994 first workshop on mobile computing systems and applications , pages=. 1994 , organization=
1994
-
[18]
Recognize anything: A strong image tagging model
Recognize Anything: A Strong Image Tagging Model , author=. 2306.03514 , archivePrefix=
-
[19]
Conversational Interactions with
Cox, Samuel Rhys and Ooi, Wei Tsang , booktitle=. Conversational Interactions with. 2023 , organization=
2023
-
[20]
Segment Anything Model Extension Zoo , author=
-
[21]
Semantic Segment Anything , author =
-
[22]
Interactive Data Synthesis for Systematic Vision Adaptation via
Qifan Yu and Juncheng Li and Wentao Ye and Siliang Tang and Yueting Zhuang , year=. Interactive Data Synthesis for Systematic Vision Adaptation via. 2305.12799 , archivePrefix=
-
[23]
Huang, Xinyu and Zhang, Youcai and Ma, Jinyu and Tian, Weiwei and Feng, Rui and Zhang, Yuejie and Li, Yaqian and Guo, Yandong and Zhang, Lei , eprint=
-
[24]
Junnan Li and Dongxu Li and Caiming Xiong and Steven Hoi , year=
-
[25]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren and Shilong Liu and Ailing Zeng and Jing Lin and Kunchang Li and He Cao and Jiayu Chen and Xinyu Huang and Yukang Chen and Feng Yan and Zhaoyang Zeng and Hao Zhang and Feng Li and Jie Yang and Hongyang Li and Qing Jiang and Lei Zhang , year=. Grounded. 2401.14159 , archivePrefix=
work page internal anchor Pith review arXiv
-
[26]
Segment Anything , author=
-
[27]
2024 , archivePrefix=
Game Generation via Large Language Models , author=. 2024 , archivePrefix=
2024
-
[28]
Steph Buongiorno and Lawrence Jake Klinkert and Tanishq Chawla and Zixin Zhuang and Corey Clark , year=
-
[29]
Text generation for quests in multiplayer role-playing video games , year =
S.B. Text generation for quests in multiplayer role-playing video games , year =
-
[30]
Player-Driven Emergence in
Peng, Xiangyu and Quaye, Jessica and Rao, Sudha and Xu, Weijia and Botchway, Portia and Brockett, Chris and Jojic, Nebojsa and DesGarennes, Gabriel and Lobb, Ken and Xu, Michael and Leandro, Jorge and Jin, Claire and Dolan, Bill , booktitle=. Player-Driven Emergence in. 2024 , volume=
2024
-
[31]
Collaborative Quest Completion with
Sudha Rao and Weijia Xu and Michael Xu and Jorge Leandro and Ken Lobb and Gabriel DesGarennes and Chris Brockett and Bill Dolan , year=. Collaborative Quest Completion with
-
[32]
A Framework for Exploring Player Perceptions of LLM -Generated Dialogue in Commercial Video Games
Akoury, Nader and Yang, Qian and Iyyer, Mohit. A Framework for Exploring Player Perceptions of LLM -Generated Dialogue in Commercial Video Games. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.151
-
[33]
2016 , organization=
Qiu, Weichao and Yuille, Alan , booktitle=. 2016 , organization=
2016
-
[34]
Extracting
Fink, Alex and Denzinger, Jorg and Aycock, John , booktitle=. Extracting. 2007 , volume=
2007
-
[35]
Proceedings of the
Krähenbühl, Philipp , title =. Proceedings of the. 2018 , pages =
2018
-
[36]
and Li, Lianchao and Wloka, Dieter and Ali, Mostafa Z
Mahmoud, Ibrahim M. and Li, Lianchao and Wloka, Dieter and Ali, Mostafa Z. , booktitle=. Believable. 2014 , volume=
2014
-
[37]
A Comprehensive Defense Approach Targeting The Computer Vision Based Cheating Tools in
Nhu, Anh and Phan, Hieu and Liu, Chang and Feng, Xianglong , booktitle=. A Comprehensive Defense Approach Targeting The Computer Vision Based Cheating Tools in. 2023 , volume=
2023
-
[38]
2019 , note=
Using Computer Vision Techniques to Play an Existing Video Game , author=. 2019 , note=
2019
-
[39]
Anonymised , year = 2024, pages =
Annonymous , title =. Anonymised , year = 2024, pages =
2024
-
[40]
Proceedings of
Grega Radež and Ciril Bohak , title =. Proceedings of
-
[41]
2025 , volume=
Yang, Daijin and Kleinman, Erica and Harteveld, Casper , journal=. 2025 , volume=
2025
-
[42]
2024 , eprint=
Large Language Models and Video Games: A Preliminary Scoping Review , author=. 2024 , eprint=
2024
-
[43]
, journal=
Gallotta, Roberto and Todd, Graham and Zammit, Marvin and Earle, Sam and Liapis, Antonios and Togelius, Julian and Yannakakis, Georgios N. , journal=. Large Language Models and Games: A Survey and Roadmap , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.